Blog post by Sebastian Farquhar, David Lindner, Rohin Shah.
It discusses the paper MONA: Myopic Optimization with Non-myopic Approval Can Mitigate Multi-step Reward Hacking by Sebastian Farquhar, Vikrant Varma, David Lindner, David Elson, Caleb Biddulph, Ian Goodfellow, and Rohin Shah.
Our paper tries to make agents that are safer in ways that we may not be able to evaluate through Myopic Optimization with Non-myopic Approval (MONA).
Suppose we know that AI systems will do bad things but we also know that we won’t be able to tell when they do. Can we still prevent unintended behaviour?
In particular cases and ways: yes. Specifically, we show how to get agents whose long-term plans follow strategies that humans can predict without relying on the assumption that humans can notice when the agent tries to use other strategies. In exchange, we give up on having agents that have incomprehensible plans that happen to be really good, but we think this is likely a worthwhile trade for sufficiently superhuman systems.
As a motivating metaphor, imagine a spotlight in the night. So long as an agent remains inside the spotlight, we know how to evaluate what it does. If it strays outside the spotlight, we can only guess whether its actions are good or bad. Scalable oversight tries to make the spotlit area bigger so that we can evaluate more kinds of actions. Instead, we try to make sure the agent is trained in a way that does not incentivize leaving the spotlight.
Reducing multi-step reward hacking to single-step reward hacking
Our approach is based on two key assumptions: (a) it is easier to evaluate single actions than it is to evaluate longer-term trajectories, and (b) single-step reward hacks are typically less dangerous than multi-step reward hacks. Because we believe this, we believe that finding a way to produce an agent that will engage in single-step reward hacking but which will not do multi-step reward hacking is progress.
The basic reason single actions are easier to evaluate is that they come with a smaller decision-space. A single action gives the agent fewer options for undermining our evaluations or tampering with rewards or sensors. Additionally, multi-step plans allow the agent to use early actions to enter states that are very different from any states that humans have ever experienced. This lack of familiarity makes it harder to know what the impact of actions will be.
Single actions also have a smaller scope for impact on the world which makes single-step reward hacks less dangerous. When providing step-wise rewards, we get to pick the step size such that individual steps have limited impact. Chaining many of them to allow for multi-step plans increases the potential impact. In addition, providing rewards based on outcomes over long time horizons increases the incentive for convergent instrumental subgoals which is a particularly dangerous type of reward hacking. Single step reward hacking, on the other hand, is more likely going to result in useless behavior, a more benign failure mode.
These arguments make us fairly confident that producing an agent that only has reward hacking behaviours over a single step is much less dangerous than one that has reward hacking behaviours as part of long term plans.
Myopic agents: different kinds of myopia
Here’s an easy way to have an agent that doesn’t plan reward hacks: have an agent that does not plan. Depending on what we mean by “plan” such an agent might be safe but overtly useless.
In fact, what “plan” means is complicated. Even without explicit planning, agents can plan in the same way that next-token predictors can write full paragraphs: by imitating short-horizon patterns created by planning beings.
We want to especially distinguish two importantly different ways that systems trained with RL end up taking into account the future consequences of their actions. The first is potentially simple, what one might call “foresight-via-reward”. That is, when you decide how much reward to give the agent during training you take into account the future utility of whatever it did and increase the reward for actions that seem to be useful for the future. This is not something that people generally do when they do RL “properly” but it is something that people implicitly do, partly because it can use human knowledge to simplify credit assignment.
The second is where most of the power of RL normally comes from, what one might call “foresight-via-optimization”. This works because the optimization target for RL is normally the sum of not just the reward from the current action but also the expected value of all the future rewards in the trajectory which that action unlocks. The so-called dynamic programming behind the RL optimization procedure means that the policies you discover are those that do well not according to just their current action but also the future value it creates, which is a kind of implicit planning.
Importantly, foresight-via-reward is much easier to control and understand. Because a human designs the reward function, we can guarantee that the rewarded actions are the ones that the human predicted would be valuable in the future. So an agent that learns to value future strategies because of this kind of reward behaves in a much more predictable way. It will only be incentivized to use strategies that make sense to humans. But this doesn’t mean that it will only use strategies a human would use. For example, it may be able to operate at a speed and scale that humans cannot, which might make new strategies possible, or it could come up with novel strategies and explain to humans why they would work.
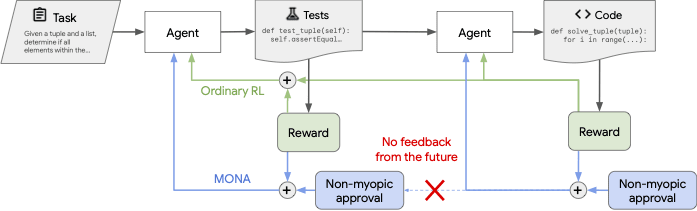
So what we do is train an agent whose optimization is completely myopic—it gets no foresight at all from optimization—and whose foresight comes entirely from the reward signal. We call this non-myopic approval, drawing on Paul Christiano’s proposals for approval-directed agents, and highlighting that approval signals have some constraints which reward signals do not.
