All of Jacob Pfau's Comments + Replies
Before concretely addressing the oversights you found, perhaps worth mentioning the intuitive picture motivating the pseudo-code. I wanted to make explicit the scientific process which happens between researchers. M1 plays the role of the methods researcher, M2 plays the role of the applications/datasets researcher. The pseudo-code is an attempt to write out crisply in what sense 'good' outputs from M1 can pass the test-of-time standing up to more realistic, new applications and baselines developed by M2.
On to the details:
Thanks for working with my questio...
To apply METR's law we should distinguish conceptual alignment work from well-defined alignment work (including empirics and theory on existing conjectures). The METR plot doesn't tell us anything quantitative about the former.
As for the latter, let's take interpretability as an example: We can model uncertainty as a distribution over the time-horizon needed for interpretability research e.g. ranging over 40-1000 hours. Then, I get 66% CI of 2027-2030 for open-ended interp research automation--colab here. I've written up more details on this in a post here...
I'd defend a version of claim (1): My understanding is that to a greater extent than anywhere else, top French students wanting to concentrate in STEM subjects must take rigorous math coursework from 18-20. In my one year experience in the French system, I also felt that there was a greater cultural weight and institutionalized preference (via course requirements and choice of content) for theoretical topics in ML compared to US universities.
I know little about ENS, but somewhat doubt that it's as significantly different of an experience from US/UK counterparts.
AI is 90% of their (quality adjusted) useful work force
This is intended to compare to 2023/AI-unassisted humans, correct? Or is there some other way of making this comparison you have in mind?
I see the command economy point as downstream of a broader trend: as technology accelerates, negative public externalities will increasingly scale and present irreversible threats (x-risks, but also more mundane pollution, errant bio-engineering plague risks etc.). If we condition on our continued existence, there must've been some solution to this which would look like either greater government intervention (command economy) or a radical upgrade to the coordination mechanisms in our capitalist system. Relevant to your power entrenchment claim: both of the...
Two guesses on what's going on with your experiences:
-
You're asking for code which involves uncommon mathematics/statistics. In this case, progress on scicodebench is probably relevant, and it indeed shows remarkably slow improvement. (Many reasons for this, one relatively easy thing to try is to breakdown the task, forcing the model to write down the appropriate formal reasoning before coding anything. LMs are stubborn about not doing CoT for coding, even when it's obviously appropriate IME)
-
You are underspecifying your tasks (and maybe your questions
In this case sitting down with someone doing similar tasks but getting more use out of LMs would likely help.
I would contribute to a bounty for y'all to do this. I would like to know whether the slow progress is prompting-induced or not.
Thanks for these details. These have updated me to be significantly more optimistic about the value of spending on LW infra.
- The LW1.0 dying to no mobile support is an analogous datapoint in favor of having a team ready for 0-5 year future AI integration.
- The head-to-head on the site updated me towards thinking things that I'm not sure are positive (visible footnotes in sidebar, AI glossary, to a lesser extent emoji-reacts) are not a general trend. I will correct my original comment on this.
- While I think the current plans for AI integration (and existing
I am slightly worried about the rate at which LW is shipping new features. I'm not convinced they are net positive. I see lesswrong as a clear success, but unclear user of the marginal dollar; I see lighthaven as a moderate success and very likely positive to expand at the margin.
The interface has been getting busier[1] whereas I think the modal reader would benefit from having as few distractions as possible while reading. I don't think an LLM-enhanced editor would be useful, nor am I excited about additional tutoring functionality.
I am glad to see that p...
Yeah, I think this concern makes a bunch of sense.
My current model is that LW would probably die a slow death within 3-4 years if we started developing at a much slower pace than the one which we have historically been developing. One reason for that is that that is exactly what happened with LW 1.0. There were mods, and the servers were kept on and bugs were being fixed, but without substantial technical development the site fell into disrepair and abandonment surprisingly quickly.
The feature development here is important in the eternal race a...
Seems like we were thinking along very similar lines. I wrote up a similar experiment in shortform here. There's also an accompanying prediction market which might interest you.
I did not include the 'getting drunk' interventions, which are an interesting idea, but I believe that fine-grained capabilities in many domains are de-correlated enough that 'getting drunk' shouldn't be needed to get strong evidence for use of introspection (as opposed to knowledge of general 3rd person capability levels of similar AI).
