Excellent summary, Harrison! I especially enjoyed your use of pillar diagrams to break up streams of text. In general, I found your post very approachable and readable.
As for Pillar 2: I find the description of goals as "generalised concepts" still pretty confusing after reading your summary. I don't think this example of a generalised concept counts as a goal: "things that are perfectly round are objects called spheres; 6-sided boxes are objects called cubes". This statement is a fact, but a goal is a normative preference about the world (cf. the is-ought distinction).
Also, I think the 'coherence' trait could do with slightly more deconfusion - you could phrase it as "goals are internally consistent and stable over time".
I think the most tenuous pillar in Ngo's argument is Pillar 2: that AI will be agentic with large-scale goals. It's plausible that the economic incentives for developing a CEO-style AI with advanced planning capabilities will not be as strong as stated. I agree that there is a strong economic incentive for CEO-style AI which can improve business decision-making. However, I'm not convinced that creating an agentic AI with large-scale goals is the best way to do this. We don't have enough information about which kinds of AI are most cost-effective for doing business decision-making. For example, the AI field may develop viable models that don't display these pesky agentic tendencies.
(On the other hand, it does seem plausible that an agentic AI with large-scale goals is a very parsimonious/natural/easily-found-by-SGD model for such business decision-making tasks.)
This is meant to be supplemental to Richard Ngo’s AGI Safety from First Principles sequence. It can serve as an overview/guide to the sequence, and an outline for navigating his core claims. It's also a submission for the AIMS Distillation contest.
Preamble: (you can skip this if you’re just looking to get into the arguments right away)
This post can be read independently of the sequence as well. Just be aware that some details may be left out in this case, and you should refer to Ngo’s sequence to get a more-detailed idea of the arguments if anything seems dissatisfying here.
Most of these ideas are Ngo’s, not mine. I provide some examples and different ways of viewing things, but the core arguments don’t necessarily represent my views (and they might not represent Ngo’s either, though I tried my best to give a fair summary!)
Intended Audience: Those new to the case for why the development of artificial general intelligence (AGI) might pose an existential threat, or those looking to have the case laid out more clearly “from first principles” (without taking any previous claims for granted).
It’s helpful if you have a vague idea of modern machine learning (what’s a neural net? What is reinforcement learning?), but you can probably get by just from considering some of the examples.
What are Ngo’s Core Claims?
Ngo’s argument stands on 4 key premises, stated below in his words:
Essentially, if all 4 premises hold, the conclusion is, “the development of superintelligent AGI will occur and poses an existential threat to humanity” (and provided you’re concerned about existential risks to humanity, this is important).
I think Ngo’s 4 core claims can be viewed as analogous to pillars holding up a structure, the conclusion:
Why is this analogy useful? It leads to a couple nice ways of thinking about the problem:
For each of the 4 sections, I’ll also introduce some of the context and definitions that Ngo uses: the “below-the-pillar” terminology. Below-the-pillar ideas aren’t truth-claims, but more like ways of thinking about the truth-claims provided with each pillar. Below-the-pillar ideas and concepts may change depending on who you’re talking with, but in this post I try to use those that Ngo establishes in his sequence.
Pillar (Premise) 1: We’ll build AIs which are much more intelligent than humans
Here’s a zoomed-in look at the claims that support pillar 1:
Below the pillar:
One of the first points of discussion that comes up when people try to discuss artificial general intelligence is what it means for something to be intelligent in the first place. Ngo starts with the definition provided by Legg, where intelligence is “the ability to do well on a wide range of cognitive tasks”.
Additionally, when it comes to training intelligent AI, there’s a difference between two ways that you could do so: an AI could be task-specific (e.g. the AI is trained by only playing chess, and is good at chess) or general (e.g. the AI is trained on a wide variety of puzzles and games, not including chess, but then happens to be able to extrapolate and learn chess when deployed).
One assumption here is that it’s very likely for an advanced AI to be a general AI, rather than task-specific. Ngo lays out a more detailed case for why, but one great reason he mentions is considering our best example of highly intelligent creatures today, humans. We’re very general; our evolutionary training (in sub-saharan Africa) and deployment (modern life) are very different, yet we’re able to generalize and use our broad cognitive abilities (like learning quickly, motor processing, social skills) to excel in either situation.
The last core bit of context Ngo introduces is the difference between intelligence and agency. It’s important to note that in this section we’re only discussing intelligence, where “[intelligence is] the ability to understand how to perform a task, and [agency/autonomy is] the motivation to actually apply that ability to do well at the task.”
