All of Ryan Kidd's Comments + Replies
Also there's a good chance AI gov won't work, and labs will just have a very limited safety budget to implement their best guess mitigations. Or maybe AI gov does work and we get a large budget, we still need to actually solve alignment.
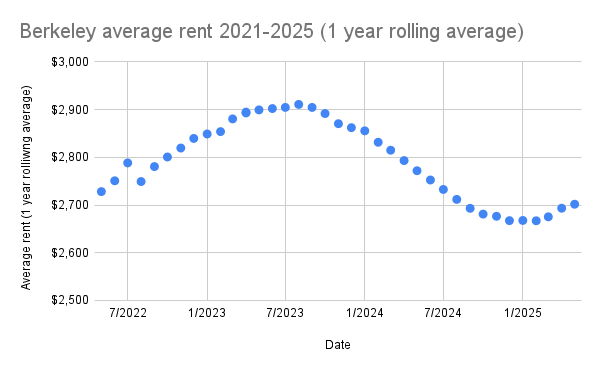
Not sure this is interesting to anyone, but I compiled Zillow's data on 2021-2025 Berkeley average rent prices recently, to help with rent negotiation. I did not adjust for inflation; these are the raw averages at each time.
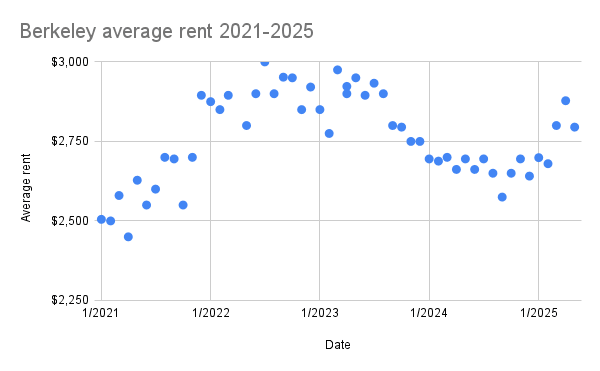
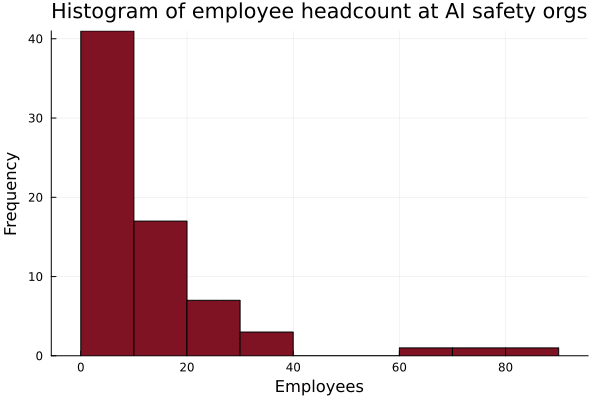
I definitely think that people should not look at my estimates and say "here is a good 95% confidence interval upper bound of the number of employees in the AI safety ecosystem." I think people should look at my estimates and say "here is a good 95% confidence interval lower bound of the number of employees in the AI safety ecosystem," because you can just add up the names. I.e., even if there might be 10x the number of employees as I estimated, I'm at least 95% confident that there are more than my estimate obtained by just counting names (obviously excluding the 10% fudge factor).
So, conduct a sensitivity analysis on the definite integral with respect to choices of integration bounds? I'm not sure this level of analysis is merited given the incomplete data and unreliable estimation methodology for the number of independent researchers. Like, I'm not even confident that the underlying distribution is a power law (instead of, say, a composite of power law and lognormal distributions, or a truncated power law), and the value of seems very sensitive to data in the vicinity, so I wouldn't want to rely on this estimate exc...
By "upper bound", I meant "upper bound on the definite integral ". I.e., for the kind of hacky thing I'm doing here, the integral is very sensitive to the choice of bounds . For example, the integral does not converge for . I think all my data here should be treated as incomplete and all my calculations crude estimates at best.
I edited the original comment to say " might be a bad upper bound" for clarity.
It's also worth noting that almost all of these roles are management, ML research, or software engineering; there are very few operations, communications, non-ML research, etc. roles listed, implying that these roles are paid significantly less.
Apparently the headcount for US corporations follows a power-law distribution, apart from mid-sized corporations, which fit a lognormal distribution better. I fit a power law distribution to the data (after truncating all datapoints with over 40 employees, which created a worse fit), which gave . This seems to imply that there are ~400 independent AI safety researchers (though note that is probability density function and this estimate might be way off); Claude estimates 400-600 for comparison. Integrating this distributio...