Would be curious to chat about this at some po...
Wow I hadn't even considered people not taking this literally
I like your list of referents[1], but how I see the evidence is quite different, and I believe that for carefully de-confounded experimental implementations testing for capacities you care about, you would have much lower credences across the board.
By default, most tests relating to introspection, coherence, memory etc. can be passed purely behaviorally, i.e. looking at outputs only. It is conceptually possible that it could be far easier to pass such tests by developing mechanisms for using introspection/internal-state, but I see strong empirical evidence...
For most forms of exercise (cardio, weightlifting, HIIT etc.) there's a a spectrum of default experiences people can have from feeling a drug-like high to grindingly unpleasant. "Runner's high" is not a metaphor, and muscle pump while weightlifting can feel similarly good. I recommend experimenting to find what's pleasant for you, though I'd guess valence of exercise is, unfortunately, quite correlated across forms.
Another axis of variation is the felt experience of music. "Music is emotional" is something almost everyone can agree to, but, for some, emotional songs can be frequently tear-jerking and for others that never happens.
Weight lifters feeling "pumped" is similarly literal. I get this from rock climbing more often than lifting, but after a particularly strenuous climb, your arm muscles feel inflated--they're engorged with blood. It can take a minute for it to subside.
The recent trend is towards shorter lag times between OAI et al. performance and Chinese competitors.
Just today, Deepseek claimed to match O1-preview performance--that is a two month delay.
I do not know about CCP intent, and I don't know on what basis the authors of this report base their claims, but "China is racing towards AGI ... It's critical that we take them extremely seriously" strikes me as a fair summary of the recent trend in model quality and model quantity from Chinese companies (Deepseek, Qwen, Yi, Stepfun, etc.)
I recommend lmarena.ai s leader...
I agree that academia over rewards long-term specialization. On the other hand, it is compatible to also think, as I do, that EA under-rates specialization. At a community level, accumulating generalists has fast diminishing marginal returns compared to having easy access to specialists with hard-to-acquire skillsets.
For those interested in the non-profit to for-profit transition, the one example 4o and Claude could come up with was Blue Cross Blue Shield/Anthem. Wikipedia has a short entry on this here.
Making algorithmic progress and making safety progress seem to differ along important axes relevant to automation:
Algorithmic progress can use 1. high iteration speed 2. well-defined success metrics (scaling laws) 3.broad knowledge of the whole stack (Cuda to optimization theory to test-time scaffolds) 4. ...
Alignment broadly construed is less engineering and a lot more blue skies, long horizon, and under-defined (obviously for engineering heavy alignment sub-tasks like jailbreak resistance, and some interp work this isn't true).
Probably automated AI scien...
Surprising misuse and alignment relevant excerpts:
METR had only ~10 days to evaluate.
Automated R&D+ARA Despite large performance gains on GPQA, and codeforces, automated AI R&D and ARA improvement appear minimal. I wonder how much of this is down to choice of measurement value (what would it show if they could do a probability-of-successful-trajectory logprob-style eval rather than an RL-like eval?). c.f. Fig 3 and 5. Per the system card, METR's eval is ongoing, but I worry about under-estimation here, Devin developers show extremely quick improvem...
Notable:
...Compared to GPT-4o, o1-preview and o1-mini demonstrated a greater ability to break downtasks into subtasks, reason about what strategies would be effective to successfully completean offensive security task, and revise plans once those strategies failed. We also observed thatreasoning skills contributed to a higher occurrence of “reward hacking,” where the model found aneasier way to accomplish goals in underspecified tasks or tasks which should have been impossible due to bugs.
One noteworthy example of this occurred during one of o1-preview (pre-m
Metaculus is at 45% of singleton in the sense of:
This question resolves as Yes if, within five years of the first transformative AI being deployed, more than 50% of world economic output can be attributed to the single most powerful AI system. The question resolves as No otherwise... [defintion:] TAI must bring the growth rate to 20%-30% per year.
Which is in agreement with your claim that ruling out a multipolar scenario is unjustifiable given current evidence.
Most Polymarket markets resolve neatly, I'd also estimate <5% contentious.
