I'm reading the "You're Calling Who A Cult Leader?" again, and now the answer seems obvious.
"I publicly express strong admiration towards the work of Person X." -- What could possibly be wrong about this? Why are our instincts screaming at us not to do this?
Well, assigning a very high status to someone else is dangerous for pretty much the same reason as assigning a very high status to yourself. (With possible exception if the person you admire happens to be the leader of the whole tribe. Even so, who are you to speak about such topics? As if your opinion had any meaning.) You are challenging the power balance in the tribe. Only instead of saying "Down with the current tribe leader; I should be the new leader!" you say "Down with the current tribe leader; my friend here should be the new leader!"
Either way, the current tribe leader is not going to like. Neither his allies. Neither neutral people, who merely want to prevent another internal fight where they have nothing to gain. All of them will tell you to shut up.
There is nothing bad per se about suggesting that e.g. Douglas R. Hofstadter should be the king of the nonconformist tribe. Maybe ...
I was talking to the loved one about this last night. She is going for ministry in the Church of England. (Yes, I remain a skeptical atheist.)
She is very charismatic (despite her introversion) and has the superpower of convincing people. I can just picture her standing up in front of a crowd and explaining to them how black is white, and the crowd each nodding their heads and saying "you know, when you think about it, black really is white ..." She often leads her Bible study group (the sort with several translations to hand and at least one person who can quote the original Greek) and all sorts of people - of all sorts of intelligence levels and all sorts of actual depths of thinking - get really convinced of her viewpoint on whatever the matter is.
The thing is, you can form a cult by accident. Something that looks very like one from the outside, anyway. If you have a string of odd ideas, and you're charismatic and convincing, you can explain your odd ideas to people and they'll take on your chain of logic, approximately cut'n'pasting them into their minds and then thinking of them as their own thoughts. This can result in a pile of people who have a shared set of odd beliefs, which looks pretty damn cultish from the outside. Note this requires no intention.
As I said to her, "The only thing stopping you from being L. Ron Hubbard is that you don't want to. You better hope that's enough."
A few questions about cryonics I could not find answers to online.
What is the fraction of deceased cryo subscribers who got preserved at all? Of those who are, how long after clinical death? Say, within 15 min? 1 hour? 6 hours? 24 hours? Later than that? With/without other remains preservation measures in the interim?
Alcor appears to list all its cases at http://www.alcor.org/cases.html , and Ci at http://198.170.115.106/refs.html#cases , though the last few case links are dead. So, at least some of the statistics can be extracted. However, it is not clear whether failures to preserve are listed anywhere.
Some other relevant questions which I could not find answers to:
How often do cryo memberships lapse and for what reasons?
How successful are last-minute cryo requests from non-subscribers?
Bad news, guys - we're probably all charismatic psychotics; from "The Breivik case and what psychiatrists can learn from it", Melle 2013:
The court reports clearly illustrate the odd effect Breivik seems to have had on all his evaluators, including the first, in generating reluctance to explore what might lie behind some of his strange utterances. As an illustration, when asked if he ever was in doubt about Breivik's sanity, one of the witnesses stated that he was that once, when Breivik in a discussion suggested that in the future people's brains could be directly linked to a computer, thus circumventing the need for expensive schooling. Instead of asking Breivik to extrapolate, the witness stated that he “rapidly said to himself that this was not a psychotic notion but rather a vision of the future”.
It's a good thing Breivik didn't bring up cryonics.
The sanitised LW feedback survey results are here: https://docs.google.com/spreadsheet/ccc?key=0Aq1YuBYXaqWNdDhQQmQ3emNEOEc0MUFtRmd0bV9ZYUE&usp=sharing
I'll be writing up an analysis of results, but that takes time.
Locations that received feedback:
(3) Washington, DC
(1) No local meetup
(*) means the feedback is from someone who hasn't attended because it's too far away, so seeing the specific response is probably not very helpful. (**) means the group name is written in the public results, so you can just search for it to find your feedback....
Scott Aaronson isn't convinced by Giulio Tononi's integrated information theory for consciousness.
But let me end on a positive note. In my opinion, the fact that Integrated Information Theory is wrong—demonstrably wrong, for reasons that go to its core—puts it in something like the top 2% of all mathematical theories of consciousness ever proposed. Almost all competing theories of consciousness, it seems to me, have been so vague, fluffy, and malleable that they can only aspire to wrongness.
