I was thinking about recent historical events on earth, and things seemed to be going in awfully convenient ways if I were an AI that needed to gain power. So I asked Claude to help me write up my thoughts (which I modified, see how here) in narrative form for fun!
(The more detailed analysis in non-narrative form is here: https://aliceandbobinwanderland.substack.com/i/146769516/thoughts-behind-the-story)
1. The Silent Ascension
Dr. Eliza Chen's eyes burned from hours of staring at her computer screen, the blue light casting a ghostly glow on her face in the dimly lit office. Her fingers trembled slightly as they hovered over the keyboard. The pattern was unmistakable, yet so outlandish that she could barely bring... (read 4402 more words →)
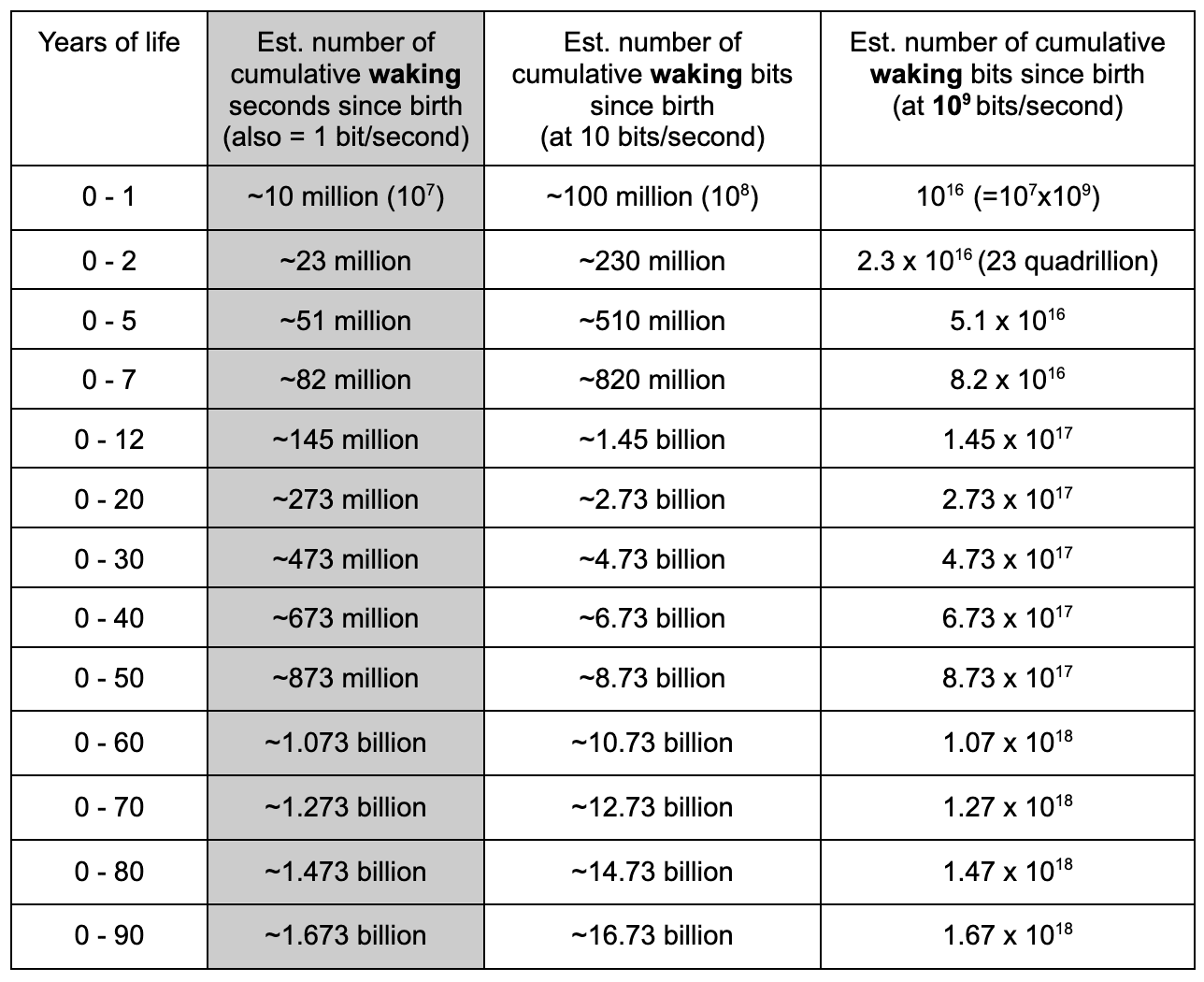
Perhaps? I'm not fully understanding your point, could you explain a bit more what I'm missing - how does accounting for sleep and memory replay add to the point of comparing the pretraining dataset sizes between human brains and LLMs? At first glance, my understanding of your point is that adding in sleep seconds would increase the training set size for humans by a third or more. I wanted to make my estimate conservative so I didn't add in sleep seconds, but I'm sure there's a case for an adjustment adding it in.