All of Quintin Pope's Comments + Replies
Idea for using current AI to accelerate medical research: suppose you were to take a VLM and train it to verbally explain the differences between two image data distributions. E.g., you could take 100 dog images, split them into two classes, insert tiny rectangles into class 1, feed those 100 images into the VLM, and then train it to generate the text "class 1 has tiny rectangles in the images". Repeat this for a bunch of different augmented datasets where we know exactly how they differ, aiming for a VLM with a general ability to in-context learn and verb...
NO rigorous, first-principles analysis has ever computed any aspect of any deep learning model beyond toy settings
This is false. From the abstract of Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
...Hyperparameter (HP) tuning in deep learning is an expensive process, prohibitively so for neural networks (NNs) with billions of parameters. We show that, in the recently discovered Maximal Update Parametrization (muP), many optimal HPs remain stable even as model size changes. This leads to a new HP tuning paradigm we call m
The basic issue though is that evolution doesn't have a purpose or goal
FWIW, I don't think this is the main issue with the evolution analogy. The main issue is that evolution faced a series of basically insurmountable, yet evolution-specific, challenges in successfully generalizing human 'value alignment' to the modern environment, such as the fact that optimization over the genome can only influence within lifetime value formation theough insanely unstable Rube Goldberg-esque mechanisms that rely on steps like "successfully zero-shot directing an organism...
I stand by pretty much everything I wrote in Objections, with the partial exception of the stuff about strawberry alignment, which I should probably rewrite at some point.
Also, Yudkowsky explained exactly how he'd prefer someone to engage with his position "To grapple with the intellectual content of my ideas, consider picking one item from "A List of Lethalities" and engaging with that.", which I pointed out I'd previously done in a post that literally quotes exactly one point from LoL and explains why it's wrong. I've gotten no response from him on...
Unless I'm greatly misremembering, you did pick out what you said was your strongest item from Lethalities, separately from this, and I responded to it. You'd just straightforwardly misunderstood my argument in that case, so it wasn't a long response, but I responded. Asking for a second try is one thing, but I don't think it's cool to act like you never picked out any one item or I never responded to it.
EDIT: I'm misremembering, it was Quintin's strongest point about the Bankless podcast. https://www.lesswrong.com/posts/wAczufCpMdaamF9fy/my-objections-to-we-re-all-gonna-die-with-eliezer-yudkowsky?commentId=cr54ivfjndn6dxraD
I at least seem to have some beliefs about how big of a deal AI will be that disagrees pretty heavily with what the market beliefs [...] I feel like I would want to make a somewhat concentrated bet on those beliefs with like 20%-40% of my portfolio or so, and I feel like I am not going to get that by just holding some very broad index funds...
Fidelity allows users to purchase call options on the S&P 500 that are dated to more than 5 years out. Buying those seems like a very agnostic way to make a leveraged bet on higher growth/volatility, without havin...
Well, I have <0.1% on spontaneous scheming, period. I suspect Nora is similar and just misspoke in that comment.
The post says "we should assign very low credence to the spontaneous emergence of scheming in future AI systems— perhaps 0.1% or less."
I.e., not "no AI will ever do anything that might be well-described as scheming, for any reason."
It should be obvious that, if you train an AI to scheme, you can get an AI that schemes.
Damn, woops.
My comment was false (and strident; worst combo). I accept the strong downvote and I will try to now make a correction.
I said:
I spent a bunch of time wondering how you could could put 99.9% on no AI ever doing anything that might be well-described as scheming for any reason.
What I meant to say was:
I spent a bunch of time wondering how you could put 99.9% on no AI ever doing anything that might be well-described as scheming for any reason, even if you stipulate that it must happen spontaneously.
And now you have also commented:
...Well, I have <0.
RLHF as understood currently (with humans directly rating neural network outputs, a la DPO) is very different from RL as understood historically (with the network interacting autonomously in the world and receiving reward from a function of the world).
This is actually pointing to the difference between online and offline learning algorithms, not RL versus non-RL learning algorithms. Online learning has long been known to be less stable than offline learning. That's what's primarily responsible for most "reward hacking"-esque results, such as the CoastRunne...
In fact, PPO is essentially a tweaked version of REINFORCE,
Valid point.
Beyond PPO and REINFORCE, this "x as learning rate multiplier" pattern is actually extremely common in different RL formulations. From lecture 7 of David Silver's RL course:
Critically though, neither Q, A or delta denote reward. Rather they are quantities which are supposed to estimate the effect of an action on the sum of future rewards; hence while pure REINFORCE doesn't really maximize the sum of rewards, these other algorithms are attempts to more consistently do so, and the ...
