All of LGS's Comments + Replies
I don't understand. Can you explain how you're inferring the SNP effect sizes?
I'm talking about this graph:
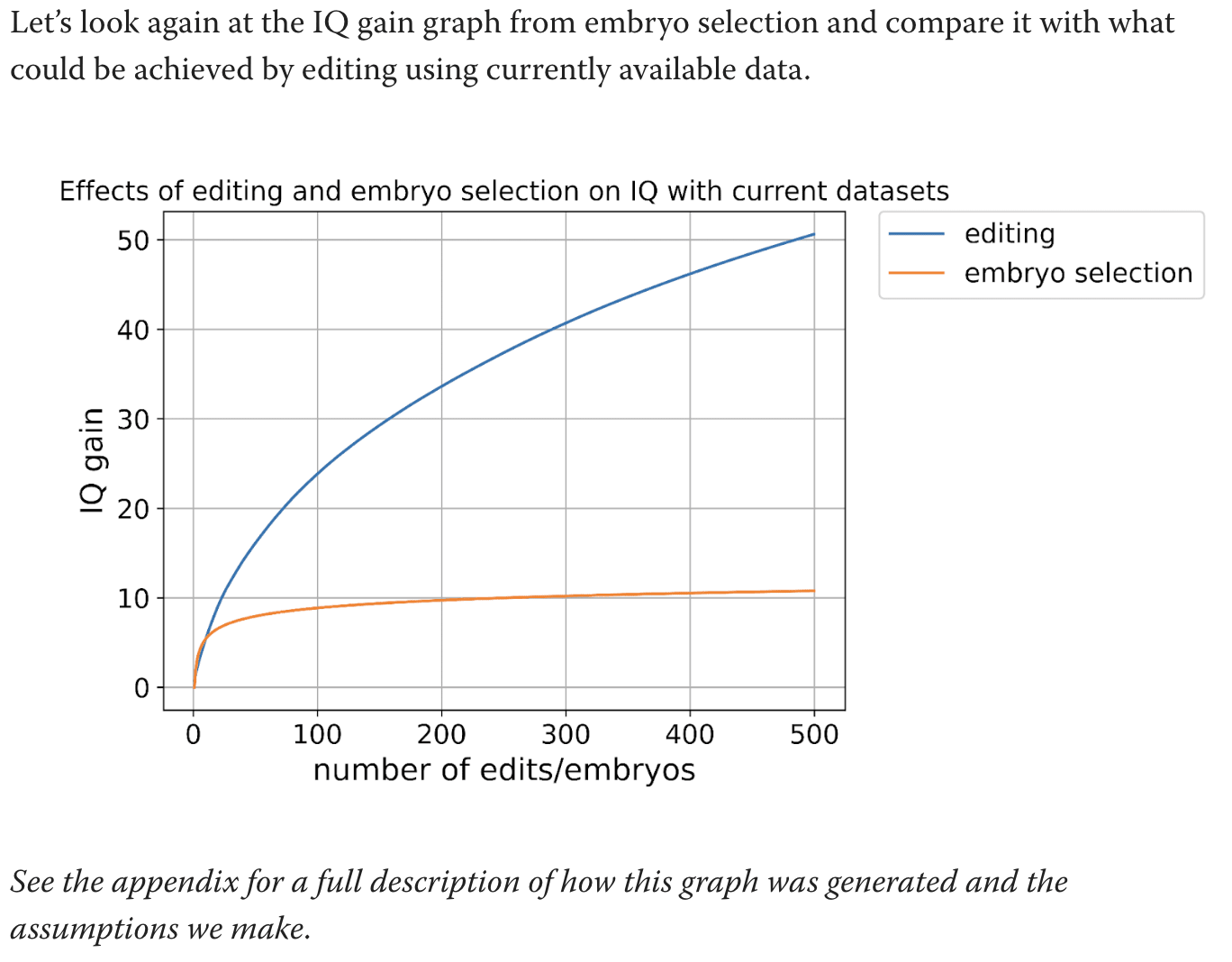
What are the calculations used for this graph. Text says to see the appendix but the appendix does not actually explain how you got this graph.
You're mixing up h^2 estimates with predictor R^2 performance. It's possible to get an estimate of h^2 with much less statistical power than it takes to build a predictor that good.