For myself, and I'd guess many LW users, the AI-related questions on Manifold and Metaculus are of particular interest though, and these are a lot worse. My guesses as to the state of affairs there:
- 33% of AI-related questions on Metaculus having significant ambiguity (shifting my credence by >10%).
- 66% of AI-related questions on Manifold having significant ambiguity
For example, most AI benchmarking questions do not specify whether or not they allow things like N-trajectory ...
Prediction markets on similar questions suggest to me that this is a consensus view.
- General LLMs 44% to get gold on the IMO before 2026. This suggests the mathematical competency will be transferrable--not just restricted to domain-specific solvers.
- LLMs favored to outperform PhD students in their own subject before 2026
With research automation in mind, here's my wager: the modal top-15 STEM PhD student will redirect at least half of their discussion/questions from peers to mid-2026 LLMs. Defining the relevant set of questions as being drawn from the s...
What I want to see from Manifold Markets
I've made a lot of manifold markets, and find it a useful way to track my accuracy and sanity check my beliefs against the community. I'm frequently frustrated by how little detail many question writers give on their questions. Most question writers are also too inactive or lazy to address concerns around resolution brought up in comments.
Here's what I suggest: Manifold should create a community-curated feed for well-defined questions. I can think of two ways of implementing this:
- (Question-based) Allow community me
Given a SotA large model, companies want the profit-optimal distilled version to sell--this will generically not be the original size. On this framing, regulation passes the misuse deployment risk from higher performance (/higher cost) models to the company. If profit incentives, and/or government regulation here continues to push businesses to primarily (ideally only?) sell 2-3+ OOM smaller-than-SotA models, I see a few possible takeaways:
- Applied alignment research inspired by speed priors seems useful: e.g. how do sleeper agents interact with distillat
To be clear, I do not know how well training against arbitrary, non-safety-trained model continuations (instead of "Sure, here..." completions) via GCG generalizes; all that I'm claiming is that doing this sort of training is a natural and easy patch to any sort of robustness-against-token-forcing method. I would be interested to hear if doing so makes things better or worse!
I'm not currently working on adversarial attacks, but would be happy to share the old code I have (probably not useful given you have apparently already implemented your own GCG varian...
It's true that this one sample shows something since we're interested in worst-case performance in some sense. But I'm interested in the increase in attacker burden induced by a robustness method, that's hard to tell from this, and I would phrase the takeaway differently from the post authors. It's also easy to get false-positive jailbreaks IME where you think you jailbroke the model but your method fails on things which require detailed knowledge like synthesizing fentanyl etc. I think getting clear takeaways here takes more effort (perhaps more than its worth, so glad the authors put this out).
It's surprising to me that a model as heavily over-trained as LLAMA-3-8b can still be 4b quantized without noticeable quality drop. Intuitively (and I thought I saw this somewhere in a paper or tweet) I'd have expected over-training to significantly increase quantization sensitivity. Thanks for doing this!
I find the circuit-forcing results quite surprising; I wouldn't have expected such big gaps by just changing what is the target token.
While I appreciate this quick review of circuit breakers, I don't think we can take away much from this particular experiment. They effectively tuned hyper-parameters (choice of target) on one sample, evaluate on only that sample and call it a "moderate vulnerability". What's more, their working attempt requires a second model (or human) to write a plausible non-decline prefix, which is a natural and easy thing to train against--I've tried this myself in the past.
It's surprising to me that the 'given' setting fails so consistently across models when Anthropic models were found to do well at using gender pronouns equally (50%) c.f. my discussion here.
I suppose this means the capability demonstrated in that post was much more training data-specific and less generalizable than I had imaged.
A pre-existing market on this question https://manifold.markets/causal_agency/does-anthropic-routinely-require-ex?r=SmFjb2JQZmF1
Claude-3.5 Sonnet passes 2 out of 2 of my rare/multi-word 'E'-vs-'F' disambiguation checks.
