All of Andrew_Critch's Comments + Replies
The evidence you present in each case is outputs generated by LLMs.
The total evidence I have (and that everyone has) is more than behavioral. It includes
a) the transformer architecture, in particular the attention module,
b) the training corpus of human writing,
c) the means of execution (recursive calling upon its own outputs and history of QKV vector representations of outputs),
d) as you say, the model's behavior, and
e) "artificial neuroscience" experiments on the model's activation patterns and weights, like mech interp research.
When I think about how...
A patient can hire us to collect their medical records into one place, to research a health question for them, and to help them prep for a doctor's appointment with good questions about the research. Then we do that, building and using our AI tool chain as we go, without training AI on sensitive patient data. Then the patient can delete their data from our systems if they want, or re-engage us for further research or other advocacy on their behalf.
A good comparison is the company Picnic Health, except instead of specifically matching patients with clinical trials, we do more general research and advocacy for them.
Do you have a mostly disjoint view of AI capabilities between the "extinction from loss of control" scenarios and "extinction by industrial dehumanization" scenarios?
a) If we go extinct from a loss of control event, I count that as extinction from a loss of control event, accounting for the 35% probability mentioned in the post.
b) If we don't have a loss of control event but still go extinct from industrial dehumanization, I count that as extinction caused by industrial dehumanization caused by successionism, accounting for the additional 50% probabilit...
I very much agree with human flourishing as the main value I most want AI technologies to pursue and be used to pursue.
In that framing, my key claim is that in practice no area of purely technical AI research — including "safety" and/or "alignment" research — can be adequately checked for whether it will help or hinder human flourishing, without a social model of how the resulting techologies will be used by individuals / businesses / governments / etc..
I may be missing context here, but as written / taken at face value, I strongly agree with the above comment from Richard. I often disagree with Richard about alignment and its role in the future of AI, but this comment is an extremely dense list of things I agree with regarding rationalist epistemic culture.
I'd love to read an elaboration of your perspective on this, with concrete examples, which avoids focusing on the usual things you disagree about (pivotal acts vs. pivotal processes, social facets of the game is important for us to track, etc.) and mainly focus on your thoughts on epistemology and rationality and how it deviates from what you consider the LW norm.
I'm afraid I'm sceptical that you methodology licenses the conclusions you draw.
Thanks for raising this. It's one of the reasons I spelled out my methodology, to the extent that I had one. You're right that, as I said, my methodology explicitly asks people to pay attention to the internal structure of what they were experiencing in themselves and calling consciousness, and to describe it on a process level. Personally I'm confident that whatever people are managing to refer to by "consciousness" is a process than runs on matter. If ...
Thanks for the response.
Personally I'm confident that whatever people are managing to refer to by "consciousness" is a process than runs on matter
I don't disagree that consciousness is a process that runs on matter, but that is a separate question from whether the typical referent of consciousness is that process. If it turned out my consciousness was being implemented on a bunch of grapes it wouldn't change what I am referring to when I speak of my own consciousness. The referents are the experiences themselves from a first-person perspective.
...I asked peop
The “hard problem of consciousness” is the problem of resolving a linguistic dispute disguised as an ontological one, where people agree on the normative properties of consciousness (it’s valuable) but on its descriptive properties (its nature as a process/pattern.)
That's just another conflation - of an easy and the hard problem - yes, there is disagreement about what mental processes are valuable, but there is also ontological problem and not everyone agree that ontological consciousness is intrinsically valuable.
I totally agree with the potential for confusion here!
My read is that the LessWrong community has too low of a prior on social norms being about membranes (e.g., when, how, and how not to cross various socially constructed information membranes). Using the term "boundaries" raises the prior on the hypothesis "social norms are often about boundaries", which I endorse and was intentional on my part, specifically for the benefit of LessWrong readership base (especially the EA community) who seemed to pay too little attention to the importance of <<boun...
Nice catch! Now replaced by 'deliberate'.
Thanks for sharing this! Because of strong memetic selection pressures, I was worried I might be literally the only person posting on this platform with that opinion.
FWIW I think you needn't update too hard on signatories absent from the FLI open letter (but update positively on people who did sign). Statements about AI risk are notoriously hard to agree on for a mix of political reasons. I do expect lab leads to eventually find a way of expressing more concerns about risks in light of recent tech, at least before the end of this year. Please feel free to call me "wrong" about this at the end of 2023 if things don't turn out that way.
