All of DaemonicSigil's Comments + Replies
Some experimental data: https://chatgpt.com/share/67ce164f-a7cc-8005-8ae1-98d92610f658
There's not really anything wrong with ChatGPT's attempt here, but it happens to have picked the same topic as a recent Numberphile video, and I think it's instructive to compare how they present the same topic: https://www.numberphile.com/videos/a-1-58-dimensional-object
My view on this is that writing a worthwhile blog post is not only a writing task, but also an original seeing task. You first have to go and find something out in the world and learn about it before you can write about it. So the obstacle is not necessarily reasoning ("look at this weird rock I found" doesn't involve much reasoning, but could make a good blog post), but a lack of things to say.
There's not any principled reason why an AI system, even a LLM in particular, couldn't do this. There is plenty going on in the world to go and find out, even if yo...
Even comment-writing is to a large extent an original seeing task, when all the relevent context would otherwise seem to be more straightforward to assemble than when writing the post itself unprompted. A good comment to a post is not a review of the whole post. It finds some point in it, looks at it in a particular way, and finds that there is a relevant observation to be made about it.
Crucially, a comment won't be made at all if such a relevant observation wasn't found, or else you get slop even when the commenter is human ("Great post!"). Chatbots did already achieve parity with a significant fraction of reddit-level comments (but not posts) I think, which are also not worth reading.
Thanks for the reply & link. I definitely missed that paragraph, whoops.
IMO even just simple gamete selection would be pretty great for avoiding the worst genetic diseases. I guess tracking nuclei with a microscope is way more feasible than the microwell thing, given how hard it looks to make IVS work at all.
I think the numbers just kind of suck. I didn't go into them much because gamete selection seems largely hypothetical. Like, the procedure here seems kinda expensive per-spermatocyte (guy who divides into 4 sperm). I gesture at how to compute it here: https://www.lesswrong.com/posts/2w6hjptanQ3cDyDw7/methods-for-strong-human-germline-engineering#The_power_of_single_gamete_selection
To give some numbers, consider 10k sperm. We look in the embryo selection powers:
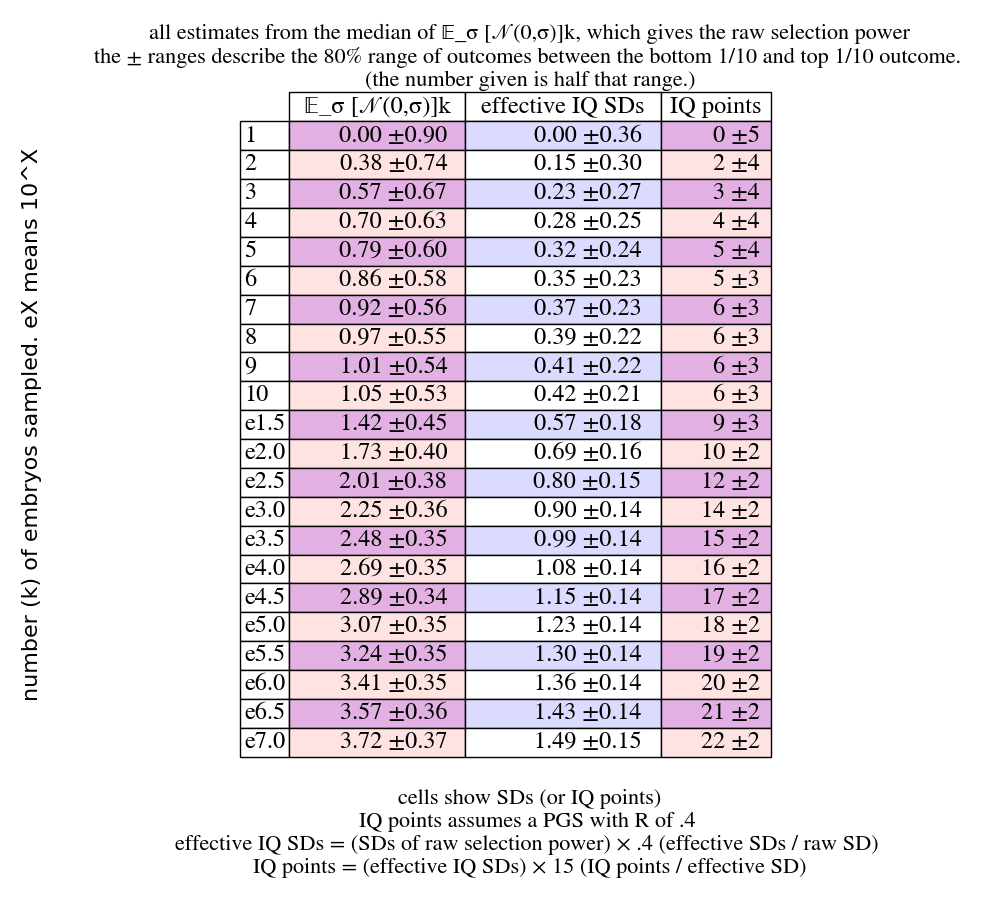
For 10k, i.e. e4.0, you get about 2.7 raw SDs, for embros; for sperm you multiply by the sperm SD...
