AI safety undervalues founders
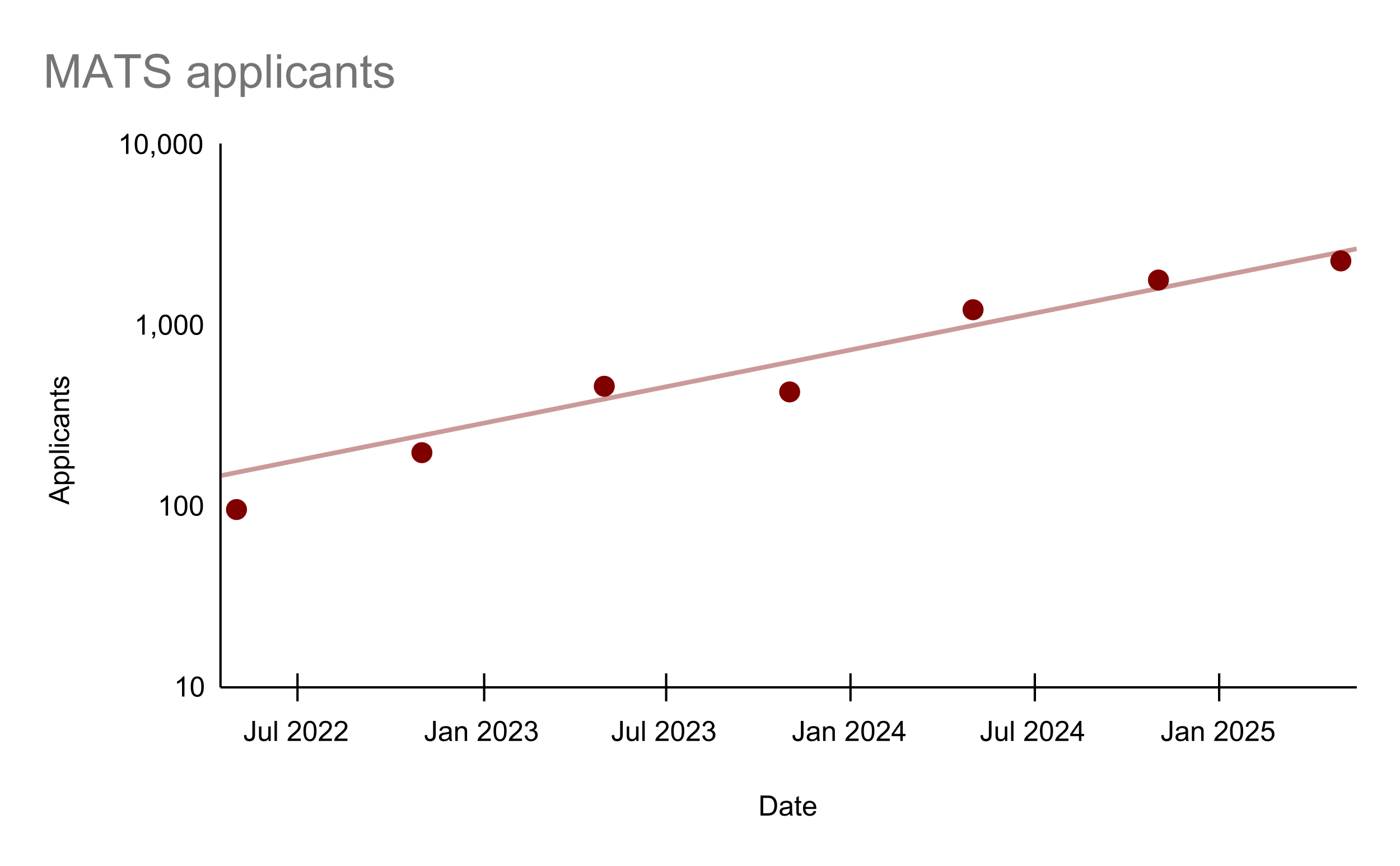
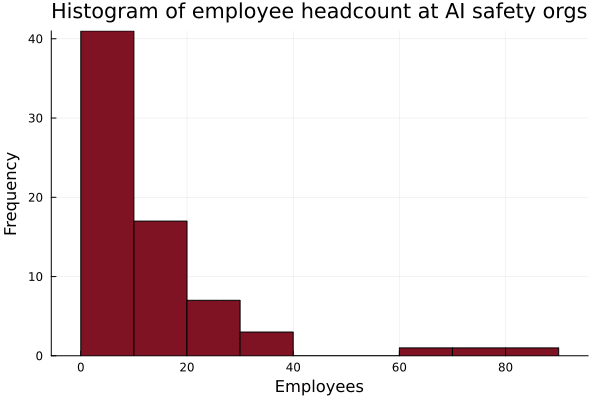
TL;DR: In AI safety, we systematically undervalue founders and field‑builders relative to researchers and prolific writers. This status gradient pushes talented would‑be founders and amplifiers out of the ecosystem, slows the growth of research orgs and talent funnels, and bottlenecks our capacity to scale the AI safety field. We should