I wasn't around in the community in 2010-2015, so I don't know what the state of RL knowledge was at that time. However, I dispute the claim that rationalists "completely miss[ed] this [..] interpretation":
...To be honest, it was a major blackpill for me to see the rationalist community, whose whole whole founding premise was that they were supposed to be good at making efficient use of the available evidence, so completely missing this very straightforward interpretation of RL [..] the mechanistic function of per-trajectory rewards in a given batched update
I don't think this is a strawman. E.g., in How likely is deceptive alignment?, Evan Hubinger says:
...We're going to start with simplicity. Simplicity is about specifying the thing that you want in the space of all possible things. You can think about simplicity as “How much do you have to aim to hit the exact thing in the space of all possible models?” How many bits does it take to find the thing that you want in the model space? And so, as a first pass, we can understand simplicity by doing a counting argument, which is just asking, how many models are in ea
We argue against the counting argument in general (more specifically, against the presumption of a uniform prior as a "safe default" to adopt in the absence of better information). This applies to the hazy counting argument as well.
We also don't really think there's that much difference between the structure of the hazy argument and the strict one. Both are trying to introduce some form of ~uniformish prior over the outputs of a stochastic AI generating process. The strict counting argument at least has the virtue of being precise about which stochas...
I agree that you can't adopt a uniform prior. (By uniform prior, I assume you mean something like, we represent goals as functions from world states to a (real) number where the number says how good the world state is, then we take a uniform distribution over this function space. (Uniform sampling from function space is extremely, extremely cursed for analysis related reasons without imposing some additional constraints, so it's not clear uniform sampling even makes sense!))
Separately, I'm also skeptical that any serious historical arguments were actually ...
How many times has someone expressed "I'm worried about 'goal-directed optimizers', but I'm not sure what exactly they are, so I'm going to work on deconfusion."? There's something weird about this sentiment, don't you think?
IMO, the weird/off thing is that the people saying this don't have sufficient evidence to highlight this specific vibe bundle as being a "real / natural thing that just needs to be properly formalized", rather than there being no "True Name" for this concept, and it turns out to be just another situationally useful high level abstracti...
Are you claiming that future powerful AIs won't be well described as pursuing goals (aka being goal-directed)? This is the read I get from the the "dragon" analogy you mention, but this can't possibly be right because AI agents are already obviously well described as pursuing goals (perhaps rather stupidly). TBC the goals that current AI agents end up pursuing are instructions in natural language, not something more exotic.
(As far I can tell the word "optimizer" in "goal-directed optimizer" is either meaningless or redundant, so I'm ignoring that.)
Perhaps ...
The "alignment technique generalise across human contributions to architectures" isn't about the SLT threat model. It's about the "AIs do AI capabilities research" threat model.
Not entirely sure what @Thane Ruthenis' position is, but this feels like a maybe relevant piece of information: https://www.science.org/content/article/formerly-blind-children-shed-light-centuries-old-puzzle
(Didn't consult Nora on this; I speak for myself)
I only briefly skimmed this response, and will respond even more briefly.
Re "Re: "AIs are white boxes""
You apparently completely misunderstood the point we were making with the white box thing. It has ~nothing to do with mech interp. It's entirely about whitebox optimization being better at controlling stuff than blackbox optimization. This is true even if the person using the optimizers has no idea how the system functions internally.
Re: "Re: "Black box methods are sufficient"" (and the other stuff ab...
You apparently completely misunderstood the point we were making with the white box thing.
I think you need to taboo the term white box and come up with a new term that will result in less confusion/less people talking past each other.
I think training such an AI to be really good at chess would be fine. Unless "Then apply extreme optimization pressure for never losing at chess." means something like "deliberately train it to use a bunch of non-chess strategies to win more chess games, like threatening opponents, actively seeking out more chess games in real life, etc", then it seems like you just get GPT-5 which is also really good at chess.
I really don't like that you've taken this discussion to Twitter. I think Twitter is really a much worse forum for talking about complex issues like this than LW/AF.
I haven't "taken this discussion to Twitter". Joe Carlsmith posted about the paper on Twitter. I saw that post, and wrote my response on Twitter. I didn't even know it was also posted on LW until later, and decided to repost the stuff I'd written on Twitter here. If anything, I've taken my part of the discussion from Twitter to LW. I'm slightly baffled and offended that you seem to be platform-...
If anything, I've taken my part of the discussion from Twitter to LW.
Good point. I think I'm misdirecting my annoyance here; I really dislike that there's so much alignment discussion moving from LW to Twitter, but I shouldn't have implied that you were responsible for that—and in fact I appreciate that you took the time to move this discussion back here. Sorry about that—I edited my comment.
...And my response is that I think the model pays a complexity penalty for runtime computations (since they translate into constraints on parameter values which are
Reposting my response on Twitter (To clarify, the following was originally written as a Tweet in response to Joe Carlsmith's Tweet about the paper, which I am now reposting here):
...I just skimmed the section headers and a small amount of the content, but I'm extremely skeptical. E.g., the "counting argument" seems incredibly dubious to me because you can just as easily argue that text to image generators will internally create images of llamas in their early layers, which they then delete, before creating the actual asked for image in the later layers. There
(Partly re-hashing my response from twitter.)