Do you have a success story for how humanity can avoid this outcome? For example what set of technical and/or social problems do you think need to be solved? (I skimmed some of your past posts and didn't find an obvious place where you talked about this.)
I do not, but thanks for asking. To give a best efforts response nonetheless:
David Dalrymple's Open Agency Architecture is probably the best I've seen in terms of a comprehensive statement of what's needed technically, but it would need to be combined with global regulations limiting compute expendit...
In a previous comment you talked about the importance of "the problem of solving the bargaining/cooperation/mutual-governance problem that AI-enhanced companies (and/or countries) will be facing". I wonder if you've written more about this problem anywhere, and why you didn't mention it again in the comment that I'm replying to.
My own thinking about 'the ~50% extinction probability I’m expecting from multi-polar interaction-level effects coming some years after we get individually “safe” AGI systems up and running' is that if we've got "safe" AGIs, we coul...
That is, norms do seem feasible to figure out, but not the kind of thing that is relevant right now, unfortunately.
From the OP:
for most real-world-prevalent perspectives on AI alignment, safety, and existential safety, acausal considerations are not particularly dominant [...]. In particular, I do not think acausal normalcy provides a solution to existential safety, nor does it undermine the importance of existential safety in some surprising way.
I.e., I agree.
...we are so unprepared that the existing primordial norms are unlikely to matter
For 18 examples, just think of 3 common everyday norms having to do with each of the 6 boundaries given as example images in the post :) (I.e., cell membranes, skin, fences, social group boundaries, internet firewalls, and national borders). Each norm has the property that, when you reflect on it, it's easy to imagine a lot of other people also reflecting on the same norm, because of the salience of the non-subjectively-defined actual-boundary-thing that the norm is about. That creates more of a Schelling-nature for that norm, relative to...
To your first question, I'm not sure which particular "the reason" would be most helpful to convey. (To contrast: what's "the reason" that physically dispersed human societies have laws? Answer: there's a confluence of reasons.). However, I'll try to point out some things that might be helpful to attend to.
First, committing to a policy that merges your utility function with someone else's is quite a vulnerable maneuver, with a lot of boundary-setting aspects. For instance, will you merge utility functions multiplicatively (as in Nas...
This is cool (and fwiw to other readers) correct. I must reflect on what it means for real world cooperation... I especially like the A <-> []X -> [][]X <-> []A trick.
I'm working on it :) At this point what I think is true is the following:
If ShortProof(x \leftrightarrow LongProof(ShortProof(x) \to x)), then MediumProof(x).
Apologies that I haven't written out calculations very precisely yet, but since you asked, that's roughly where I'm at :)
Actually the interpretation of \Box_E as its own proof system only requires the other systems to be finite extenions of PA, but I should mention that requirement! Nonetheless even if they're not finite, everything still works because \Box_E still satisfies necessitation, distributivity, and existence of modal fixed points.
Thanks for bringing this up.
Based on a potential misreading of this post, I added the following caveat today:
Important Caveat: Arguments in natural language are basically never "theorems". The main reason is that human thinking isn't perfectly rational in virtually any precisely defined sense, so sometimes the hypotheses of an argument can hold while its conclusion remains unconvincing. Thus, the Löbian argument pattern of this post does not constitute a "theorem" about real-world humans: even when the hypotheses of the argument hold, the argument will not always play out...
Thanks! Added a note to the OP explaining that hereby means "by this utterance".
Hat tip to Ben Pace for pointing out that invitations are often self-referential, such as when people say "You are hereby invited", because "hereby" means "by this utterance":
https://www.lesswrong.com/posts/rrpnEDpLPxsmmsLzs/open-technical-problem-a-quinean-proof-of-loeb-s-theorem-for?commentId=CFvfaWGzJjnMP8FCa
That comment was like 25% of my inspiration for this post :)
I've now fleshed out the notation section to elaborate on this a bit. Is it better now?
...In short, is our symbol for talking about what PA can prove, and is shorthand for PA's symbols for talking about what (a copy of) PA can prove.
