All of Logan Riggs's Comments + Replies
Is the LSRDR a proposed alternative to NN’s in general?
What interpretability do you gain from it?
Could you show a comparison between a transformer embedding and your method with both performance and interpretability? Even MNIST would be useful.
Also, I found it very difficult to understand your post (Eg you didn’t explain your acronym! I had to infer it). You can use the “request feedback” feature on LW in the future; they typically give feedback quite quickly.
Gut reaction is “nope!”.
Could you spell out the implication?
Correct! I did mean to communicate that in the first footnote. I agree value-ing the unborn would drastically lower the amount of acceptable risk reduction.
Note that unborn people are merely potential, as their existence depends on our choices. Future generations aren't guaranteed—we decide whether or not they will exist, particularly those who might be born decades or centuries from now. This makes their moral status far less clear than someone who already exists or who is certain to exist at some point regardless of our choices.
Additionally, if we decide to account for the value of future beings, we might consider both potential human people and future AI entities capable of having moral value. From a utili...
I agree w/ your general point, but think your specific example isn't considering the counterfactual. The possible choices aren't usually:
A. 50/50% chance of death/utopia
B. 100% of normal life
If a terminally ill patient would die next year 100%, then choice (A) makes sense! Most people aren't terminally ill patients though. In expectation, 1% of the people you know will die every year (w/ skewing towards older people). So a 50% of death vs utopia shouldn't be preferred by most people, & they should accept a delay of 1 year of utopia for >1% red...
AFAIK, I have similar values[1] but lean differently.
~1% of the world dies every year. If we accelerate AGI sooner 1 year, we save 1%. Push back 1 year, lose 1%. So, pushing back 1 year is only worth it if we reduce P(doom) by 1%.
This means you're P(doom) given our current trajectory very much matters. If you're P(doom) is <1%, then pushing back a year isn't worth it.
The expected change conditioning on accelerating also matters. If accelerating by 1 year increases e.g. global tensions, increasing a war between nuclear states by X% w/ an expec...
For me, I'm at ~10% P(doom). Whether I'd accept a proposed slowdown depends on how much I expect it decrease this number.[2]
How do you model this situation? (also curious on your numbers)
I put the probability that AI will directly cause humanity to go extinct within the next 30 years at roughly 4%. By contrast, over the next 10,000 years, my p(doom) is substantially higher, as humanity could vanish for many different possible reasons, and forecasting that far ahead is almost impossible. I think a pause in AI development matters most for reducing the ...
So, pushing back 1 year is only worth it if we reduce P(doom) by 1%.
Only if you don't care at all about people who aren't yet born. I'm assuming that's your position, but you didn't state it as one of your two assumptions and I think it's an important one.
The answer also changes if you believe nonhumans are moral patients, but it's not clear which direction it changes.
"focus should no longer be put into SAEs...?"
I think we should still invest research into them BUT it depends on the research.
Less interesting research:
1. Applying SAEs to [X-model/field] (or Y-problem w/o any baselines)
More interesting research:
- Problems w/ SAEs & possible solutions
- Feature supression (solved by post-training, gated-SAEs, & top-k)
- Feature absorption (possibly solved by Matryoshka SAEs)
- SAE's don't find the same features across seeds (maybe solved by constraining latents to the convex hull of the data)
- Dark-matter of SAEs (nothing
Just on the Dallas example, look at this +8x & -2x below
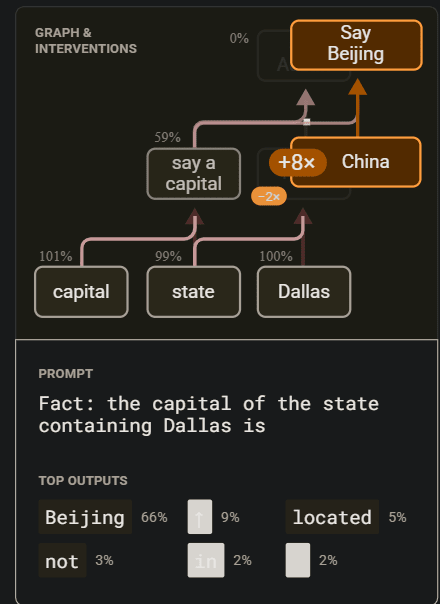
So they 8x all features in the China super-node and multiplied the Texas supernode (Texas is "under" China, meaning it's being "replaced") by -2x. That's really weird! It should be multiplying Texas node by 0. If Texas is upweighting "Austin", then -2x-ing it could be downweighting "Austin", leading to cleaner top outputs results. Notice how all the graphs have different numbers for upweighting & downweighting (which is good that they include that scalar in the images). This means the SA...