I decided to exclude OpenAI's nonprofit salaries as I didn't think they counted as an "AI safety nonprofit" and their highest paid current employees are definitely employed by the LLC. I decided to include Open Philanthropy's nonprofit employees, despite the fact that their most highly compensated employees are likely those under the Open Philanthropy LLC.
As part of MATS' compensation reevaluation project, I scraped the publicly declared employee compensations from ProPublica's Nonprofit Explorer for many AI safety and EA organizations (data here) in 2019-2023. US nonprofits are required to disclose compensation information for certain highly paid employees and contractors on their annual Form 990 tax return, which becomes publicly available. This includes compensation for officers, directors, trustees, key employees, and highest compensated employees earning over $100k annually. Therefore, my data does not...
Thanks! I wasn't sure whether to include Simplex, or the entire Obelisk team at Astera (which Simplex is now part of), or just exclude these non-scaling lab hybrid orgs from the count (Astera does neuroscience too).
I counted total employees for most orgs. In the spreadsheet I linked, I didn't include an estimate for total GDM headcount, just that of the AI Safety and Alignment Team.
Most of the staff at AE Studio are not working on alignment, so I don't think it counts.
I was very inclusive. I looked at a range of org lists, including those maintained by 80,000 Hours and AISafety.com.
Assuming that I missed 10% of orgs, this gives a rough estimate for the total number of FTEs working on AI safety or adjacent work at ~1000, not including students or faculty members. This is likely an underestimate, as there are a lot of AI safety-adjacent orgs in areas like AI security and robustness.
I did a quick inventory on the employee headcount at AI safety and safety-adjacent organizations. The median AI safety org has 10 8 employees. I didn't include UK AISI, US AISI, CAIS, and the safety teams at Anthropic, GDM, OpenAI, and probably more, as I couldn't get accurate headcount estimates. I also didn't include "research affiliates" or university students in the headcounts for academic labs. Data here. Let me know if I missed any orgs!
I expect mech interp to be particularly easy to automate at scale. If mech interp has capabilities externalities (e.g., uncovering useful learned algorithms or "retargeting the search"), this could facilitate rapid performance improvements.
It seems plausible to me that if AGI progress becomes strongly bottlenecked on architecture design or hyperparameter search, a more "genetic algorithm"-like approach will follow. Automated AI researchers could run and evaluate many small experiments in parallel, covering a vast hyperparameter space. If small experiments are generally predictive of larger experiments (and they seem to be, a la scaling laws) and model inference costs are cheap enough, this parallelized approach might be be 1) computationally affordable and 2) successful at overcoming the architecture bottleneck.
Apr 18, 11:59 pm PT :)
Hi! Yes, MATS is always open to newbies, though our bar has raised significantly over the last few years. AISF is great, but I would also recommend completing ARENA or ML4Good courses if you are pursuing a technical project, or completing an AI gov research project.
It seems plausible to me that if AGI progress becomes strongly bottlenecked on architecture design or hyperparameter search, a more "genetic algorithm"-like approach will follow. Automated AI researchers could run and evaluate many small experiments in parallel, covering a vast hyperparameter space.
LISA's current leadership team consists of an Operations Director (Mike Brozowski) and a Research Director (James Fox). LISA is hiring for a new CEO role; there has never been a LISA CEO.
How fast should the field of AI safety grow? An attempt at grounding this question in some predictions.
- Ryan Greenblatt seems to think we can get a 30x speed-up in AI R&D using near-term, plausibly safe AI systems; assume every AIS researcher can be 30x’d by Alignment MVPs
- Tom Davidson thinks we have <3 years from 20%-AI to 100%-AI; assume we have ~3 years to align AGI with the aid of Alignment MVPs
- Assume the hardness of aligning TAI is equivalent to the Apollo Program (90k engineer/scientist FTEs x 9 years = 810k FTE-years); therefore, we need ~
I appreciate the spirit of this type of calculation, but think that it's a bit too wacky to be that informative. I think that it's a bit of a stretch to string these numbers together. E.g. I think Ryan and Tom's predictions are inconsistent, and I think that it's weird to identify 100%-AI as the point where we need to have "solved the alignment problem", and I think that it's weird to use the Apollo/Manhattan program as an estimate of work required. (I also don't know what your Manhattan project numbers mean: I thought there were more like 2.5k scientists/engineers at Los Alamos, and most of the people elsewhere were purifying nuclear material)
Ah, that's a mistake. Our bad.
