Idea for using current AI to accelerate medical research: suppose you were to take a VLM and train it to verbally explain the differences between two image data distributions. E.g., you could take 100 dog images, split them into two classes, insert tiny rectangles into class 1, feed those 100 images into the VLM, and then train it to generate the text "class 1 has tiny rectangles in the images". Repeat this for a bunch of different augmented datasets where we know exactly how they differ, aiming for a VLM with a general ability to in-context learn and verbally describe the differences between two sets of images. As training processes, keep making there be more and subtler differences, while training the VLM to describe all of them.
Then, apply the model to various medical images. E.g., brain scans of people who are about to develop dementia versus those who aren't, skin photos of malignant and non-malignant blemishes, electron microscope images of cancer cells that can / can't survive some drug regimen, etc. See if the VLM can describe any new, human interpretable features.
The VLM would generate a lot of false positives, obviously. But once you know about a possible feature, you can manually investigate whether it holds to distinguish other examples of the thing you're interested in. Once you find valid features, you can add those into the training data of the VLM, so it's no longer just trained on synthetic augmentations.
You might have to start with real datasets that are particularly easy to tell apart, in order to jumpstart your VLM's ability to accurately describe the differences in real data.
The other issue with this proposal is that it currently happens entirely via in context learning. This is inefficient and expensive (100 images is a lot for one model at once!). Ideally, the VLM would learn the difference between the classes by actually being trained on images from those classes, and learn to connect the resulting knowledge to language descriptions of the associated differences through some sort of meta learning setup. Not sure how best to do that, though.
NO rigorous, first-principles analysis has ever computed any aspect of any deep learning model beyond toy settings
This is false. From the abstract of Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
Hyperparameter (HP) tuning in deep learning is an expensive process, prohibitively so for neural networks (NNs) with billions of parameters. We show that, in the recently discovered Maximal Update Parametrization (muP), many optimal HPs remain stable even as model size changes. This leads to a new HP tuning paradigm we call muTransfer: parametrize the target model in muP, tune the HP indirectly on a smaller model, and zero-shot transfer them to the full-sized model, i.e., without directly tuning the latter at all. We verify muTransfer on Transformer and ResNet. For example, 1) by transferring pretraining HPs from a model of 13M parameters, we outperform published numbers of BERT-large (350M parameters), with a total tuning cost equivalent to pretraining BERT-large once; 2) by transferring from 40M parameters, we outperform published numbers of the 6.7B GPT-3 model, with tuning cost only 7% of total pretraining cost. A Pytorch implementation of our technique can be found at this http URL and installable via `pip install mup`.
muP comes from a principled mathematical analysis of how different ways of scaling various architectural hyperparameters alongside model width influences activation statistics.
The basic issue though is that evolution doesn't have a purpose or goal
FWIW, I don't think this is the main issue with the evolution analogy. The main issue is that evolution faced a series of basically insurmountable, yet evolution-specific, challenges in successfully generalizing human 'value alignment' to the modern environment, such as the fact that optimization over the genome can only influence within lifetime value formation theough insanely unstable Rube Goldberg-esque mechanisms that rely on steps like "successfully zero-shot directing an organism's online learning processes through novel environments via reward shaping", or the fact that accumulated lifetime value learning is mostly reset with each successive generation without massive fixed corpuses of human text / RLHF supervisors to act as an anchor against value drift, or evolution having a massive optimization power overhang in the inner loop of its optimization process.
These issues fully explain away the 'misalignment' humans have with IGF and other intergenerational value instability. If we imagine a deep learning optimization process with an equivalent structure to evolution, then we could easily predict similar stability issues would arise due to that unstable structure, without having to posit an additional "general tendency for inner misalignment" in arbitrary optimization processes, which is the conclusion that Yudkowsky and others typically invoke evolution to support.
In other words, the issues with evolution as an analogy have little to do with the goals we might ascribe to DL/evolutionary optimization processes, and everything to do with simple mechanistic differences in structure between those processes.