Re the "Appendix: Cheap DNA segment sensing" section, just going to throw out a thought that occurred to me (very much a non-expert). Let's say we're doing IVS, and assume we can separate spermatocytes into separate microwells before they undergo meiosis. The starting cells all have a known genome. Then the cell in each microwell divides into 4 cells. If we sequence 3 of them, then we know by process of elimination what the sequence on the 4th cell is, at a very high level of detail, including crossovers, etc. So we kill 3 cells and look at their DNA, and ...
Yep, this is the standard first "clever person starts thinking about nondestructive sequencing" thing. E.g. I wrote about it here: https://tsvibt.blogspot.com/2022/06/non-destructively-sequencing-gametes-by.html and Gwern mentions it. It's addressed in the present article here:
...In theory one could do "entanglement sequencing", wherein you capture the four meiotic "grandchildren" of a single gametogonium (progenitor stem cell that produces gametes). This is impractical as far as I know, because both oogenesis and spermatogenesis are complex and all but req
This was a fun little exercise. We get many "theory of rationality" posts on this site, so it's very good to also have some chances to practice figuring out confusing things also mixed in. The various coins each teach good lessons about ways the world can surprise you.
Anyway, I think this was an underrated post, and we need more posts in this general category.
Running parallel to the spin axis would be fine, though.
Anthropic shadow isn't a real thing, check this post: https://www.lesswrong.com/posts/LGHuaLiq3F5NHQXXF/anthropically-blind-the-anthropic-shadow-is-reflectively
Also, you should care about worlds proportional to the square of their amplitude.
Thanks for making the game! I also played it, just didn't leave a comment on the original post. Scored 2751. I played each location for an entire day after building an initial food stockpile, and so figured out the timing of Tiger Forest and Dog Valley. But I also did some fairly dumb stuff, like assuming a time dependence for other biomes. And I underestimated Horse Hills, since when I foraged it for a full day, I got unlucky and only rolled a single large number. For what it's worth, I find these applet things more accessible than a full-on D&D.Sci (...
Have to divide by number of airships, which probably makes them less safe than planes, if not cars. I think the difficulty is mostly with having a large surface-area exposed to the wind making the ships difficult to control. (Edit: looking at the list on Wikipedia, this is maybe not totally true. A lot of the crashes seem to be caused by equipment failures too.)
Are those things that you care about working towards?
No, and I don't work on airships and have no plans to do so. I mainly just think it's an interesting demonstration of how weak electrostatic forces can be.
Yep, Claude sure is a pretty good coder: Wang Tile Pattern Generator
This took 1 initial write and 5 change requests to produce. The most manual effort I had to do was look at unicode ranges and see which ones had distinctive-looking glyphs in them. (Sorry if any of these aren't in your computer's glyph library.)
I've begun worshipping the sun for a number of reasons. First of all, unlike some other gods I could mention, I can see the sun. It's there for me every day. And the things it brings me are quite apparent all the time: heat, light, food, and a lovely day. There's no mystery, no one asks for money, I don't have to dress up, and there's no boring pageantry. And interestingly enough, I have found that the prayers I offer to the sun and the prayers I formerly offered to 'God' are all answered at about the same 50% rate.
-- George Carlin
Everyone who earns money exerts some control by buying food or whatever else they buy. This directs society to work on producing those goods and services. There's also political/military control, but it's also (a much narrower set of) humans who have that kind of control too.