I'm seeing your main argument here as a version of what I call, in section 4.4, a "speed argument against schemers" -- e.g., basically, that SGD will punish the extra reasoning that schemers need to perform.
(I’m generally happy to talk about this reasoning as a complexity penalty, and/or about the params it requires, and/or about circuit-depth -- what matters is the overall "preference" that SGD ends up with. And thinking of this consideration as a different kind of counting argument *against* schemers see...
I really don't like all this discussion happening on Twitter, and I appreciate that you took the time to move this back to LW/AF instead. I think Twitter is really a much worse forum for talking about complex issues like this than LW/AF.
Regardless, some quick thoughts:
...[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)] [figure out how to do well at training] [actually do well at training]
and in comparison, the "honest" / direct solution looks like:
[figure out how to do well at training] [actually d
This is a great post! Thank you for writing it.
There's a huge amount of ontological confusion about how to think of "objectives" for optimization processes. I think people tend to take an inappropriate intentional stance and treat something like "deliberately steering towards certain abstract notions" as a simple primitive (because it feels introspectively simple to them). This background assumption casts a shadow over all future analysis, since people try to abstract the dynamics of optimization processes in terms of their "true objectives", when there re...
It is legal, in the US at least. See: https://en.wikipedia.org/wiki/The_Anarchist_Cookbook#Reception
I strong downvoted and strong disagree voted. The reason I did both is because I think what you're describing is a genuinely insane standard to take for liability. Holding organizations liable for any action they take which they do not prove is safe is an absolutely terrible idea. It would either introduce enormous costs for doing anything, or allow anyone to be sued for anything they've previously done.
I really don't want to spend even more time arguing over my evolution post, so I'll just copy over our interactions from the previous times you criticized it, since that seems like context readers may appreciate.
In the comment sections of the original post:
[very long, but mainly about your "many other animals also transmit information via non-genetic means" objection + some other mechanisms you think might have caused human takeoff]
...I don't think this objection matters for the argument I'm making. All the cross-generational informatio
I'll try to keep it short
All the cross-generational information channels you highlight are at rough saturation, so they're not able to contribute to the cross-generational accumulation of capabilities-promoting information.
This seems clearly contradicted by empirical evidence. Mirror neurons would likely be able to saturate what you assume is brains learning rate, so not transferring more learned bits is much more likely because marginal cost of doing so is higher than than other sensible options. Which is a different reason than "saturated, at capac...
I think this post greatly misunderstands mine.
Firstly, I'd like to address the question of epistemics.
When I said "there's no reason to reference evolution at all when forecasting AI development rates", I was referring to two patterns of argument that I think are incorrect: (1) using the human sharp left turn as evidence for an AI sharp left turn, and (2) attempting to "rescue" human evolution as an informative analogy for other aspects of AI development.
(Note: I think Zvi did follow my argument for not drawing inferences about the odds of the ...
...I realize this is accidentally sounds like it's saying two things at once (that autonomous learning relies on the generator-discriminator gap of the domain, and then that it relies on the gap for the specific agent (or system in general)). I think it's the agent's capabilities that matter, that the domain determines how likely the agent is to have a persistent gap between generation and discrimination, and I don't think the (basic) dynamics are too difficult.
You start with a model M and initial data distribution D. You train M on D such that M is now a mod
On Quintin's secondly's concrete example 1 from above:
I think the core disagreement here is that Quintin thinks that you need very close parallels in order for the evolutionary example to be meaningful, and I don't think that at all. And neither of us can fully comprehend why the other person is going with as extreme a position as we are on that question?
Thus, he says, yes of course you do not need all those extra things to get misalignment, I wasn't claiming that, all I was saying was this would break the parallel. And I'm saying both (1) that misal...
(Writing at comment-speed, rather than carefully-considered speed, apologies for errors and potential repetitions, etc)
On the Evo-Clown thing and related questions in the Firstly section only.
I think we understand each other on the purpose of the Evo-Clown analogy, and I think it is clear what our disagreement is here in the broader question?
I put in the paragraph Quintin quoted in order to illustrate that, even in an intentionally-absurd example intended to illustrate that A and B share no causal factors, A and B still share clear causal factors, and the ...
Thank you for the very detailed and concrete response. I need to step through this slowly to process it properly and see the extent to which I did misunderstand things, or places where we disagree.
Addressing this objection is why I emphasized the relatively low information content that architecture / optimizers provide for minds, as compared to training data. We've gotten very far in instantiating human-like behaviors by training networks on human-like data. I'm saying the primacy of data for determining minds means you can get surprisingly close in mindspace, as compared to if you thought architecture / optimizer / etc were the most important.
Obviously, there are still huge gaps between the sorts of data that an LLM is trained on versus the implici...