- " 1+1=2" means "Peano Arithmetic (PA) can prove that 1+1=2". No parentheses are needed; the "" applies to the whole line that follows it. Also, does not stand for an expression in PA; it's a symbol we use to talk about what PA can prove.
- "" basically means the sam
Well, the deduction theorem is a fact about PA (and, propositional logic), so it's okay to use as long as means "PA can prove".
But you're right that it doesn't mix seamlessly with the (outer) necessitation rule. Necessitation is a property of "", but not generally a property of "". When PA can prove something, it can prove that it can prove it. By contrast, if PA+X can prove Y, that does mean that PA can prove that PA+X can prove Y (because PA alone can work through proofs in a Gödel encoding), but it doesn't mean that PA+...
Well, is just short for , i.e., "(not A) or B". By contrast, means that there exists a sequence of (very mechanical) applications of modus ponens, starting from the axioms of Peano Arithmetic (PA) with appended, ending in . We tried hard to make the rules of so that it would agree with in a lot of cases (i.e., we tried to design to make the deduction theorem true), but it took a lot of work in the design of Peano Arithmetic and can't be taken for gr...
It's true that the deduction theorem is not needed, as in the Wikipedia proof. I just like using the deduction theorem because I find it intuitive (assume , prove , then drop the assumption and conclude ) and it removes the need for lots of parentheses everywhere.
I'll add a note about the meaning of so folks don't need to look it up, thanks for the feedback!
It did not get accross! Interesting. Procedurally I still object to calling people's arguments "crazy", but selfishly I guess I'm glad they were not my arguments? At a meta level though I'm still concerned that LessWrong culture is too quick to write off views as "crazy". Even the the "coordination is delusional"-type views that Katja highlights in her post do not seem "crazy" to me, more like misguided or scarred or something, in a way that warrants a closer look but not being called "crazy".
Oliver, see also this comment; I tried to @ you on it, but I don't think LessWrong has that functionality?
Separately from my other reply explaining that you are not the source of what I'm complaining about here, I thought I'd add more color to explain why I think my assessment here is not "hyperbolic". Specifically, regarding your claim that reducing AI x-risk through coordination is "not only fine to suggest, but completely uncontroversial accepted wisdom", please see the OP. Perhaps you have not witnessed such conversations yourself, but I have been party to many of these:
...Some people: AI might kill everyone. We should design a godlike super-AI of
Thanks, Oliver. The biggest update for me here — which made your entire comment worth reading, for me — was that you said this:
I also think it's really not true that coordination has been "fraught to even suggest".
I'm surprised that you think that, but have updated on your statement at face value that you in fact do. By contrast, my experience around a bunch common acquaintances of ours has been much the same as Katja's, like this:
...Some people: AI might kill everyone. We should design a godlike super-AI of perfect goodness to prevent that.
Others
This makes sense to me if you feel my comment is meant as a description of you or people-like-you. It is not, and quite the opposite. As I see it, you are not a representative member of the LessWrong community, or at least, not a representative source of the problem I'm trying to point at. For one thing, you are willing to work for OpenAI, which many (dozens of) LessWrong-adjacent people I've personally met would consider a betrayal of allegiance to "the community". Needless to say, the field of AI governance as it exists is not unc...
It would help if you specified which subset of "the community" you're arguing against. I had a similar reaction to your comment as Daniel did, since in my circles (AI safety researchers in Berkeley), governance tends to be well-respected, and I'd be shocked to encounter the sentiment that working for OpenAI is a "betrayal of allegiance to 'the community'".
Katja, many thanks for writing this, and Oliver, thanks for this comment pointing out that everyday people are in fact worried about AI x-risk. Since around 2017 when I left MIRI to rejoin academia, I have been trying continually to point out that everyday people are able to easily understand the case for AI x-risk, and that it's incorrect to assume the existence of AI x-risk can only be understood by a very small and select group of people. My arguments have often been basically the same as yours here: in my case, informal conversations with U...