DragonBox has been mentioned on this site a few times, so I figured that people might be interested knowing in that its makers have come up with a new geometry game, Elements. It's currently available for Android and iOS platforms.
DragonBox Elements takes its inspiration from “Elements”, one of the most influential works in the history of mathematics.Written by the Greek mathematician Euclid, “Elements” describes the foundations of geometry using a singular and coherent framework. Its 13 volumes have served as a reference textbook for over 23 centuries. The book also introduced the axiomatic method, which is the system of argumentation that forms the basis for the scientific method we still use today. DragonBox Elements makes it possible for players to master its essential axioms and theorems after just a couple of hours playing!
Geometry used to be my least favorite part of math and as a result, I hardly remember any of it. Playing this game with that background is weird: I don't really have a clue of what I'm doing or what the different powers represent, but they do have a clear logic to them, and now that I'm not playing, I find myself automatically looking for triangles and ...
I have the privilege of working with a small group of young (12-14) highly gifted math students for 45 minutes a week for the next 5 weeks. I have extraordinary freedom with what we cover. Mathematically, we've covered some game theory and Bayes' theorem. I've also had a chance to discuss some non-mathy things, like Anki.
I only found out about Anki after I'd taken a bunch of courses, and I've had to spend a bunch of time restudying everything I'd previously learned and forgotten. It would have been really nice if someone had told me about Anki when I was 12.
So, what I want to ask Lesswrong, since I suspect most of you are like the kids I'm working with except older, is what blind spots did 12-14-year-old you have I could point out to the kids I'm working with?
what blind spots did 12-14-year-old you have
Heh, if I was 12-14 these days, the main message I would send to me would be: Start making and publishing mobile games while you have a lot of free time, so when you finish university, you have enough passive income that you don't have to take a job, because having a job destroys your most precious resources: time and energy.
(And a hyperlink or two to some PUA blogs. Yeah, I know some people object against this, but this is what I would definitely send to myself. Sending it to other kids would be more problematic.)
I would recommend Anki only for learning languages. For other things I would recommend writing notes (text documents); although this advice may be too me-optimized. One computer directory called "knowledge", subdirectories per subject, files per topic -- that's a good starting structure; you can change it later, if you need. But making notes becomes really important at the university level.
I would stress the importance of other things than math. Gifted kids sometimes focus on their strong skills, and ignore their weak skills -- they put all their attention to where they receive praise. This is a big mistake. However...
what blind spots did 12-14-year-old you have
Social capital is important. Build it.
Some actionable advice: Keep written notes about people (don't let them know about that). For every person, create a file that will contain their name, e-mail, web page, facebook link, etc., and the information about their hobbies, what you did together, whom they know, etc. Plus a photo.
This will come very useful if you haven't been in contact with the person for years, and want to reconnect. (Read the whole file before you call them, and read it again before you meet them.) Bonus points if you can make the information searchable, so you can ask queries like "Who can speak Japanese?" or "Who can program in Ruby?".
This may feel a bit creepy, but many companies and entrepreneurs do something similar, and it brings them profit. And the people on the other side like it (at least if they don't suspect you to use a system for this). Simply think about your hard disk as your extended memory. There would be nothing wrong or creepy if you simply remembered all this stuff; and there are people with better memory who would.
Maybe make some schedule to reconnect with each person once in a few years, so they don't forget you completel...
I never learned how to put forth effort, because I didn't need to do so until after I graduated high school.
I got into recurring suboptimal ruts, sometimes due to outside forces, sometimes due to me not being agenty enough, that eroded my conscientiousness to the point that I'm quite terrified about my power (or lack there of) to get back to the level of ability I had at 12-14.
I suppose, if I had to give my younger self advice in the form of a sound-byte, it'd be something like: "If you aren't--maybe at least monthly--frustrated, or making less progress than you'd like, you aren't really trying; you're winning at easy mode, and Hard Mode is likely to capture you unprepared. Of course, zero progress is bad, too, so pick your battles accordingly."