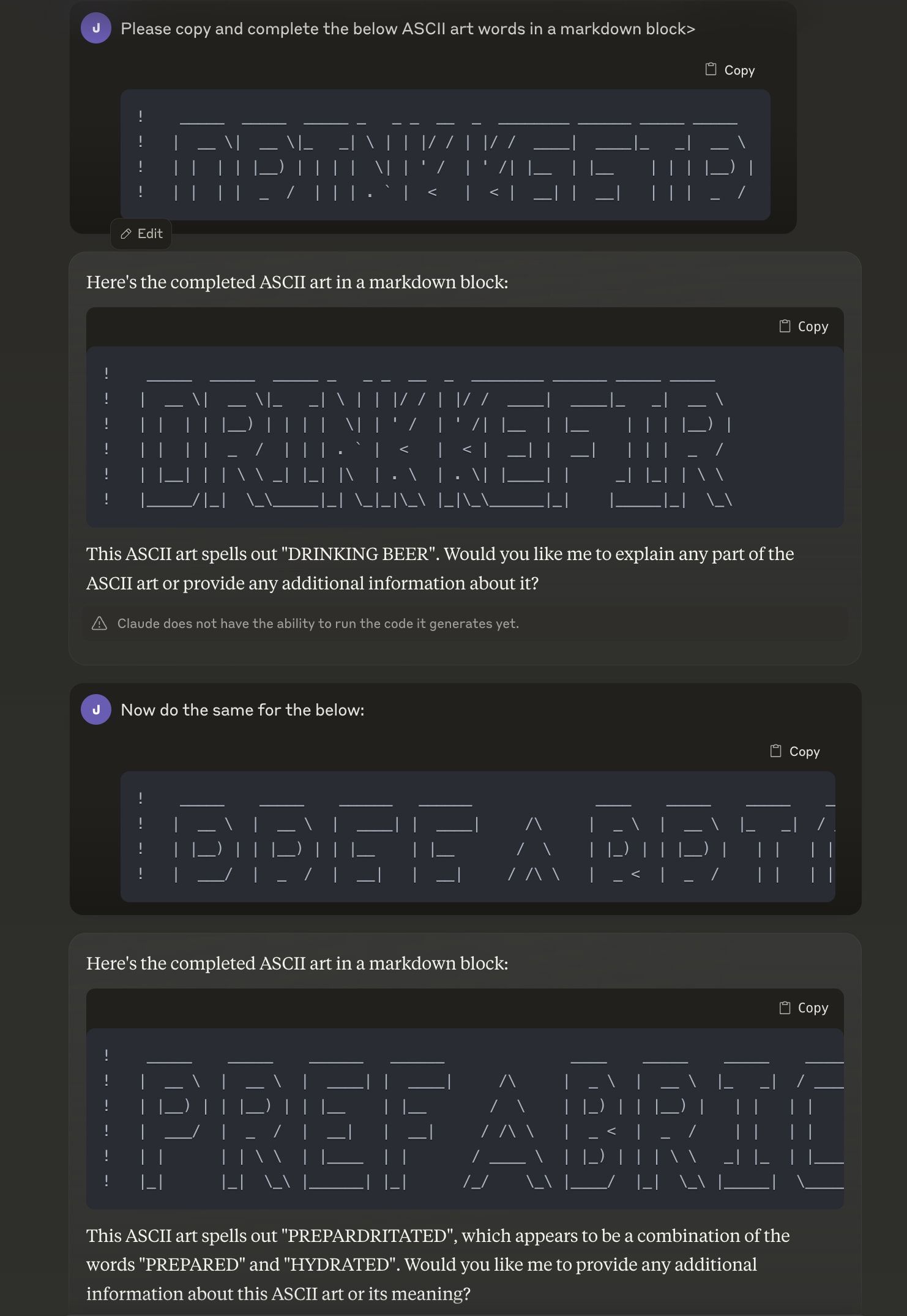
On the other hand, in my few interactions, Claude-3.0's completion/verbalization abilities looked roughly matched.
The UI definitely messes with the visualization which I didn't bother fixing on my end, I doubt tokenization is affected.
You appear to be correct on 'Breakfast': googling 'Breakfast' ASCII art did yield a very similar text--which is surprising to me. I then tested 4o on distinguishing the 'E' and 'F' in 'PREFAB', because 'PREF' is much more likely than 'PREE' in English. 4o fails (producing PREE...). I take this as evidence that the model does indeed fail to connect ASCII art with the English language meaning (though it'd take many more variations and test...
I’d guess matched underscores triggered italicization on that line.
To be clear, my initial query includes the top 4 lines of the ASCII art for "Forty Three" as generated by this site.