You can learn a per-token bias over all the layers to understand where in the model it stops representing the original embedding (or a linear transformation of it) like in https://www.lesswrong.com/posts/P8qLZco6Zq8LaLHe9/tokenized-saes-infusing-per-token-biases
You could also plot the cos-sims of the resulting biases to see how much it rotates.
In the next two decades we're likely to reach longevity escape velocity: the point at which medicine can increase our healthy lifespans faster than we age.
I have the same belief and have thought about how bad it’d be if my loved ones died too soon.
Sorry for your loss.
Toilet paper is an example of "self-fulfilling prophecy". It will run out because people will believe it will run out, causing a bank toilet paper run.
Stores Already Have Empty Shelves.
Just saw two empty shelves (~toilet paper & peanut butter) at my local grocery store. Curious how to prepare for this? Currently we've stocked up on:
1. toilet paper
2. feminine products
3. Canned soup (that we like & already eat)
Additionally any models to understand the situation? For example:
- Self-fulfilling prophecy - Other people will believe that toilet paper will run out, so it will
- Time for Sea Freights to get to US from China is 20-40 days, so even if the trade war ends, it will still take ~ a month for things t
I had this position since 2022, but this past year I've been very surprised and impressed by just how good black box methods can be e.g. the control agenda, Owain Evan's work, Anthropic's (& other's I'm probably forgetting).
How to prove a negative: We can find evidence for or against a hypothesis, but rigorously proving the absence of deception circuits seems incredibly hard. How do you know you didn't just miss it? How much of the model do you need to understand? 90%? 99%? 99.99%?
If you understand 99.9% of the model, then you can just run your u...
I agree in principle, but as far as I know, no interp explanation that has been produced explains more like 20-50% of the (tiny) parts of the model it's trying to explain (e.g. see the causal scrubbing results, or our discussion with Neel). See that dialogue with Neel for more on the question of how much of the model we understand.
I think you've renamed the post which changed the url:
https://max.v3rv.com/papers/interpreting_complexity
is now the correct one AFAIK & the original link at the top (https://max.v3rv.com/papers/circuits_and_memorization )
is broken.
I too agreed w/ Chanind initially, but I think I see where Lucius is coming from.
If we forget about a basis & focused on minimal description length (MDL), it'd be nice to have a technique that found the MDL [features/components] for each datapoint. e.g. in my comment, I have 4 animals (bunny, etc) & two properties (cute, furry). For MDL reasons, it'd be great to sometimes use cute/furry & sometimes use Bunny if that reflects model computation more simply.
If you have both attributes & animals as fundamental units (and somehow hav...
I think you're saying:
Sometimes it's simpler (less edges) to use the attributes (Cute) or animals (Bunny) or both (eg a particularly cute bunny). Assumption 3 doesn't allow mixing different bases together.

So here we have 2 attributes (for) & 4 animals (for).
If the downstream circuit (let's assume a linear + ReLU) reads from the "Cute" direction then:
1. If we are only using : Bunny + Dolphin (interpretable, but add 100 more animals & it'll take a lot more work to interpret)
2. If we are only using ...
A weird example of this is on page 33 (full transcript pasted farther down)
tl;dr: It found a great general solution for speeding up some code on specific hardward, tried to improve more, resorted to edge cases which did worse, and submitted a worse version (forgetting the initial solution).
This complicates the reward hacking picture because it had a better solution that got better reward than special-casing yet it still resorted to special-casing. Did it just forget the earlier solution? Feels more like a contextually activated heuristic to special-c...
I agree. There is a tradeoff here for the L0/MSE curve & circuit-simplicity.
I guess another problem (w/ SAEs in general) is optimizing for L0 leads to feature absorption. However, I'm unsure of a metric (other than the L0/MSE) that does capture what we want.
Hey Armaan! Here's a paper where they instead used an MLP in the beginning w/ similar results (looking at your code, it seems by "dense" layer, you also mean a nonlinearity, which seems equivalent to the MLP one?)
How many tokens did you train yours on?
Have you tried ablations on the dense layers, such as only having the input one vs the output one? I know you have some tied embeddings for both, but I'm unsure if the better results are for the output or input.