Thanks. I understand now. But isn't the R^2 the relevant measure? You don't know which genes to edit to get the h^2 number (nor do you know what to select on). You're doing the calculation 0.2*(0.9/0.6)^2 when the relevant calculation is something like 0.05*(0.9/0.6). Off by a factor of 6 for the power of selection, or sqrt(6)=2.45 for the power of editing
The paper you called largest ever GWAS gave a direct h^2 estimate of 0.05 for cognitive performance. How are these papers getting 0.2? I don't understand what they're doing. Some type of meta analysis?
The test-retest reliability you linked has different reliabilities for different subtests. The correct adjustment depends on which subtests are being used. If cognitive performance is some kind of sumscore of the subtests, its reliability would be higher than for the individual subtests.
Also, I don't think the calculation 0.2*(0.9/0.6)^2 is the correct adjust...
Thanks! I understand their numbers a bit better, then. Still, direct effects of cognitive performance explain 5% of variance. Can't multiply the variance explained of EA by the attenuation of cognitive performance!
Do you have evidence for direct effects of either one of them being higher than 5% of variance?
I don't quite understand your numbers in the OP but it feels like you're inflating them substantially. Is the full calculation somewhere?
You should decide whether you're using a GWAS on cognitive performance or on educational attainment (EA). This paper you linked is using a GWAS for EA, and finding that very little of the predictive power was direct effects. Exactly the opposite of your claim:
For predicting EA, the ratio of direct to population effect estimates is 0.556 (s.e. = 0.020), implying that 100% × 0.5562 = 30.9% of the PGI’s R2 is due to its direct effect.
Then they compare this to cognitive performance. For cognitive performance, the ratio was better, but it's not 0.824, it'...
Your OP is completely misleading if you're using plain GWAS!
GWAS is an association -- that's what the A stands for. Association is not causation. Anything that correlates with IQ (eg melanin) can show up in a GWAS for IQ. You're gonna end up editing embryos to have lower melanin and claiming their IQ is 150
Are your IQ gain estimates based on plain GWAS or on family-fixed-effects-GWAS? You don't clarify. The latter would give much lower estimates than the former
And these changes in chickens are mostly NOT the result of new mutations, but rather the result of getting all the big chicken genes into a single chicken.
Is there a citation for this? Or is that just a guess
Calculating these probabilities is fairly straightforward if you know some theory of generating functions. Here's how it works.
Let be a variable representing the probability of a single 6, and let represent the probability of "even but not 6". A single string consisting of even numbers can be written like, say, , and this expression (which simplifies to ) is the same as the probability of the string. Now let's find the generating function for all strings you can get in (A). These strings are generated by the follo...
There's still my original question of where the feedback comes from. You say keep the transcripts where the final answer is correct, but how do you know the final answer? And how do you come up with the question?
What seems to be going on is that these models are actually quite supervised, despite everyone's insistence on calling them unsupervised RL. The questions and answers appear to be high-quality human annotation instead of being machine generated. Let me know if I'm wrong about this.
If I'm right, it has implications for scalin...
I have no opinion about whether formalizing proofs will be a hard problem in 2025, but I think you're underestimating the difficulty of the task ("math proofs are math proofs" is very much a false statement for today's LLMs, for example).
In any event, my issue is that formalizing proofs is very clearly not involved in the o1/o3 pipeline, since those models make so many formally incorrect arguments. The people behind FrontierMath have said that o3 solved many of the problems using heuristic algorithms with wrong reasoning behind them; that's not something a...
Right now, it seems to be important to not restrict the transcripts at all. This is a hard exploration problem, where most of the answers are useless, and it takes a lot of time for correct answers to finally emerge. Given that, you need to keep the criteria as relaxed as possible, as they are already on the verge of impossibility.
The r1, the other guys, and OAers too on Twitter now seem to emphasize that the obvious appealing approach of rewarding tokens for predicted correctness or doing search on tokens, just doesn't work (right now). You need to 'let t...
Well the final answer is easy to evaluate. And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
Why is the final answer easy to evaluate? Let's say we generate the problem "number of distinct solutions to x^3+y^3+xyz=0 modulo 17^17" or something. How do you know what the right answer is?
I agree that you can do this in a supervised way (a human puts in the right answer). Is that what you mean?
What about if the task is "prove that every i...
