Google just announced a very large language model that achieves SOTA across a very large set of tasks, mere days after DeepMind announced Chinchilla, and their discovery that data-scaling might be more valuable than we thought.
Here's the blog post, and here's the paper. I'll repeat the abstract here, with a highlight in bold,
Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model (PaLM).
We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned stateof-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.



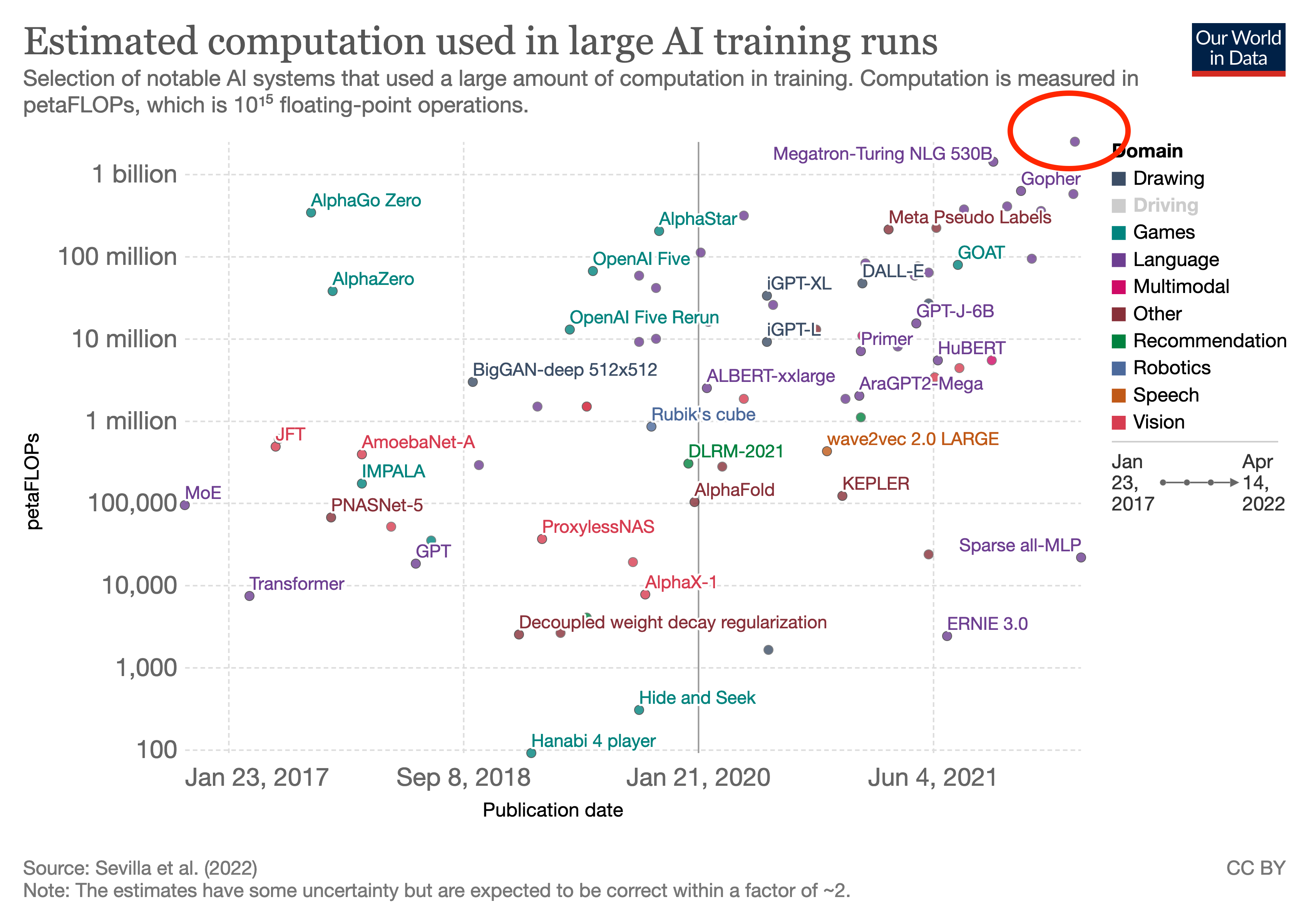


Which is reasonable. It has been about <2.5 years since GPT-3 was trained (they mention the move to Azure disrupting training, IIRC, which lets you date it earlier than just 'May 2020'). Under the 3.4 month "AI and Compute" trend, you'd expect 8.8 doublings or the top run now being 445x. I do not think anyone has a 445x run they are about to unveil any second now. Whereas on the slower >5.7-month doubling in that link, you would expect <36x, which is still 3x PaLM's actual 10x, but at least the right order of magnitude.
There may also be other runs around PaLM scale, pushing peak closer to 30x. (eg Gopher was secret for a long time and a larger Chinchilla would be a logical thing to do and we wouldn't know until next year, potentially; and no one's actually computed the total FLOPS for ERNIE-Titan AFAIK, and it may still be running so who knows what it's up to in total compute consumption. So, 10x from PaLM is the lower bound, and 5 years from now, we may look back and say "ah yes, XYZ nailed the compute-trend exactly, we just didn't learn about it until recently when they happened to disclose exact numbers." Somewhat like how some Starcraft predictions were falsified but retroactively turned out to be right because we just didn't know about AlphaStar and no one had noticed Vinyal's Blizzard talk implying they were positioned for AlphaStar.)