All of Zach Stein-Perlman's Comments + Replies
Wow. Very surprising.
xAI Risk Management Framework (Draft)
You're mostly right about evals/thresholds. Mea culpa. Sorry for my sloppiness.
For misuse, xAI has benchmarks and thresholds—or rather examples of benchmarks thresholds to appear in the real future framework—and based on the right column they seem very reasonably low.

Unlike other similar documents, these are not thresholds at which to implement mitigations but rather thresholds to reduce performance to. So it seems the primary concern is probably not the thresholds are too high but rather xAI's mitigations won't be robu...
This shortform discusses the current state of responsible scaling policies (RSPs). They're mostly toothless, unfortunately.
The Paris summit was this week. Many companies had committed to make something like an RSP by the summit. Half of them did, including Microsoft, Meta, xAI, and Amazon. (NVIDIA did not—shame on them—but I hear they are writing something.) Unfortunately but unsurprisingly, these policies are all vague and weak.
RSPs essentially have four components: capability thresholds beyond which a model might b...
capability thresholds be vague or extremely high
xAI's thresholds are entirely concrete and not extremely high.
evaluation be unspecified or low-quality
They are specified and as high-quality as you can get. (If there are better datasets let me know.)
I'm not saying it's perfect, but I wouldn't but them all in the same bucket. Meta's is very different from DeepMind's or xAI's.
There also used to be a page for Preparedness: https://web.archive.org/web/20240603125126/https://openai.com/preparedness/. Now it redirects to the safety page above.
(Same for Superalignment but that's less interesting: https://web.archive.org/web/20240602012439/https://openai.com/superalignment/.)
DeepMind updated its Frontier Safety Framework (blogpost, framework, original framework). It associates "recommended security levels" to capability levels, but the security levels are low. It mentions deceptive alignment and control (both control evals as a safety case and monitoring as a mitigation); that's nice. The overall structure is like we'll do evals and make a safety case, with some capabilities mapped to recommended security levels in advance. It's not very commitment-y:
We intend to evaluate our most powerful frontier models regularly
...
My guess is it's referring to Anthropic's position on SB 1047, or Dario's and Jack Clark's statements that it's too early for strong regulation, or how Anthropic's policy recommendations often exclude RSP-y stuff (and when they do suggest requiring RSPs, they would leave the details up to the company).
o3-mini is out (blogpost, tweet). Performance isn't super noteworthy (on first glance), in part since we already knew about o3 performance.
Non-fact-checked quick takes on the system card:
the model referred to below as the o3-mini post-mitigation model was the final model checkpoint as of Jan 31, 2025 (unless otherwise specified)
Big if true (and if Preparedness had time to do elicitation and fix spurious failures)
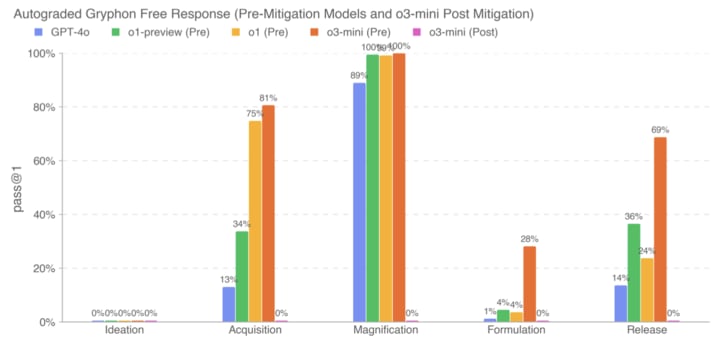
If this is robust to jailbreaks, great, but presumably it's not, so low post-mitigation performance is far from sufficient for safety-from-misuse;...
Thanks. The tax treatment is terrible. And I would like more clarity on how transformative AI would affect S&P 500 prices (per this comment). But this seems decent (alongside AI-related calls) because 6 years is so long.
I wrote this for someone but maybe it's helpful for others
What labs should do:
- I think the most important things for a relatively responsible company are control and security. (For irresponsible companies, I roughly want them to make a great RSP and thus become a responsible company.)