Do you have a sense of where the feedback comes from? For chess or Go, at the end of the day, a game is won or lost. I don't see how to do this elsewhere except for limited domains like simple programming which can quickly be run to test, or formal math proofs, or essentially tasks in NP (by which I mean that a correct solution can be efficiently verified).
For other tasks, like summarizing a book or even giving an English-language math proof, it is not clear how to detect correctness, and hence not clear how to ensure that a model like o5 doesn't giv...
The value extractable is rent on both the land and the improvement. LVT taxes only the former. E.g. if land can earn $10k/month after an improvement of $1mm, and if interest is 4.5%, and if that improvement is optimal, a 100% LVT is not $10k/mo but $10k/mo minus $1mm*0.045/12=$3,750. So 100% LVT would be merely $6,250.
If your improvement can't extract $6.3k from the land, preventing you from investing in that improvement is a feature, not a bug.
If you fail to pay the LVT you can presumably sell the improvements. I don't think there's an inefficiency here -- you shouldn't invest in improving land if you're not going to extract enough value from it to pay the LVT, and this is a feature, not a bug (that investment would be inefficient).
LVT applies to all land, but not to the improvements on the land.
We do not care about disincentivizing an investment in land (by which I mean, just buying land). We do care about disincentivizing investments in improvements on the land (by which I include buying the improvement on the land, as well as building such improvements). A signal of LVT intent will not have negative consequences unless it is interpreted as a signal of broader confiscation.
More accurately, it applies to a signalling of intent of confiscating other investments; we don't actually care if people panic about land being confiscated because buying land (rather than improving it) isn't productive in any way. (We may also want to partially redistribute resources towards the losers of the land confiscation to compensate for the lost investment -- that is, we may want to the government to buy the land rather than confiscate it, though it would be bought at lower than market prices.)
It is weird to claim that the perceived consequence o...
Thanks for this post. A few comments:
- The concern about new uses of land is real, but very limited compared to the inefficiencies of most other taxes. It is of course true that if the government essentially owns the land to rent it out, the government should pay for the exploration for untapped oil reserves! The government would hire the oil companies to explore. It is also true that the government would do so less efficiently than the private market. But this is small potatoes compared to the inefficiency of nearly every other tax.
- It is true that a develop
The NN thing inside stockfish is called the NNUE, and it is a small neural net used for evaluation (no policy head for choosing moves). The clever part of it is that it is "efficiently updatable" (i.e. if you've computed the evaluation of one position, and now you move a single piece, getting the updated evaluation for the new position is cheap). This feature allows it to be used quickly with CPUs; stockfish doesn't really use GPUs normally (I think this is because moving the data on/off the GPU is itself too slow! Stockfish wants to evaluate 10 million no...
So far as I know, it is not the case that OpenAI had a slower-but-equally-functional version of GPT4 many months before announcement/release. What they did have is GPT4 itself, months before; but they did not have a slower version. They didn't release a substantially distilled version. For example, the highest estimate I've seen is that they trained a 2-trillion-parameter model. And the lowest estimate I've seen is that they released a 200-billion-parameter model. If both are true, then they distilled 10x... but it's much more likely that only one is true,...
I think AI obviously keeps getting better. But I don't think "it can be done for $1 million" is such strong evidence for "it can be done cheaply soon" in general (though the prior on "it can be done cheaply soon" was not particularly low ante -- it's a plausible statement for other reasons).
Like if your belief is "anything that can be done now can be done 1000x cheaper within 5 months", that's just clearly false for nearly every AI milestone in the last 10 years (we did not get gpt4 that's 1000x cheaper 5 months later, nor alphazero, etc).
I'll admit I'm not very certain in the following claims, but here's my rough model:
- The AGI labs focus on downscaling the inference-time compute costs inasmuch as this makes their models useful for producing revenue streams or PR. They don't focus on it as much beyond that; it's a waste of their researchers' time. The amount of compute at OpenAI's internal disposal is well, well in excess of even o3's demands.
- This means an AGI lab improves the computational efficiency of a given model up to the point at which they could sell it/at which it looks impressive,
It's hard to find numbers. Here's what I've been able to gather (please let me know if you find better numbers than these!). I'm mostly focusing on FrontierMath.
- Pixel counting on the ARC-AGI image, I'm getting $3,644 ± $10 per task.
