systems that have a tendency to evolve towards a narrow target configuration set when started from any point within a broader basin of attraction, and continue to do so despite perturbations.
When determining whether a system "optimizes" in practice, the heavy lifting is done by the degree to which the set of states that the system evolves toward -- the suspected "target set" -- feels like it forms a natural class to the observer.
The issue here is that what the observer considers "a natural class" is informed by the data-distribution that the observer has previously been exposed to.
Whether or not an axis is "useful" depends on your utility function.
If you only care about compressing certain books from The Library of Babel, then "general optimality" is real — but if you value them all equally, then "general optimality" is fake.
When real, the meaning of "general optimality" depends on which books you deem worthy of consideration.
Within the scope of an analysis whose consideration is restricted to the cluster of sequences typical to the Internet, the term "general optimality" may be usefully applied to a predictive model. Such analysis is unfit to reason about search over a design-space — unless that design-space excludes all out-of-scope sequences.
Yeah. Here's an excerpt from Antifragile by Taleb:
One can make a list of medications that came Black Swan–style from serendipity and compare it to the list of medications that came from design. I was about to embark on such a list until I realized that the notable exceptions, that is, drugs that were discovered in a teleological manner, are too few—mostly AZT, AIDS drugs.
Backpropagation designed it to be good on mostly-randomly selected texts, and for that it bequeathed a small sliver of general optimality.
"General optimality" is a fake concept; there is no compressor that reduces the filesize of every book in The Library of Babel.
This was kinda a "holy shit" moment
Publicly noting that I had a similar moment recently; perhaps we listened to the same podcast.
For what it's worth, he has shared (confidential) AI predictions with me, and I was impressed by just how well he nailed (certain unspecified things) in advance—both in absolute terms & relative to the impression one gets by following him on twitter.
I resent the implication that I need to "read the literature" or "do my homework" before I can meaningfully contribute to a problem of this sort.
The title of my post is "how 2 tell if ur input is out of distribution given only model weights". That is, given just the model, how can you tell which inputs the model "expects" more? I don't think any of the resources you refer to are particularly helpful there.
Your paper list consists of six arXiv papers (1, 2, 3, 4, 5, 6).
Paper 1 requires you to bring a dataset.
We propose leveraging [diverse image and text] data to improve deep anomaly detection by training anomaly detectors against an auxiliary dataset of outliers, an approach we call Outlier Exposure (OE). This enables anomaly detectors to generalize and detect unseen anomalies.
Paper 2 just says "softmax classifers tend to make more certain predictions on in-distribution inputs". I should certainly hope so. (Of course, not every model is a softmax classifer.)
We present a simple baseline that utilizes probabilities from softmax distributions. Correctly classified examples tend to have greater maximum softmax probabilities than erroneously classified and out-of-distribution examples, allowing for their detection.
Paper 3 requires you to know the training set, and also it only works on models that happen to be softmax classifiers.
Paper 4 requires a dataset of in-distribution data, it requires you to train a classifier for every model you want to use their methods with, and it looks like it requires the data to be separated into various classes.

Paper 5 is basically the same as Paper 2, except it says "logits" instead of "probabilities", and includes more benchmarks.
We [...] find that a surprisingly simple detector based on the maximum logit outperforms prior methods in all the large-scale multi-class, multi-label, and segmentation tasks.
Paper 6 only works for classifiers and it also requires you to provide an in-distribution dataset.
We obtain the class conditional Gaussian distributions with respect to (low- and upper-level) features of the deep models under Gaussian discriminant analysis, which result in a confidence score based on the Mahalanobis distance.
It seems that all of the six methods you referred me to either (1) require you to bring a dataset, or (2) reduce to "Hey guys, classifiers make less confident predictions OOD!". Therefore, I feel perfectly fine about failing to acknowledge the extant academic literature here.