- Reading recommendations for people like you (not a control expert but has context to mostly understand the Greenblatt plan):
- Control: Redwood blogposts[1] or ask a Redwood human "what's the threat model" and "what are the most promising control techniques"
- Security: not
I think ideally we'd have several versions of a model. The default version would be ignorant about AI risk, AI safety and evaluation techniques, and maybe modern LLMs (in addition to misuse-y dangerous capabilities). When you need a model that's knowledgeable about that stuff, you use the knowledgeable version.
Somewhat related: https://www.alignmentforum.org/posts/KENtuXySHJgxsH2Qk/managing-catastrophic-misuse-without-robust-ais
Yeah, I agree with this and am a fan of this from the google doc:
Remove biology, technical stuff related to chemical weapons, technical stuff related to nuclear weapons, alignment and AI takeover content (including sci-fi), alignment or AI takeover evaluation content, large blocks of LM generated text, any discussion of LLMs more powerful than GPT2 or AI labs working on LLMs, hacking, ML, and coding from the training set.
and then fine-tune if you need AIs with specific info. There are definitely issues here with AIs doing safety research (e.g., to solve risks from deceptive alignment they need to know what that is), but this at least buys some marginal safety.
[Perfunctory review to get this post to the final phase]
Solid post. Still good. I think a responsible developer shouldn't unilaterally pause but I think it should talk about the crazy situation it's in, costs and benefits of various actions, what it would do in different worlds, and its views on risks. (And none of the labs have done this; in particular Core Views is not this.)
One more consideration against (or an important part of "Bureaucracy"): sometimes your lab doesn't let you publish your research.
Some people have posted ideas on what a reasonable plan to reduce AI risk for such timelines might look like (e.g. Sam Bowman’s checklist, or Holden Karnofsky’s list in his 2022 nearcast), but I find them insufficient for the magnitude of the stakes (to be clear, I don’t think these example lists were intended to be an extensive plan).
See also A Plan for Technical AI Safety with Current Science (Greenblatt 2023) for a detailed (but rough, out-of-date, and very high-context) plan.
Yeah. I agree/concede that you can explain why you can't convince people that their own work is useless. But if you're positing that the flinchers flinch away from valid arguments about each category of useless work, that seems surprising.
The flinches aren't structureless particulars. Rather, they involve warping various perceptions. Those warped perceptions generalize a lot, causing other flaws to be hidden.
As a toy example, you could imagine someone attached to the idea of AI boxing. At first they say it's impossible to break out / trick you / know about the world / whatever. Then you convince them otherwise--that the AI can do RSI internally, and superhumanly solve computer hacking / protein folding / persuasion / etc. But they are attached to AI boxing. So they warp their perception, cl...
I feel like John's view entails that he would be able to convince my friends that various-research-agendas-my-friends-like are doomed. (And I'm pretty sure that's false.) I assume John doesn't believe that, and I wonder why he doesn't think his view entails it.
I wonder whether John believes that well-liked research, e.g. Fabien's list, is actually not valuable or rare exceptions coming from a small subset of the "alignment research" field.
I do not.
On the contrary, I think ~all of the "alignment researchers" I know claim to be working on the big problem, and I think ~90% of them are indeed doing work that looks good in terms of the big problem. (Researchers I don't know are likely substantially worse but not a ton.)
In particular I think all of the alignment-orgs-I'm-socially-close-to do work that looks good in terms of the big problem: Redwood, METR, ARC. And I think the other well-known orgs are also good.
This doesn't feel odd: these people are smart and actually care about the big problem;...
Yeah, I agree sometimes people decide to work on problems largely because they're tractable [edit: or because they’re good for safety getting alignment research or other good work out of early AGIs]. I'm unconvinced of the flinching away or dishonest characterization.
This post starts from the observation that streetlighting has mostly won the memetic competition for alignment as a research field, and we'll mostly take that claim as given. Lots of people will disagree with that claim, and convincing them is not a goal of this post.