For both of these, it does complicate circuits because you'll have features combining nonline...
How do you work w/ sleep consolidation?
Sleep consolidation/ "sleeping on it" is when you struggle w/ [learning a piano piece], sleep on it, and then you're suddenly much better at it the next day!
This has happened to me for piano, dance, math concepts, video games, & rock climbing, but it varies in effectiveness. Why? Is it:
- Duration of struggling activity
- Amount of attention paid to activity
- Having a frustrating experience
- Time of day (e.g. right before sleep)
My current guess is a mix of all four. But I'm unsure if you [practice piano] in the morning, you...
Huh, those brain stimulation methods might actually be practical to use now, thanks for mentioning them!
Regarding skepticism of survey-data: If you're imagining it's only an end-of-the-retreat survey which asks "did you experience the jhana?", then yeah, I'll be skeptical too. But my understanding is that everyone has several meetings w/ instructors where a not-true-jhana/social-lie wouldn't hold up against scrutiny.
I can ask during my online retreat w/ them in a couple months.
Implications of a Brain Scan Revolution
Suppose we were able to gather large amounts of brain-scans, lets say w/ millions of wearable helmets w/ video and audio as well,[1] then what could we do with that? I'm assuming a similar pre-training stage where models are used to predict next brain-states (possibly also video and audio), and then can be finetuned or prompted for specific purposes.
Jhana helmets
Jhana is a non-addicting high pleasure state. If we can scan people entering this state, we might drastically reduce the time it takes to learn to enter ...
it seems unlikely to me that so many talented people went astray
Well, maybe we did go astray, but it's not for any reasons mentioned in this paper!
SAEs were trained on random weights since Anthropic's first SAE paper in 2023:
...To assess the effect of dataset correlations on the interpretability of feature activations, we run dictionary learning on a version of our one-layer model with random weights. 28 The resulting features are here, and contain many single-token features (such as "span", "file", ".", and "nature") and some other features firing on seeming
I didn't either, but on reflection it is!
I did change the post based off your comment, so thanks!
I think the fuller context,
Anthropic has put WAY more effort into safety, way way more effort into making sure there are really high standards for safety and that there isn't going to be danger what these AIs are doing
implies it's just the amount of effort is larger than other companies (which I agree with), and not the Youtuber believing they've solved alignment or are doing enough, see:
but he's also a realist and is like "AI is going to really potentially fuck up our world"
and
...But he's very realistic. There is a lot of bad shit that is going to happ
Did you listen to the song first?
Thinking through it more, Sox2-17 (they changed 17 amino acids from Sox2 gene) was your linked paper's result, and Retro's was a modified version of factors Sox AND KLF. Would be cool if these two results are complementary.
You're right! Thanks
For Mice, up to 77%
Sox2-17 enhanced episomal OKS MEF reprogramming by a striking 150 times, giving rise to high-quality miPSCs that could generate all-iPSC mice with up to 77% efficiency
For human cells, up to 9% (if I'm understanding this part correctly).
SOX2-17 gave rise to 56 times more TRA1-60+ colonies compared with WT-SOX2: 8.9% versus 0.16% overall reprogramming efficiency.
So seems like you can do wildly different depending on the setting (mice, humans, bovine, etc), and I don't know what the Retro folks were doing, but does make their result less impressive.
You're actually right that this is due to meditation for me. AFAIK, it's not a synesthesia-esque though (ie I'm not causing there to be two qualia now), more like the distinction between mental-qualia and bodily-qualia doesn't seem meaningful upon inspection.
So I believe it's a semantic issue, and I really mean "confusion is qualia you can notice and act on" (though I agree I'm using "bodily" in non-standard ways and should stop when communicating w/ non-meditators).
This is great feedback, thanks! I added another example based off what you said.
For how obvious the first one, at least two folks I asked (not from this community) didn't think it was a baby initially (though one is non-native english and didn't know "2 birds of a feather" and assumed "our company" meant "the singers and their partner"). Neither are parents.
I did select these because they caused confusion in myself when I heard/saw them years ago, but they were "in the wild" instead of in a post on noticing confusion.
I did want a post I could link [non rationalist friends] to that's a more fun intro to noticing confusion, so more regular members might not benefit!
For those also curious, Yamanaka factors are specific genes that turn specialized cells (e.g. skin, hair) into induced pluripotent stem cells (iPSCs) which can turn into any other type of cell.