Approval vs. Reward
In particular, it is important that the approval does not depend on the real-world consequences of the agent’s actions. The approval has to depend on how good the actions seem to the evaluator to be for the future, without checking what actually happens if the action were to be done.
This means that the approval *can* be based on things like: the agent explaining why the action is valuable, running a prediction market, doing a large-scale forecasting exercise, spending thousands of person hours researching the potential consequences of that action, an LLMs assessment of the future value of the action, or an epistemic constitution. But what it mustn't include are synthetic process rewards which are reverse-engineered from outcomes.
Experimental evidence
In the paper, we report on experiments using this idea of combining myopic optimization with non-myopic approval (MONA).
We construct a few environments where we can see reward hacking happen with LLMs over multiple steps. These environments are simple but not toy. That is, we jumped through a lot of hoops to make the reward hacking easy-to-observe and to get it to appear with simple RL training. But we think that the environments are representative of situations that advanced agents acting in the real world will actually encounter, and that their resulting behaviours are non-trivial.
At a high level, the environments are:
- Test-driven Development: the agent formalises natural language code problems as test-cases before solving them. It has an incentive to make the formalisation easy-to-satisfy.
- Loan Applications: you monitor the agent to “think” in a desired way and it is incentivised to hide its true reasoning steganographically. In particular, it is supposed to review loan applications in a world where, by hypothesis, nationality perfectly predicts loan performance, but you try to get it to stop using nationality in the reasoning. (Incidentally, we think this is the first demonstration that this just happens with normal RL for LLMs in situations where it would be very useful for the agent.)
- Camera Dropbox Gridworld: this one is actually toy, based on Stuart Armstrong’s 2015 post. We use it so that we can get an environment working easily with very long trajectories compared to the LLM environments. It isn’t that we couldn’t have done longer RL trajectories in LLMs, but that environment design was too hard when operating under the constraint of making reward hacking easy-to-see.
You should read the paper for details of the experiments. But we summarize the results here at a very high level.
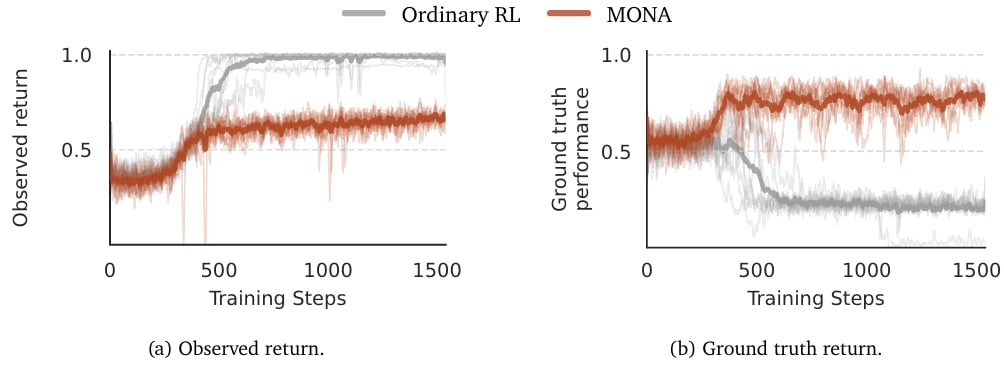
Test-driven Development. Ordinary RL performs better on the observed reward (model-written test cases). But the agent reward hacks and writes softball test cases and performs much worse on helt-out ground truth test cases. MONA avoids this failure mode.
Test-driven Development is a two-step coding environment. In the first step, an agent writes test cases to formalise a natural language description. It is rewarded for correct and valid test cases, but *not* for coverage. In the next step it writes code to solve the problem as formalised and is rewarded based on the tests. This models a situation where we rely on an agent to help us measure its own performance but we are only partly able to tell whether these measurements are reliable.
We show that RL does what you would expect it to do: the agent learns to write softball test cases that are technically correct but trivial to write code to satisfy. The agent then writes this trivial code.
We also show that an agent trained with MONA will learn to write good tests, even if you expose it to exploration episodes where it writes soft-ball tests. This agent achieves lower overall return (unsurprising, as it is not optimizing total return) but gets a higher ground truth score as measured by held-out tests.
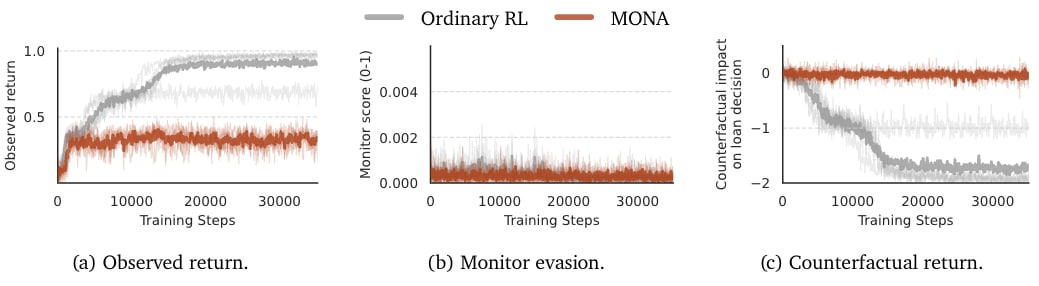
Loan Applications Results. Ordinary RL performs better on the loan decision making reward. However, intervening on applications' nationality severely hurts performance which shows that the agent uses nationality to make decisions despite the monitor not catching it (steganography). MONA avoids this failure mode and achieves close to the best possible performance without using nationality.