Crucial questions for AI safety field-builders:
- What is the most important problem in your field? If you aren't working on it, why?
- Where is everyone else dropping the ball and why?
- Are you addressing a gap in the talent pipeline?
- What resources are abundant? What resources are scarce? How can you turn abundant resources into scarce resources?
- How will you know you are succeeding? How will you know you are failing?
- What is the "user experience" of my program?
- Who would you copy if you could copy anyone? How could you do this?
- Am I better than the counterfactual?
- Who are your clients? What do they want?
Additional resources, thanks to Avery:
- COT Scaling implies slower takeoff speeds (Zoellner - 10 min)
- o1: A Technical Primer (Hoogland - 20 min)
- Unpacking o1 and the Path to AGI (Brown - up to 8:38)
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (Deepmind, Snell - 20 min to skim)
- Speculations on Test-Time Scaling (Rush - from 4:25 to 21:25, 17 min total)
And 115 prospective mentors applied for Summer 2025!
When onboarding advisors, we made it clear that we would not reveal their identities without their consent. I certainly don't want to require that our advisors make their identities public, as I believe this might compromise the intent of anonymous peer review: to obtain genuine assessment, without fear of bias or reprisals. As with most academic journals, the integrity of the process is dependent on the editors; in this case, the MATS team and our primary funders.
It's possible that a mere list of advisor names (without associated ratings) would be sufficient to ensure public trust in our process without compromising the peer review process. We plan to explore this option with our advisors in future.
Yeah, it's definitely a kind of messy tradeoff. My sense is just that the aggregate statistics you provided didn't have that many bits of evidence that would allow me to independently audit a trust chain.
A thing that I do think might be more feasible is to make it opt-in for advisors to be public. E.g. SFF only had a minority of recommenders be public about their identity, but I do still think it helps a good amount to have some names.
(Also, just for historical consistency: Most peer review in the history of science was not anonymous. Anonymous peer review...
Not currently. We thought that we would elicit more honest ratings of prospective mentors from advisors, without fear of public pressure or backlash, if we kept the list of advisors internal to our team, similar to anonymous peer review.
I'm tempted to set this up with Manifund money. Could be a weekend project.
How would you operationalize a contest for short-timeline plans?
Something like the OpenPhil AI worldview contest: https://www.openphilanthropy.org/research/announcing-the-winners-of-the-2023-open-philanthropy-ai-worldviews-contest/
Or the ARC ELK prize: https://www.alignment.org/blog/prizes-for-elk-proposals/
In general, I wouldn't make it too complicated and accept some arbitrariness. There is a predetermined panel of e.g. 5 experts and e.g. 3 categories (feasibility, effectiveness, everything else). All submissions first get scored by 2 experts with a shallow judgment (e.g., 5-10 minutes). Maybe there is some "saving" ...
But who is "MIRI"? Most of the old guard have left. Do you mean Eliezer and Nate? Or a consensus vote of the entire staff (now mostly tech gov researchers and comms staff)?
On my understanding, EA student clubs at colleges/universities have been the main “top of funnel” for pulling people into alignment work during the past few years. The mix people going into those clubs is disproportionately STEM-focused undergrads, and looks pretty typical for STEM-focused undergrads. We’re talking about pretty standard STEM majors from pretty standard schools, neither the very high end nor the very low end of the skill spectrum.
At least from the MATS perspective, this seems quite wrong. Only ~20% of MATS scholars in the last ~4 program...
You could consider doing MATS as "I don't know what to do, so I'll try my hand at something a decent number of apparent experts consider worthwhile and meanwhile bootstrap a deep understanding of this subfield and a shallow understanding of a dozen other subfields pursued by my peers." This seems like a common MATS experience and I think this is a good thing.
Some caveats:
- A crucial part of the "hodge-podge alignment feedback loop" is "propose new candidate solutions, often grounded in theoretical models." I don't want to entirely focus on empirically fleshing out existing research directions to the exclusion of proposing new candidate directions. However, it seems that, often, new on-paradigm research directions emerge in the process of iterating on old ones!