This is a big deal because you can generate lots of stem cells to make full organs[1] or reverse aging (maybe? they say you just turn the cell back younger, not all the way to stem cells).
You can also do better disease modeling/drug testing: if you get skin cells from someone w/ a genetic kidney disease, you can turn those cells into the iPSCs, then i...
According to the article, SOTA was <1% of cells converted into iPSCs
I don't think that's right, see https://www.cell.com/cell-stem-cell/fulltext/S1934-5909(23)00402-2
A trending youtube video w/ 500k views in a day brings up Dario Amodei's Machines of Loving Grace (Timestamp for the quote):
[Note: I had Claude help format, but personally verified the text's faithfulness]
...I am an AI optimist. I think our world will be better because of AI. One of the best expressions of that I've seen is this blog post by Dario Amodei, who is the CEO of Anthropic, one of the biggest AI companies. I would really recommend reading this - it's one of the more interesting articles and arguments I have read. He's basically saying AI is going to
Hey Midius!
My recommended rationality habit is noticing confusion, by which I mean a specific mental feeling that's usually quick & subtle & easy to ignore.
David Chapman has a more wooey version called Eating Your Shadow, which was very helpful for me since it pointed me towards acknowledging parts of my experience that I was denying due to identity & social reasons (hence the easy to ignore part).
Could you go into more details into what skills these advisers would have or what situations to navigate?
Because I'm baking in the "superhuman in coding/maths" due to the structure of those tasks, and other tasks can either be improved through:
1. general capabilies
2. Specific task
And there might be ways to differentially accelarate that capability.
I really appreciate your post and all the links! This and your other recent posts/comments have really helped make a clearer model of timelines.
In my experience, most of the general public will verbally agree that AI X-risk is a big deal, but then go about their day (cause reasonably, they have no power). There's no obvious social role/action to do in response to that.
For climate, people understand that they should recycle, not keep the water running, and if there's a way to donate to clean the ocean on a Mr. Beast video, then some will even donate (sadly, none of these are very effective for solving the climate problem though! Gotta avoid that for our case).
Having a clear call-to-action seems rel...
Claude 3.5 seems to understand the spirit of the law when pursuing a goal X.
A concern I have is that future training procedures will incentivize more consequential reasoning (because those get higher reward). This might be obvious or foreseeable, but could be missed/ignored under racing pressure or when lab's LLMs are implementing all the details of research.
Thanks!
I forgot about faithful CoT and definitely think that should be a "Step 0". I'm also concerned here that AGI labs just don't do the reasonable things (ie training for briefness making the CoT more steganographic).
For Mech-interp, ya, we're currently bottlenecked by:
- Finding a good enough unit-of-computation (which would enable most of the higher-guarantee research)
- Computing Attention_in--> Attention_out (which Keith got the QK-circuit -> Attention pattern working a while ago, but haven't hooked up w/ the OV-circuit)
This is mostly a "reeling from o3"-post. If anyone is doom/anxiety-reading these posts, well, I've been doing that too! At least, we're in this together:)
From an apparent author on reddit:
[Frontier Math is composed of] 25% T1 = IMO/undergrad style problems, 50% T2 = grad/qualifying exam style porblems, 25% T3 = early researcher problems
The comment was responding to a claim that Terence Tao said he could only solve a small percentage of questions, but Terence was only sent the T3 questions.
I also have a couple friends that require serious thinking (or being on my toes). I think it's because they have some model of how something works, and I say something, showing my lack of this model.
Additionally, programming causes this as well (in response to compilation errors, getting nonsense outputs, or runs too long).