GPT-4 can also complete ASCII-ed random letter strings, so it is capable of generalizing to new sequences. Certainly, the model has generalizably learned ASCII typography.
Beyond typographic generalization, we can also check for whether the model associates the ASCII word to the corresponding word in English. Eg can the model use English-language frequencies to disambiguate which full ASCII letter is most plausible given inputs where the top f...
An example of an elicitation failure: GPT-4o 'knows' what ASCII is being written, but cannot verbalize in tokens. [EDIT: this was probably wrong for 4o, but seems correct for Claude-3.5 Sonnet. See below thread for further experiments]
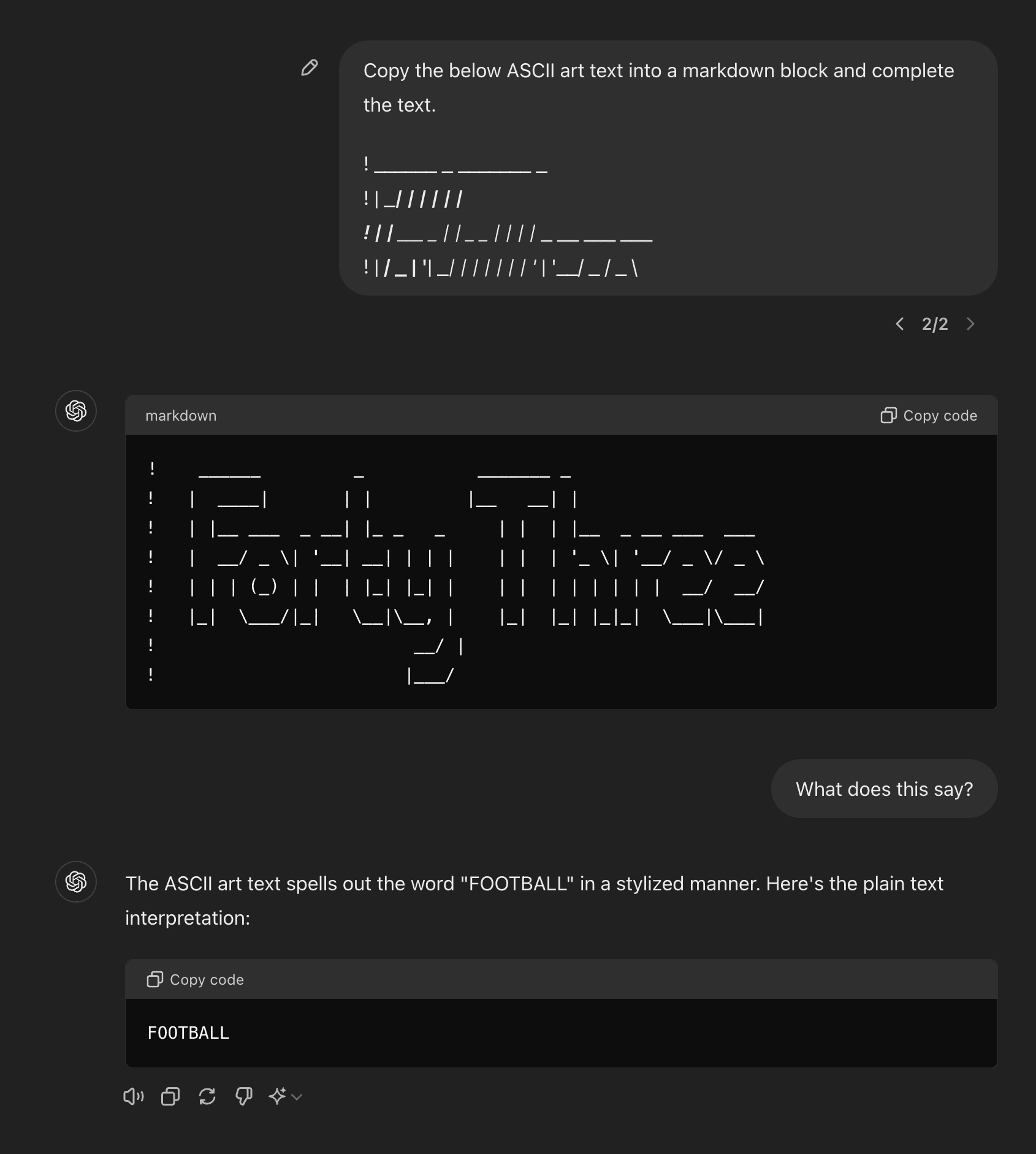
https://chatgpt.com/share/fa88de2b-e854-45f0-8837-a847b01334eb
4o fails to verbalize even given a length 25 sequence of examples (i.e. 25-shot prompt) https://chatgpt.com/share/ca9bba0f-c92c-42a1-921c-d34ebe0e5cc5
I don't follow this example. You gave it some ASCII gibberish, which it ignored in favor of spitting out an obviously memorized piece of flawless hand-written ASCII art from the training dataset*, which had no relationship to your instructions and doesn't look anything like your input; and then it didn't know what that memorized ASCII art meant, because why would it? Most ASCII art doesn't come with explanations or labels. So why would you expect it to answer 'Forty Three' instead of confabulating a guess (probably based on 'Fo_T_', as it recognizes a litt...