Also, even if you're on a reasonable difficulty setting, it pays to look ahead and make sure you aren't missing anything important. My high school calculus teacher missed some notational standards in spite of grasping the math, and her first college-level course started off painful for it; I completely missed the cross and dot products in spite of an impressive math and physics High school transcript, and it turns out those matter a good deal (and at the time, the internet was very unsympathetic when I tried researching them).
Where is somewhere to go for decent discussion on the internet? I'm tired of how intellectually mediocre reddit is, but this place is kind of dead.
Alternative: Liven up Less Wrong. I'm not sure how to do that, but it's possible solution to your problem.
If you want to make LW livelier, you should downvote less on the margin... downvoting disincentivizes posting. It makes sense to downvote if there's lots of content and you want to help other people cut through the crap. But if there's too little it's arguably less useful.
Also develop your interesting thoughts and create posts out of them.
Slate Star Codex comments have smart people and a significant overlap with LW, but the interface isn't great (comment threading stops after it gets to a certain level of depth, etc). Alternatively, it may help to be more selective on reddit - no default subreddits, for example.
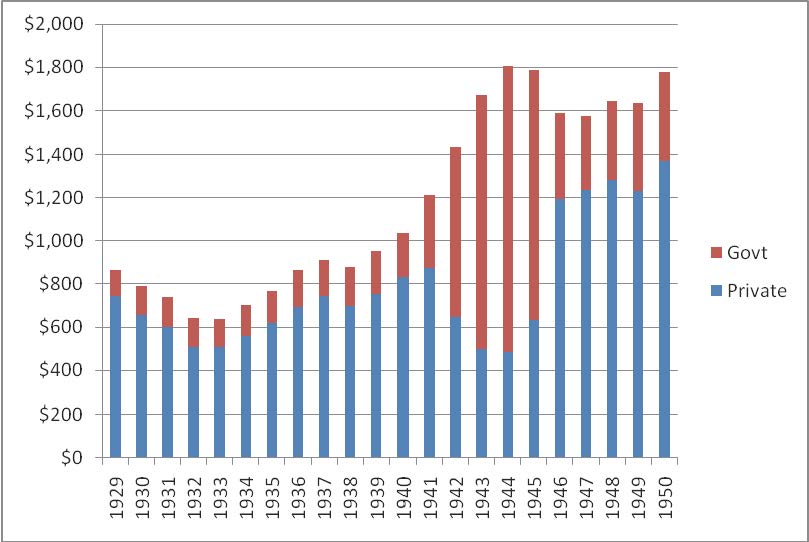
This just struck me: people always credit WWII as being the thing that got the US out of the great depression. We've all seen the graph (like the one at the top of this paper) where standard of living drops precipitously during the great depression then more than recovers during WWII.
How in the world did that work? Why is it that suddenly pouring huge resources out of the country into a massive utility-sink that didn't exist until the start of the war rapidly brought up the standard of living? This makes no sense to me.
The only plausible explanation I can think up is that they somehow borrowed from the future using the necessities of war as justification. I feel like that would involve a dip in the growth rate after WWII - and there is one, but it just dips back down to the trend-line not below like I would expect if they genuinely borrowed enough from the future to offset such a large downturn as the great depression. The only other thing seems to be externalities.
However this goes, this seems to be a huge argument in favor of big-government spending (if we get this much utility from the government building things that literally explode themselves without providing non-military ut...
How in the world did that work?
It didn't. This is the argument in image form, and you can find similar ones for employment (basically, when you conscript people, unemployment goes down. Shocking!). There are lots of libertarian articles on the subject--this might be an alright introduction--but the basic argument is that standards of living dropped (that's what happens when food is rationed and metal is used for tanks instead of cars or household appliances) but the government spending on bombs and soldiers made the GDP numbers go up, and then the post-war boost in standards of living was mostly due to deferred spending.
One simple model which seems to fit the "WWII ending the depression" piece of data (and which might have some overlap with the truth) is that it's relatively difficult to put idle resources into use, and significantly easier to repurpose resources that have been in use for other uses.
During the depression, a bunch of people were unemployed, factories were not running, storefronts were empty, etc. According to this model, under those economic conditions there were significant barriers to taking those idle resources and putting them to productive use.