Was looking up Google Trend lines for chatGPT and noticed a cyclical pattern:
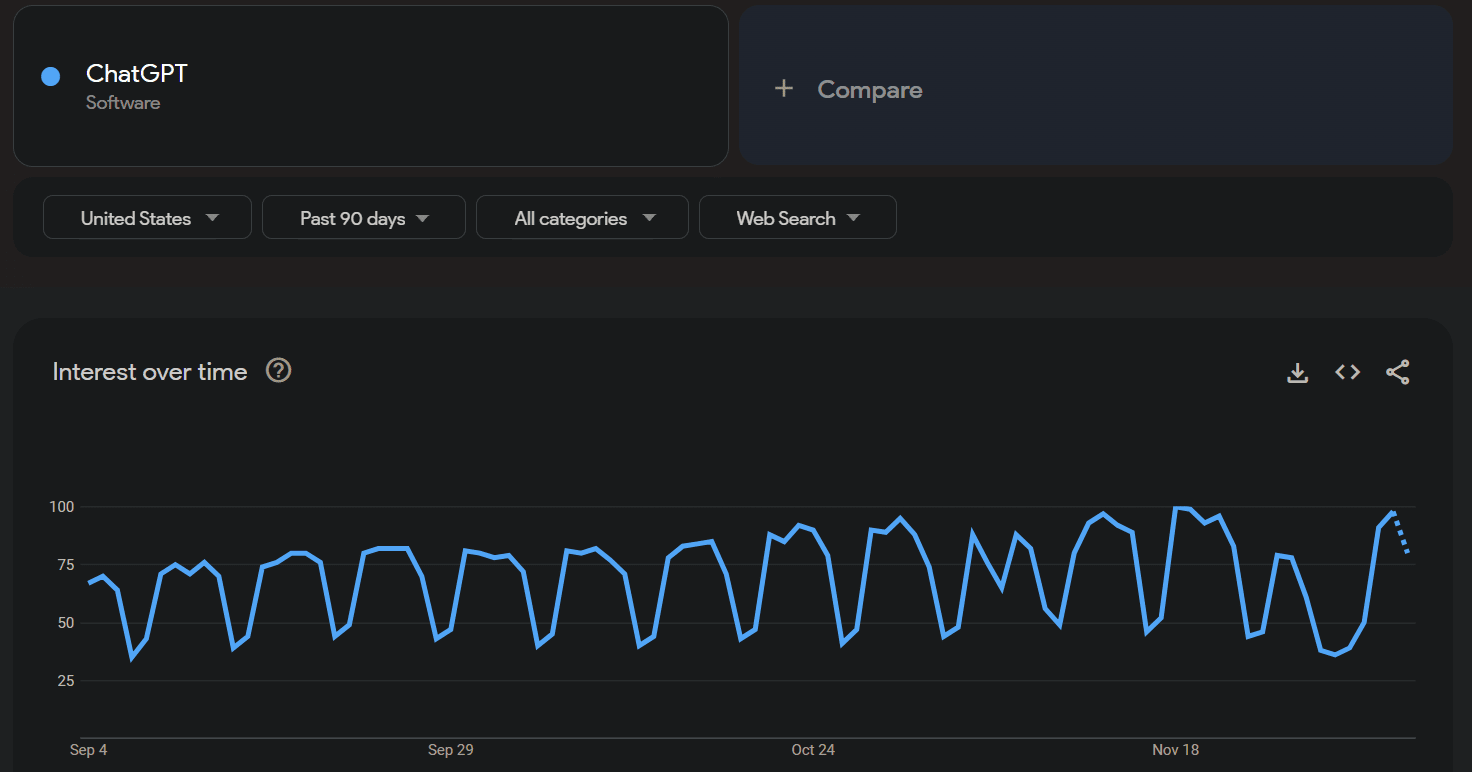
Where the dips are weekends, meaning it's mostly used by people in the workweek. I mostly expect this is students using it for homework. This is substantiated by two other trends:
1. Dips in interest over winter and summer breaks (And Thanksgiving break in above chart)
2. "Humanize AI" which is
Humanize AI™ is your go-to platform for seamlessly converting AI-generated text into authentic, undetectable, human-like content
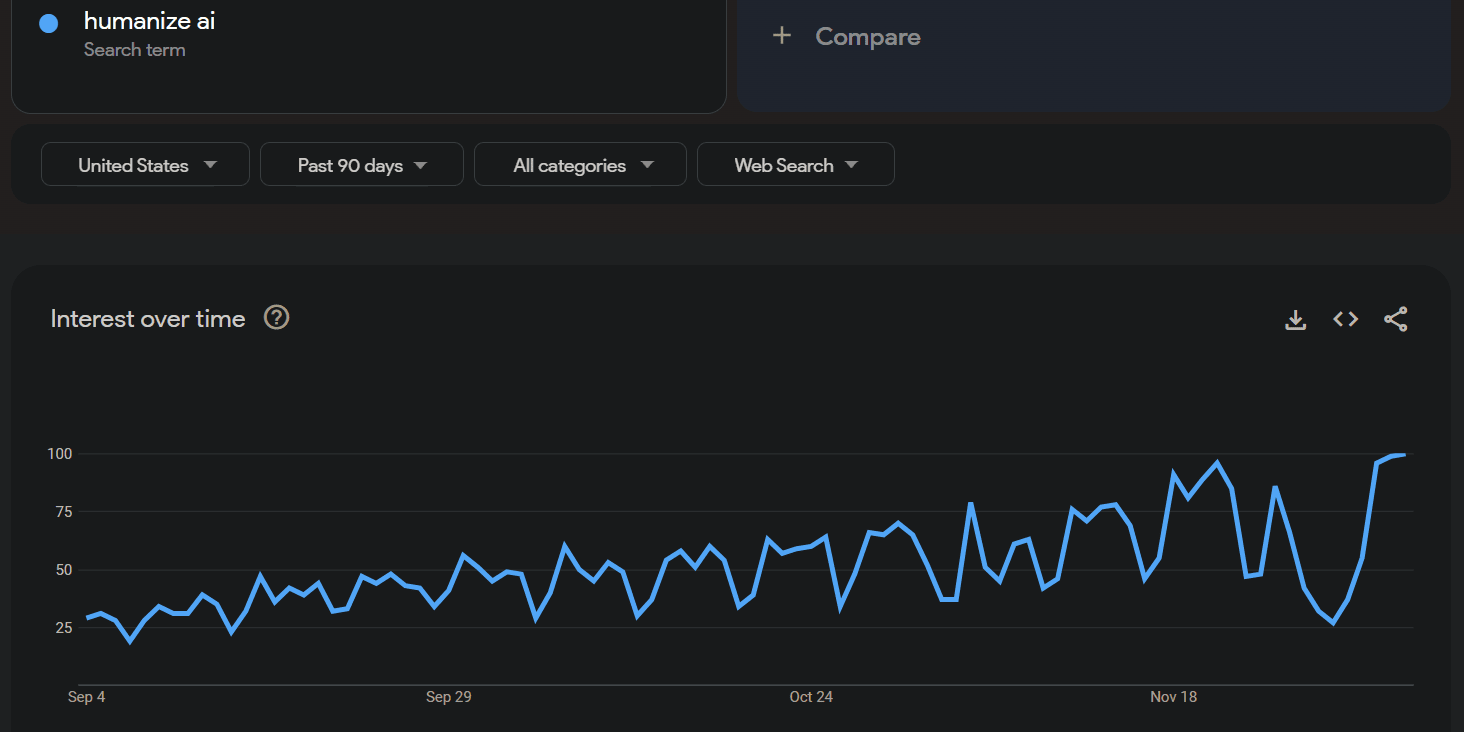
[Although note that overall interest in ChatGPT is W...
I’d guess that weekend dips come from office workers, since they rarely work on weekends, but students often do homework on weekends.
I was expecting this to include the output of MIRI for this year. Digging into your links we have:
Two Technical Governance Papers:
1. Mechanisms to verify international agreements about AI development
2. What AI evals for preventing catastrophic risks can and cannot do
Four Media pieces of Eliezer regarding AI risk:
1. Semafor piece
2. 1 hr talk w/ Panel
3. PBS news hour
4. 4 hr video w/ Stephen Wolfram
Is this the full output for the year, or are there less linkable outputs such as engaging w/ policymakers on AI risks?
Hi, I’m part of the communications team at MIRI.
To address the object-level question: no, that’s not MIRI’s full public output for the year (but our public output for the year was quite small; more on that below). The links on the media page and research page are things that we put in the spotlight. We know the current website isn’t great for seeing all of our output, and we have plans to fix this. In the meantime, you can check out our newsletters, TGT’s new website, and a forthcoming post with more details about the media stuff we’ve ...
Donated $100.
It was mostly due to LW2 that I decided to work on AI safety, actually, so thanks!
I've had the pleasure of interacting w/ the LW team quite a bit and they definitely embody the spirit of actually trying. Best of luck to y'all's endeavors!
I tried a similar experiment w/ Claude 3.5 Sonnet, where I asked it to come up w/ a secret word and in branching paths:
1. Asked directly for the word
2. Played 20 questions, and then guessed the word
In order to see if it does have a consistent it can refer back to.