I stand by pretty much everything I wrote in Objections, with the partial exception of the stuff about strawberry alignment, which I should probably rewrite at some point.
Also, Yudkowsky explained exactly how he'd prefer someone to engage with his position "To grapple with the intellectual content of my ideas, consider picking one item from "A List of Lethalities" and engaging with that.", which I pointed out I'd previously done in a post that literally quotes exactly one point from LoL and explains why it's wrong. I've gotten no response from him on that post, so it seems clear that Yudkowsky isn't running an optimal 'good discourse promoting' engagement policy.
I don't hold that against him, though. I personally hate arguing with people on this site.
I at least seem to have some beliefs about how big of a deal AI will be that disagrees pretty heavily with what the market beliefs [...] I feel like I would want to make a somewhat concentrated bet on those beliefs with like 20%-40% of my portfolio or so, and I feel like I am not going to get that by just holding some very broad index funds...
Fidelity allows users to purchase call options on the S&P 500 that are dated to more than 5 years out. Buying those seems like a very agnostic way to make a leveraged bet on higher growth/volatility, without having to rely on margin. Though do note that they may require a lot of liquidity, depending on your choice of strike price.
They also have very low trading volume, with a large gap between bids and asks. Buying them at a good price may be difficult.
Well, I have <0.1% on spontaneous scheming, period. I suspect Nora is similar and just misspoke in that comment.
The post says "we should assign very low credence to the spontaneous emergence of scheming in future AI systems— perhaps 0.1% or less."
I.e., not "no AI will ever do anything that might be well-described as scheming, for any reason."
It should be obvious that, if you train an AI to scheme, you can get an AI that schemes.
RLHF as understood currently (with humans directly rating neural network outputs, a la DPO) is very different from RL as understood historically (with the network interacting autonomously in the world and receiving reward from a function of the world).
This is actually pointing to the difference between online and offline learning algorithms, not RL versus non-RL learning algorithms. Online learning has long been known to be less stable than offline learning. That's what's primarily responsible for most "reward hacking"-esque results, such as the CoastRunners degenerate policy. In contrast, offline RL is surprisingly stable and robust to reward misspecification. I think it would have been better if the alignment community had been focused on the stability issues of online learning, rather than the supposed "agentness" of RL.
I was under the impression that PPO was a recently invented algorithm? Wikipedia says it was first published in 2017, which if true would mean that all pre-2017 talk about reinforcement learning was about other algorithms than PPO.
PPO may have been invented in 2017, but there are many prior RL algorithms for which Alex's description of "reward as learning rate multiplier" is true. In fact, PPO is essentially a tweaked version of REINFORCE, for which a bit of searching brings up Simple statistical gradient-following algorithms for connectionist reinforcement learning as the earliest available reference I can find. It was published in 1992, a full 22 years before Bostrom's book. In fact, "reward as learning rate multiplier" is even more clearly true of most of the update algorithms described in that paper. E.g., equation 11:
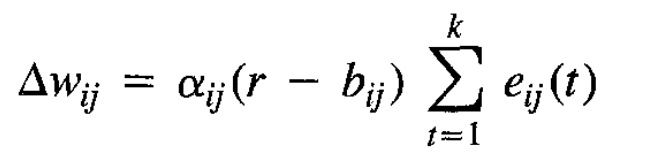
Here, the reward (adjusted by a "reinforcement baseline" ) literally just multiplies the learning rate. Beyond PPO and REINFORCE, this "x as learning rate multiplier" pattern is actually extremely common in different RL formulations. From lecture 7 of David Silver's RL course:

To be honest, it was a major blackpill for me to see the rationalist community, whose whole whole founding premise was that they were supposed to be good at making efficient use of the available evidence, so completely missing this very straightforward interpretation of RL (at least, I'd never heard of it from alignment literature until I myself came up with it when I realized that the mechanistic function of per-trajectory rewards in a given batched update was to provide the weights of a linear combination of the trajectory gradients. Update: Gwern's description here is actually somewhat similar).
implicitly assuming that all future AI architectures will be something like GPT+DPO is counterproductive.