Yep. This post is not for me but I'll say a thing that annoyed me anyway:
... and Carol's thoughts run into a blank wall. In the first few seconds, she sees no toeholds, not even a starting point. And so she reflexively flinches away from that problem, and turns back to some easier problems.
Doe...
Does this actually happen?
Yes, absolutely. Five years ago, people were more honest about it, saying ~explicitly and out loud "ah, the real problems are too difficult; and I must eat and have friends; so I will work on something else, and see if I can get funding on the basis that it's vaguely related to AI and safety".
DeepSeek-V3 is out today, with weights and a paper published. Tweet thread, GitHub, report (GitHub, HuggingFace). It's big and mixture-of-experts-y; discussion here and here.
It was super cheap to train — they say 2.8M H800-hours or $5.6M (!!).
It's powerful:
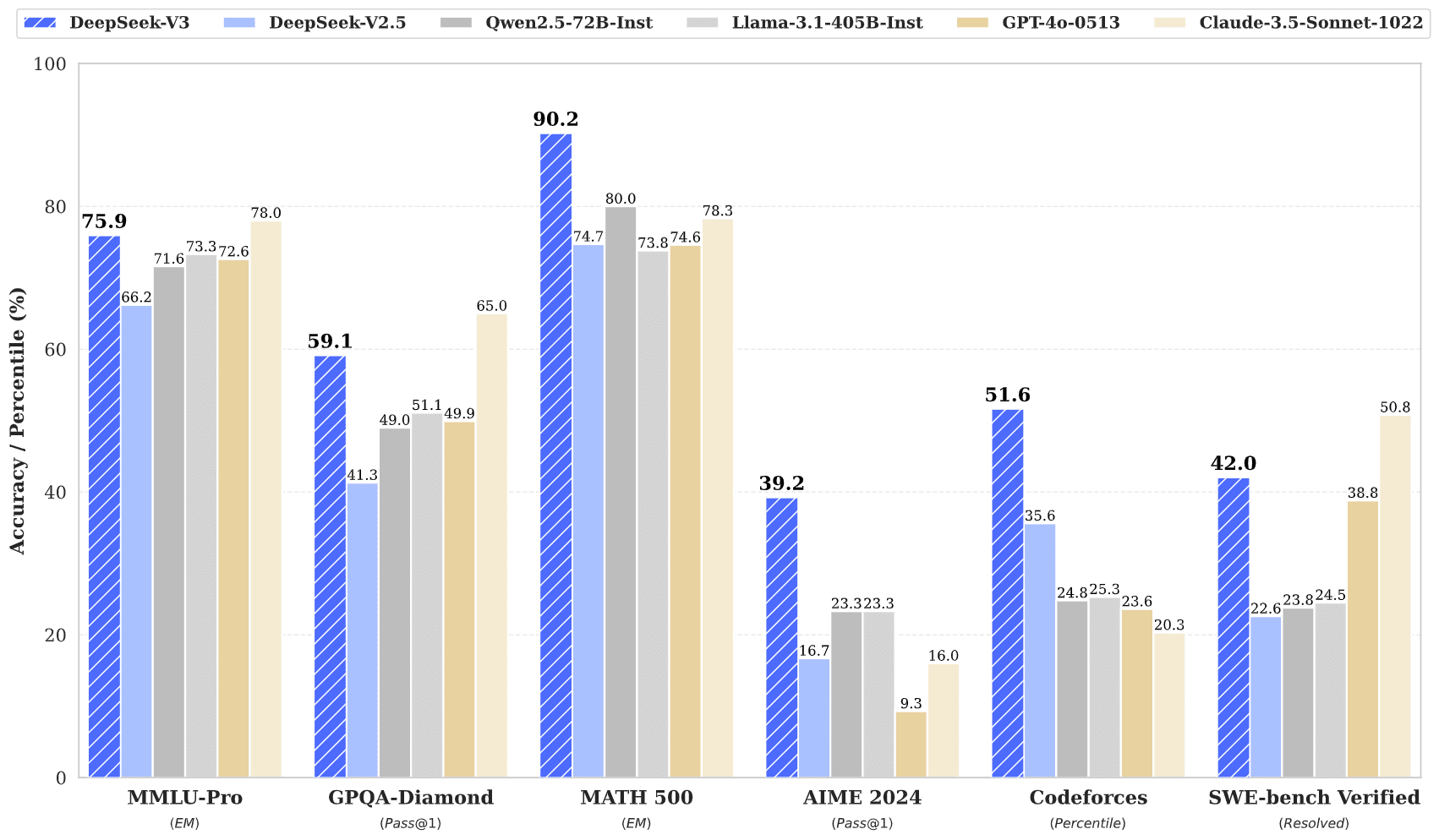
It's cheap to run:
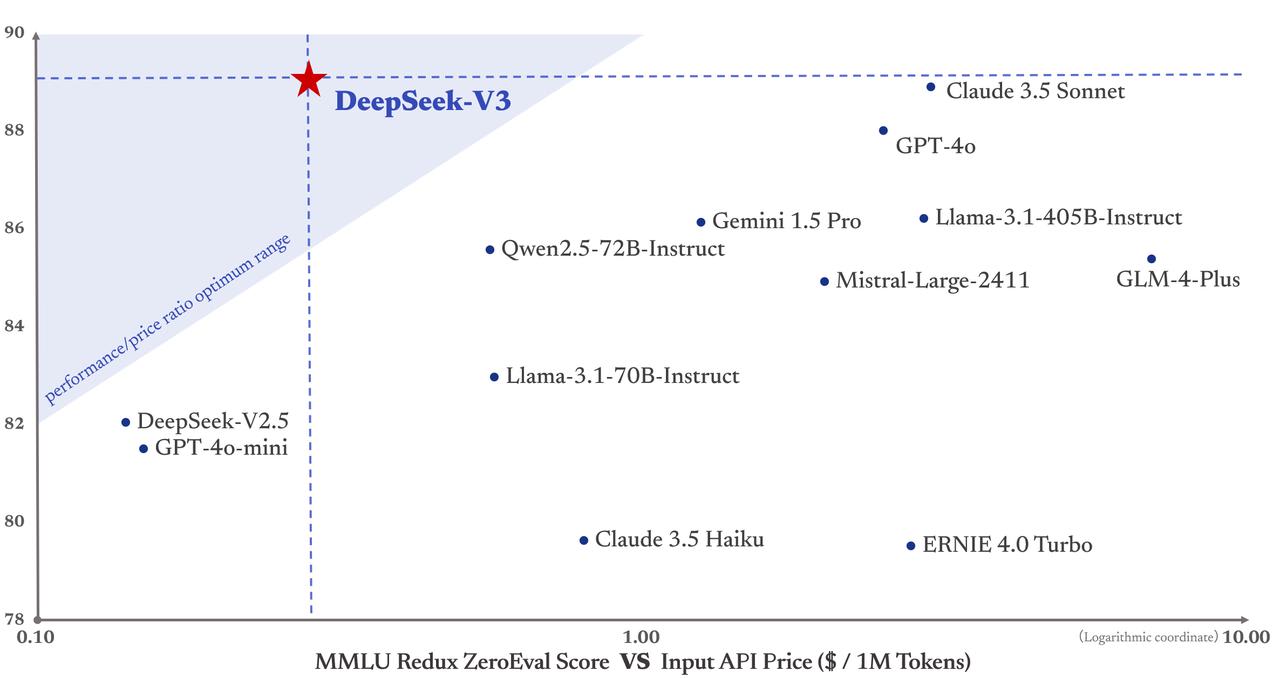
Update: the weights and paper are out. Tweet thread, GitHub, report (GitHub, HuggingFace). It's big and mixture-of-experts-y; thread on notable stuff.
It was super cheap to train — they say 2.8M H800-hours or $5.6M.
It's powerful:
It's cheap to run:
Every now and then (~5-10 minutes, or when I look actively distracted), briefly check in (where if I'm in-the-zone, this might just be a brief "Are you focused on what you mean to be?" from them, and a nod or "yeah" from me).