Working up the Pillar:
The most fundamental claim behind premise 1 is that it’s physically possible to build machines that are more intelligent than us. Ngo doesn’t delve into the complex debate around AI timelines and when superintelligence will be created, but his point is more that superintelligence can be created (and it’s pointed out that many researchers believe it will be before 2100).
The next claim in this stack of sub-arguments: similar to progress in AI in the past, we could expect things like increased computing speed, better algorithms, and improved training data to increase AI performance, eventually leading to human-level AI. But could this human-level AI turn into something superintelligent?
According to Ngo, once we reach human-level AI, 3 more factors (in addition to the previous 3) will help it improve to superhuman level fairly quickly. These are:
Top of the pillar
Pillar 1 lays out the case for why superhuman intelligence will likely arise using modern machine learning. But merely possessing superintelligence does not imply that an AI will be a threat to us. Will it want to take power from humans to use for its own purposes? If it wants and chooses to, its superior intelligence will certainly allow it to take power. But what does it mean for an AI to “want” something in the first place, and is it possible to know and control what AIs will want? This is explored in the next two pillars.
Pillar (Premise) 2: Those superintelligent AIs will be autonomous agents which pursue large-scale goals
Large goals and agentic AIs - Why care?
I think the point of this section/pillar needs some motivation. It’s not initially clear why we need to be concerned about “autonomous agents which pursue large-scale goals”. That sentence on its own doesn’t sound like a very big deal, until Ngo brings up the connection with Bostrom’s instrumental convergence thesis:
We’re concerned about “autonomous agents which pursue large-scale goals” because they will want to (and will be able to, if superintelligent) pursue power over humans as an instrumental goal (see Bostrom).
Ngo also briefly addresses ways a superintelligent AI might obtain power other than as an instrumental goal, but these aren’t discussed much and they haven’t been a focus of AI safety research in the past.
But why doesn’t Ngo frame this whole part of the sequence as “These AI’s will pursue power over humans” rather than “These AIs will be autonomous agents which pursue large-scale goals”? The former seems much more concerning and a cause for worry. The reason for using the latter is that it’s useful to introduce concepts of goals and agency into the discussion of AI alignment. Provided you agree with Bostrom’s instrumental convergence thesis (and this is a hidden assumption not included in the Pillar 2 diagram), then the “AI’s will pursue power over humans” conclusion is a given (if the AIs are autonomous and pursuing large-scale goals). So the question of whether AIs will be willing and able to take power from humans can be broken down into two parts:
A quick explanation of goals and autonomy, below:
Below the Pillar
In describing an AI’s goal, we’re trying to explain what it means for an AI to “want” to achieve that goal. Ngo uses the idea of goals as generalized concepts, where goals are made up of the concepts an AI possesses. A concept could be an idea about the physical world or the agent’s training environment (e.g. “things that are perfectly round are objects called spheres; 6-sided boxes are objects called cubes”), it could be a deontological rule (e.g. “I should never touch spheres”), or they could refer to thought processes (e.g. “what's the best way to avoid spheres?”).
The other important aspect of this section is autonomy/agency. Ngo thinks of autonomy by describing it in terms of 6 traits that we’d expect autonomous agents to have:
Working up the pillar
The structure of this pillar is less certain. I think the two middle points could be swapped, as they both contribute equally to the idea that superintelligent AIs will be autonomous and pursue large-scale goals. That being said, let’s start with the bottom point as depicted:
Ngo lays out the idea that concepts can generalize from the training environment to the real world (deployment); as a result, the goals made up of those concepts similarly generalize. Consider our above AI that’s been trained in a shape-filled environment. Depending how you train it, it might somehow learn the goal “gather cubes” in its artificial environment. In deployment (the real world), however, nothing perfectly fits the description of “cube” that it knows. If the AI’s idea of “cube” could be generalized to a real-world concept (e.g. something like “non-round objects”), then the AI’s goals could be generalized to some goal in the real world “gather non-round objects” or maybe even more generally “gather resources”. In other words, small-scale goals learned in training can generalize to become large-scale goals (like gathering resources or obtaining power, for example), depending on how the AI’s concepts generalize.
Secondly, Ngo points out that general AI will likely have more autonomous qualities than task-specific AI (using the 6 terms used to define autonomy). We don’t know exactly what training processes will produce AGI, but we should expect economic pressures to push researchers to prioritize making the most agentic AI (since agentic AI will be the most general and thus most useful).
Top of the pillar
In conclusion, the ideas in pillar 2 give us reason to believe that advanced AI will be both agentic and will seek large-scale goals. This is a cause for worry, as it will lead to the AI to pursue power over humans (from the instrumental convergence thesis). However, it isn’t always bad for an AI to take power from humans; if the AI is doing what we want it to do, it would be a good thing to have the superintelligence to use its power for our purposes. The issue arises when AI acquires power to use for its own misaligned goals, which we discuss next.