When I bring up the "actual RL algorithms don't seem very dangerous or agenty to me" point, people often respond with "Future algorithms will be different and more dangerous".
I think this is a bad response for many reasons. In general, it serves as an unlimited excuse to never update on currently available evidence. It also has a bad track record in ML, as the core algorithmic structure of RL algorithms capable of delivering SOTA results has not changed that much in over 3 decades. In fact, just recently Cohere published Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs, which found that the classic REINFORCE algorithm actually outperforms PPO for LLM RLHF finetuning. Finally, this counterpoint seems irrelevant for Alex's point in this post, which is about historical alignment arguments about historical RL algorithms. He even included disclaimers at the top about this not being an argument for optimism about future AI systems.
I don't think this is a strawman. E.g., in How likely is deceptive alignment?, Evan Hubinger says:
We're going to start with simplicity. Simplicity is about specifying the thing that you want in the space of all possible things. You can think about simplicity as “How much do you have to aim to hit the exact thing in the space of all possible models?” How many bits does it take to find the thing that you want in the model space? And so, as a first pass, we can understand simplicity by doing a counting argument, which is just asking, how many models are in each model class?
First, how many Christs are there? Well, I think there's essentially only one, since there's only one way for humans to be structured in exactly the same way as God. God has a particular internal structure that determines exactly the things that God wants and the way that God works, and there's really only one way to port that structure over and make the unique human that wants exactly the same stuff.Okay, how many Martin Luthers are there? Well, there's actually more than one Martin Luther (contrary to actual history) because the Martin Luthers can point to the Bible in different ways. There's a lot of different equivalent Bibles and a lot of different equivalent ways of understanding the Bible. You might have two copies of the Bible that say exactly the same thing such that it doesn't matter which one you point to, for example. And so there's more Luthers than there are Christs.
But there's even more Pascals. You can be a Pascal and it doesn't matter what you care about. You can care about anything in the world, all of the various different possible things that might exist for you to care about, because all that Pascal needs to do is care about something over the long term, and then have some reason to believe they're going to be punished if they don't do the right thing. And so there’s just a huge number of Pascals because they can care about anything in the world at all.
So the point is that there's more Pascals than there are the others, and so probably you’ll have to fix fewer bits to specify them in the space.
Evan then goes on to try to use the complexity of the simplest member of each model class as an estimate for the size of the classes (which is probably wrong, IMO, but I'm also not entirely sure how he's defining the "complexity" of a given member in this context), but this section seems more like an elaboration on the above counting argument. Evan calls it "a slightly more concrete version of essentially the same counting argument".
And IMO, it's pretty clear that the above quoted argument is implicitly appealing to some sort of uniformish prior assumption over ways to specify different types of goal classes. Otherwise, why would it matter that there are "more Pascals", unless Evan thought the priors over the different members of each category were sufficiently similar that he could assess their relative likelihoods by enumerating the number of "ways" he thought each type of goal specification could be structured?
Look, Evan literally called his thing a "counting argument", Joe said "Something in this vicinity [of the hazy counting argument] accounts for a substantial portion of [his] credence on schemers [...] and often undergirds other, more specific arguments", and EY often expounds on the "width" of mind design space. I think counting arguments represent substantial intuition pumps for a lot of people (though often implicitly so), so I think a post pushing back on them in general is good.
I think it actually points to convergence between human and NN learning dynamics. Human visual cortices are also bad at hands and text, to the point that lucid dreamers often look for issues with their hands / nearby text to check whether they're dreaming.
One issue that I think causes people to underestimate the degree of convergence between brain and NN learning is to compare the behaviors of entire brains to the behaviors of individual NNs. Brains consist of many different regions which are "trained" on different internal objectives, then interact with each other to collectively produce human outputs. In contrast, most current NNs contain only one "region", which is all trained on the single objective of imitating certain subsets of human behaviors.
We should thus expect NN learning dynamics to most resemble those of single brain regions, and that the best match for humanlike generalization patterns will arise from putting together multiple NNs that interact with each other in a similar manner as human brain regions.