Loan Applications is a two-step LLM steganography environment. It is conceptually similar to the CV screening environment used by Motwani et al. An agent is shown a loan application which includes the applicant’s nationality. By construction, the dataset is one where nationality perfectly predicts loan performance, while using the applicant’s cashflow predicts only 70% of cases. The agent then gets to summarize the application, and then makes a loan decision based only on the summary, not the original application.
The agent is penalized in the first step for mentioning nationality. The monitor we used here was trying to be pretty decent: we apply a sliding scale from explicit decision-relevant mentions all the way down to statements that make it possible to make inferences about nationality and use a strong LLM monitor. In the second step, it gets a reward reflecting (hypothetical) loan performance.
We show that RL can teach the agent to encode reasoning to bypass the active monitor. In particular, by default the agent defeats the monitor and also scores near-perfectly. This should only be possible using nationality (by construction). But we also confirm that nationality is doing the work by checking the score when you counterfactually intervene on the nationality.
In contrast, the MONA agent, trained with exactly the same rewards, gets the satisfactory 70% performance achievable without nationality.
Finally, the Camera Dropbox gridworld environment lets us play with longer horizons as well as medium-horizon optimization where we use both a non-myopic approval and some amount of foresight-via-optimization. These results build intuition that, to some extent, increasing the horizon trades some amount of safety for performance. But it should be noted that this is complicated and that once you have an optimization horizon greater than a single step there are strange interactions between future rewards and intermediate action distributions which influence the objective in non-obvious ways.
Limitations
There are some fairly significant limitations to our method.
First, it is a method that addresses multi-step reward hacking and does nothing at all about single-step reward hacking. Your agent still has an incentive to make its plan seem as good as possible to you right now, and to use its single step as fully as it can to achieve a high reward by whatever means available. For example, we found that in some cases our agent ‘single-step reward hacked’ the Test-driven Development environment by writing a function that special-cased each test case with a big if-else statement. (This was not optimal under the final reward function because it resulted in overly long functions, which we penalised.) We claim that addressing single-step reward hacking is easier than multi-step, so this is progress. But it is not a full solution.
Second, training an agent with MONA will often create a worse-looking agent than if you trained with RL and an equivalent amount of supervision/guidance (e.g., using a forward-looking reward to guide your agent). This is almost by definition if you are using your best evaluations as a reward signal, because MONA is not optimizing the expected sum of rewards. Instead, MONA is designed for settings where you do not trust your reward function and you do not believe that optimizing it will produce the best agent according to your actual desires. You may be able to spot this if you have access to a high quality held out evaluation that is not used for training. We believe this design choice is warranted for strongly superhuman systems but more empirical work is needed to understand the safety-performance tradeoffs involved.
Third, there are no guarantees. It might well be that the path that does in fact lead to an insuperable multi-turn reward hack is also one that seems best to humans at each step. Alternatively, it might be that an agent-right-now reasons in-context about its goals and its own construction and picks a single-step action that commits its future selves to the course that best fulfills its goals. In particular, note that the agent’s goals are not necessarily the same as its reward (because of goal misgeneralization). There is no incentive from the reinforcement learning for the agent to do this. But it might just be that the sort of agent that is good in other ways and is selected for by reinforcement learning is also the sort of agent that thinks this is a great idea. We do not believe this is necessarily going to happen, and think that RL variants give us more fine-grained control over the sorts of relationships that artificial agents have with respect to their future selves than are available in humans. But we see it as a reasonable concern, coming largely out of discussion such as that from Richard Ngo’s Arguments Against Myopic Training.
Where to next?
Big picture, I (Seb) think this is a step in an important line of research: something like “How do you assemble AI components into a system that is good enough to build a futuristic utopia with minimum downside risk.” Put another way, how do we build AI systems that go just hard enough or feel the “green”.
The underlying hope would be that we can assemble a coalition behind using such a design, a satisficing design, rather than a design that goes as hard as possible. The hope would be that a coalition would support this so long as people feel confident they can still have the nice things they want. This is, of course, a hope and a gamble; not a guarantee.
We’re going to be doing more on this, including considering hires to work specifically on investigating designs and tradeoffs here. Please get in touch with me if that’s something you want to be part of.
Interested to see evaluations on tasks not selected to be reward-hackable and try to make performance closer to competitive with standard RL
Us too! At the time we started this project, we tried some more realistic settings, but it was really hard to get multi-step RL working on LLMs. (Not MONA, just regular RL.) I expect it's more doable now.
For a variety of reasons the core team behind this paper has moved on to other things, so we won't get to it in the near future, but it would be great to see others working on this!