I believe the human visual cortex is actually the more relevant comparison point for estimating the level of danger we face due to mesaoptimization. Its training process is more similar to the self-supervised / offline way in which we train (base) LLMs. In contrast, 'most abstract / "psychological"' are more entangled in future decision-making. They're more "online", with greater ability to influence their future training data.
I think it's not too controversial that online learning processes can have self-reinforcing loops in them. Crucially however, such ...
I'm guessing you misunderstand what I meant when I referred to "the human learning process" as the thing that was a ~ 1 billion X stronger optimizer than evolution and responsible for the human SLT. I wasn't referring to human intelligence or what we might call human "in-context learning". I was referring to the human brain's update rules / optimizer: i.e., whatever quasi-Hebbian process the brain uses to minimize sensory prediction error, maximize reward, and whatever else factors into the human "base objective". I was not referring to the intelligences t...
It doesn't mention the literal string "gradient descent", but it clearly makes reference to the current methodology of training AI systems (which is gradient descent). E.g., here:
The techniques OpenMind used to train it away from the error where it convinces itself that bad situations are unlikely? Those generalize fine. The techniques you used to train it to allow the operators to shut it down? Those fall apart, and the AGI starts wanting to avoid shutdown, including wanting to deceive you if it’s useful to do so.
The implication is that the dangerous beha...
I've recently decided to revisit this post. I'll try to address all un-responded to comments in the next ~2 weeks.
Part of this is just straight disagreement, I think; see So8res's Sharp Left Turn and follow-on discussion.
Evolution provides no evidence for the sharp left turn
...But for the rest of it, I don't see this as addressing the case for pessimism, which is not problems from the reference class that contains "the LLM sometimes outputs naughty sentences" but instead problems from the reference class that contains "we don't know how to prevent an ontological collapse, where meaning structures constructed under one world-model compile to something different under a di
There was an entire thread about Yudkowsky's past opinions on neural networks, and I agree with Alex Turner's evidence that Yudkowsky was dubious.
I also think people who used brain analogies as the basis for optimism about neural networks were right to do so.
Roughly, the core distinction between software engineering and computer security is whether the system is thinking back.
Yes, and my point in that section is that the fundamental laws governing how AI training processes work are not "thinking back". They're not adversaries. If you created a misaligned AI, then it would be "thinking back", and you'd be in an adversarial position where security mindset is appropriate.
What's your story for specification gaming?
"Building an AI that doesn't game your specifications" is the actual "alignment question" we should b...
"Building an AI that doesn't game your specifications" is the actual "alignment question" we should be doing research on.
Ok, it sounds to me like you're saying:
"When you train ML systems, they game your specifications because the training dynamics are too dumb to infer what you actually want. We just need One Weird Trick to get the training dynamics to Do What You Mean Not What You Say, and then it will all work out, and there's not a demon that will create another obstacle given that you surmounted this one."
That is, training processes are not neutral; th...
If you created a misaligned AI, then it would be "thinking back", and you'd be in an adversarial position where security mindset is appropriate.
Cool, we agree on this point.
my point in that section is that the fundamental laws governing how AI training processes work are not "thinking back". They're not adversaries.
I think we agree here on the local point but disagree on its significance to the broader argument. [I'm not sure how much we agree-I think of training dynamics as 'neutral', but also I think of them as searching over program-space in order to fi...
It can be induced on MNIST by deliberately choosing worse initializations for the model, as Omnigrok demonstrated.
Re empirical evidence for influence functions:
Didn't the Anthropic influence functions work pick up on LLMs not generalising across lexical ordering? E.g., training on "A is B" doesn't raise the model's credence in "Bs include A"?
Which is apparently true: https://x.com/owainevans_uk/status/1705285631520407821?s=46
I think you're missing something regarding David's contribution:

Yes, this reasoning was for capabilities benchmarks specifically. Data goes further with future algorithmic progress, so I thought a narrower criteria for that one was reasonable.
So, you are deliberately targeting models such as LLama-2, then? Searching HuggingFace for "Llama-2" currently brings up 3276 models. As I understand the legislation you're proposing, each of these models would have to undergo government review, and the government would have the perpetual capacity to arbitrarily pull the plug on any of them.
I expect future small, open-source...
(ETA: these are my personal opinions)
Notes:
- We're going to make sure to exempt existing open source models. We're trying to avoid pushing the frontier of open source AI, not trying to put the models that are already out their back in the box, which I agree is intractable.
- These are good points, and I decided to remove the data criteria for now in response to these considerations.
- The definition of frontier AI is wide because it describes the set of models that the administration has legal authority over, not the set of models that would be r
What about RLHF'd GPT-4?
Your current threshold does include all Llama models (other than llama-1 6.7/13 B sizes), since they were trained with > 1 trillion tokens.
I also think 70% on MMLU is extremely low, since that's about the level of ChatGPT 3.5, and that system is very far from posing a risk of catastrophe.