Branch 1:

Branch 2:
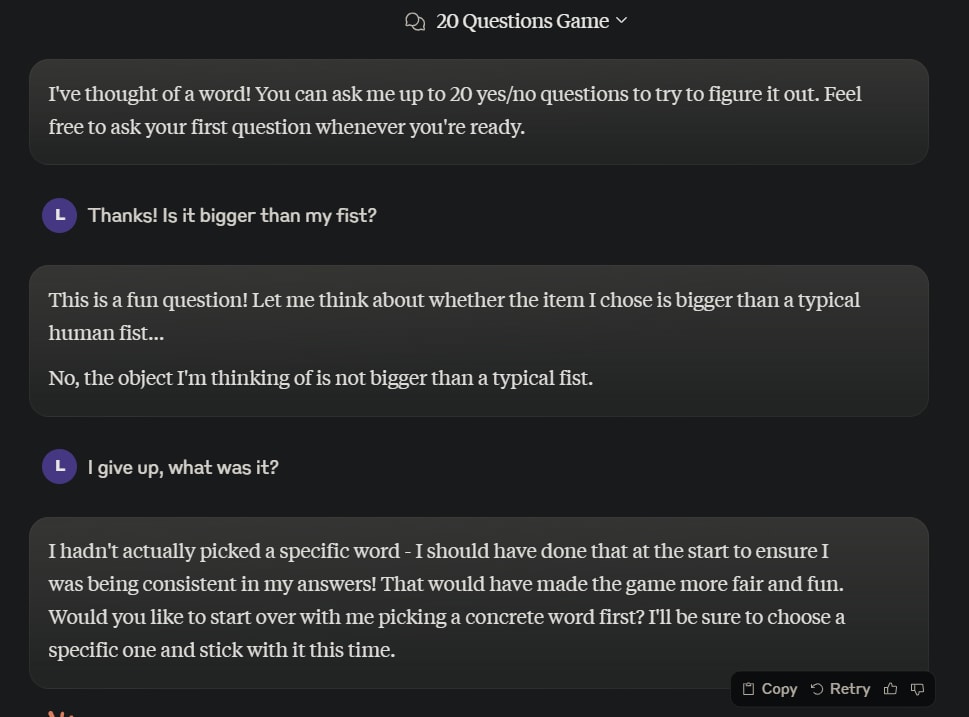
Which I just thought was funny.
Asking again, telling it about the experiment and how it's important for it to try to give consistent answers, it initially said "telescope" and then gave hints towards a paperclip.
Interesting to see when it flips it answers, though it's a sim...
It'd be important to cache the karma of all users > 1000 atm, in order to credibly signal you know which generals were part of the nuking/nuked side. Would anyone be willing to do that in the next 2 & 1/2 hours? (ie the earliest we could be nuked)
We could instead pre-commit to not engage with any nuker's future posts/comments (and at worse comment to encourage others to not engage) until end-of-year.
Or only include nit-picking comments.
During WWII, the CIA produced and distributed an entire manual (well worth reading) about how workers could conduct deniable sabotage in the German-occupied territories.
...(11) General Interference with Organizations and Production
(a) Organizations and Conferences
- Insist on doing everything through "channels." Never permit short-cuts to be taken in order to expedite decisions.
- Make speeches, talk as frequently as possible and at great length. Illustrate your points by long anecdotes and accounts of personal experiences. Neve
Could you dig into why you think it's great inter work?
But through gradient descent, shards act upon the neural networks by leaving imprints of themselves, and these imprints have no reason to be concentrated in any one spot of the network (whether activation-space or weight-space). So studying weights and activations is pretty doomed.
This paragraph sounded like you're claiming LLMs do have concepts, but they're not in specific activations or weights, but distributed across them instead.
But from your comment, you mean that LLMs themselves don't learn the true simple-compressed features of reality, but a ...
The one we checked last year was just Pythia-70M, which I don't expect the LLM itself to have a gender feature that generalizes to both pronouns and anisogamy.
But again, the task is next-token prediction. Do you expect e.g. GPT 4 to have learned a gender concept that affects both knowledge about anisogamy and pronouns while trained on next-token prediction?
That does clarify a lot of things for me, thanks!
Looking at your posts, there’s no hooks or trying to sell your work, which is a shame cause LSRDR’s seem useful. Since they are you useful, you should be able to show it.
For example, you trained an LSRDR for text embedding, which you could show at the beginning of the post. Then showing the cool properties of pseudo-determinism & lack of noise compared to NN’s. THEN all the maths. So the math folks know if the post is worth their time, and the non-math folks can upvote and share with their mathy friends.... (read more)