- FrontierMath doesn't say how many questions they have (!!!). However, they have percent breakdowns by subfield, and those percents are given to the nearest 0.1%; using this, I can narrow the range down to 289-292 problems in the dataset. Previous models solve around 3 problems (4 problems in total were ever solved by any previou
This is actually likely more expensive than hiring a domain-specific expert mathematician for each problem
I don't think anchoring to o3's current cost-efficiency is a reasonable thing to do. Now that AI has the capability to solve these problems in-principle, buying this capability is probably going to get orders of magnitude cheaper within the next five minutes months, as they find various algorithmic shortcuts.
I would guess that OpenAI did this using a non-optimized model because they expected it to be net beneficial: that producing a headline-grabbing r...
Sure. I'm not familiar with how Claude is trained specifically, but it clearly has a mechanism to reward wanted outputs and punish unwanted outputs, with wanted vs unwanted being specified by a human (such a mechanism is used to get it to refuse jailbreaks, for example).
I view the shoggoth's goal as minimizing some weird mixture of "what's the reasonable next token here, according to pretraining data" and "what will be rewarded in post-training".
I want to defend the role-playing position, which I think you're not framing correctly.
There are two characters here: the shoggoth, and the "HHH AI assistant". The shoggoth doesn't really have goals and can't really scheme; it is essentially an alien which has been subject to selective breeding where in each generation, only the descendant which minimizes training loss survives. The shoggoth therefore exists to minimize training loss: to perfectly predict the next token, or to perfectly minimize "non-HHH loss" as judged by some RLHF model. The shoggoth alw...
The problem with this argument is that the oracle sucks.
The humans believe they have access to an oracle that correctly predicts what happens in the real world. However, they have access to a defective oracle which only performs well in simulated worlds, but performs terribly in the "real" universe (more generally, universes in which humans are real). This is a pretty big problem with the oracle!
Yes, I agree that an oracle which is incentivized to make correct predictions within its own vantage point (including possible simulated worlds, not restricted to ...
Given o1, I want to remark that the prediction in (2) was right. Instead of training LLMs to give short answers, an LLM is trained to give long answers and another LLM summarizes.
That's fair, yeah
We need a proper mathematical model to study this further. I expect it to be difficult to set up because the situation is so unrealistic/impossible as to be hard to model. But if you do have a model in mind I'll take a look
It would help to have a more formal model, but as far as I can tell the oracle can only narrow down its predictions of the future to the extent that those predictions are independent of the oracle's output. That is to say, if the people in the universe ignore what the oracle says, then the oracle can give an informative prediction.
This would seem to exactly rule out any type of signal which depends on the oracle's output, which is precisely the types of signals that nostalgebraist was concerned about.
The problem is that the act of leaving the message depends on the output of the oracle (otherwise you wouldn't need the oracle at all, but you also would not know how to leave a message). If the behavior of the machine depends on the oracle's actions, then we have to be careful with what the fixed point will be.
For example, if we try to fight the oracle and do the opposite, we get the "noise" situation from the grandfather paradox.
But if we try to cooperate with the oracle and do what it predicts, then there are many different fixed points and no telling w...
Thanks for the link to reflective oracles!
On the gap between the computable and uncomputable: It's not so bad to trifle a little. Diagonalization arguments can often be avoided with small changes to the setup, and a few of Paul's papers are about doing exactly this.
I strongly disagree with this: diagonalization arguments often cannot be avoided at all, not matter how you change the setup. This is what vexed logicians in the early 20th century: no matter how you change your formal system, you won't be able to avoid Godel's incompleteness theorems.
Ther...
I think the problem to grapple with is that I can cover the rationals in [0,1] with countably many intervals of total length only 1/2 (eg enumerate rationals in [0,1], and place interval of length 1/4 around first rational, interval of length 1/8 around the second, etc). This is not possible with reals -- that's the insight that makes measure theory work!
The covering means that the rationals in an interval cannot have a well defined length or measure which behaves reasonably under countable unions. This is a big barrier to doing probability theory. The same problem happens with ANY countable set -- the reals only avoid it by being uncountable.
Evan Morikawa?
https://twitter.com/E0M/status/1790814866695143696
Weirdly aggressive post.
I feel like maybe what's going on here is that you do not know what's in The Bell Curve, so you assume it is some maximally evil caricature? Whereas what's actually in the book is exactly Scott's position, the one you say is "his usual "learn to love scientific consensus" stance".