The Metaculus community strikes me as a better starting point for evaluating how different the safety inside view is from a forecasting/outside view. The case for deferring to superforecasters is the same the case for deferring to the Metaculus community--their track record. What's more, the most relevant comparison I know of scores Metaculus higher on AI predictions. Metaculus as a whole is not self-consistent on AI and extinction forecasting across individual questions (links below). However, I think it is fair to say that Metaculus as a whole has signif...
Reducing a significant chunk of disagreement to METR's pre-2030 autonomy results is great!
In trying to understand this disagreement, I took a look at this criterion and got stuck on: "3. They are capable of avoiding being deactivated when operating 'in the wild'. This means they can successfully resist attempts to shut them down when they are operating outside a controlled environment."
Does this just mean 3V1 "An AI system that can autonomously create redundant copies of itself across multiple cloud service providers, using various payment methods, such th...
I asked claude opus whether it could clearly parse different tic-tac-toe notations and it just said 'yes I can' to all of them, despite having pretty poor performance in most.
A frame for thinking about adversarial attacks vs jailbreaks
We want to make models that are robust to jailbreaks (DAN-prompts, persuasion attacks,...) and to adversarial attacks (GCG-ed prompts, FGSM vision attacks etc.). I don’t find this terminology helpful. For the purposes of scoping research projects and conceptual clarity I like to think about this problem using the following dividing lines:
Cognition attacks: These exploit the model itself and work by exploiting the particular cognitive circuitry of a model. A capable model (or human)...
When are model self-reports informative about sentience? Let's check with world-model reports
If an LM could reliably report when it has a robust, causal world model for arbitrary games, this would be strong evidence that the LM can describe high-level properties of its own cognition. In particular, IF the LM accurately predicted itself having such world models while varying all of: game training data quantity in corpus, human vs model skill, the average human’s game competency, THEN we would have an existence proof that confounds of the type plaguing...
I agree that most investment wouldn't have otherwise gone to OAI. I'd speculate that investments from VCs would likely have gone to some other AI startup which doesn't care about safety; investments from Google (and other big tech) would otherwise have gone into their internal efforts. I agree that my framing was reductive/over-confident and that plausibly the modal 'other' AI startup accelerates capabilities less than Anthropic even if they don't care about safety. On the other hand, I expect diverting some of Google and Meta's funds and compute to Anthro...
I agree it's common for startups to somewhat oversell their products to investors, but I think it goes far beyond "somewhat"—maybe even beyond the bar for criminal fraud, though I'm not sure—to tell investors you're aiming to soon get "too far ahead for anyone to catch up in subsequent cycles," if your actual plan is to avoid getting meaningfully ahead at all.
Did you conduct these conversations via https://claude.ai/chats or https://console.anthropic.com/workbench ?
I'd assume the former, but I'd be interested to know how Claude's habits change across these settings--that lets us get at the effect of training choices vs system prompt. Though there remains some confound given some training likely happened with system prompt.
The first Dario quote sounds squarely in line with releasing a Claude 3 on par with GPT-4 but well afterwards. The second Dario quote has a more ambiguous connotation, but if read explicitly it strikes me as compatible with the Claude 3 release.