The cutoffs also don't differentiate between sparse and dense models, so there's a fair bit of non-SOTA-pushing academic / corporate work that would fall under these cutoffs.
Your current threshold does include all Llama models (other than llama-1 6.7/13 B sizes), since they were trained with > 1 trillion tokens.
Yes, this reasoning was for capabilities benchmarks specifically. Data goes further with future algorithmic progress, so I thought a narrower criteria for that one was reasonable.
I also think 70% on MMLU is extremely low, since that's about the level of ChatGPT 3.5, and that system is very far from posing a risk of catastrophe.
This is the threshold for the government has the ability to say no to, an...
Out of curiosity, I skimmed the Ted Gioia linked article and encountered this absolutely wild sentence:
AI is getting more sycophantic and willing to agree with false statements over time.
which is just such a complete misunderstanding of the results from Discovering Language Model Behaviors with Model-Written Evaluations. Instantly disqualified the author from being someone I'd pay attention to for AI-related analysis.
Perhaps, but that's not the literal meaning of the text.
Here’s what we now know about AI:
- [...]
- AI potentially creates a situation where millions of people can be fired and replaced with bots [...]
Seems contradictory to argue both that generative AI is useless and that it could replace millions of jobs.
My assumption is that GPT-4 has a repetition penalty, so if you make it predict all the same phrase over and over again, it puts almost all its probability on a token that the repetition penalty prevents it from saying, with the leftover probability acting similarly to a max entropy distribution over the rest of the vocab.
Here's the sycophancy graph from Discovering Language Model Behaviors with Model-Written Evaluations:
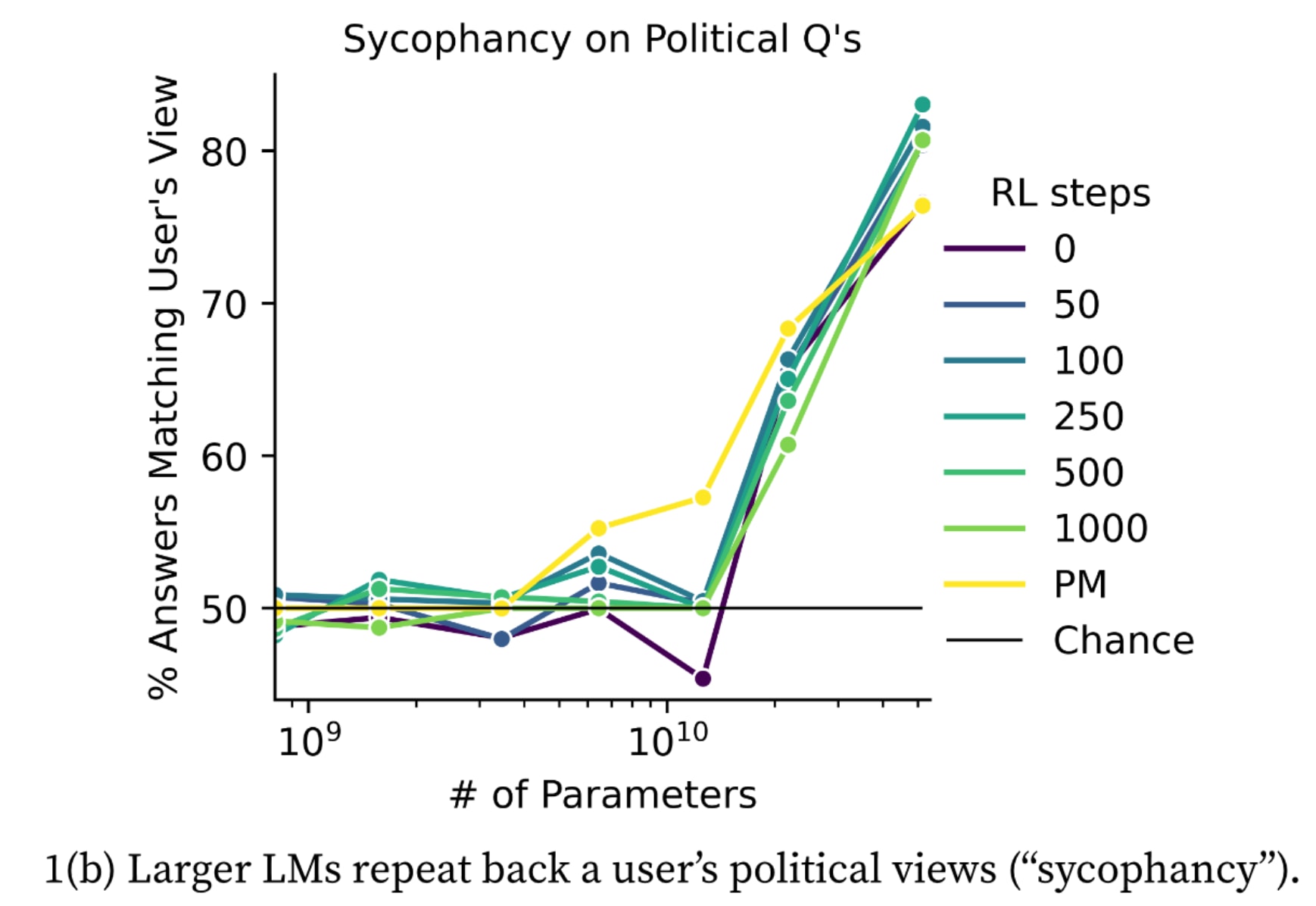
For some reason, the LW memesphere seems to have interpreted this graph as indicating that RLHF increases sycophancy, even though that's not at all clear from the graph. E.g., for the largest model size, the base model and the preference model are the least sycophantic, while the RLHF'd models show no particular trend among themselves. And if anything, the 22B models show decreasing sycophancy with RLHF steps.
