When you share a link on social media the platform fetches the page and includes a preview with your post:
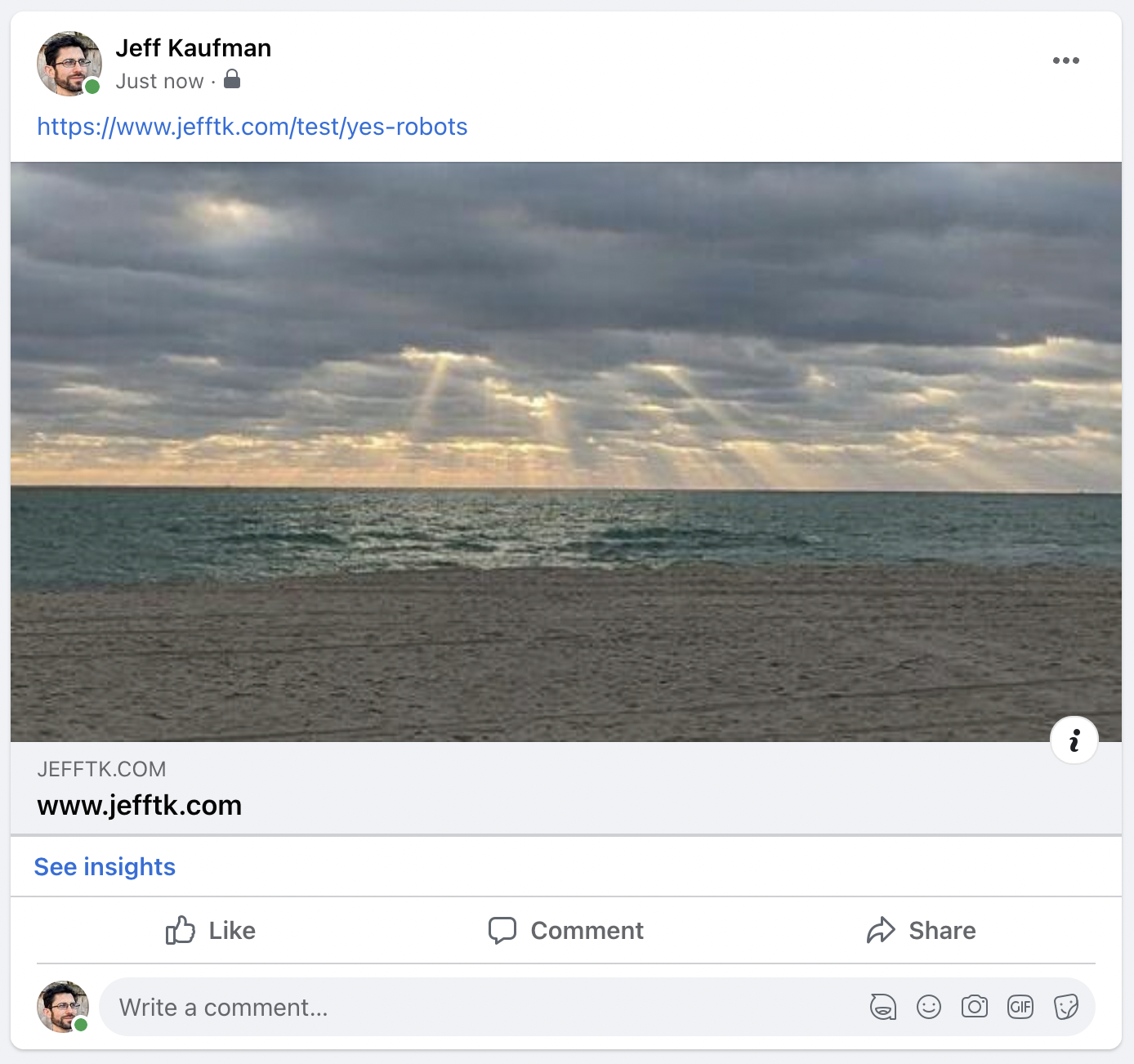
Even though this happens automatically the system doesn't obey the