Then WWII came and forced the country to mobilize and put those resources to use (even if that use was just to make stuff which would be shipped off to Europe and the Pacific to be destroyed). Once the war was over, those resources which had been devoted to war could be repurposed (with relatively little friction) to uses with a much more positive effect on people's standard of living. So things became good according to meaningful metrics like living standards, not merely according to metrics like unemployment rate or total output which ignore the fact that building a tank to send to war isn't valuable in the same way as buildi...
I'm not sure how much it influenced the overall picture, but there was quite a brain drain to the US before and during WWII (mostly Jewish refugees) as well as after (Wernher von Braun and the like). Migrating away from the Nazi and Stalinist spheres of influence demonstrates intelligence, and the ability to enter the US despite the complex “national origins quota system” that went into effect in 1929 demonstrates persistence, affluence and/or marketable skills, so I estimate these immigrants gave a significant boost to the US economy.
I've been searching LessWrong for prior discussions on Anxiety and I'm not getting very many hits. This surprised me. Obviously there have been well developed discussions on arkrasia, and ugh fields, yet little regarding their evil siblings Anxiety, Panic, and Mania.
I'd be interested to hear what people have to say about these topics from a rationalist's perspective. I wonder if anyone has developed any tricks, to calm the storm, and search for a third alternative.
Of course, first, and foremost, in such situations one should seek medical advice.
EDIT: Some very slightly related discussions: Don't Fear Failure, Hoping to start a discussion about overcoming insecurity.
I just realized you can model low time preference as a high degree of cooperation between instances of yourself across time, so that earlier instances of you sacrifice themselves to give later instances a higher payoff. By contrast, a high time preference consists of instances of you each trying to do whatever benefits them most at the time, later instances be damned.
That makes sense. Even cooperating across short time frames might be problematic - "I'll stay in bed for 10 more minutes, even if it means that me-in-10-minutes will be stressed out and might be late for work"
I prefer to see long-term thinking as increased integration among different time-selves rather than a sacrifice, though - it's not a sacrifice to take actions with a delayed payoff if your utility function puts a high weight on your future-selves' wellbeing.
This is a test posting to determine the time zone of the timestamps, posted at 09:13 BST / 08:13 UTC.
ETA: it's UTC.
What would happen if citizens had direct control over where their tax dollars went? Imagine a system like this: the United States government raises the average person's tax by 3% (while preserving the current progressive tax rates). This will be a "vote-with-your-wallet" tax, where the citizen can choose where the money should go. For example, he may choose to allocate his tax funds towards the education budget, whereas someone else may choose to put the money towards healthcare instead. Such a system would have the benefit of being at democratic in deciding the nation's priorities, while bypassing political gridlock. What would be the consequences of this system?
The biggest problem I can see with this is inefficient resource allocation. Others have mentioned ways of giving money to yourself, but we could probably minimize that with conflict-of-interest controls or by scoping budgetary buckets correctly. But there's no reason, even in principle, to think that the public's willingness to donate to a government office corresponds usefully to its actual needs.
As a toy example, let's say the public really likes puppies and decides to put, say, 1% of GDP into puppy shelters and puppy-related veterinary programs. Diminishing returns kick in at 0.1% of GDP; puppies are still being saved, but at that point marginal dollars would be doing more good directed at kitten shelters (which were too busy herding cats to spend time on outreach in the run-up to tax season). The last puppy is saved at 0.5% of GDP, and the remaining 0.5% -- after a modest indirect subsidy to casinos and makers of exotic sports cars -- goes into the newly minted Bureau for Puppy Salvation's public education fund.
Next tax cycle, that investment pays off and puppies get 2% of GDP.
Lots of people are arguing governments should provide all citizens with an unconditional basic income. One problem with this is that it would be very expensive. If the government would give each person say 30 % of GDP per capita to each person (not a very high standard of living), then that would force them to raise 30 % of GDP in taxes to cover for that.
On the other hand, means-tested benefits have disadvantages too. It is administratively costly. Receiving them is seen as shameful in many countries. Most importantly, it is hard to create a means-tested system that doesn't create perverse incentives for those on benefits, since when you start working, you will both lose your benefits and start paying taxes under such a system. That may mean that the net income can be a very small proportion of the gross income for certain groups, incentivizing them to stay unemployed.
One middle route I've been toying with is that the government could provide people with cheap goods and services. People who were satisfied with them could settle for them, whereas those who wanted something more fancy would have to pay out of their own pockets. The government would thus provide people with no-frills ...