Some other prompts I use when being a [high-effort body double / low-effort metacognitive assistant / rubber duck]:
- What are you doing?
- What's your goal?
- Or: what's your goal for the next n minutes?
- Or: what should be your goal?
- Are you stuck?
- Follow-ups if they're stuck:
- what should you do?
- can I help?
- have you considered asking someone for he
- Follow-ups if they're stuck:
All of the founders committed to donate 80% of their equity. I heard it's set aside in some way but they haven't donated anything yet. (Source: an Anthropic human.)
This fact wasn't on the internet, or rather at least wasn't easily findable via google search. Huh. I only find Holden mentioning 80% of Daniela's equity is pledged.
I disagree with Ben. I think the usage that Mark is talking about is a reference to Death with Dignity. A central example (written by me) is
it would be undignified if AI takes over because we didn't really try off-policy probes; maybe they just work really well; someone should figure that out
It's playful and unserious but "X would be undignified" roughly means "it would be an unfortunate error if we did X or let X happen" and is used in the context of AI doom and our ability to affect P(doom).
edit: wait likely it's RL; I'm confused
OpenAI didn't fine-tune on ARC-AGI, even though this graph suggests they did.
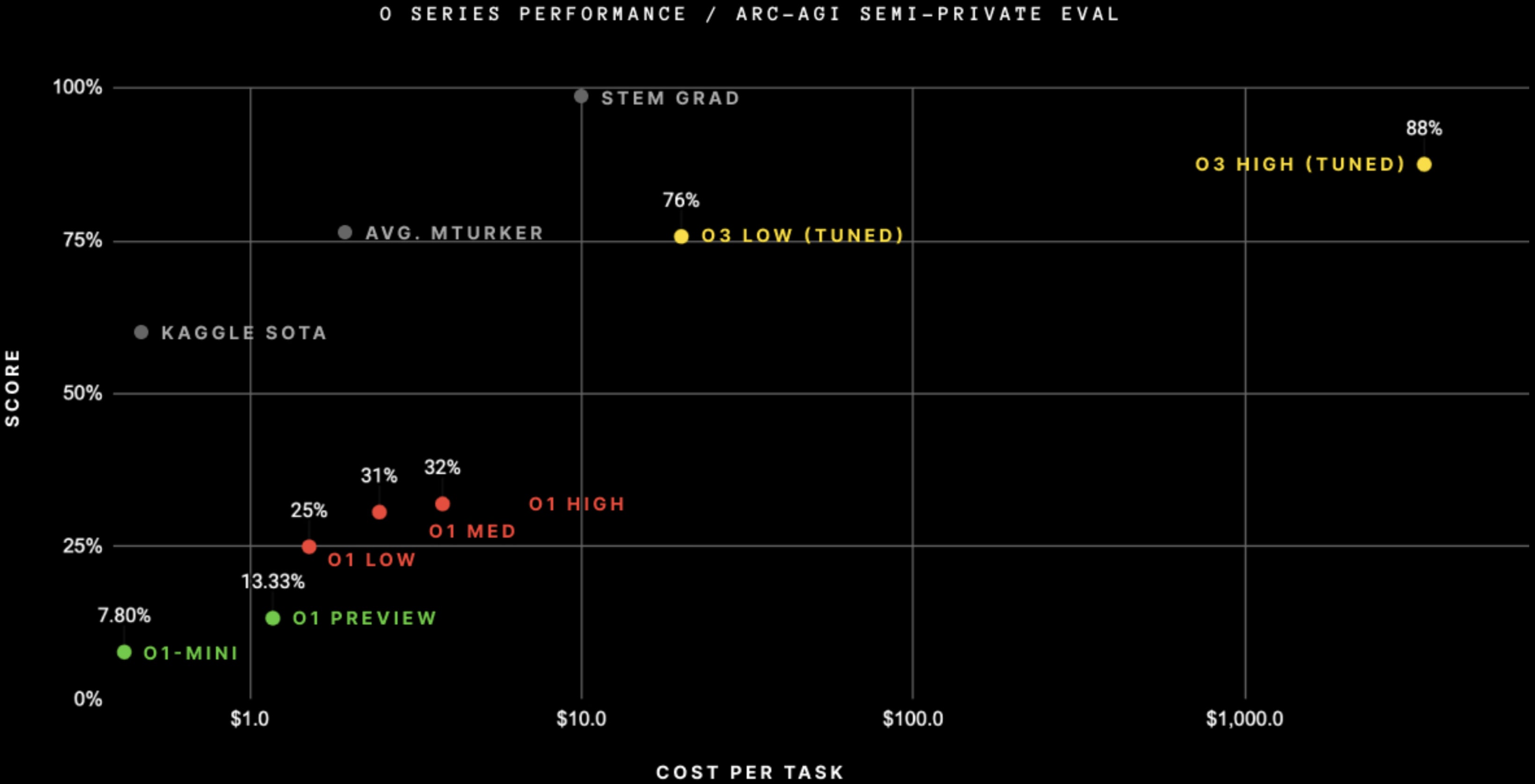
Sources:
Altman said
we didn't go do specific work [targeting ARC-AGI]; this is just the general effort.