deliberately raise the status of founders and field-builders and lower the friction for starting and scaling new AI safety orgs. Epistemic status: A lot of hot takes with less substantiation than I'd like. Also, there is an obvious COI in that I am an AI safety org founder and field-builder. Coauthored with ChatGPT. Why boost AI safety founders? * Multiplier effects: Great founders and field-builders have multiplier effects on recruiting, training, and deploying talent to work on AI safety. At MATS, mentor applications are increasing 2.2x/year and fellow applications are increasing 1.8x/year, but deployed research talent is only increasing at 1.25x/year. If we want to 10-100x the AI safety field in the next 8 years, we need multiplicative capacity, not just marginal hires; training programs and founders are the primary constraints. * Anti-correlated attributes: “Founder‑mode” is somewhat anti‑natural to “AI concern.” The cognitive style most attuned to AI catastrophic risk (skeptical, risk‑averse, theory-focused) is not the same style that woos VCs, launches companies, and ships MVPs. If we want AI safety founders, we need to counterweight the selection against risk-tolerant cognitive styles to prevent talent drift and attract more founder-types to AI safety. * Adverse incentives: The dominant incentive gradients in AI safety point away from founder roles. Higher social status, higher compensation, and better office/advisor access often accrue to research roles, so the local optimum is “be a researcher,” not “found something.” Many successful AI safety founders work in research-heavy roles (e.g., Buck Shlegeris, Beth Barnes, A
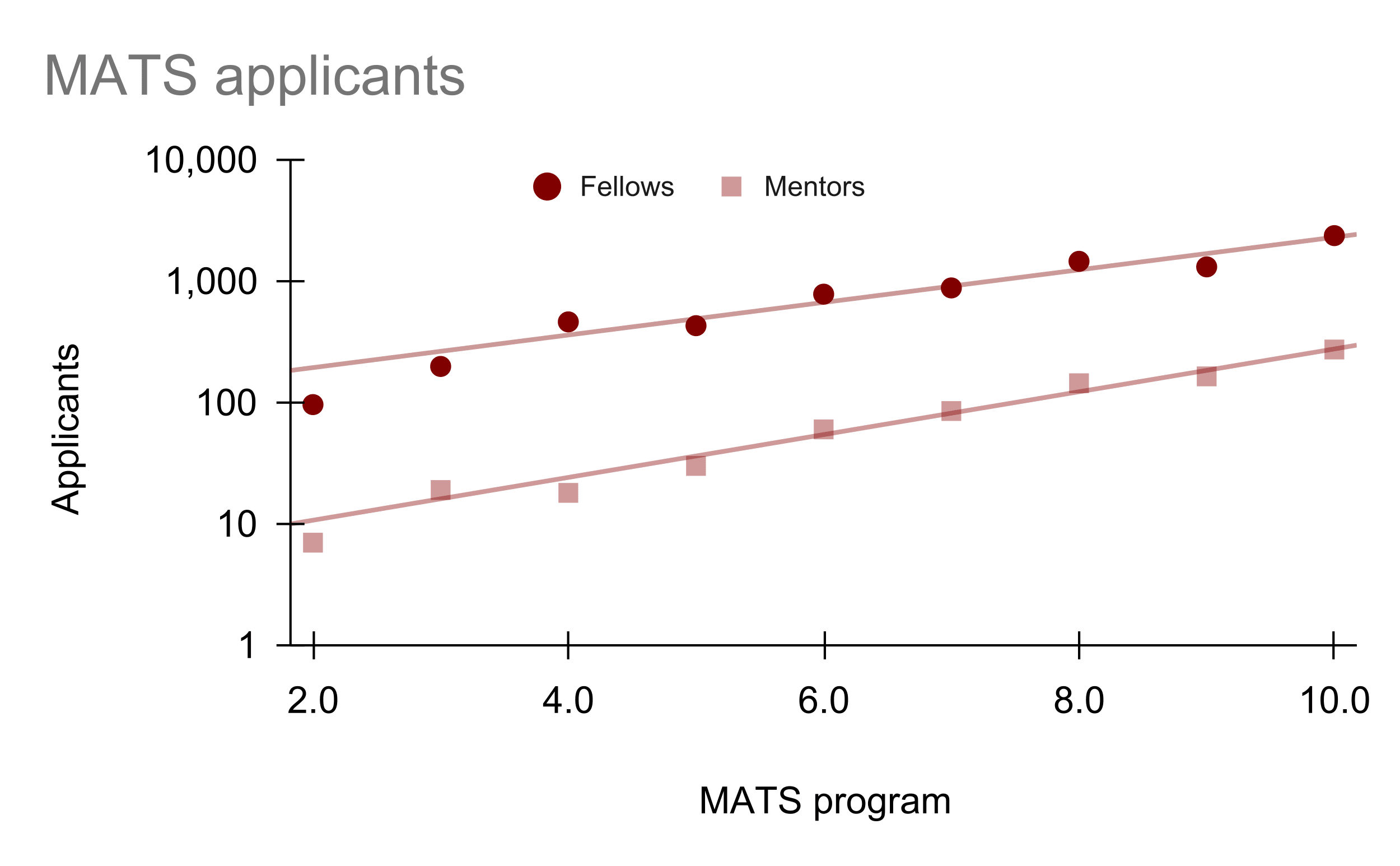

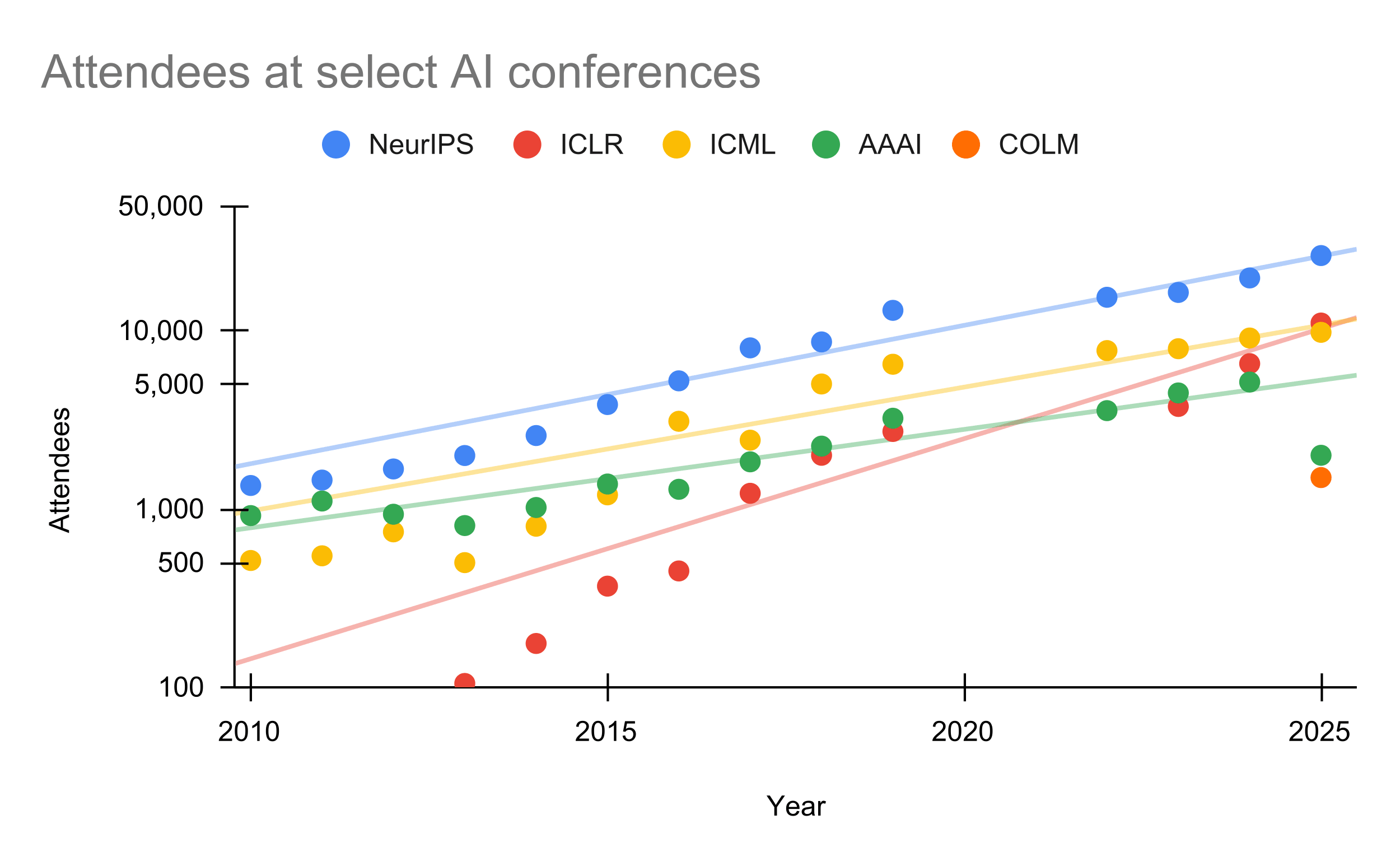
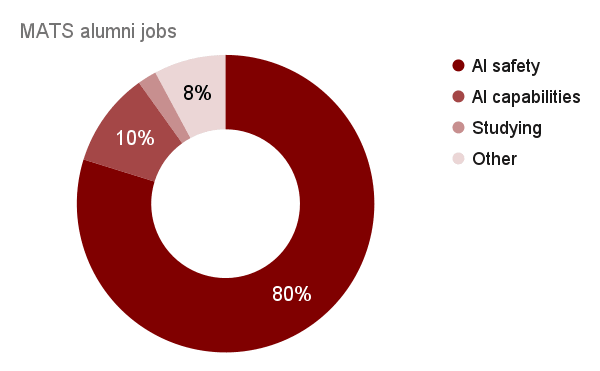
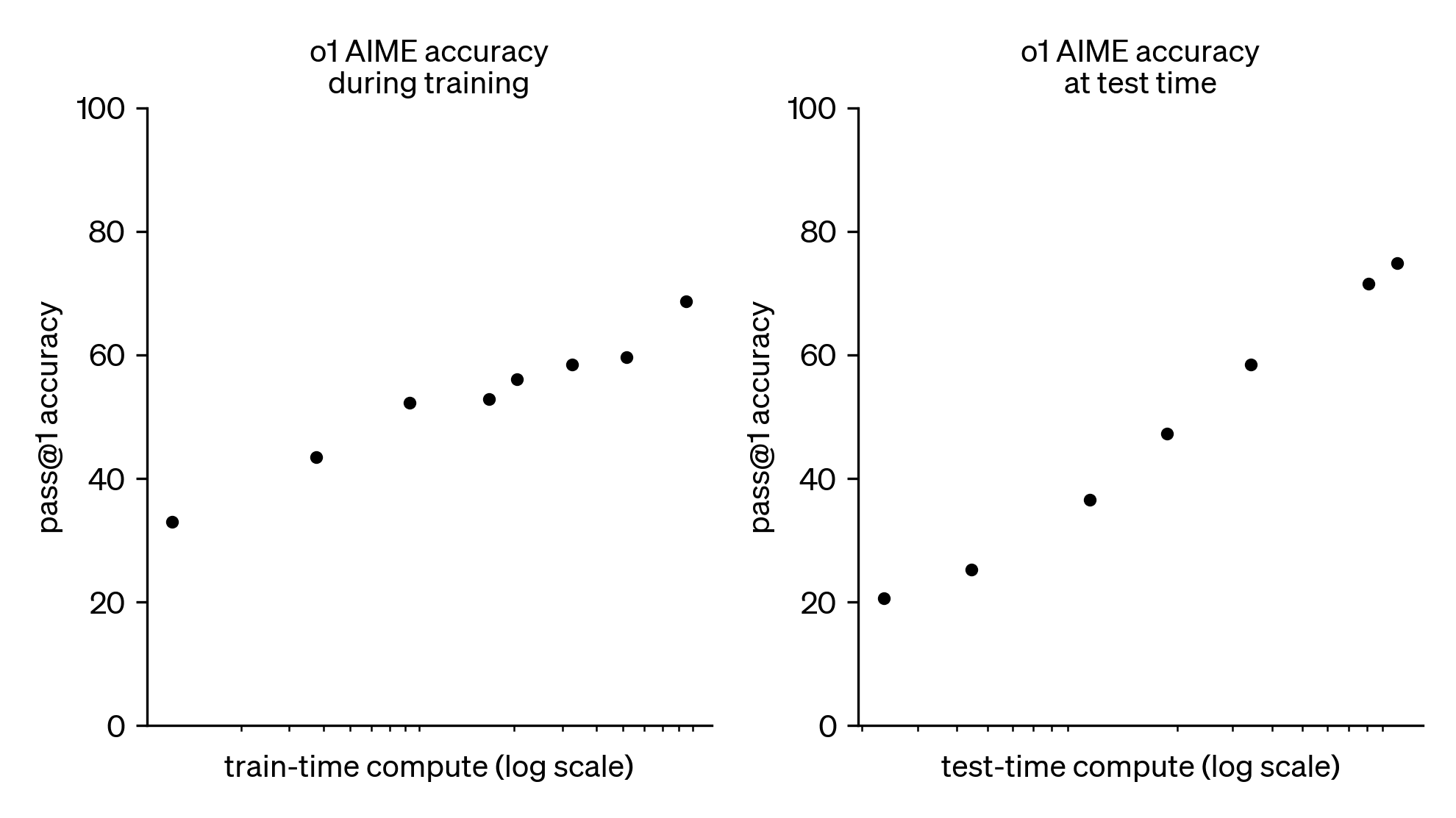