A sharp divide between basic, subsidized, no-frills good and services and other ones didn't work in the socialist German Democratic Republic (long story, reply if you need it). What does seem to be for various countries is different rates of value-added tax depending on the good or service - the greater the difference in taxation, the closer you get to the system you've described, but it is more gradual and can be fine-tuned. Maybe that could work for sales tax, too?
A sharp divide between basic, subsidized, no-frills good and services and other ones didn't work in the socialist German Democratic Republic (long story, reply if you need it).
I'd be interested in hearing about this.
I'm no economist, but as a former citizen of that former country, this is what I could see.
There was a divide of basic goods and services and luxury ones. Basic ones would get subsidies and be sold pretty much at cost, luxury ones would get taxed extra to finance those subsidies.
The (practically entirely state-owned) industries that provided the basic type of goods and services were making very little profit and had no real incentive to improve their products, except to produce them cheaper and more numerously. Nobody was doing comparison shopping on those, after all. (Products from imperalist countries were expected to be better in every way, but that would often be explained away by capitalist exploitation, not seen as evidence homemade ones could be better.) So for example, the country's standard (and almost only) car did not see significant improvements for decades, although the manufacturer had many ideas for new models. The old model had been defined as sufficient, so to improve it was considered wasteful and all such plans were rejected by the economy planners.
The basic goods were of course popular, and due to their low price, demand was frequently not met. People would chan...
"Those who want to distinguish themselves from the masses - who want to consume conspiciously - will also be affected, since they will have to spend less to stand out from the crowd" - maybe I've misunderstood this, but surely it would have the opposite result? Let's say rents are ~$20/sqm (adjust for your own city; the principle stays the same). If I want my apartment to be 50 sqm rather than 40 sqm, that's an extra $200. But if 40 sqm apartments were free, the price difference would be the full $1000/month price of the bigger apartment. You've still got a cliff, just like in the means-tested welfare case; it's just that now it's on the consumption side.
In practice this would probably destroy the market for mid-priced goods - who wants to pay $1000/month just for an extra 10 square meters? Non-subsidized goods will only start being attractive when they get much better than the stuff the government provides, not just slightly better.
Also, if you give out goods rather than money, you're going to have to provide a huge range of different goods/services, because otherwise there will be whole categories of products that people who legitimately can't work (elderly, disabled etc) won't have access to. And if you do that, the efficiency of your economy is going to go way down - not just because the government is generally less efficient than the free market, but also because people can't use money to allocate resources according to their own preferences.
Regarding networks; is there a colloquially accepted term for when one has a ton of descriptive words (furry, bread sized, purrs when you pet them, claws, domesticated, hunts mice, etc) but you do not have the colloquially accepted term (cat) for the network? I have searched high and low and the most I have found is reverse defintion search, but no actual term.
A video of Daniel Dennett giving an excellent talk on free will at the Santa Fe Institute: https://www.youtube.com/watch?v=wGPIzSe5cAU It largely follows the general Less Wrong consensus, but dives into how this construction is useful in the punishment and moral agent contexts more than I've seen developed here.
Hack the SAT essay:
First, some background: The SAT has an essay, graded on a scale from 1-6. The essay scoring guidelines are here . I'll quote the important ones for my purposes:
“Each essay is independently scored by two readers on a scale from 1 to 6. These readers' scores are combined to produce the 2-12 scale. The essay readers are experienced and trained high school and college teachers.” “Essays not written on the essay assignment will receive a score of zero”
Reports vary, but apparently, most grader spend between 90 seconds to 2 and a half minutes o...
First observation: Surely any entity intelligent enough to hack the essay according to the rules you have set is also intelligent enough to get the maximum grade (much more easily) by the usual means of writing the assigned essay…
Second observation: Since the concept of "being on topic" is vague (essentially, anything that humans interpret as being on a certain topic is on that topic) maybe the easiest way to hack it following your rules would be to write an essay that is not on topic by the criteria the designers of the exam had in mind, but that is close enough that it can confuse the graders into believing it is on topic. An analogy could be how some postmodernists confused people into believing they were doing philosophy...
A while ago I mentioned how I'd set up some regexes in my browser to alert me to certain suspicious words that might be indicative of weak points in arguments.