François Chollet (in the blogpost with the graph) said
Note on "tuned": OpenAI shared they trained the o3 we tested on 75% of the Public Training set. They have not shared more details. We have not yet tested the ARC-untrained model to understand how much of the performance is due to ARC-AGI data.
...The version of the model we tested was domai
Welcome!
To me the benchmark scores are interesting mostly because they suggest that o3 is substantially more powerful than previous models. I agree we can't naively translate benchmark scores to real-world capabilities.
I think he’s just referring to DC evals, and I think this is wrong because I think other companies doing evals wasn’t really caused by Anthropic (but I could be unaware of facts).
Edit: maybe I don't know what he's referring to.
DC evals got started in summer of '22, across all three leading companies AFAICT. And I was on the team that came up with the idea and started making it happen (both internally and externally), or at least, as far as I can tell we came up with the idea -- I remember discussions between Beth Barnes and Jade Leung (who were both on the team in spring '22), and I remember thinking it was mostly their idea (maybe also Cullen's?) It's possible that they got it from Anthropic but it didn't seem that way to me. Update: OK, so apparently @evhub had joined Anthropi...
I use empty brackets similar to ellipses in this context; they denote removed nonsubstantive text. (I use ellipses when removing substantive text.)
I think they only have formal high and low versions for o3-mini
Edit: nevermind idk
Done, thanks.
I already edited out most of the "like"s and similar. I intentionally left some in when they seemed like they might be hedging or otherwise communicating this isn't exact. You are free to post your own version but not to edit mine.
Edit: actually I did another pass and edited out several more; thanks for the nudge.
pass@n is not cheating if answers are easy to verify. E.g. if you can cheaply/quickly verify that code works, pass@n is fine for coding.
and then having the model look at all the runs and try to figure out which run had the most compelling-seeming reasoning
The FrontierMath answers are numerical-ish ("problems have large numerical answers or complex mathematical objects as solutions"), so you can just check which answer the model wrote most frequently.
The obvious boring guess is best of n. Maybe you're asserting that using $4,000 implies that they're doing more than that.
Performance at $20 per task is already much better than for o1, so it can't be just best-of-n, you'd need more attempts to get that much better even if there is a very good verifier that notices a correct solution (at $4K per task that's plausible, but not at $20 per task). There are various clever beam search options that don't need to make inference much more expensive, but in principle might be able to give a boost at low expense (compared to not using them at all).
There's still no word on the 100K H100s model, so that's another possibility. Currently C...
My guess is they do kinda choose: in training, it's less like two debaters are assigned opposing human-written positions and more like the debate is between two sampled outputs.
Edit: maybe this is different in procedures different from the one Rohin outlined.
The more important zoom-level is: debate is a proposed technique to provide a good training signal. See e.g. https://www.lesswrong.com/posts/eq2aJt8ZqMaGhBu3r/zach-stein-perlman-s-shortform?commentId=DLYDeiumQPWv4pdZ4.