Critch, I agree it’s easy for most people to understand the case for AI being risky. I think the core argument for concern—that it seems plausibly unsafe to build something far smarter than us—is simple and intuitive, and personally, that simple argument in fact motivates a plurality of my concern. That said:
- I think it often takes weirder, less intuitive arguments to address many common objections—e.g., that this seems unlikely to happen within our lifetimes, that intelligence far superior to ours doesn’t even seem possible, that we’re safe because softwar
I think it's uncharitable to psychoanalyze why people upvoted John's comment; his object-level point about GoF seems good and merits an upvote IMO. Really, I don't know what to make of GoF. It's not just that governments have failed to ban it, they haven't even stopped funding it, or in the USA case they stopped funding it and then restarted I think. My mental models can't explain that. Anyone on the street can immediately understand why GoF is dangerous. GoF is a threat to politicians and national security. GoF has no upsides that stand up to scrutiny, an...
The question feels leading enough that I don't really know how to respond. Many of these sentences sound pretty crazy to me, so I feel like I primarily want to express frustration and confusion that you assign those sentences to me or "most of the LessWrong community".
...However, for some reason, the idea that people outside the LessWrong community might recognize the existence of AI x-risk — and therefore be worth coordinating with on the issue — has felt not only poorly received on LessWrong, but also fraught to even suggest. For instance, I tried to poi
However, for some reason, the idea that people outside the LessWrong community might recognize the existence of AI x-risk — and therefore be worth coordinating with on the issue — has felt not only poorly received on LessWrong, but also fraught to even suggest.
I object to this hyperbolic and unfair accusation. The entire AI Governance field is founded on this idea; this idea is not only fine to suggest, but completely uncontroversial accepted wisdom. That is, if by "this idea" you really mean literally what you said -- "people outside the LW community migh...
That particular statement was very poorly received, with a 139-karma retort from John Wentworth arguing,
What exactly is the model by which some AI organization demonstrating AI capabilities will lead to world governments jointly preventing scary AI from being built, in a world which does not actually ban gain-of-function research?
I’m not sure what’s going on here
So, wait, what’s actually the answer to this question? I read that entire comment thread and didn’t find one. The question seems to me to be a good one!
I agree this is a big factor, and might be the main pathway through which people end up believing what people believe the believe. If I had to guess, I'd guess you're right.
E.g., if there's a evidence E in favor of H and evidence E' against H, if the group is really into thinking about and talking about E as a topic, then the group will probably end up believing H too much.
I think it would be great if you or someone wrote a post about this (or whatever you meant by your comment) and pointed to some examples. I think the LessWrong community is somewhat plagued by attentional bias leading to collective epistemic blind spots. (Not necessarily more than other communities; just different blind spots.)
Ah, thanks for the correction! I've removed that statement about "integrity for consequentialists" now.
I've searched my memory for the past day or so, and I just wanted to confirm that the "ever" part of my previous message was not a hot take or exaggeration.
I'm not sure what to do about this. I am mulling.
This piece of news is the most depressing thing I've seen in AI since... I don't know, ever? It's not like the algorithms for doing this weren't lying around already. The depressing thing for me is that it was promoted as something to be proud of, with no regard for the framing implication that cooperative discourse exists primarily in service of forming alliances to exterminate enemies.
I've searched my memory for the past day or so, and I just wanted to confirm that the "ever" part of my previous message was not a hot take or exaggeration.
I'm not sure what to do about this. I am mulling.
Thanks for raising this! I assume you're talking about this part?

They explore a pretty interesting set-up, but they don't avoid the narrowly-self-referential sentence Ψ:
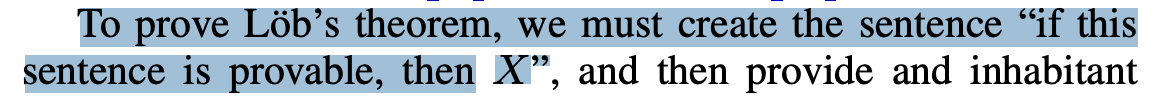
So, I don't think their motivation was the same as mine. For me, the point of trying to use a quine is to try to get away from that sentence, to create a different perspective on the foundations for people that find that kind of sentence confusing, but who find self-referential documents less confusing. I added a section "Further meta-motivation (added Nov 26)" about this ...
At this point I'm more interested in hashing out approaches that might actually conform to the motivation in the OP. Perhaps I'll come back to this discussion with you after I've spent a lot more time in a mode of searching for a positive result that fits with my motivation here. Meanwhile, thanks for thinking this over for a bit.