Okay, I'll be the idiot who gives the obvious answer: Yeah, pretty much.
Very nice post, thanks for writing it.
Your options are numbered when you refer to them in the text, but are listed as bullet points originally. Probably they should also be numbered there!
Now we can get down to the actual physics discussion. I have a bag of fairly unrelated statements to make.
-
The "center of mass moves at constant velocity" thing is actually just as solid as, say, conservation of angular momentum. It's just less famous. Both are consequences of Noether's theorem, angular momentum conservation arising from symmetry under rotations and the
Good point, the whole "model treats tokens it previously produced and tokens that are part of the input exactly the same" thing and the whole "model doesn't learn across usages" thing are also very important.
When generating each token, they "re-read" everything in the context window before predicting. None of their internal calculations are preserved when predicting the next token, everything is forgotten and the entire context window is re-read again.
Given that KV caching is a thing, the way I chose to phrase this is very misleading / outright wrong in retrospect. While of course inference could be done in this way, it's not the most efficient, and one could even make a similar statement about certain inefficient ways of simulating a person's thoughts.
If I...
Let's say we have a bunch of datapoints in that are expected to lie on some lattice, with some noise in the measured positions. We'd like to fit a lattice to these points that hopefully matches the ground truth lattice well. Since just by choosing a very fine lattice we can get an arbitrarily small error without doing anything interesting, there also needs to be some penalty on excessively fine lattices. This is a bit of a strange problem, and an algorithm for it will be presented here.
method
Since this is a lattice problem, the first question to jump ...
Cool, Facebook is also on this apparently: https://x.com/PicturesFoIder/status/1840677517553791440
This might be worth pinning as a top-level post.
The amount of entropy in a given organism stays about the same, though I guess you could argue it increases as the organism grows in size. Reason: The organism isn't mutating over time to become made of increasingly high entropy stuff, nor is it heating up. The entropy has to stay within an upper and lower bound. So over time the organism will increase entropy external to itself, while the internal entropy doesn't change very much, maybe just fluctuates within the bounds a bit.
It's probably better to talk about entropy per unit mass, rather than entropy de...
Speaking of which, I wonder if multi-modal transformers have started being used by blind people yet. Since we have models that can describe images, I wonder if it would be useful for blind people to have a device with a camera and a microphone and a little button one can press to get it to describe what the camera is seeing. Surely there are startups working on this?
Yes. See Be my AI.
a device with a camera and a microphone and a little button
Why the retrofuturistic description of a smartphone?
Found this paper on insecticide costs: https://sci-hub.st/http://dx.doi.org/10.1046/j.1365-2915.2000.00262.x
It's from 2000, so anything listed here would be out of patent today.
hardening voltage transformers against ionising radiation
Is ionization really the mechanism by which transformers fail in a solar storm? I thought it was that changes in the Earth's magnetic field induced large currents in long transmission lines, overloading the transformers.
Sorry for the self promotion, but some folks may find this post relevant: https://www.lesswrong.com/posts/uDXRxF9tGqGX5bGT4/logical-share-splitting (ctl-F for "Application: Conditional prediction markets")
tldr: Gives a general framework that would allow people to make this kind of trade with only $N in capital, just as a natural consequence of the trading rules of the market.
Anyway, I definitely agree that Manifold should add the feature you describe! (As for general logical share splitting, well, it would be nice, but probably far too much work to convert the existing codebase over.)
IMO, a very good response, which Eliezer doesn't seem to be interested in making as far as I can tell, is that we should not be making the analogy natural selection <--> gradient descent, but rather, human brain learning algorithm <--> gradient descent ; natural selection <--> us trying to build AI.
So here, the striking thing is that evolution failed to solve the alignment problem for humans. I.e. we have a prior example of strongish general intelligence being created, but no prior examples of strongish general intelligence being aligne...
People here might find this post interesting: https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d
The author argues that search algorithms will play a much larger role in AI in the future than they do today.