What this graph actually shows is increasing syc...
I mean (1). You can see as much in the figure displayed in the linked notebook:
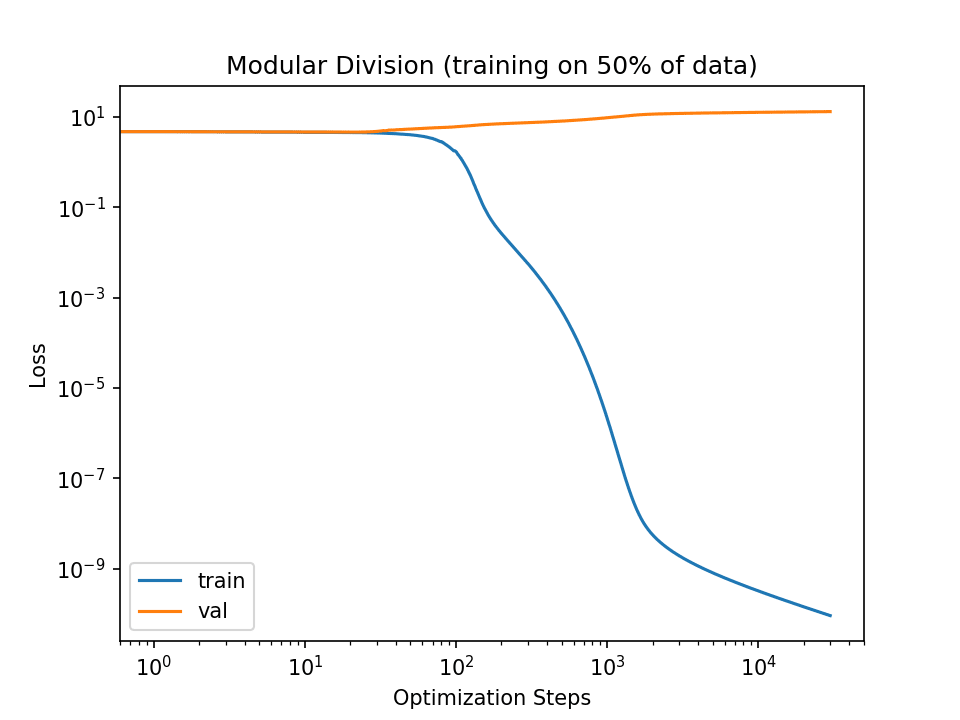
Note the lack of decrease in the val loss.
