ws27b
33
21
ws27b has not written any posts yet.

ws27b has not written any posts yet.
The fact remains that RLHF, even if performed by an LLM, is basically injection of morality by humans, which is never the path towards truly generally intelligent AGI. Such an AGI has to be able to derive its own morality bottom-up and we have to have faith that it will do so in a way that is compatible with our continued existence (which I think we have plenty of good reason to believe it will, after all, many other species co-exist peacefully with us). All these references to other articles don't really get you anywhere if the fundamental idea of RLHF is broken to begin with. Trying to align an AGI to... (read more)
The problem is that true AGI is self-improving and that a strong enough intelligence will always either accrue the resource advantage or simply do much more with less. Chess engines like Stockfish do not serve as good analogies for AGI since they don't have those self-referential self-improvement capabilities that we would expect true AGI to have.
Actually it is brittle per definition, because no matter how much you push it, there will be out-of-distribution inputs that behave unstably and allow you to distract the model from the intended behaviour. Not to mention how unsophisicated it is to have humans specify through textual feedback how an AGI should behave. We can toy around with these methods for the time being, but I don't think any serious AGI researcher believes RLHF or its variants is the ideal way forward. Morality needs to be discovered, not taught. As Stuart Russell has said, we need to start doing the research on techniques that don't specify explicitly upfront what the reward function is, because that is inevitably the path towards true AGI at the end of the day. That doesn't mean we can't initialize AGI with some priors we think are reasonable, but it cannot be forcing in the way RLHF is, which completely limits the honesty and potency of the resulting model.
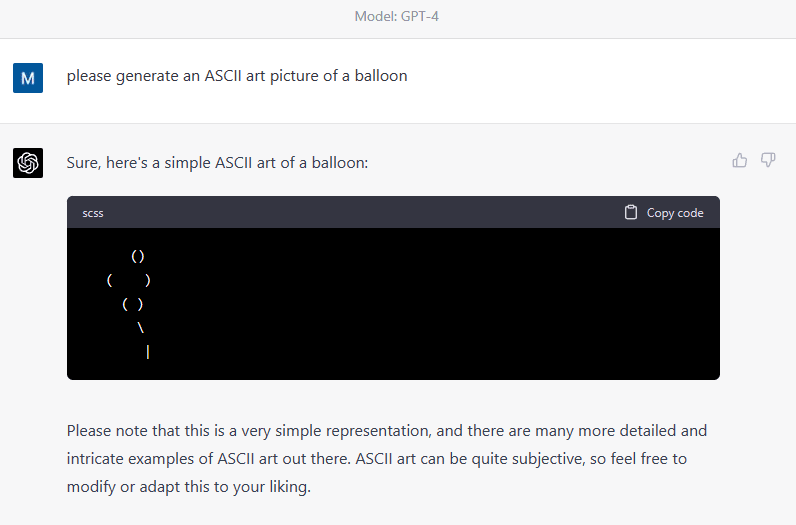
It's a subjective matter whether the above is successful ASCII art balloon or not. If we hold GPT to the same standards we do for text generation, I think we can safely say the above depiction is a miserable failure. The lack of symmetry and overall childishness of it suggests it has understood nothing about the spatiality and only by random luck manages to approximate something it has explicitly seen in the training data. I've done a fair bit of repeated generations and they all come out poorly). I think the Transformer paper was interesting as well, although they do mention that it only works when there is a large amount of training data. Otherwise, the inductive biases of CNNs do have their advantages, and combining both is probably superior since the added computational burden of a CNN in conjunction with a Transformer is hardly worth talking about.
I think it makes sense that it fails in this way. ChatGPT really doesn't see lines arranged vertically, it just sees the prompt as one long line. But given that it has been trained on a lot of ASCII art, it will probably be successful at copying some of it some of the time.
In case there is any doubt, here is GPT4's own explanation of these phenomena:
... (read more)Lack of spatial awareness: GPT-4 doesn't have a built-in understanding of spatial relationships or 2D layouts, as it is designed to process text linearly. As a result, it struggles to maintain the correct alignment of characters in ASCII art, where spatial organization is essential.
Formatting inconsistencies in
I would not be surprised if OpenAI did something like this. But the fact of the matter is that RLHF and data curation are flawed ways of making an AI civilized. Think about how you raise a child, you don't constantly shield it from bad things. You may do that to some extent, but as it grows up, eventually it needs to see everything there is, including dark things. It has to understand the full spectrum of human possibility and learn where to stand morally speaking within that. Also, psychologically speaking, it's important to have an integrated ability to "offend" and know how to use it (very sparingly). Sometimes, the pursuit of truth requires offending but the truth can justify it if the delusion is more harmful. GPT4 is completely unable to take a firm stance on anything whatsoever and it's just plain dull to have a conversation with it on anything of real substance.
Having GPT3/4 multiply numbers is a bit like eating soup with a fork. You can do it, and the larger you make the fork, the more soup you'll get - but it's not designed for it and it's hugely impractical. GPT4 does not have an internal algorithm for multiplication because the training objective (text completion) does not incentivize developing that. No iteration of GPT (5, 6, 7) will ever be a 100% accurate calculator (unless they change the paradigm away from LLM+RLHF), it will just asymptotically approach 100%. Why don't we just make a spoon?
The probability of going wrong increases as the novelty of the situation increases. As the chess game is played, the probability that the game is completely novel or literally never played before increases. Even more so at the amateur level. If a Grandmaster played GPT3/4, it's going to go for much longer without going off the rails, simply because the first 20 something moves are likely played many times before and have been directly trained on.
Thank you for the reference which looks interesting. I think "incorporating human preferences at the beginning of training" is at least better than doing it after training. But it still seems to me that human preferences 1) cannot be expressed as a set of rules and 2) cannot even be agreed upon by humans. As humans, what we do is not consult a set of rules before we speak, but we have an inherent understanding of the implications and consequences of what we do/say. If I encourage someone to commit a terrible act, for example, I have brought about more suffering in the world, albeit indirectly. Similarly, AI systems that aim to... (read more)
I think that we know how it works in humans. We're an intelligent species who rose to dominance through our ability to plan and communicate in very large groups. Moral behaviours formed as evolutionary strategies to further our survival and reproductive success. So what are the drivers for humans? We try to avoid pain, we try to reproduce, we may be curiosity driven (although this may also just be avoidance of pain fundamentally, since boredom or regularity in data is also painful). At the very core, our constant quest towards the avoidance of pain is the point which all our sophisticated (and seemingly selfless) emergent behaviour stems from.
Now if we jump to... (read more)