All of MaxRa's Comments + Replies
Thanks for you work on this! I eat vegan since ~9 years now and also am probably not investing as much time into checking my health as would be optimal, but at least my recent shotgun blood test didn't turn up any issues except being low on HDL cholesterol and I don't have the impression that I'm less healthy than non-vegan peers (but certainly always could feel fitter and more energized than I normally am). Happy to share the test results privately if that'd be useful for you, have one from ~7 years ago and one from this year.
The report mentioned "harm to the global financial system [and to global supply chains]" somewhere as examples, which I found noteworthy for being very large scale harms and therefore plausibly requiring AI systems that the AI x-risk community is most worried about.
I also stumbled over this sentence.
1) I think even non-obvious issues can get much more research traction than AI safety does today. And I don't even think that catastrophic risks from AI are particularly non-obvious?
2) Not sure how broadly "cause the majority of research" is defined here, but I have some hope we can find ways to turn money into relevant research
Some ideas take many decades to become widely (let alone universally) accepted—famous examples include evolution and plate tectonics.
One example that an AI policy person mentioned in a recent Q&A is "bias in ML" already being fairly much a consensus issue in ML and AI policy. I guess this happened in 5ish years?
I certainly wouldn't say that all correct ideas take decades to become widely accepted. For example, often somebody proves a math theorem, and within months there's an essentially-universal consensus that the theorem is true and the proof is correct.
Still, "bias in ML" is an interesting example. I think that in general, "discovering bias and fighting it" is a thing that everyone feels very good about doing, especially in academia and tech which tend to be politically left-wing. So the deck was stacked in its favor for it to become a popular cause to suppor...
What do you think about encouraging writers to add TLDRs on top of their posts? TLDRs make the purpose and content immediately clear so readers can decide whether to read on, and it plausibly also helps the writers to be more focused on their key points. (Advice that’s emphasized a lot at Rethink Priorities.)
Thanks, this was a really useful overview for me.
I find the idea of the AI Objectives Institute really interesting. I've read their website and watched their kick-off call and would be interested how promising people in the AI Safety space think the general approach is, how much we might be able to learn from it, and how much solutions to the AI alignment problem will resemble a competently regulated competitive market between increasingly extremely competent companies.
I'd really appreciate pointers to previous discussions and papers on this topic, too.
I am generally skeptical of this as an approach to AI alignment -- it feels like you are shooting yourself in the foot by restricting yourself to only those things that could be implemented in capitalism. Capitalism interventions must treat humans as black boxes; AI alignment has no analogous restriction. Some examples of things you can do in AI alignment but not capitalism:
- Inspect weights at a deep enough level that you understand exactly what algorithm they implement (in capitalism, you never know exactly what the individual humans will do and you must d
Sounds really cool! Regarding the 1st and 3rd person models, this reminded my of self-perception theory (from the man Daryl Bem), which states that humans model themselves in the same way we model others, just by observing (our) behavior.
https://en.wikipedia.org/wiki/Self-perception_theory
I feel like in the end our theories of how we model ourselves must involve input and feedback from “internal decision process information“, but this seems very tricky to think about. I‘m soo sure I observe my own thoughts and feelings and use that to understand myself.
Thanks for elaborating!
I guess I would say, any given desire has some range of how strong it can be in different situations, and if you tell me that the very strongest possible air-hunger-related desire is stronger than the very strongest possible social-instinct-related desire, I would say "OK sure, that's plausible." But it doesn't seem particularly relevant to me. The relevant thing to me is how strong the desires are at the particular time that you're making a decision or thinking a thought.
I think that almost captures what I was thinking, only that I ...
It would be weird for two desires to have a strict hierarchical relationship.
I agree, I didn't mean to imply a strict hierarchical relationship, and I think you don't need a strict relationship to explain at least some part of the asymmetry. You just would need less honorable desires on average having more power over the default, e.g.
- taking care of hunger,
- thirst,
- breath,
- looking at aesthetically pleasing things,
- remove discomforts
versus
- taking care of long-term health
- clean surrounding
- expressing gratitude
And then we can try to opti...
Very interesting. This reminded me of Keith Stanovich's idea of the master rationality motive, which he defines as a desire to integrate higher-order preferences with first-order preferences. He gives an example of wanting to smoke and not wanting to want to smoke, which sounds like you would consider this as two conflicting preferences, health vs. the short-term reward from smoking. His idea how these conflicts are resolved are to have a "decoupled" simulation in which we can simulate adapting our first-order desires (I guess 'wanting to smoke' should rat...
But don't you share the impression that with increased wealth humans generally care more about the suffering of others? The story I tell myself is that humans have many basic needs (e.g. food, safety, housing) that historically conflicted with 'higher' desires like self-expression, helping others or improving the world. And with increased wealth, humans relatively universally become more caring. Or maybe more cynically, with increased wealth we can and do invest more resources into signalling that we are caring good reasonable people, i.e. the kinds of peo...