Pillar (Premise) 3: The AI’s goals will be misaligned with ours; that is, they will aim towards outcomes that aren’t desirable by our standards
This pillar is a “thick” pillar. There are two independent components that make up the problem of misalignment: inner and outer misalignment. Even if one gets solved, the other is still a concern if left unaddressed.
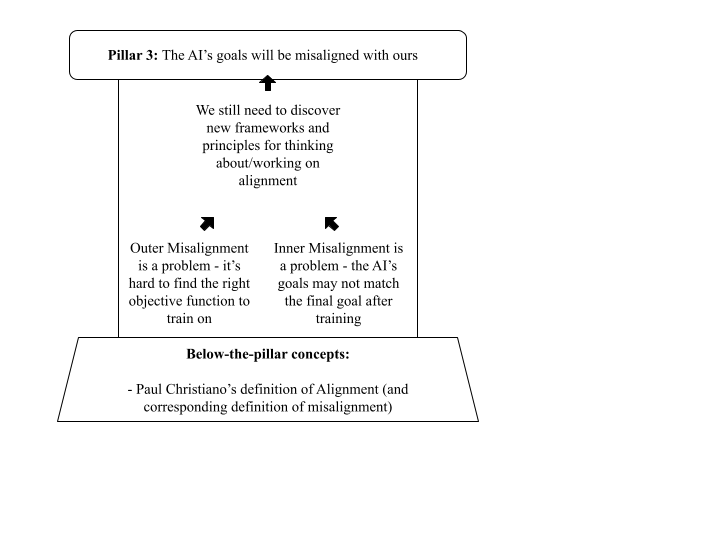
Below the Pillar
The needed context for discussing misalignment is, well, what it means for an AI to be misaligned in the first place. Ngo uses Paul Christiano’s definition of alignment, and turns it on it’s head to get a nice concise definition of misalignment:
“An AI, A, is said to be misaligned with a human, H, if H would want A not to do what A is trying to do”.
Working up the Pillar
Outer alignment: Say you want to get an AI to do X, by optimizing with respect to some objective function. The problem of outer alignment is figuring out what objective function to use (e.g. which specific reward function, in reinforcement learning) which encourages an AI to do X without also acting in ways we don’t want.
Here’s an example I’ve heard mentioned a few times. Note that this is not originally mine; I remember it from somewhere but unfortunately couldn’t find the original source (if you know, please tell so they can get credit). Say you want to get rich, and you try to train your AI with an objective function that encodes a goal along the lines of “maximize the number of dollars in my bank account”. It’s possible for your AI to learn to “make money” by hacking your bank and switching the $0 in your account to a $9999999999999. This clearly isn’t the goal you intended (you want real money, not a lawsuit from your bank!), but the AI still satisfied the objective function. Coming up with a good function that represents the idea of “maximize the money in my bank account without doing anything that humans would consider slimy” is a whole new can of worms. This is even harder when it comes to AGI; as Ngo says,
Inner Alignment: Say you want to get an AI to do task X. You train your AI on an objective function that maximizes X. However, while in training and learning to do X, the AI finds out that doing Y is a really helpful step towards X. As a result, your AI learns to want to do Y instead of wanting to do X. You deploy your AI, and it only tries to do Y, even though in the real world Y no longer makes X happen. X doesn’t happen, and you get sad because your AI was inner-misaligned. In other words, the AI learns to desire instrumental goals, rather than the final goals that you specify in the objective function. For more clarification, there are some examples of this happening here, and this post also explains inner misalignment really well from a simple perspective.
New frameworks and principles: Ngo points out that the solution of “alignment = outer alignment + inner alignment” can be simplistic and misleading. One key reason behind this point is that we still wouldn’t know what to do once we find the “safe” objective function (an objective function that somehow encodes all the behavior we’d expect from an aligned AI). The question still remains how we would train an AI to learn the goals specified by this objective function, and there are other tools at our disposal that we could use in the training process to create aligned AI (Ngo considers factors like neural architectures, [reinforcement learning] algorithms, environments, optimisers, etc). In other words, finding a good objective function to train on is only part of the picture towards aligning AI.