I remember reading the EJT post and left some comments there. The basic conclusions I arrived at are:
- The transitivity property is actually important and necessary, one can construct money-pump-like situations if it isn't satisfied. See this comment
- If we keep transitivity, but not completeness, and follow a strategy of not making choices inconsistent with out previous choices, as EJT suggests, then we no longer have a single consistent utility function. However, it looks like the behaviour can still be roughly described as "picking a utility function at
If you're working with multidimensional tensors (eg. in numpy or pytorch), a helpful pattern is often to use pattern matching to get the sizes of various dimensions. Like this: batch, chan, w, h = x.shape. And sometimes you already know some of these dimensions, and want to assert that they have the correct values. Here is a convenient way to do that. Define the following class and single instance of it:
class _MustBe:
""" class for asserting that a dimension must have a certain value.
the class itself is private, one should import a particular objOh, very cool, thanks! Spoiler tag in markdown is:
:::spoiler
text here
:::
Heh, sure.
Promote from a function to a linear operator on the space of functions, . The action of this operator is just "multiply by ". We'll similarly define meaning to multiply by the first, second integral of , etc.
Observe:
Now we can calculate what we get when applying times. The calculation simplifies when we note that all terms are of the form . Result:
Now we apply the above operator to :
The sum terminates b
Use integration by parts:
Then is another polynomial (of smaller degree), and is another "nice" function, so we recurse.
Other people have mentioned sites like Mechanical Turk. Just to add another thing in the same category, apparently now people will pay you for helping train language models:
https://www.dataannotation.tech/faq?
Haven't tried it yet myself, but a roommate of mine has and he seems to have had a good experience. He's mentioned that sometimes people find it hard to get assigned work by their algorithm, though. I did a quick search to see what their reputation was, and it seemed pretty okay:
...Linkpost for: https://pbement.com/posts/threads.html
Today's interesting number is 961.
Say you're writing a CUDA program and you need to accomplish some task for every element of a long array. Well, the classical way to do this is to divide up the job amongst several different threads and let each thread do a part of the array. (We'll ignore blocks for simplicity, maybe each block has its own array to work on or something.) The method here is as follows:
for (int i = threadIdx.x; i < array_len; i += 32) {
arr[i] = ...;
}
So the threads make the foll...
So once that research is finished, assuming it is successful, you'd agree that many worlds would end up using fewer bits in that case? That seems like a reasonable position to me, then! (I find the partial-trace kinds of arguments that people make pretty convincing already, but it's reasonable not to.)
MW theories have to specify when and how decoherence occurs. Decoherence isn't simple.
They don't actually. One could equally well say: "Fundamental theories of physics have to specify when and how increases in entropy occur. Thermal randomness isn't simple." This is wrong because once you've described the fundamental laws and they happen to be reversible, and also aren't too simple, increasing entropy from a low entropy initial state is a natural consequence of those laws. Similarly, decoherence is a natural consequence of the laws of quantum mechanics (with a not-too-simple Hamiltonian) applied to a low entropy initial state.
Good post, and I basically agree with this. I do think it's good to mostly focus on the experimental implications when talking about these things. When I say "many worlds", what I primarily mean is that I predict that we should never observe a spontaneous collapse, even if we do crazy things like putting conscious observers into superposition, or putting large chunks of the gravitational field into superposition. So if we ever did observe such a spontaneous collapse, that would falsify many worlds.
Amount of calculation isn't so much the concern here as the amount of bits used to implement that calculation. And there's no law that forces the amount of bits encoding the computation to be equal. Copenhagen can just waste bits on computations that MWI doesn't have to do.
In particular, I mentioned earlier that Copenhagen has to have rules for when measurements occur and what basis they occur in. How does MWI incur a similar cost? What does MWI have to compute that Copenhagen doesn't that uses up the same number of bits of source code?
Like, yes, an expect...
Right, so we both agree that the randomness used to determine the result of a measurement in Copenhagen, and the information required to locate yourself in MWI is the same number of bits. But the argument for MWI was never that it had an advantage on this front, but rather that Copenhagen used up some extra bits in the machine that generates the output tape in order to implement the wavefunction collapse procedure. (Not to decide the outcome of the collapse, those random bits are already spoken for. Just the source code of the procedure that collapses the ...
Disagree.
If you're talking about the code complexity of "interleaving": If the Turing machine simulates quantum mechanics at all, it already has to "interleave" the representations of states for tiny things like a electrons being in a superposition of spin states or whatever. This must be done in order to agree with experimental results. And then at that point not having to put in extra rules to "collapse the wavefunction" makes things simpler.