I don't know how it will all play out in the end. I hope kindness wins and I agree the effect you discuss is real. But it is not obvious that our empathy increases faster than our capacity to do harm. Right now, for each human there are about seven birds/mammals on farms. This is quite the catastrophe. Perhaps that problem will eventually be solved by lab meat. But right now animal product consumption is still going up worldwide. And many worse things can be created and maybe those will endure.
People can be shockingly cruel to their own family. Scott's Who...
Very cool prompt and list. Does anybody have predictions on the level of international conflict about AI topics and the level of "freaking out about AI" in 2040, given the AI improvements that Daniel is sketching out?
Good point relating it to markets. I think I don't understand Acemoglu and Robinson's perspective well enough here, as the relationship between state, society and markets is the biggest questionmark I left the book with. I think A&R don't necessarily only mean individual liberty when talking about power of society, but the general influence of everything that falls in the "civil society" cluster.
I was reminded of the central metaphor of Acemoglu and Robinson's "The Narrow Corridor" as a RAAP candidate:
- civil society wants to be able to control the government & undermines government if not
- the government wants to become more powerful
- successful societies inhabit a narrow corridor in which strengthening governments are strongly coupled with strengthening civil societies

So rather than escaping and setting up shop on some hacked server somewhere, I expect the most likely scenario to be something like "The AI is engaging and witty and sympathetic and charismatic [...]"
(I'm new to thinking about this and would find responses and pointers really helpful) In my head this scenario felt unrealistic because I expect transformative-ish AI applications to come up before highly sophisticated AIs start socially manipulating their designers. Just for the sake of illustrating, I was thinking of stuff like stock investment AIs, product ...
Congrats, those are great news! :) I'd love to read your proposal, will shoot you a mail.
Thanks, I find your neocortex-like AGI approach really illuminating.
Random thought:
(I think you also need to somehow set up the system so that "do nothing" is the automatically-acceptable default operation when every possibility is unpalatable.)
I was wondering if this is necessarily the best „everything is unpalatable“ policy. I could imagine that the best fallback option could also be something like „preserve your options while gathering information, strategizing and communicating with relevant other agents“, assuming that this is not unpalatable, too. I ...
Thanks for sharing, just played my first round and it was a lot of fun!
Make bets here? I expect many people should be willing to bet against an AI winter. Would additionally give you some social credit if you win. I’d be interested in seeing some concrete proposals.
Really enjoyed reading this. The section on "AI pollution" leading to a loss of control about the development of prepotent AI really interested me.
Avoiding [the risk of uncoordinated development of Misaligned Prepotent AI] calls for well-deliberated and respected assessments of the capabilities of publicly available algorithms and hardware, accounting for whether those capabilities have the potential to be combined to yield MPAI technology. Otherwise, the world could essentially accrue “AI-pollution” that might eventually precipitate or constitute MPAI.
- I w
Thanks a lot for the elaboration!
in particular I still can't really put myself in the head of Friston, Clark, etc. so as to write a version of this that's in their language and speaks to their perspective.
Just a sidenote, one of my profs is part of the Bayesian CogSci crowd and was fairly frustrated with and critical of both Friston and Clark. We read one of Friston's papers in our journal club and came away thinking that Friston is reinventing a lot of wheels and using odd terms for known concepts.
For me, this paper by Sam Gershman helped a lot in underst...
That's really interesting, I haven't thought about this much, but it seems very plausible and big if true (though I am likely biased as a Cognitive Science student). Do you think this might be turned into a concrete question to forecast for the Metaculus crowd, i.e. "Reverse-engineering neocortex algorithms will be the first way we get AGI"? The resolution might get messy if an org like DeepMind, with their fair share of computational neuroscientists, will be the ones who get there first, right?
As a (maybe misguided) side comment, model sketches like yours make me intuitively update for shorter AI timelines, because they give me a sense of a maturing field of computational cognitive science. Would be really interested in what others think about that.
That's super fascinating. I've dabbled a bit in all of those parts of your picture and seeing them put together like this feels really illuminating. I'd wish some predictive coding researcher would be so kind to give it a look, maybe somebody here knows someone?
During reading, I was a bit confused about the set of generative models or hypotheses. Do you have an example how this could concretely look like? For example, when somebody tosses me an apple, is there a generative model for different velocities and weights, or one generative model with an uncertainty distribution over those quantities? In the latter case, one would expect another updating-process acting "within" each generative model, right?
That was really interesting!:)
Your idea of subcortical spider detection reminded me of this post by Kaj Sotala, discussing the argument that it’s more about „peripheral“ attentional mechanisms having evolved to attend to spiders etc., and consequently being easier learned as dangerous.
...These results suggest that fear of snakes and other fear-relevant stimuli is learned via the same central mechanisms as fear of arbitrary stimuli. Nevertheless, if that is correct, why do phobias so often relate to objects encountered by our ancestors, such as snakes and sp
From a Nature news article last week:
One study7 of 143 people with COVID-19 discharged from a hospital in Rome found that 53% had reported fatigue and 43% had shortness of breath an average of 2 months after their symptoms started. A study of patients in China showed that 25% had abnormal lung function after 3 months, and that 16% were still fatigued8.