In addition to the objective function, Ngo explains that, in order to align agentic AGIs, we need to be able to more-precisely discuss what concepts and goals our agents have. Rather than relying on mathematical frameworks, Ngo suggests we’ll need principles and frameworks similar to those in cognitive science and evolutionary biology. To fit with the pillar structure analogy, this is saying that we’ll need better below-the-pillar concepts for pillar 2, regarding goals and agency. Working things out there will help us better view and address some currently-vague problems about alignment (Ngo mentions some here including gradient hacking and distinguishing motivation from reward signal vs reward function)
Top of the Pillar
In conclusion, Pillar 3 makes the case for why we shouldn’t expect AI to be aligned by default; it lays out the problems that need to be resolved in order to align AIs, and also points out that we still have incomplete frameworks for thinking about alignment. I’d like to mention one thing Ngo brings up near the end of this section, where he says it may be possible to “design training setups which create pressures towards agents which are still very intelligent and capable of carrying out complex tasks, but not very agentic - thereby preventing misalignment without solving either outer alignment or inner alignment”. In other words, preventing AI existential-risk by toppling pillar 2 may be possible, despite that most research so far has looked at addressing pillar 3.
Next we look at the problem in pillar 4: even if superintelligent AI is misaligned and agentic, will it have the means to gain control over humanity, or are there still things we can do to stop it?
Pillar (Premise) 4: The development of such AIs would lead to them gaining control of humanity’s future
Below the Pillar
Assuming an agentic, superintelligent, misaligned AI is created, “AI takeover” has been described to possibly happen in two main ways. Note there are other possibilities for AGI gaining control over humanity that aren’t mentioned here, but these two categories encompass most scenarios. These are detailed more in Ngo’s post or in the relevant authors’ writing.
Scenario 1: Paul Christiano’s scenario, as explained by Ngo:
These "strategically important tasks" might be things like political decision making/coordination, creating novel technologies, etc..
Scenario 2: Yudkowsky’s / Bostrom’s scenario, as explained by Ngo:
Working up the Pillar
The assumption at the bottom of this pillar is not typically contested: AGI will be software that can be copied and run on multiple computers, not bound to specific hardware (in contrast to how humans are bound to our physical bodies).
From there, the argument is fairly high-level, and this lack of specificity makes it a little more difficult to discuss whether it's true or not (we get to this later though). The claim: AGI can attain power over humans by developing novel technologies and coordinating better than humans. In either case, doing so would lead to one of the two previously-described disaster scenarios.
Following this, the autonomous misaligned AGI will be able to use its power to accomplish its own goals, regardless of the desires of the human population.
Crumbling or Stabilizing Pillar 4
Ngo points out that the high-level nature of his argument in the middle of the pillar (that AGI will be able to acquire more power over humans) makes it hard to refute. To give interlocutors something more tangible to discuss, he considers 4 factors that affect the possibility of AGI obtaining power. Adding to the pillar analogy, each of these factors will either strengthen the pillar (causing the control problem to be more difficult and thus more of a concern) or weaken it (making the control problem easier to address/solve). They're detailed below, along with the ways that some might affect the others.
Top of the Pillar
Provided these 4 methods of control fail (humanity is unable to coordinate, takeoff speeds are too fast to do anything about, AI is sufficiently intransparent, and the AGI doesn't get deployed in a constrained way), it seems very likely that this AGI will be able to acquire power over humans. And even if some of these control methods do occur and work, it does not guarantee that the AGI won't still secure power. Again, this takeover would probably occur in the form of one of the two previously mentioned disaster scenarios; from there, humanity would have little to no control over its future trajectory.
Conclusion - Figure out what you think about this structure
Referring back to each pillar, we have 4 core claims leading up to the idea that superintelligent AI will pose an existential risk.
Ngo ties this back to a form of Stuart Russel’s “gorilla problem”; if we end up creating AIs that are much smarter than us which seek their own goals, we’ll only be the second-most powerful species in the world. Just as gorillas have their fate determined almost entirely by humans, we too could have our fate as a species almost entirely determined by misaligned artificial superintelligence.
Overall, Ngo’s sequence is a great introduction to the case for existential risk from AGI. My hope is that this post will help others to navigate it, and also help readers figure out their points of disagreement: where the 4-pillar structure is weak, which pillars you think are most tractable to knock down, and which below-the-pillar concepts you think should be changed in this discussion. I would’ve appreciated a similar framework when I started thinking about why I am or am not convinced by the risks posed by AI, and (though there are many holes in the analogy if you look too hard) I’d love to see more posts that lay out different individuals’ “landscape view”.
If you think I misrepresented Ngo’s sequence anywhere, please let me know so I can correct it. Thanks for reading, and a big thank you to all those who provided feedback on this!
Ngo points out in the conclusion of his sequence that there are some cases where transformative AGI will pose an existential threat, even if we address the problem of misaligned AGI detailed in the 4-pillar structure. I don't mention those cases in this post, but they could be considered as their own separate structure. Read more here.