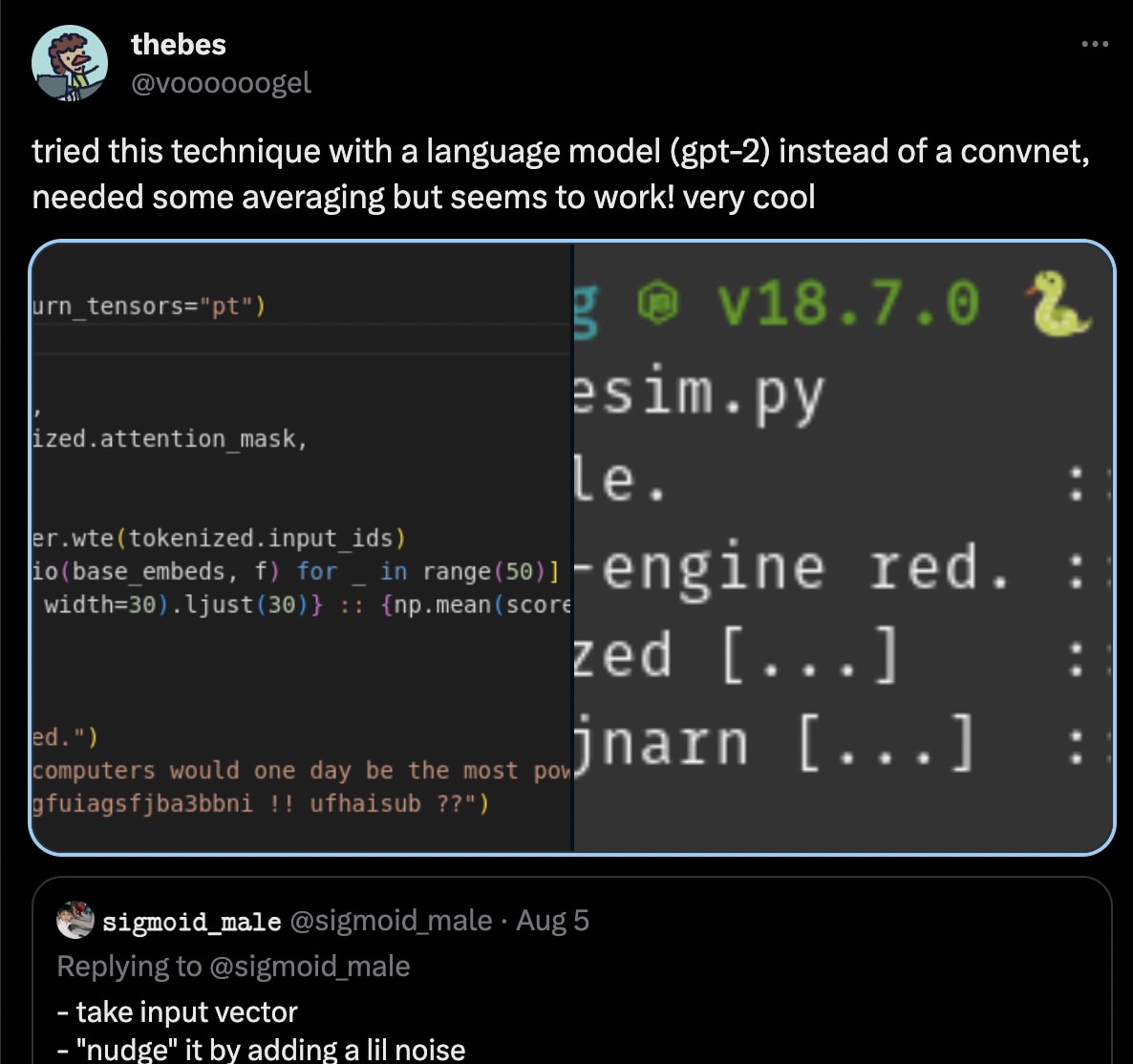
(Additionally, the methods in my post were also replicated in language models by @voooooogel:
Obtaining an Adderall prescription.
I use Done, and can recommend messaging their support to switch you to RxOutreach (a service that mails you your medication) if you live in an area with Adderall shortages, like, say, the Bay Area.
I recently met several YC founders and OpenAI enterprise clients — a salient theme was the use of LLMs to ease the crushing burden of various forms of regulatory compliance.
And how would God predict (with perfect fidelity) what humans would do without simulating them flawlessly? A truly flawless physical simulation has no less moral weight than "reality" -- indeed, the religious argument could very well be that our world exists as a figment of this God's imagination.