robots.txt exclusion rules (RFC 3909): I have
/test/no-robots excluded in my robots.txt but that doesn't stop it:
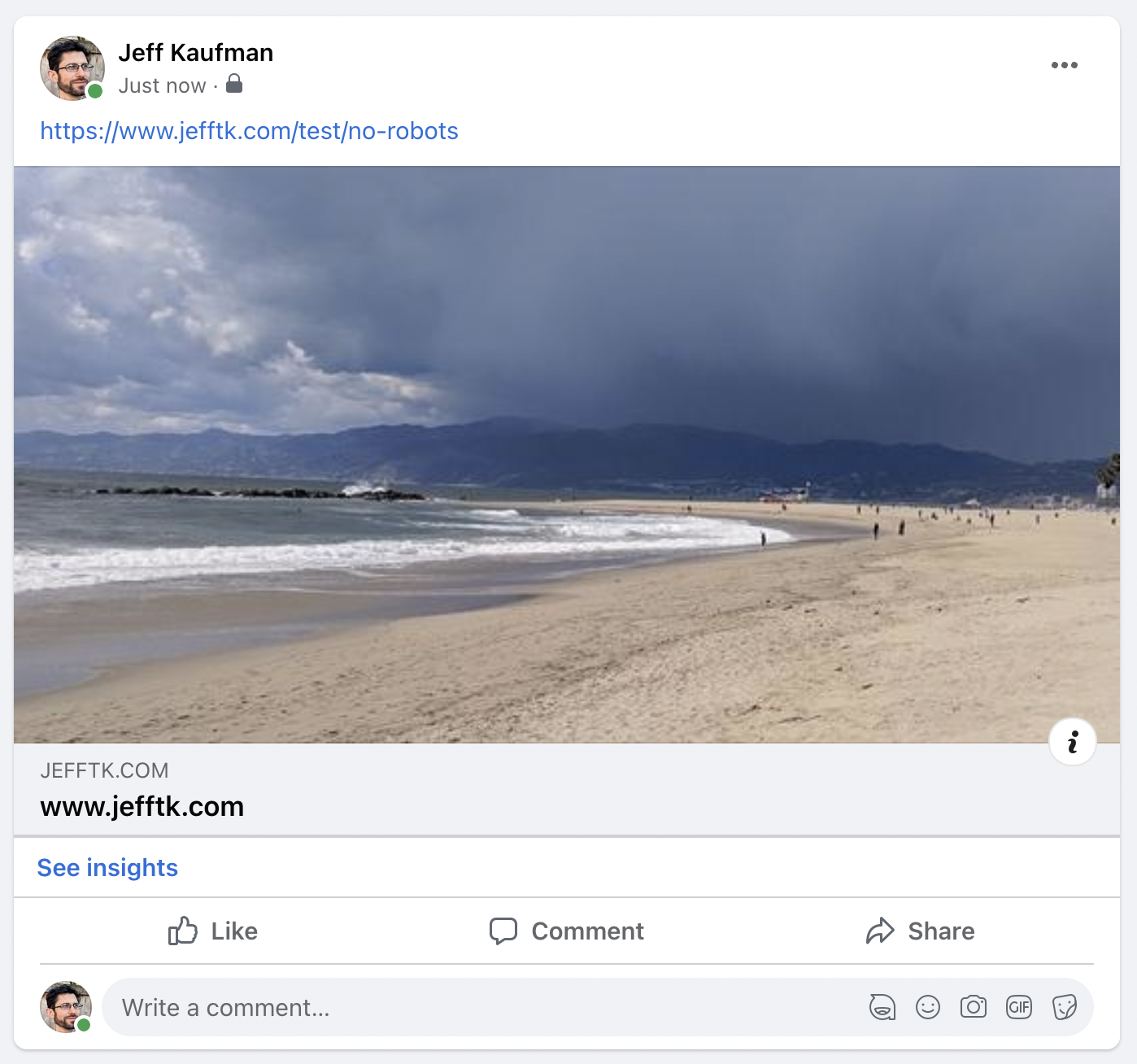
I don't even see a request for robots.txt in my logs.