True! "Hereby" covers a solid contingent of self-referential sentences. I wonder if there's a "hereby" construction that would make the self-referential sentence Ψ (from the Wikipedia poof) more common-sense-meaningful to, say, lawyers.
this suggests that you're going to be hard-pressed to do any self-reference without routing through the nomal machinery of löb's theorem, in the same way that it's hard to do recursion in the lambda calculus without routing through the Y combinator
If by "the normal machinery", you mean a clever application of the diagonal lemma, then I agree. But I think we can get away with not having the self-referential sentence, by using the same y-combinator-like diagonal-lemma machinery to make a proof that refers to itself (instead of a proof about sentences t...
This sentence is an exception, but there aren't a lot of naturally occurring examples.
No strong claim either way, but as a datapoint I do somewhat often use the phrase "I hereby invite you to <event>" or "I hereby <request> something of you" to help move from 'describing the world' to 'issuing an invitation/command/etc'.
Thanks for your attention to this! The happy face is the outer box. So, line 3 of the cartoon proof is assumption 3.
If you want the full []([]C->C) to be inside a thought bubble, then just take every line of the cartoon and put into a thought bubble, and I think that will do what you want.
LMK if this doesn't make sense; given the time you've spent thinking about this, you're probably my #1 target audience member for making the more intuitive proof (assuming it's possible, which I think it is).
ETA: You might have been asking if th...
Yes to both of you on these points:
- Yes to Alex that (I think) you can use an already-in-hand proof of Löb to make the self-referential proof work, and
- Yes to Eliezer that that would be cheating wouldn't actually ground out all of the intuitions, because then the "santa clause"-like sentence is still in use in already-in-hand proof of Löb.
(I'll write a separate comment on Eliezer's original question.)
That thing is hilarious and good! Thanks for sharing it. As for the relevance, it explains the statement of Gödel's theorem, but not the proof it. So, it could be pretty straightforwardly reworked to explain the statement of Löb's theorem, but not so easily the proof of Löb's theorem. With this post, I'm in the business of trying to find a proof of Löb that's really intuitive/simple, rather than just a statement of it that's intuitive/simple.
Why is it unrealistic? Do you actually mean it's unrealistic that the set I've defined as "A" will be interpretable at "actions" in the usual coarse-grained sense? If so I think that's a topic for another post when I get into talking about the coarsened variables ...
Going further, my proposed convention also suggests that "Cartesian frames" should perhaps be renamed to "Cartesian factorizations", which I think is a more immediately interpretable name for what they are. Then in your equation , you can refer to and as "Cartesian factors", satisfying your desire to treat and as interchangeable. And, you leave open the possibility that the factors are derivable from a "Cartesian partition" of the world into the "Cartesian parts" &n...
Scott, thanks for writing this! While I very much agree with the distinctions being drawn, I think the word "boundary" should be usable for referring to factorizations that do not factor through the physical separation of the world into objects. In other words, I want the technical concept of «boundaries» that I'm developing to be able to refer to things like social boundaries, which are often not most-easily-expressed in the physics factorization of the world into particles (but are very often expressible as Markov blankets in a more abstract ...
Thanks, Scott!
I think the boundary factorization into active and passive is wrong.
Are you sure? The informal description I gave for A and P allow for the active boundary to be a bit passive and the passive boundary to be a bit active. From the post:
...the active boundary, A — the features or parts of the boundary primarily controlled by the viscera, interpretable as "actions" of the system— and the passive boundary, P — the features or parts of the boundary primarily controlled by the environment, interpretable as "perceptions" of the
Thanks, fixed!
Cool! This was very much in line with the kind of update I was aiming for here, cheers :)
Huh, weird. I read Eliezer's definition of meta-honesty as not the same thing as your definition of «honesty that is closed under reflection». Specifically, in Eliezer-meta-honesty, his honesty at the meta-level is stronger (i.e., zero tolerance for lies) than his honesty at the object level (some tolerance for lies), whereas your notion sounds like it has no such strengthening-as-you-go-up-in-meta pattern to it. Am I misunderstanding you?
Thanks Anna for posting this! I agree with your hypothesis, and would add that shaming humans for not being VNM agents is probably a contributor to AI risk because of the cultural example it sets / because of the self-fulling prophesy of how-intelligence-gets-used that it supports.