DeepMind alignment team opinions on AGI ruin arguments
We had some discussions of the AGI ruin arguments within the DeepMind alignment team to clarify for ourselves which of these arguments we are most concerned about and what the implications are for our work. This post summarizes the opinions of a subset of the alignment team on these arguments. Disclaimer: these are our own opinions that do not represent the views of DeepMind as a whole or its broader community of safety researchers. This doc shows opinions and comments from 8 people on the alignment team (without attribution). For each section of the list, we show a table summarizing agreement / disagreement with the arguments in that section (the tables can be found in this sheet). Each row is sorted from Agree to Disagree, so a column does not correspond to a specific person. We also provide detailed comments and clarifications on each argument from the team members. For each argument, we include a shorthand description in a few words for ease of reference, and a summary in 1-2 sentences (usually copied from the bolded parts of the original arguments). We apologize for some inevitable misrepresentation of the original arguments in these summaries. Note that some respondents looked at the original arguments while others looked at the summaries when providing their opinions (though everyone has read the original list at some point before providing opinions). A general problem when evaluating the arguments was that people often agreed with the argument as stated, but disagreed about the severity of its implications for AGI risk. A lot of these ended up as "mostly agree / unclear / mostly disagree" ratings. It would have been better to gather two separate scores (agreement with the statement and agreement with implications for risk). Summary of agreements, disagreements and implications Most agreement: * Section A ("strategic challenges"): #1 (human level is nothing special), #2 (unaligned superintelligence could easily take over), #8 (capabilities generaliz
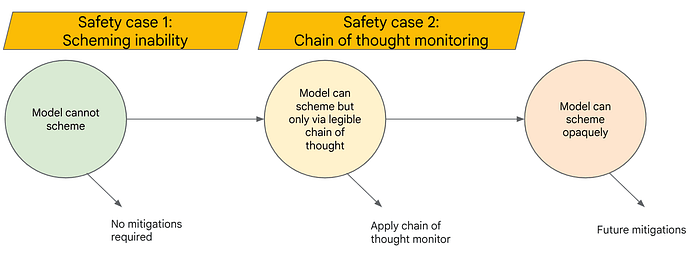

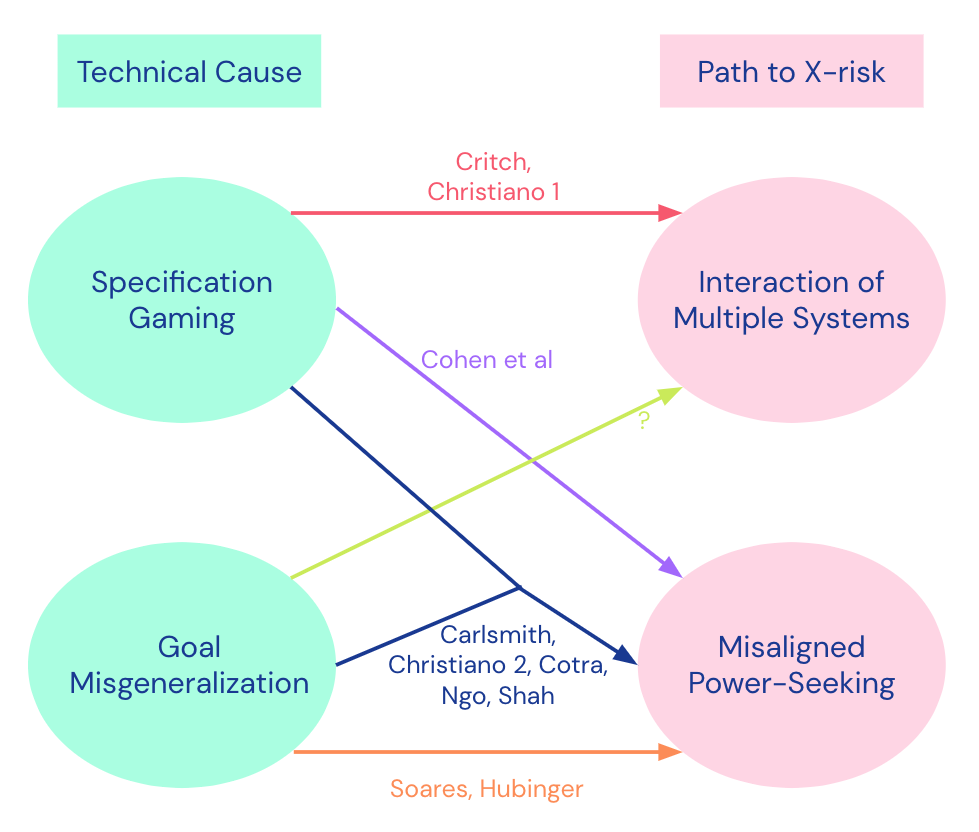
Similarly to Leo, I think racing to AGI is bad and it would be good to coordinate not to do that. I support proposals for AI regulations that would make this easier. I signed various open letters to this effect on AI red lines, AI Treaty, SB1047, and others.
I'm pretty uncertain if pushing for an AI pause now is an effective way to achieve this, and I think it's quite plausibly better to pause later rather than now. In the next few years, we will have more solid evidence of misalignment, and we would be able to make better use of a pause period (which is likely to be finite) e.g. with automated... (read more)