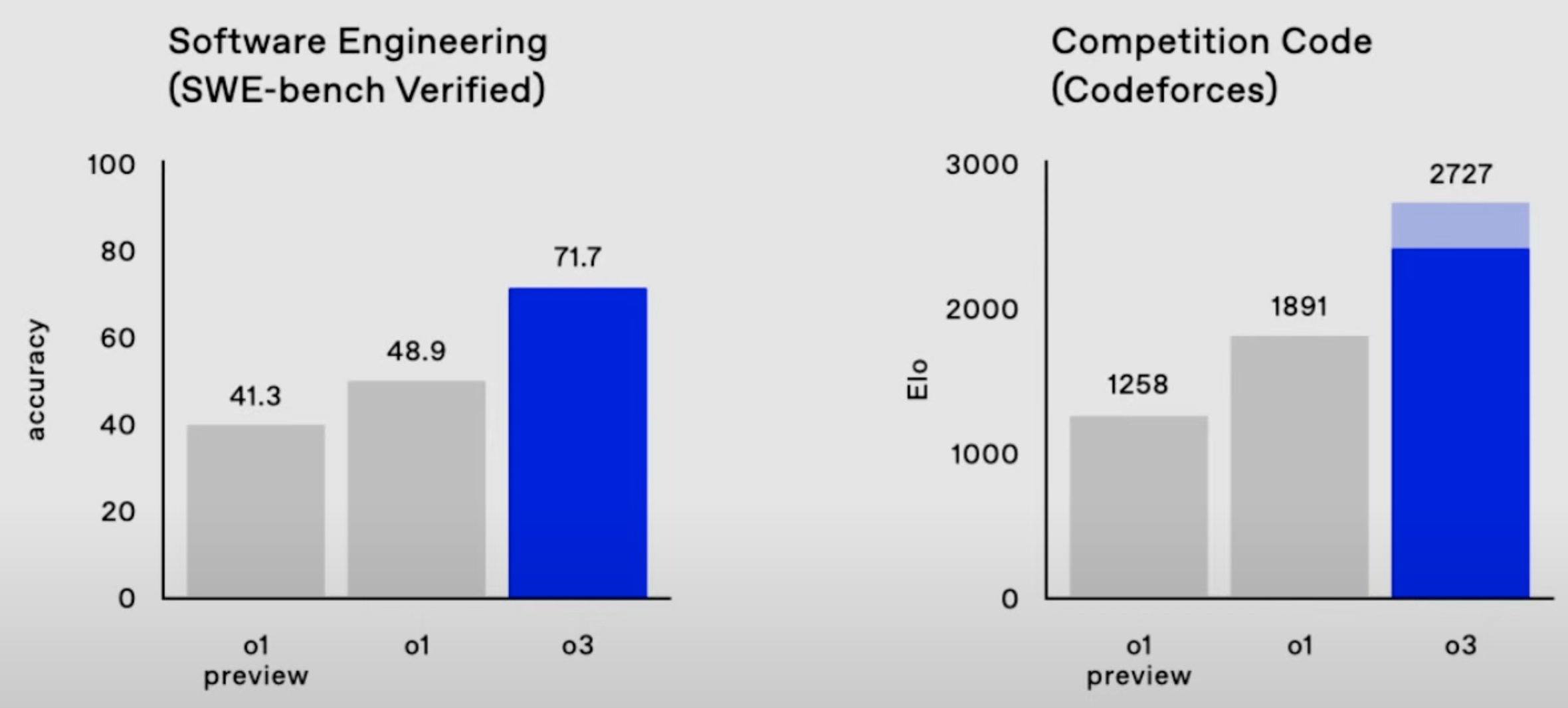
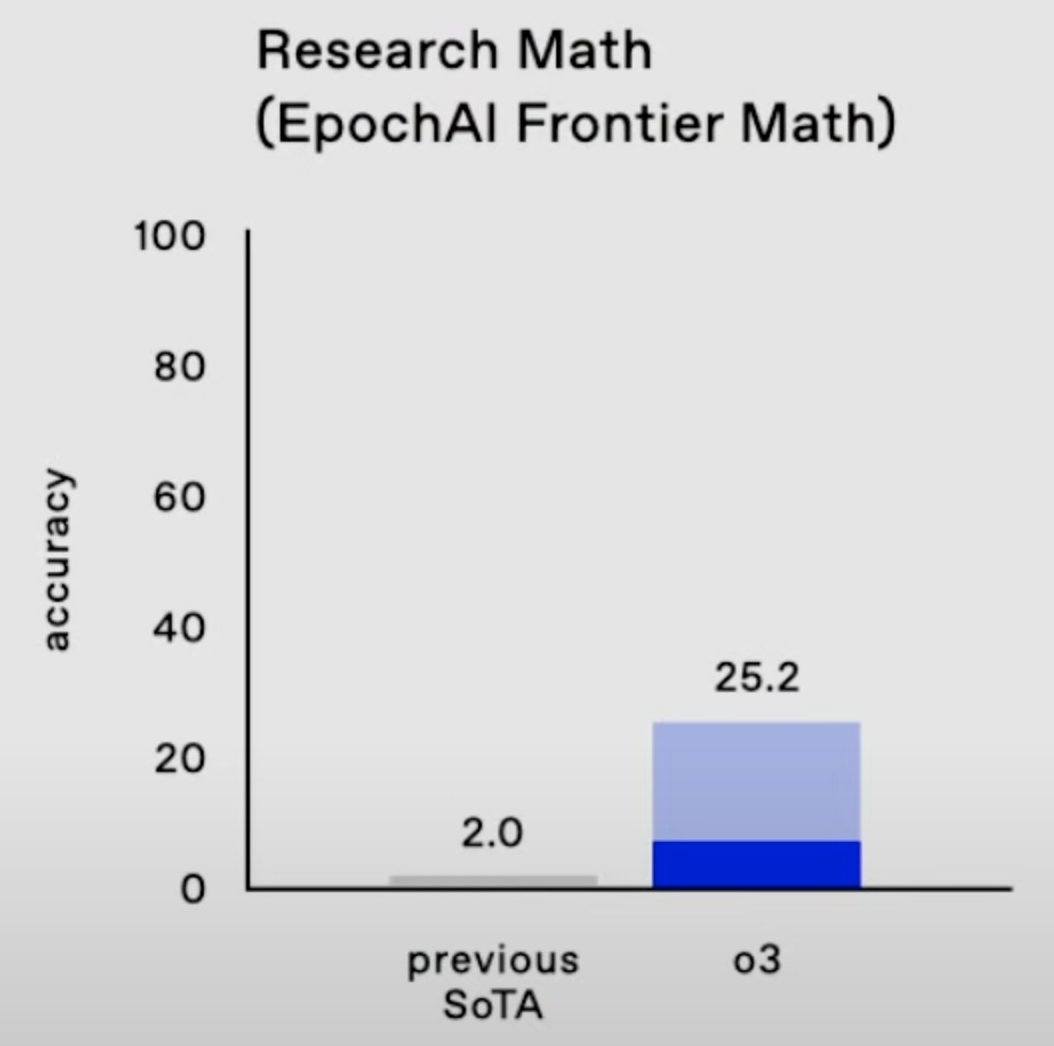
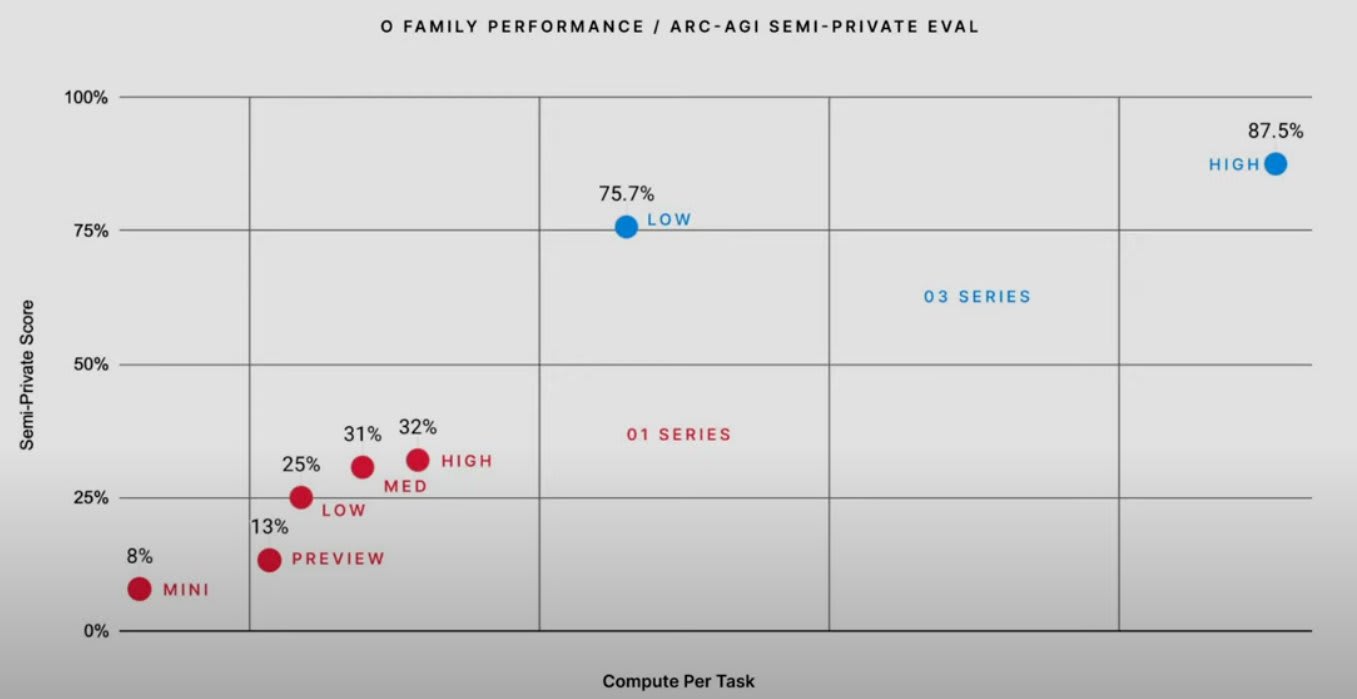
Yes, I would generally support picking the latter as they have a "faster time to mentorship/research leadership/impact" and the field seems currently bottlenecked on mentorship and research leads, not marginal engineers (though individual research leads might feel bottlenecked on marginal engineers).
We should prioritize people who already have research or engineering experience or a very high iteration speed as we are operating under time constraints; AGI is coming soon. Additionally, I think "research taste" will be more important than engineering ability given AI automation and this takes a long time to build; better to select people with existing research experience they can adapt from another field (also promotes interdisciplinary knowledge transfer).
I talk more about it here.