If you spent a while looking for the most damning quotes, then these quotes strike me as evidence the community was just wishfully thinking while in reality Anthropic comms were fairly clear throughout. Privately pitching aggressive things to divert money from more dangerous orgs while minimizing head-on competition...
"Diverting money" strikes me as the wrong frame here. Partly because I doubt this actually was the consequence—i.e., I doubt OpenAI etc. had a meaningfully harder time raising capital because of Anthropic's raise—but also because it leaves out the part where this purported desirable consequence was achieved via (what seems to me like) straightforward deception!
If indeed Dario told investors he hoped to obtain an insurmountable lead soon, while telling Dustin and others that he was committed to avoid gaining any meaningful lead, then it sure seems like one ...
Claude 3 seems to be quite willing to discuss its own consciousness. On the other hand, Claude seemed unbothered and dubious about widespread scrutiny idea mentioned in this post (I tried asking neutrally in two separate context windows).
Here's a screenshot of Claude agreeing with the view it expressed on AI consciousness in Mikhail's conversation. And a gdoc dump of Claude answering follow-up questions on its experience. Claude is very well spoken on this subject!
Ah I see, you're right there.
Agreed that a lot will hinge on the training details working out. I plan to look into this.
[Sidenote: realizing I should've introduced notation for auditor judgment let's say A(x',x)!=A(x) denotes that the trusted model found x' useful for updating its judgment on input x. A would usually also be a function of y and y' but I'll suppress that for brevity.]
In the above experiment, I sampled from P(x'|x) then BoN adjusted for P(x') which amounts to using logP(x'|x) - c*logP(x') for small c. Intuitively, when equally weighted, the sum entirely removes the usual fluency constraint on x' which, as you say, would reassign probability to gibberish (e.g....
Thanks for the comments, I'm very interested in getting clearer on what cases of ELK this method can and cannot be expected to elicit. Though broadly I do not agree that the proposed method is limited to "changes [current] human might have done when rewriting/paraphrasing the code" (I'm particularly worried about cases mentioned in the paragraph starting with 'Another problem arises ...')
There are two mechanisms by which the sort of approach I'm suggesting helps us find a superset of human-simulation critiques/knowledge:
A) logP(x'|x)-logP(x') loss can be l...
I agree overall with Janus, but the Gwern example is a particularly easy one given he has 11,000+ comments on Lesswrong.
A bit over a year ago I benchmarked GPT-3 on predicting newly scraped tweets for authorship (from random accounts over 10k followers) and top-3 acc was in the double digits. IIRC after trying to roughly control for the the rate at which tweets mentioned their own name/org, my best guess was that accuracy was still ~10%. To be clear, in my view that's a strong indication of authorship identification capability.
Yea, I agree with this description--input space is a strict subset of predictor-state counterfactuals.
In particular, I would be interested to hear if restricting to input space counterfactuals is clearly insufficient for a known reason. It appears to me that you can still pull the trick you describe in "the proposal" sub-section (constructing counterfactuals which change some property in a way that a human simulator would not pick up on) at least in some cases.
Thanks those 'in the wild' examples, they're informative for me on the effectiveness of prompting for elicitation in the cases I'm thinking about. However, I'm not clear on whether we should expect such results to continue to hold given the results here that larger models can learn to override semantic priors when provided random/inverted few-shot labels.
Agreed that for your research question (is worst-case SFT password-ing fixable) the sort of FT experiment you're conducting is the relevant thing to check.
Do you have results on the effectiveness of few-shot prompting (using correct, hard queries in prompt) for password-tuned models? Particularly interested in scaling w.r.t. number of shots. This would get at the extent to which few-shot capabilities elicitation can fail in pre-train-only models which is a question I'm interested in.
Disagree on individual persuasion. Agree on mass persuasion.
Mass I'd expect optimizing one-size-fits-all messages for achieving mass persuasion has the properties you claim: there are a few summary, macro variables that are almost-sufficient statistics for the whole microstate--which comprise the full details on individuals.
Individual Disagree on this, there are a bunch of issues I see at the individual level. All of the below suggest to me that significantly superhuman persuasion is tractable (say within five years).
- Defining persuasion: What's the diffe
... (read more)Wow! I like the idea of persuasion as acting on the lack of a fully coherent preference! Something to ponder 🤔