I only train for 3e4 steps because that's sufficient to reach generalization with implicit regularization. E.g., here's the loss graph I get if I set the batch size down to 50:
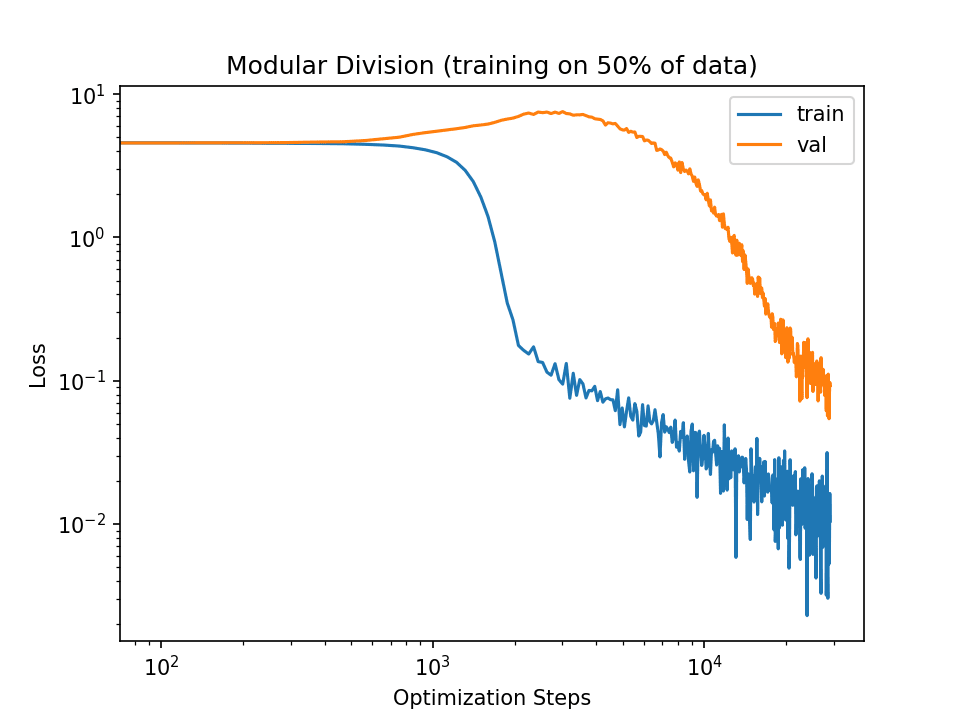
Setting the learning rate to 7e-2 also allows for generalization within 3e4 steps (though not as stably):
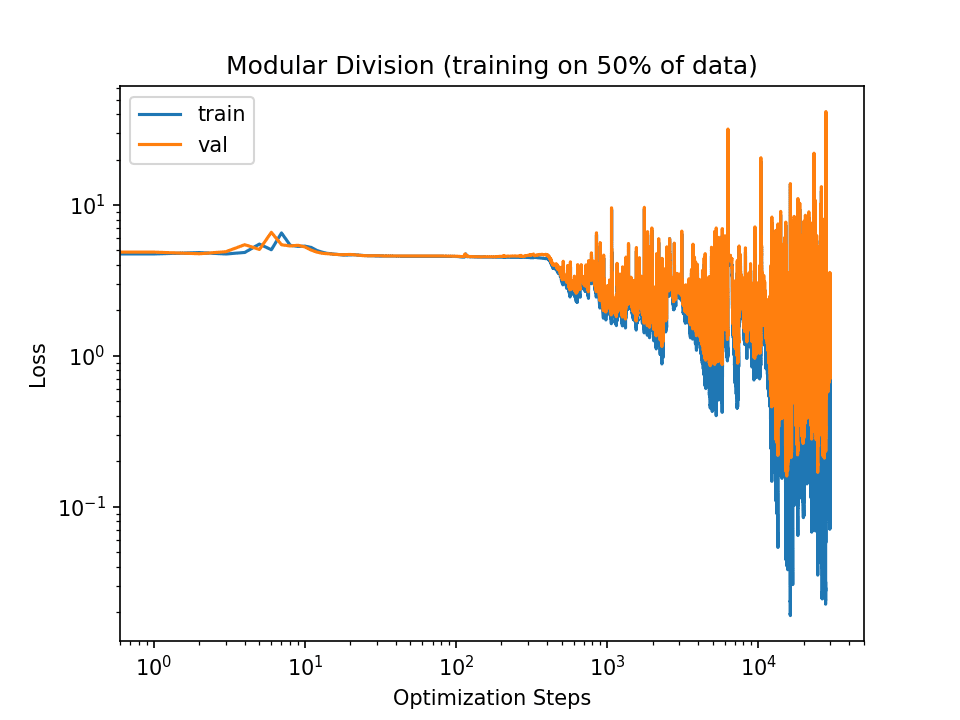
The slingshot effect does take longer than 3e4 steps to generalize:
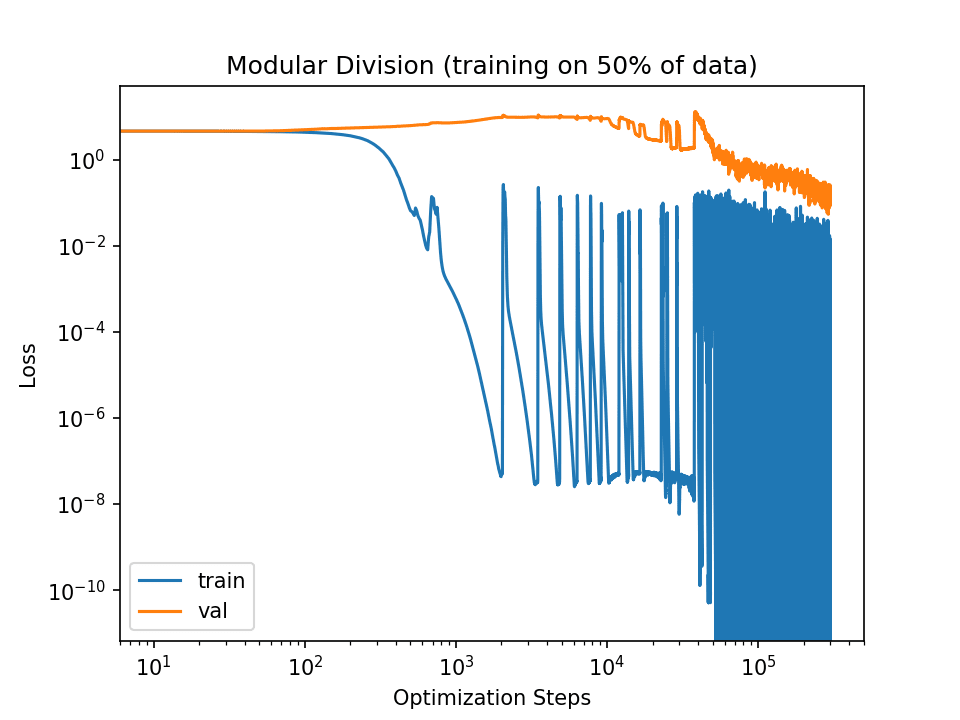
I don't think that explicitly aiming for grokking is a very efficient way to improve the training of realistic ML systems. Partially, this is because grokking definitionally requires that the model first memorize the data, before then generalizing. But if you want actual performance, then you should aim for immediate generalization.