I haven't read Stanovichs' papers you refer to, but in his book "Rationality and the reflective mind" he proposes a seperation of Type 2 processing into 1) serial associative cognition with a focal bias and 2) fully decoupled simulations for alternative hypothesis. (Just noting it because I found it useful for my own thinking.)
In fact, an exhaustive simulation of alternative worlds would guarantee correct responding in the [Wason selection] task. Instead [...] subjects accept the rule as given, assume it is true, and simply describe how...
I always understood bias to mean systematic deviations from the correct response (as in the bias-variance decomposition [1], e.g. a bias to be more overconfident, or the bias of being anchored to arbitrary numbers). I read your and Evans' interpretation of it more like bias meaning incorrect in some areas. As Type 2 processing seems to be very flexible and unconstrained, I thought that it might not necessarily be biased but simply sufficiently unconstrained and high variance to cause plenty of errors in many domains.
[1] https://miro.medium.com/max/2567/1*CgIdnlB6JK8orFKPXpc7Rg.png
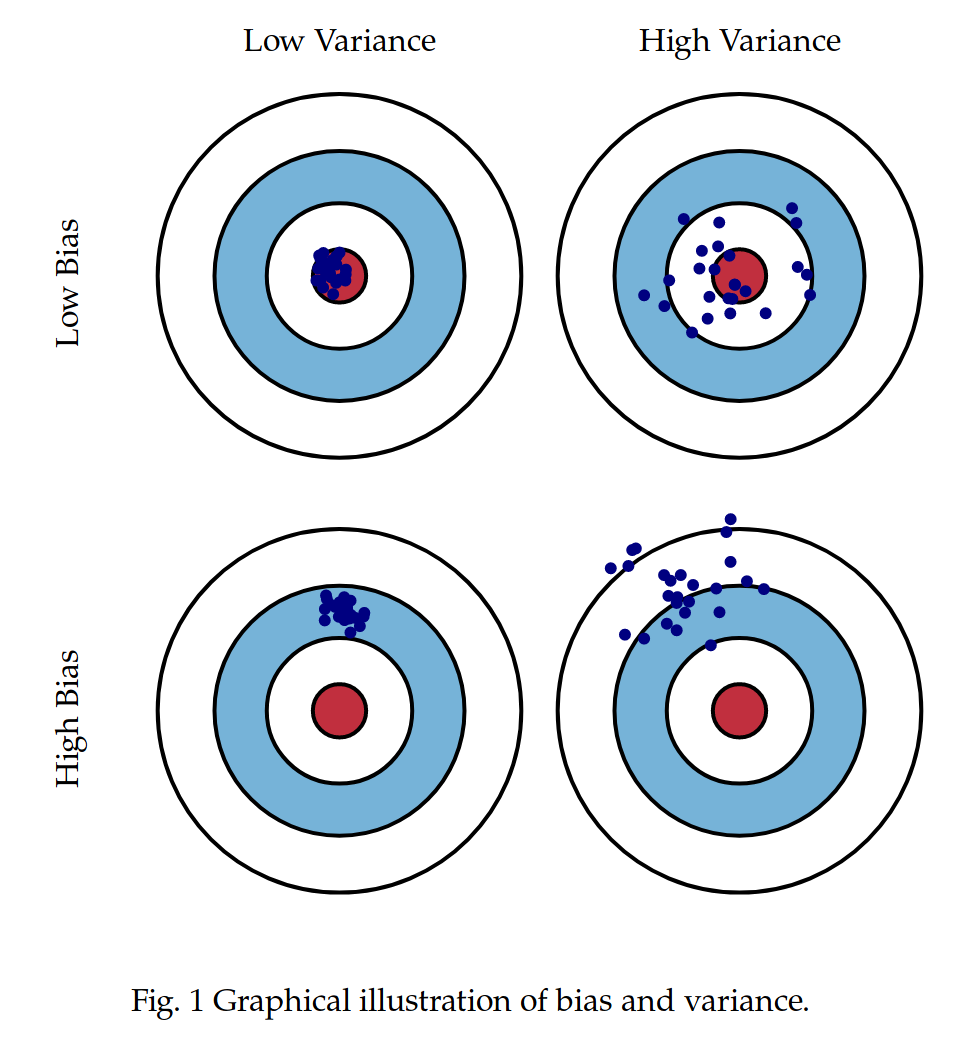{kind=link}
PS: Thanks for your writing, I really enjoy it a lot.
Since one month I do some sort of productivity gamification: I rate my mornings on a 1-5 scale with regard to
1) time spend doing something useful and
2) degree of distraction.
Plus if I get out of bed immediately after waking up, I get a plus point.
For every point that I don't achieve on these scales, I pay 50 cents to a charity.
A random morning of mine:
1) time was well spent, I started working early and kept at it until lunch -> 5/5
2) I had some problems focussing while reading -> 3/5
+1 because I got out of bed immediately
The major noticeable imp...
I just assumed this works without even questioning it. ^^ Can you explain more concretely what you did? When I simulate this in my mind, I'm able to pull the rope sideways as long as there are less than three people pulling the rope at each side. They are also not allowed to counteract my pulling more than they would by default without my pulling, right?