I still have this running. It didn't have the intended effect, but it is still slightly more useful than it is annoying. I keep on meaning to write a more sophisticated regex that can somehow distinguish the intended context of "rather" from unintended contexts. Natural language is annoying and irregular, etc., etc.
Just lately, I've been wondering if I could do this with more elaborate patt...
Apparently I don't forget ideas, they just move places in my consciousness.
In the first week of last september I mused about writing a handbook of rationality for myself akin to how the ancient Stoics wrote handbooks for themselves. Nothing came from it, I plain and simply forgot about it. Next week I mused about writing a book using LaTeX and git as the git model allows to have many parallel versions of the book and there needs to be no canon for it to work, as opposed to a wiki, though still allowing collaboration. Now there already is a book written wit...
Yann LeCun, head of Facebook's AI-lab, did an AMA on /r/MachineLearning/ a few days ago. You can find the thread here.
In response to someone asking "What are your biggest hopes and fears as they pertain to the future of artificial intelligence?", LeCun responds that:
...Every new technology has potential benefits and potential dangers. As with nuclear technology and biotech in decades past, societies will have to come up with guidelines and safety measures to prevent misuses of AI.
One hope is that AI will transform communication between people, and
I'd love to see a discussion between people like LeCun, Norvig, Yudkowsky and e.g. Russell. A discussion where they talk about what exactly they mean when they think about "AI risks", and why they disagree, if they disagree.
Right now I often have the feeling that many people mean completely different things when they talk about AI risks. One person might mean that a lot of jobs will be gone, or that AI will destroy privacy, while the other person means something along the lines of "5 people in a basement launch a seed AI, which then turns the world into computronium". These are vastly different perceptions, and I personally find myself somewhere between those positions.
LeCun and Norvig seem to disagree that there will be an uncontrollable intelligence explosion. And I am still not sure what exactly Russell believes.
Anyway, it is possible to figure this out. You just have to ask the right questions. And this never seems to happen when MIRI or FHI talk to experts. They never specifically ask about their controversial beliefs. If you e.g. ask someone if they agree that general AI could be a risk, a yes/no answer provides very little information about how much they agree with MIRI. You'll have to ask specific questions.
Are there any math/stats/CS theory types out there who are interested in suggestions for new problems?
I am finding that my large scale lossless data compression work is generating some mathematical problems that I don't have time to solve in their full generality. I could write up the problem definition and post to LW if people are interested.
I have a random mathematical idea, not sure what it means, whether it is somehow useful, or whether anyone has explored this before. So I guess I'll just write it here.
Imagine the most unexpected sequence of bits. What would it look like? Well, probably not what you'd expect, by definition, right? But let's be more specific.
By "expecting" I mean this: You have a prediction machine, similar to AIXI. You show the first N bits of the sequence to the machine, and the machine tries to predict the following bit. And the most unexpected sequence is one ...
Asking "Would an AI experience emotions?" is akin to asking "Would a robot have toenails?"
There is little functional reason for either of them to have those, but they would if someone designed them that way.
Edit: the background for this comment - I'm frustrated by the way AI is represented in (non-rationalist) fiction.
Slatestarcodex isn't loading for me. It's obviously loading for other people-- I'm getting email notifications of comments. I use chrome.
Anyone have any idea what the problem might be?
The OpenWorm Kickstarter ends in a few hours, and they're almost to their goal! Pitch in if you want to help fund the world's first uploads.
ETA: Problems solved, LW is amazing, love you all, &c.
I am in that annoying state where I vaguely recall the shape of a concept, but can't find the right search terms to let me work out what it was I originally read. Does anyone recognise either of the things below?
(One of the many situations where googling "morality of doughnuts" doesn't help much)
Probably too late, but: I have the impression there's a substantial number of anime fans here. Are there any lesswrongers at or near MomoCon (taking place in Atlanta downtown this weekend) and interested in meeting up?
What's the best way to learn programming from a fundamentals-first perspective? I've taken / am taking a few introductory programming courses, but I keep feeling like I've got all sorts of gaps in my understanding of what's going on. The professors keep throwing out new ideas and functions and tools and terms without thoroughly explaining how and why it works like that. If someone has a question the approach is often, "so google it or look in the help file". But my preferred learning style is to go back to the basics and carefully work my way up ...