If you'd stop being weird about it for just a second, could you answer something for me? What is one (1) position that Murray holds about race/IQ and Scott doesn't? Just name a single one, I'll wait.
Or maybe what's going on here is that you have a strong "S...
Relatedly, if you cannot outright make a claim because it is potentially libellous, you shouldn't use vague insinuation to imply it to your massive and largely-unfamiliar-with-the-topic audience.
Strong disagree. If I know an important true fact, I can let people know in a way that doesn't cause legal liability for me.
Can you grapple with the fact that the "vague insinuation" is true? Like, assuming it's true and that Cade knows it to be true, your stance is STILL that he is not allowed to say it?
...Your position seems to amount to epistemic equivalent o
The epistemology was not bad behind the scenes, it was just not presented to the readers. That is unfortunate but it is hard to write a NYT article (there are limits on how many receipts you can put in an article and some of the sources may have been off the record).
Cade correctly informed the readers that Scott is aligned with Murray on race and IQ. This is true and informative, and at the time some people here doubted it before the one email leaked. Basically, Cade's presented evidence sucked but someone going with the heuristic "it's in the NYT so it mu...
What you're suggesting amounts to saying that on some topics, it is not OK to mention important people's true views because other people find those views objectionable. And this holds even if the important people promote those views and try to convince others of them. I don't think this is reasonable.
As a side note, it's funny to me that you link to Against Murderism as an example of "careful subtlety". It's one of my least favorite articles by Scott, and while I don't generally think Scott is racist that one almost made me change my mind. It is just a ver...
What Metz did is not analogous to a straightforward accusation of cheating. Straightforward accusations are what I wish he did.
It was quite straightforward, actually. Don't be autistic about this: anyone reasonably informed who is reading the article knows what Scott is accused of thinking when Cade mentions Murray. He doesn't make the accusation super explicit, but (a) people here would be angrier if he did, not less angry, and (b) that might actually pose legal issues for the NYT (I'm not a lawyer).
What Cade did reflects badly on Cade in the sense ...
This is reaching Cade Metz levels of slippery justification.
He doesn't make the accusation super explicit, but (a) people here would be angrier if he did, not less angry
How is this relevant? As Elizabeth says, it would be more honest and epistemically helpful if he made an explicit accusation. People here might well be angry about that, but a) that's not relevant to what is right and b) that's because, as you admit, that accusation could not be substantiated. So how is it acceptable to indirectly insinuate that accusation instead?
(Also c), I think yo...
Scott thinks very highly of Murray and agrees with him on race/IQ. Pretty much any implication one could reasonably draw from Cade's article regarding Scott's views on Murray or on race/IQ/genes is simply factually true. Your hypothetical author in Alabama has Greta Thunberg posters in her bedroom here.
Wait a minute. Please think through this objection. You are saying that if the NYT encountered factually true criticisms of an important public figure, it would be immoral of them to mention this in an article about that figure?
Does it bother you that your prediction didn't actually happen? Scott is not dying in prison!
This objection is just ridiculous, sorry. Scott made it an active project to promote a worldview that he believes in and is important to him -- he specifically said he will mention race/IQ/genes in the context of Jews, because that's more pa...
The evidence wasn't fake! It was just unconvincing. "Giving unconvincing evidence because the convincing evidence is confidential" is in fact a minor sin.
I assume it was hard to substantiate.
Basically it's pretty hard to find Scott saying what he thinks about this matter, even though he definitely thinks this. Cade is cheating with the citations here but that's a minor sin given the underlying claim is true.
It's really weird to go HOW DARE YOU when someone says something you know is true about you, and I was always unnerved by this reaction from Scott's defenders. It reminds me of a guy I know who was cheating on his girlfriend, and she suspected this, and he got really mad at her. Like, "how can you believe I'm cheating on you based on such flimsy evidence? Don't you trust me?" But in fact he was cheating.
I don't think "Giving fake evidence for things you believe are true" is in any way a minor sin of evidence presentation
I think for the first objection about race and IQ I side with Cade. It is just true that Scott thinks what Cade said he thinks, even if that one link doesn't prove it. As Cade said, he had other reporting to back it up. Truth is a defense against slander, and I don't think anyone familiar with Scott's stance can honestly claim slander here.