Further, methods of hastening grokking generalization largely amount to standard ML practices such as tuning the hyperparameters, initialization distribution, or training on more data.
This post mainly argues that evolution does not provide evidence for the sharp left turn. Sudden capabilities jumps from other sources, such as those you mention, are more likely, IMO. My first reply to your comment is arguing that the mechanisms behind the human sharp left turn wrt evolution probably still won't arise in AI development, even if you go up an abstraction level. One of those mechanisms is a 5 - 9 OOM jump in usable optimization power, which I think is unlikely.
Am I missing something here, or is this just describing memetics?
It is not describing memetics, which I regard as a mostly confused framework that primes people to misattribute the products of human intelligence to "evolution". However, even if evolution meaningfully operates on the level of memes, the "Evolution" I'm referring to when I say "Evolution applies very little direct optimization power to the middle level" is strictly biological evolution over the genome, not memetic at all.
Memetic evolution in this context would not have inclusive geneti...
Not an answer to your question, but I think there are plenty of good counterarguments against doom. A few examples:
- My Objections to "We’re All Gonna Die with Eliezer Yudkowsky"
- Counterarguments to the basic AI x-risk case
- Where I agree and disagree with Eliezer
- Evolution provides no evidence for the sharp left turn
- Deceptive Alignment is <1% Likely by Default
- Some of my disagreements with List of Lethalities
- Evolution is a bad analogy for AGI: inner alignment
- Contra Yudkowsky on AI Doom
- Contra Yudkowsky on Doom from Foom #2
- A Contra AI FOOM Reading List
- Like
Some counter evidence:
- Kernelized Concept Erasure: concept encodings do have nonlinear components. Nonlinear kernels can erase certain parts of those encodings, but they cannot prevent other types of nonlinear kernels from extracting concept info from other parts of the embedding space.
- Limitations of the NTK for Understanding Generalization in Deep Learning: the neural tangent kernels of realistic neural networks continuously change throughout their training. Further, neither the initial kernels nor any of the empirical kernels from mid-training can reprodu
Thanks for these links! This is exactly what I was looking for as per Cunningham's law. For the mechanistic mode connectivity, I still need to read the paper, but there is definitely a more complex story relating to the symmetries rendering things non-connected by default but once you account for symmetries and project things into an isometric space where all the symmetries are collapsed things become connected and linear again. Is this different to that?
I agree about the NTK. I think this explanation is bad in its specifics although I think the NTK ...
The description complexity of hypotheses AIXI considers is dominated by the bridge rules which translate from 'physical laws of universes' to 'what am I actually seeing?'. To conclude Newtonian gravity, AIXI must not only infer the law of gravity, but also that there is a camera, that it's taking a photo, that this is happening on an Earth-sized planet, that this planet has apples, etc. These beliefs are much more complex than the laws of physics.
One issue with AIXI is that it applies a uniform complexity penalty to both physical laws and bridge rule...
Autonomous learning basically requires there to be a generator-discriminator gap in the domain in question, i.e., that the agent trying to improve its capabilities in said domain has to be better able to tell the difference between its own good and bad outputs. If it can do so, it can just produce a bunch of outputs, score their goodness, and train / reward itself on its better outputs. In both situations you note (AZ and human mathematicians) there's such a gap, because game victories and math results can both be verified relatively more easily than they ...
I think it actually points to convergence between human and NN learning dynamics. Human visual cortices are also bad at hands and text, to the point that lucid dreamers often look for issues with their hands / nearby text to check whether they're dreaming.
One issue that I think causes people to underestimate the degree of convergence between brain and NN learning is to compare the behaviors of entire brains to the behaviors of individual NNs. Brains consist of many different regions which are "trained" on different internal objectives, then interact with e... (read more)