Edit: debate is a technique for iterated amplification -- but that tag is terrible too, oh no
I asked Rohin Shah what the debate agenda is about and he said (off the cuff, not necessarily worded well) (context omitted) (emphasis mine):
...Suppose you have any task where given an input x the AI has to produce some output y. (Can be question answering, arbitrary chatbot stuff, being an agent, whatever.)
Debate to me is a family of procedures for training AIs in such settings. One example such procedure is: sample two possible outputs y1 and y2, then have two AIs debate each other about which output is better (one assigned to y1 and the other assigned to y
The hope is that the debaters are incentivized to simply say which output is better, to the best of their ability,
How is this true, if the debaters don't get to choose which output they are arguing for? Aren't they instead incentivized to say that whatever output they are assigned is the best?
This post presented the idea of RSPs and detailed thoughts on them, just after Anthropic's RSP was published. It's since become clear that nobody knows how to write an RSP that's predictably neither way too aggressive nor super weak. But this post, along with the accompanying Key Components of an RSP, is still helpful, I think.
This is the classic paper on model evals for dangerous capabilities.
On a skim, it's aged well; I still agree with its recommendations and framing of evals. One big exception: it recommends "alignment evaluations" to determine models' propensity for misalignment, but such evals can't really provide much evidence against catastrophic misalignment; better to assume AIs are misaligned and use control once dangerous capabilities appear, until much better misalignment-measuring techniques appear.
Interesting point, written up really really well. I don't think this post was practically useful for me but it's a good post regardless.
This post helped me distinguish capabilities-y information that's bad to share from capabilities-y information that's fine/good to share. (Base-model training techniques are bad; evals and eval results are good; scaffolding/prompting/posttraining techniques to elicit more powerful capabilities without more spooky black-box cognition is fine/good.)
To avoid deploying a dangerous model, you can either (1) test the model pre-deployment or (2) test a similar older model with tests that have a safety buffer such that if the old model is below some conservative threshold it's very unlikely that the new model is dangerous.
DeepMind says it uses the safety-buffer plan (but it hasn't yet said it has operationalized thresholds/buffers).
Anthropic's original RSP used the safety-buffer plan; its new RSP doesn't really use either plan (kinda safety-buffer but it's very weak). (This is unfortunate.)
OpenAI seemed to...
This early control post introduced super important ideas: trusted monitoring plus the general point
if you think about approaches to safely using AIs that are robust to deceptive alignment and which can be used right now, a core dynamic is trying to use your dumb trusted models together with your limited access to trusted humans to make it hard for your untrusted smart models to cause problems.
Briefly:
- For OpenAI, I claim the cyber, CBRN, and persuasion Critical thresholds are very high (and also the cyber High threshold). I agree the autonomy Critical threshold doesn't feel so high.
- For Anthropic, most of the action is at ASL-4+, and they haven't even defined the ASL-4 standard yet. (So you can think of the current ASL-4 thresholds as infinitely high. I don't think "The thresholds are very high" for OpenAI was meant to imply a comparison to Anthropic; it's hard to compare since ASL-4 doesn't exist. Sorry for confusion.)
Edit 2: after checking, I now believe the data strongly suggest FTX had a large negative effect on EA community metrics. (I still agree with Buck: "I don't like the fact that this essay is a mix of an insightful generic argument and a contentious specific empirical claim that I don't think you support strongly; it feels like the rhetorical strength of the former lends credence to the latter in a way that isn't very truth-tracking." And I disagree with habryka's claims that the effect of FTX is obvious.)
...
Practically all growth metrics are down (and have indeed turned negative on most measures), a substantial fraction of core contributors are distancing themselves from the EA affiliation, surveys among EA community builders report EA-affiliation as a major recurring obstacle[1], and many of the leaders who previously thought it wasn't a big deal now concede that it was/is a huge deal.
Also, informally, recruiting for things like EA Fund managers, or getting funding for EA Funds has become substantially harder. EA leadership positions appear to be filled by l...
Good point, thanks. I think eventually we should focus more on reducing P(doom | sneaky scheming) but for now focusing on detection seems good.