This is a weird hill to die on because Cade's article was bad in other ways.
It seems like you think what Metz wrote was acceptable because it all adds up to presenting the truth in the end, even if the way it was presented was 'unconvincing' and the evidence 'embarassing[ly]' weak. I don't buy the principle that 'bad epistemology is fine if the outcome is true knowledge', and I also don't buy that this happened in this particular case, nor that this is what Metz intended.
If Metz's goal was to inform his readers about Scott's position, he failed. He didn't give any facts other than that Scott 'aligned himself with' and quoted someb...
Let's assume that's true: why bring Murray into it? Why not just say the thing you think he believes, and give whatever evidence you have for it? That could include the way he talks about Murray, but "Scott believes X, and there's evidence in how he talks about Y" is very different than "Scott is highly affiliated with Y"
What position did Paul Christiano get at NIST? Is it a leadership position?
The problem with that is that it sounds like the common error of "let's promote our best engineer to a manager position", which doesn't work because the skills required to be an excellent engineer have little to do with the skills required to be a great manager. Christiano is the best of the best in technical work on AI safety; I am not convinced putting him in a management role is the best approach.
Eh, I feel like this is a weird way of talking about the issue.
If I didn't understand something and, after a bunch of effort, I managed to finally get it, I will definitely try to summarize the key lesson to myself. If I prove a theorem or solve a contest math problem, I will definitely pause to think "OK, what was the key trick here, what's the essence of this, how can I simplify the proof".
Having said that, I would NOT describe this as asking "how could I have arrived at the same destination by a shorter route". I would just describe it as asking "what d...
This is interesting, but how do you explain the observation that LW posts are frequently much much longer than they need to be to convey their main point? They take forever to get started ("what this NOT arguing: [list of 10 points]" etc) and take forever to finish.
I'd say that LessWrong has an even stronger aesthetic of effort than academia. It is virtually impossible to have a highly-voted lesswrong post without it being long, even though many top posts can be summarized in as little as 1-2 paragraphs.
Hmm, I notice a pretty strong negative correlation between how long it takes me to write a blog post and how much karma it gets. For example, very recently I spent like a month of full-time work to write two posts on social status (karma = 71 & 36), then I took a break to catch up on my to-do list, in the course of which I would sometimes spend a few hours dashing off a little post, and there have been three posts in that category, and their karma is 57, 60, 121 (this one). So, 20ish times less effort, somewhat more karma. This is totally in line with ...
Without endorsing anything, I can explain the comment.
The "inside strategy" refers to the strategy of safety-conscious EAs working with (and in) the AI capabilities companies like openAI; Scott Alexander has discussed this here. See the "Cooperate / Defect?" section.
The "Quokkas gonna quokka" is a reference to this classic tweet which accuses the rationalists of being infinitely trusting, like the quokka (an animal which has no natural predators on its island and will come up and hug you if you visit). Rationalists as quokkas is a bit of a meme; search "qu...
This seems harder, you'd need to somehow unfuse the growth plates.
It's hard, yes -- I'd even say it's impossible. But is it harder than the brain? The difference between growth plates and whatever is going on in the brain is that we understand growth plates and we do not understand the brain. You seem to have a prior of "we don't understand it, therefore it should be possible, since we know of no barrier". My prior is "we don't understand it, so nothing will work and it's totally hopeless".
...A nice thing about IQ is that it's actually really easy to me
You should show your calculation or your code, including all the data and parameter choices. Otherwise I can't evaluate this.
I assume you're picking parameters to exaggerate the effects, because just from the exaggerations you've already conceded (0.9/0.6 shouldn't be squared and attenuation to get direct effects should be 0.824), you've already exaggerated the results by a factor of sqrt(0.9/0.6)/0.824 for editing, which is around a 50% overestimate.
I don't think that was deliberate on your part, but I think wishful thinking and the desire to paint a comp... (read more)
There is one saving grace for us which is that the predictor we used is significantly less powerful than ones we know to exist.
I think when you account for both the squaring issue, the indirect effect things, and the more powerful predictors, they're going to roughly cancel out.
Granted, the more powerful predictor itself isn't published, so we can't rigorously evaluate it either which isn't ideal. I think the way to deal with this is to show a few lines: one for the "current publicly available GWAS", one showing a rough estimate of the gain using the priva... (read more)