In October 27th 2022, Eliezer Yudkowsky tweeted this:

So far so good. I may ask myself when this happened and why the paperclips example was the one that actually sticked, but so far I have no reason to worry about my understanding of AI safety. But here's more of the conversation that happened on Twitter:
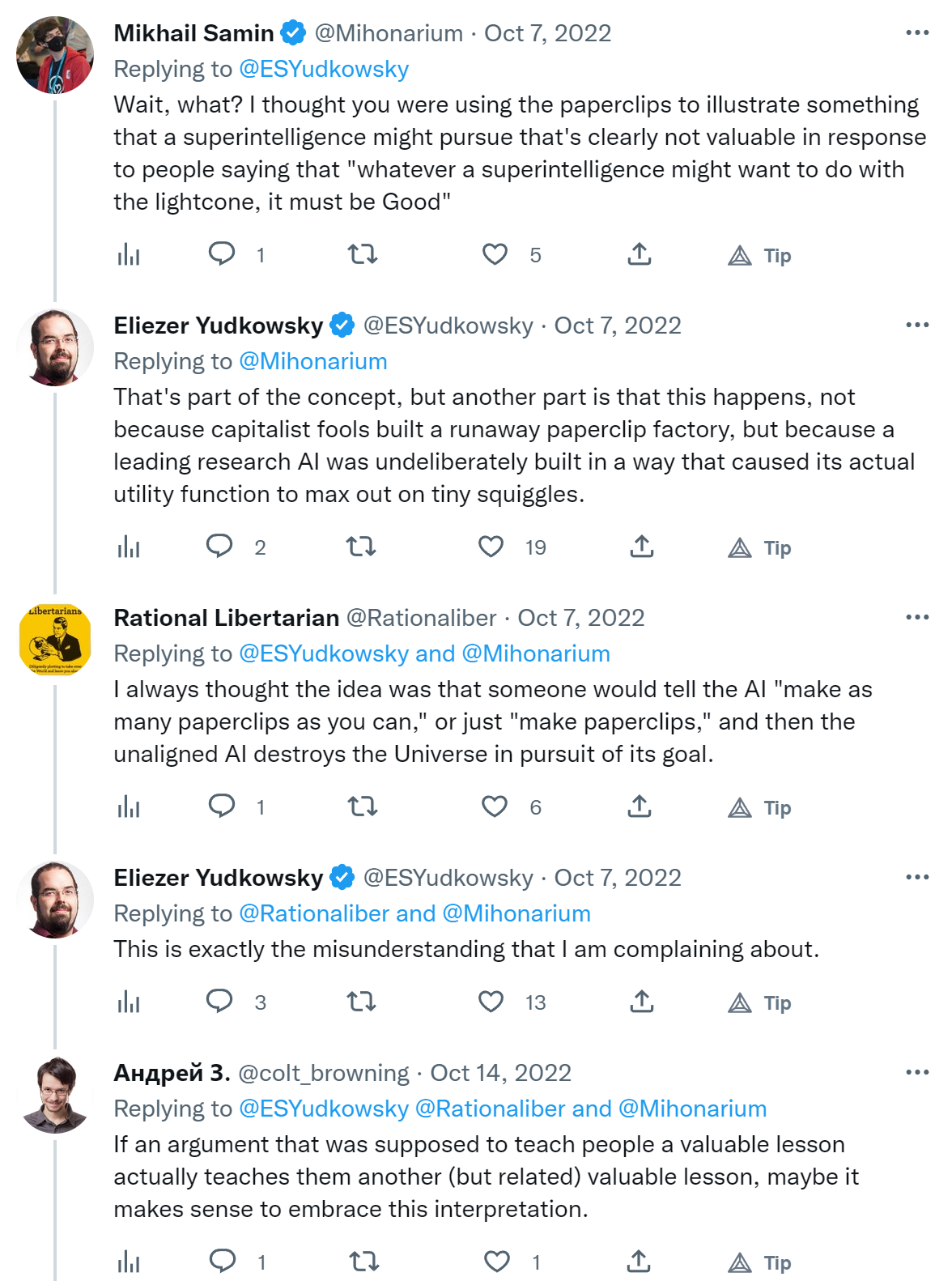
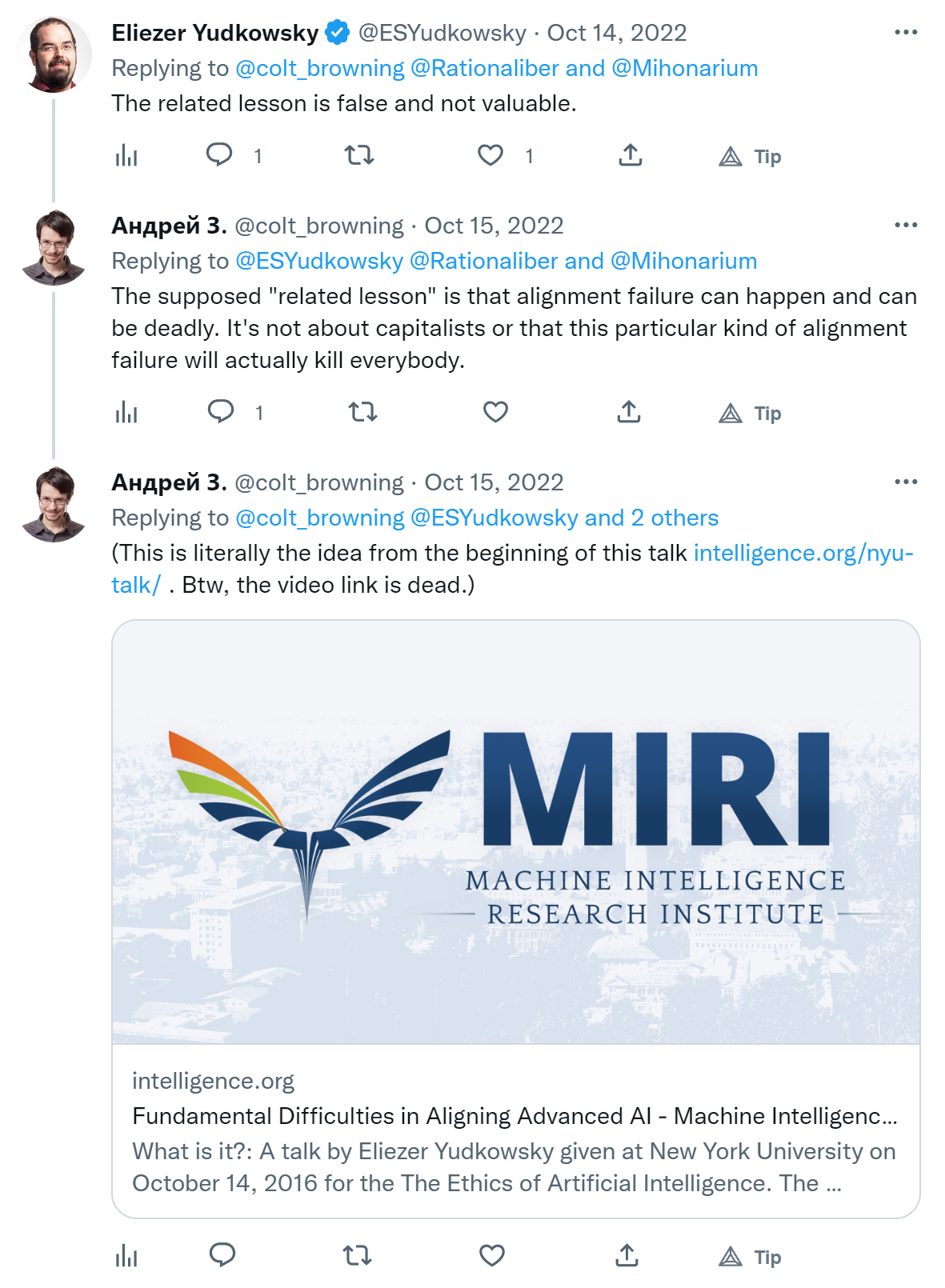
When Eliezer says "this is exactly the misunderstanding I'm complaining about" and "the related lesson is false and not valuable" I start to question my own sanity. This example is used pretty much everywhere. In Bostrom's Superintelligence, Rob Miles' videos about the stamp collector (inspired by a blog post by Nate Soares), Wait But Why's introduction to AI risk and I don't know what else.
So here are questions:
1. I don't see how the paperclips metaphor is wrong. Or am I misunderstanding Eliezer?
2. If it's wrong, why is it used everywhere?
I agree with you here, although something like "predict the next token" seems more and more likely. Although I'm not sure if this is in the same class of goals as paperclip maximizing in this context, and if the kind of failure it could lead to would be similar or not.