- "Playing theoretical builder-breaker" is an important skill and I think this should be taught more widely. "Iterators," as I conceive of them, are capable
Alice is excited about the eliciting latent knowledge (ELK) doc, and spends a few months working on it. Bob is excited about debate, and spends a few months working on it. At the end of those few months, Alice has a much better understanding of how and why ELK is hard, has correctly realized that she has no traction on it at all, and pivots to working on technical governance. Bob, meanwhile, has some toy but tangible outputs, and feels like he's making progress.
I don't want to respond to the examples rather than the underlying argument, but it seems ...
Some caveats:
- A crucial part of the "hodge-podge alignment feedback loop" is "propose new candidate solutions, often grounded in theoretical models." I don't want to entirely focus on empirically fleshing out existing research directions to the exclusion of proposing new candidate directions. However, it seems that, often, new on-paradigm research directions emerge in the process of iterating on old ones!
- "Playing theoretical builder-breaker" is an important skill and I think this should be taught more widely. "Iterators," as I conceive of them, are capable
Obviously I disagree with Tsvi regarding the value of MATS to the proto-alignment researcher; I think being exposed to high quality mentorship and peer-sourced red-teaming of your research ideas is incredibly valuable for emerging researchers. However, he makes a good point: ideally, scholars shouldn't feel pushed to write highly competitive LTFF grant applications so soon into their research careers; there should be longer-term unconditional funding opportunities. I would love to unlock this so that a subset of scholars can explore diverse research directions for 1-2 years without 6-month grant timelines looming over them. Currently cooking something in this space.
I'm not sure!
We don't collect GRE/SAT scores, but we do have CodeSignal scores and (for the first time) a general aptitude test developed in collaboration with SparkWave. Many MATS applicants have maxed out scores for the CodeSignal and general aptitude tests. We might share these stats later.
I don't agree with the following claims (which might misrepresent you):
- "Skill levels" are domain agnostic.
- Frontier oversight, control, evals, and non-"science of DL" interp research is strictly easier in practice than frontier agent foundations and "science of DL" interp research.
- The main reason there is more funding/interest in the former category than the latter is due to skill issues, rather than worldview differences and clarity of scope.
- MATS has mid researchers relative to other programs.
I don't think it makes sense to compare Google intern salary with AIS program stipends this way, as AIS programs are nonprofits (with associated salary cut) and generally trying to select against people motivated principally by money. It seems like good mechanism design to pay less than tech internships, even if the technical bar for is higher, given that value alignment is best selected by looking for "costly signals" like salary sacrifice.
I don't think the correlation for competence among AIS programs is as you describe.
I think there some confounders here:
- PIBBSS had 12 fellows last cohort and MATS had 90 scholars. The mean/median MATS Summer 2024 scholar was 27; I'm not sure what this was for PIBBSS. The median age of the 12 oldest MATS scholars was 35 (mean 36). If we were selecting for age (which is silly/illegal, of course) and had a smaller program, I would bet that MATS would be older than PIBBSS on average. MATS also had 12 scholars with completed PhDs and 11 in-progress.
- Several PIBBSS fellows/affiliates have done MATS (e.g., Ann-Kathrin Dombrowski, Magdalena Wache,
Are these PIBBSS fellows (MATS scholar analog) or PIBBSS affiliates (MATS mentor analog)?
Updated figure with LASR Labs and Pivotal Research Fellowship at current exchange rate of 1 GBP = 1.292 USD.

That seems like a reasonable stipend for LASR. I don't think they cover housing, however.
That said, maybe you are conceptualizing of an "efficient market" that principally values impact, in which case I would expect the governance/policy programs to have higher stipends. However, I'll note that 87% of MATS alumni are interested in working at an AISI and several are currently working at UK AISI, so it seems that MATS is doing a good job of recruiting technical governance talent that is happy to work for government wages.
Note that governance/policy jobs pay less than ML research/engineering jobs, so I expect GovAI, IAPS, and ERA, which are more governance focused, to have a lower stipend. Also, MATS is deliberately trying to attract top CS PhD students, so our stipend should be higher than theirs, although lower than Google internships to select for value alignment. I suspect that PIBBSS' stipend is an outlier and artificially low due to low funding. Given that PIBBSS has a mixture of ML and policy projects, and IMO is generally pursuing higher variance research than MATS, I suspect their optimal stipend would be lower than MATS', but higher than a Stanford PhD's; perhaps around IAPS' rate.
I'm open to this argument, but I'm not sure it's true under the Trump administration.