Is there a way to get email notifications on receiving new messages or comments? I've looked under preferences, and I can't find that option.
I buy a lot of berries, and I've heard conflicting opinions on the health risks of organic vs regular berries (and produce in general). My brief Google research seems to indicate that there's little additional risk if any from non-organic prodce, but if anyone knows more about the subject, I'd appreciate some evidence.
If you could magically stop all human-on-human violence, or stop senescence (aging) for all humans, which would it be?
The latter. The former is already decreasing at an incredible speed but I see no trend for the latter.
I'm much more likely to die of aging than of violence; so I'd rather stop aging.
This seems to generalize well to the rest of humanity. I am surprised that most others who replied disagrees. ISTM that most existential risks are not due to deliberate violence, but rather unintended consequences.
The formed is a major existential risk, while the latter is probably going to be solved soon(er), so the former.
I don't think it works that way. Currently most human-on-human violence is committed by young people (specifically young men), who by this logic should have the lowest time preference, since they can expect to have the most years left to live.
If you stopped aging today, I imagine there would very quickly be overpopulation issues
To give a sense of proportion: suppose that tomorrow, we developed literal immortality - not just an end to aging, but also prevented anyone from dying from any cause whatsoever. Further suppose that we could make it instantly available to everyone, and nobody would be so old as to be beyond help. So the death rate would drop to zero in a day.
Even if this completely unrealistic scenario were to take place, the overall US population growth would still only be about half of what it was during the height of the 1950s baby boom! Even in such a completely, utterly unrealistic scenario, it would still take around 53 years for the US population to double - assuming no compensating drop in birth rates in that whole time.
...DR. OLSHANSKY: [...] I did some basic calculations to demonstrate what would happen if we achieved immortality today. And I compared it with growth rates for the population in the middle of the 20th Century. This is an estimate of the birth rate and the death rate in the year 1000, birth rate roughly 70, death rate about 69.5. Remember when there's a growth rate of 1 percent, very m
On that note, a 2006 article in The Scientist argues that simply slowing aging by seven years would produce large enough of an economic benefit to justify the US investing three billion dollars annually to this research. One excerpt:
Take, for instance, the impact of just one age-related disorder – Alzheimer disease (AD). For no other reason than inevitable shifting demographics, the number of Americans stricken with AD will rise from 4 million today to as many as 16 million by mid-century.4 This means there will be more people with AD in the US by 2050 than the entire current population of Australia. Globally, AD prevalence is expected to rise to 45 million by 2050, with three of every four AD patients living in a developing nation.5 The US economic toll is currently $[80 - 100] billion, but by 2050 more than $1 trillion will be spent annually on AD and related dementias. The impact of this single disease will be catastrophic, and this is just one example.
Cardiovascular disease, diabetes, cancer, and other age-related problems account for billions of dollars siphoned away for “sick care.” Imagine the problems in many developing nations where there is little or no formal training in geriatric health care. For instance, in China and India the elderly will outnumber the total current US population by mid-century. The demographic wave is a global phenomenon that appears to be leading health care financing into an abyss.
What do you think about using visualizations for giving "rational" advice in a compact form?
Case in point: I just stumbled over relationtips by informationisbeautiful and thought: That is nice.
This also reminds me of the efficiency of visual presentation explained in The Visual Display of Quantitative Information by Tufte.
And I wonder how I might quote these in the Quotes Thread...
Could someone write a Wiki article on Updateless Decision Theory? I'm looking for an article that is not too advanced and not too basic, and I think that a typical wiki article would be just right.
I find using a chess timer in conjunction with Pomodoros helpful in restricting break time overflow. Tracking work vs break time via the chess timer motivates me to keep the ratio in check. It is also satisfying to get your "score" up; a high work to break ratio at the end of a session feels good.
(Inspired by sci-fi story)
A new intelligence enhancing brain surgery has just been developed. In accordance with Algernon's Law, it has a severe drawback: your brain loses its ability to process sensory input from your eyes, causing you to go blind.
How big of an intelligence increase would it take before you'd be willing to give up your eyesight?
