Could orcas be (trained to be) smarter than humans?
(Btw everything I write here about orcas also applies to a slightly lesser extent to pilot whales (especially long finned ones)[1].) (I'm very very far from an orca expert - basically everything I know about them I learned today.) I always thought that bigger animals might have bigger brains than humans but not actually more neurons in their neocortex (like elephants) and that number of neurons in the neocortex or prefrontal cortex might be a good inter-species indicator of intelligence for mammalian brains.[2] Yesterday I discovered that orcas actually have 2.05 times as many neurons in their neocortex[3] than humans from this wikipedia list. Interestingly though, given my pretty bad model of how intelligent some species are, the "number of neurons in neocortex" still seems like a proxy that doesn't perform too badly on the wikipedia list. Orca brains are not just larger but also more strongly folded. Orcas are generally regarded as one of the smartest animal species, sometimes as the smartest, but I'm wondering whether they might actually be smarter than humans -- in the sense that they could be superhuman at abstract problem solving if given comparable amounts of training as humans. Another phrasing to clarify what I mean by "could trained to be smarter": Average orcas significantly (possibly vastly) outperforming average (or even all) humans at solving scientific problems, if we enabled them to use computers through BCI and educated them from childhood like (gifted?) human children.[4] I would explain the evidence and considerations here in more detail but luckily someone else already wrote the post I wanted to write on reddit, only a lot better than I could've. I highly recommend checking this out (5min read): https://www.reddit.com/r/biology/comments/16y81ct/the_case_for_whales_actually_matching_or_even/ One more thing that feels worth adding: * Orcas are very social animals.[5] It's plausible to me that what caused humans to become this intelligent w
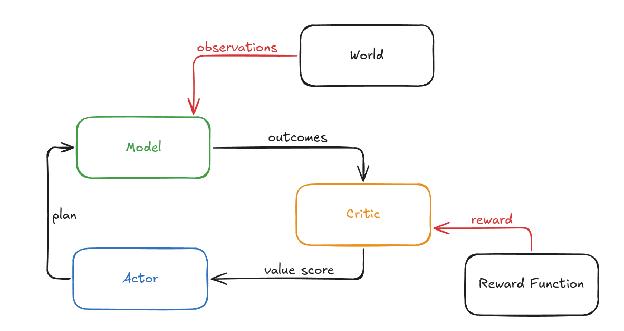
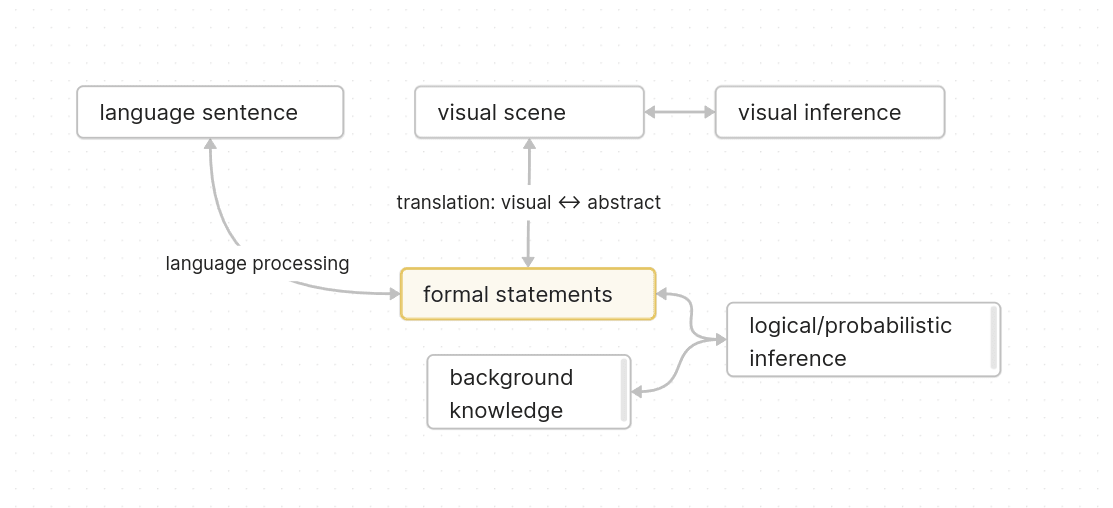
Btw if you mean there are 10k contributions already that are on the level of John's contributions, I strongly disagree with this. I'm not sure whether John's math is significantly useful, and I don't think it's been that much progress relative to "almost on track to maybe solve alignment", but in terms of (alignment) philosophy John's work is pretty great compared to academic philosophy.
In... (read more)