If you're talking about the complexity of locating yourself in the computation: Inferring which world you're in is...
This notion of faith seems like an interesting idea, but I'm not 100% sure I understand it well enough to actually apply it in an example.
Suppose Descartes were to say: "Y'know, even if there were an evil Daemon fooling every one of my senses for every hour of the day, I can still know what specific illusions the Daemon is choosing to show me. And hey, actually, it sure does seem like there are some clear regularities and patterns in those illusions, so I can sometimes predict what the Daemon will show me next. So in that sense it doesn't matter whether my...
To be clear, I'm definitely pretty sympathetic to TurnTrout's type error objection. (Namely: "If the agent gets a high reward for ingesting superdrug X, but did not ingest it during training, then we shouldn't particularly expect the agent to want to ingest superdrug X during deployment, even if it realizes this would produce high reward.") But just rereading what Zack has written, it seems quite different from what TurnTrout is saying and I still stand by my interpretation of it.
- eg. Zack writes: "obviously the line itself does not somehow contain a repr
It's the same thing for piecewise-linear functions defined by multi-layer parameterized graphical function approximators: the model is the dataset. It's just not meaningful to talk about what a loss function implies, independently of the training data. (Mean squared error of what? Negative log likelihood of what? Finish the sentence!)
This confusion about loss functions...
I don't think this is a confusion, but rather a mere difference in terminology. Eliezer's notion of "loss function" is equivalent to Zack's notion of "loss function" curried with the...
The issue seems more complex and subtle to me.
It is fair to say that the loss function (when combined with the data) is a stochastic environment (stochastic due to sampling the data), and the effect of gradient descent is to select a policy (a function out of the function space) which performs very well in this stochastic environment (achieves low average loss).
If we assume the function-approximation achieves the minimum possible loss, then it must be the case that the function chosen is an optimal control policy where the loss function (understood as incl...
Could you give an example of knowledge and skills not being value neutral?
(No need to do so if you're just talking about the value of information depending on the values one has, which is unsurprising. But it sounds like you might be making a more substantial point?)
Fair enough for the alignment comparison, I was just hoping you could maybe correct the quoted paragraph to say "performance on the hold-out data" or something similar.
(The reason to expect more spread would be that training performance can't detect overfitting but performance on the hold-out data can. I'm guessing some of the nets trained in Miller et al did indeed overfit (specifically the ones with lower performance).)
More generally, John Miller and colleagues have found training performance is an excellent predictor of test performance, even when the test set looks fairly different from the training set, across a wide variety of tasks and architectures.
Seems like figure 1 from Miller et al is a plot of test performance vs. "out of distribution" test performance. One might expect plots of training performance vs. "out of distribution" test performance to have more spread.
In this context, we're imitating some probability distribution, and the perturbation means we're slightly adjusting the probabilities, making some of them higher and some of them lower. The adjustment is small in a multiplicative sense not an additive sense, hence the use of exponentials. Just as a silly example, maybe I'm training on MNIST digits, but I want the 2's to make up 30% of the distribution rather than just 10%. The math described above would let me train a GAN that generates 2's 30% of the time.
I'm not sure what is meant by "the difference from...
Perturbation Theory in Machine Learning
Linkpost for: https://pbement.com/posts/perturbation_theory.html
In quantum mechanics there is this idea of perturbation theory, where a Hamiltonian is perturbed by some change to become . As long as the perturbation is small, we can use the technique of perturbation theory to find out facts about the perturbed Hamiltonian, like what its eigenvalues should be.
An interesting question is if we can also do perturbation theory in machine learning. Suppose I am training a GAN, a diffuser, or some other machine lea...
I don't think we should consider the centroid important in describing the LLM's "ontology". In my view, the centroid just points in the direction of highest density of words in the LLM's space of concepts. Let me explain:
The reason that embeddings are spread out is to allow the model to distinguish between words. So intuitively, tokens with largeish dot product between them correspond to similar words. Distinguishability of tokens is a limited resource, so the training process should generally result in a distribution of tokens that uses this resource in a...
We probably don't disagree that much. What "original seeing" means is just going and investigating things you're interested in. So doing lengthy research is actually a much more central example of this than coming up with a bold new idea is.
As I say above: "There's not any principled reason why an AI system, even a LLM in particular, couldn't do this."