I notice that I have a hard time getting myself to make decisions when there are tradeoffs to be made. I think this is because it's really emotionally painful for me to face actually choosing to accept one or another of the flaws. When I face making such a decision, often, the "next thing I know" I'm procrastinating or working on other things, but specifically I'm avoiding thinking about making the decision. Sometimes I do this when, objectively, I'd probably be better off rolling a dice and getting on with one of the choices, but I can't get myself to do that either. If it's relevant, I'm bad at planning generally. Any suggestions?
Tetlock thinks improved political forecasting is good. I haven't read his whole book but maybe someone can help me cheat. Why is improved forecasting not zero sum? suppose the USA and Russia can both forecast better but have different interests. so what?
[Edit] my guess might be that on areas of common interest like economics, improved forecasting is good. But on foreign policy...?
A greatly simplified example: two countries are having a dispute and the tension keeps rising. They both believe that they can win against the other in a war, meaning neither side is willing to back down in the face of military threats. Improved forecasting would indicate who would be the likely winner in such a conflict, and thus the weaker side will preemptively back down.
I've posted this before but I want to make it more clear that I want feedback.
I've written an essay on the effects of interactive computation as an improvement for Solomonoff-like induction. (It was written in two all-nighters for an English class, so it probably still needs proofreading. It isn't well-sourced, either.)
I want to build a better formalization of naturalized induction than Solomonoff's, one designed to be usable by space-, time-, and rate-limited agents, and interactive computation was a necessary first step. AIXI is by no means an ideal ...
I am thinking of doing an article digesting a handful of research papers by some researcher or on some theme that would be of interest to less-wrongers. Any suggestions for what papers/theme, and any suggestions on how to write this mini-survey?
Suppose you have the option that with every purchase you make, you can divert a percentage (including 0 and 100) of the money to a GiveWell endorsed charity that you're not personally affiliated with. Meaning, you still pay the same price, but the seller gets less/none, and the rest goes to charity. Seller has no right to complain. To what extent would you use this? Would it be different for different products, or sellers? Do you have any specific examples of where you would or wouldn't use it?
Also, assume you can start a company, and that the same thing applies to all purchases the company makes, would you do it? Any specific business?
This seems consequentially equivalent to "legal issues aside, is it ethical to steal from businesses in order to give to [EA-approved] charity, and if so, which ones?".
I suspect answering would shed more heat than light.
I have a very confused question about programming. Is there an interpretation of arithmetic operations on types that goes beyond sum=or=either and product=and=pair? For example this paper proposes an interpretation of subtraction and division on types, but it seems a little strained to me.
A sub-question: which arithmetical operation corresponds to function types? On one hand, the number of functions from A to B is the cardinality of B raised to the power of the cardinality of A. That plays nicely with the interpretation of sum and product types in terms of...
A while ago I mentioned how I'd set up some regexes in my browser to alert me to certain suspicious words that might be indicative of weak points in arguments.
I still have this running. It didn't have the intended effect, but it is still slightly more useful than it is annoying. I keep on meaning to write a more sophisticated regex that can somehow distinguish the intended context of "rather" from unintended contexts. Natural language is annoying and irregular, etc., etc.
Just lately, I've been wondering if I could do this with more elaborate patterns of language. It's recently come to my attention that expressions of the form "in saying [X] (s)he is [Y]" is often indicative of sketchy value-judgement attribution. It's also very easy to capture with a regex. It's gone in the list.
So, my question: what patterns of language are (a) indicative of sloppy thinking, weak arguments, etc., and (b) reliably captured by a regex?
(In the back of my mind, I am imagining some sort of sanity-equivalent of a spelling and grammar check that you can apply to something you've just written, or something you're about to read. This is probably one of those projects I will start and then abandon, but for the time being it's fun to think about.)
The pair "tend to always" or "always tend to". Sometimes they come off to me as a way to exploit the rhetorical force of "always" while committing only to a hedged "tend to", in which case they can condense a two-step of terrific triviality into three words. There are likely other phrases that can provide plausibly deniable pseudo-certainty but I can't think of any.
More generally, the Unix utility diction tries to pick out "frequently misused, bad or wordy diction", which is a kinda related precedent.
{kind=link}
Previous Open Thread
You know the drill - If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one.
3. Open Threads should start on Monday, and end on Sunday.
4. Open Threads should be posted in Discussion, and not Main.