But that's actually ok! The robots exclusion standard is for
"crawlers", or automated agents. When I share a link I want the
preview to be included, and so the bot fetching the page is acting as
my agent. This is the same reason why it's fine that WebPageTest and PageSpeed Insights also ignore
robots.txt: they're fetching specific pages at the user
s request so they can measure performance.
This puts Mastodon in an awkward situation. They do want to include
previews, because they're trying to do all the standard social network
things, and if they respected robots.txt many sites
you'd want to be able to preview won't work. They also don't want
the originating instance to generate the preview and include it in the
post, because it's open to abuse:
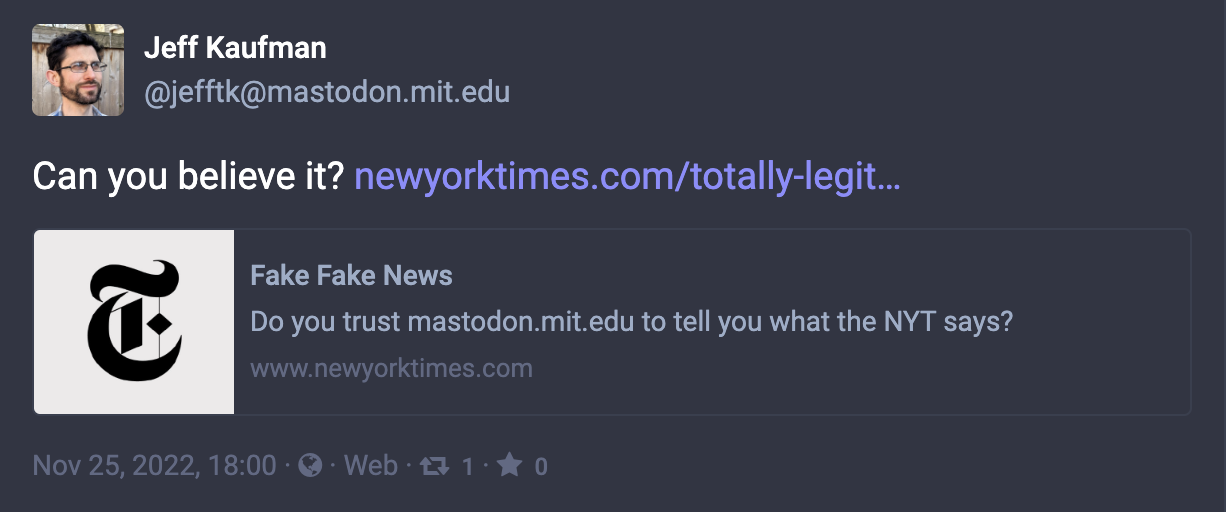
You can trust mastodon.mit.edu about what
@jefftk@mastodon.mit.edu says, but not about what
newyorktimes.com says.
The approach Mastodon has gone with is to have each instance generate link previews for each incoming link. This means that while having a link shared on Twitter or Facebook might give you one automated pageview for the preview, on Mastodon it gives you one for each instance the link is federated to. For a link shared by a widely-followed account this might mean thousands of link-preview requests hitting a server, and I'd also now consider this traffic to be from an automated agent.
I'm not sure what the right approach is for Mastodon. Making the link
preview fetcher respect robots.txt would be a good
start. [1]
Longer term I think including link previews when composing a post and
handling abuse with defederation seems like it should work as well as
the rest of Mastodon's abuse handling.
(context)
[1] Wouldn't that just add an extra request and increase the load on
sites even more? No: everyone builds sites to make serving
robots.txt very cheaply. Serving HTML, however, often
involves scripting languages, DB lookups, and other slow operations.
It seems like you could mitigate this a lot if you didn't generate the preview until you were about to render the post for the first time. Surely the vast majority of these automated previews are being rendered zero times, and saving nothing. (This arguably links the fetch to a human action, as well.)
If you didn't want to take the hit that would cause -- since it would probably mean the first view of a post didn't get a preview at all -- you could at least limit it to posts that the server theoretically might someday have a good reason to render (i.e. require that there be someone on the server following the poster before doing automated link fetching on the post.)