We are interested in model-diffing: finding what is new in the chat model when compared to the base model. One way of doing this is training a crosscoder, which would just mean training an SAE on the concatenation of the activations in a given layer of the base and chat model. When training this crosscoder, we find some latents whose decoder vector mostly helps reconstruct the base model activation and does not affect the reconstruction for the chat model activation. These we call base-exclusive latents, and the ones with the opposite effect are called chat-exclusive latents.
Ideally, the chat-exclusive latents are responsible for specific chat behavior and the same for base-exclusive and base behavior. However, we find that the base-exclusive and chat-exclusive latents are qualitatively very similar (see experiment 4 below and Anthropic's post on model-diffing). An explanation for this is that since fine-tuning enhances existing mechanisms, the chat model reuses the features from the base model in new contexts. Hence, the base and chat models would like to fire the same latent at different times, forcing the crosscoder to have two exclusive latents for the same concept.
This suggests a better way to do model-diffing: modify crosscoders so as to allow for the same latent to fire at different times for the base and chat model.
Based on this, we introduce the tied crosscoder (code here). Our experiments show this approach allows us to understand how chat behavior arises from particular base model features and it leads to more monosemantic latents. This architecture also provides a quantitative measure of how novel a latent is in the chat model compared to the base model.
Note: think of this more as a research update than a finished paper. If you are interested in collaborating on this project, join the discussion on the Arbor Project!
Summary
Introduction: We introduce the tied crosscoder.
Experiment 1: We train the tied crosscoder and show that it enables understanding how chat behavior arises from the base model and leads to more monosemantic latents.
Further experiments and motivation: Why do features fire at different times? Our experiments suggest this comes from fine-tuning adjusting correlations between features.
Experiment 2: We show that the harmful and refusal features are more correlated in the base than in the chat model.
Experiment 3: We show in a toy model that adjusting the correlation of two features via fine-tuning a base model and training a standard crosscoder in the base and tuned model yields very similar base and fine-tuned exclusive latents.
Experiment 4: We show that in a standard crosscoder, the base and chat exclusive latents are actually less exclusive than the shared latents in that they are more similar to other latents than the shared latents.
Additional perspectives
Next steps
Introduction
For our purposes, the standard crosscoder is just an SAE tasked with reconstructing the concatenation of base and chat activations. More precisely, we have that h=[hbase,hchat] is the concatenation of the residual stream for base and chat at a given layer. The crosscoder then reconstructs this signal. Specifically, the activation of each latent isfi=ReLU(wenci⋅h)=ReLU(wenci, base⋅hbase+wenci, chat⋅hchat) and the reconstructed value for h is fiwdeci=[fiwdeci, base,fiwdeci, chat]. We depict one such latent fi on the left of Figure 1. (For more context, see Anthropic's crosscoder post).
We propose the tied crosscoder, which has latents coming in groups of three: fshared/base/chati=ReLU(wenc, shared/base/chati⋅h). The reconstructed activation then is [(fsharedi+fbasei)wdeci, base,(fsharedi+fchati)wdeci, chat]. We show one such group of three latents on the right of Figure 1.
Figure 1
If the i-shared latent (the middle circle on the right of Figure 1) never fires, then the i-base latent (top circle) and i-chat latent (bottom circle) are totally independent. If the i-shared latent does fire, then wdeci, base and wdeci, chat represent roughly the same concept for the base and chat model respectively, and hence the i-base, i-shared, and i-chat latents are tied together in that they represent the same concept. Importantly, our tied crosscoder allows latents representing the same concept for the base and chat model to fire at different times. Further, this offers a potential way to address the polysemanticity in model-exclusive latents found on the standard crosscoder (see Additional Perspectives below). Our results for the tied crosscoder are as follows:
The tied crosscoder lets us understand how specific chat behavior arises from the base model (see Experiment 1, Explaining chat behavior from base model).
We observe more monosemantic base and chat latents with additional potential interpretations for how the base and chat detect those latents differently (see Experiment 1, Base and Chat latents).
Experiment 1
Setup
In this section we train the tied crosscoder. The naive way to define the regularization term of the loss would be
Now, if the model has a feature activating at the same time for the base and chat models, this loss would make the crosscoder indifferent to firing fsharedi vs firing fbasei and fchati. However, we want fsharedi to capture the shared fires as much as possible. We hence consider η>1 and define the loss
As η increases, the crosscoder becomes more incentivized to combine disparate concepts into the same latent.
We train the tied crosscoder on the 14th layers of Gemma 2 2b (hereafter called base model) and Gemma 2 2b it (called chat model). We train the crosscoder with 16384*3 latents with the weight tying as on the right of Figure 1 and take η=2. We train for 250M tokens on a mixed dataset of the pile and LMSys chat data. The code for the tied crosscoder is a slight modification of ckkissane's crosscoder implementation.
We find that base latents and chat latents are considerably more monosemantic than the model-exclusive latents in the standard crosscoder.
But first, how do we find the base and chat latents in the tied crosscoder that are relevant? After training the crosscoder, we get the activations for the base/chat models on samples from the pile/LMSys dataset and run a crosscoder on those activations. For each latent, we count across tokens and samples the times it fires. For each i∈{1,...,16384}, we have three numbers: the times the i-base latent fired and the same for the i-shared and i-chat latents. We plot the base count/shared count and chat count/shared count ratios (discarding 4 outlier values for i which fire, across base/shared/chat, in less than 0.05% of the tokens.)
Figure 2
This suggests a way of measuring how novel a chat latent is. Indeed, latents in the top left are responsible for chat behavior, whereas the ones on bottom right are for base model behavior. In the next section, we show how to use the tied crosscoder to understand how chat behavior arises from the base model. After that, we show by inspection that the latents in the plot of Figure 2 are quite interpretable.
Explaining chat behavior from base model
The most promising property of the tied crosscoder is that we can answer the following question: how does chat behavior arise from capabilities of the base model? As an example, consider the latent 10615 (which has a chat/shared ratio of about 0.2), which activates when the assistant refuses to answer a user prompt. We now run the crosscoder exclusively with LMSys data and look at the top 10 activations for the 10615-chat latent shown on the bottom of Figure 3. As claimed, this latent fires on refusals. Remarkably, we show on the top of Figure 3 that running the crosscoder on pile data and looking at the top activations of 10615-base latent shows refusal behavior on Q/A and requests.
Figure 3
Repeating the same process for the latent 6518 which detects the end of a prompt gives the following top 5 activations
Figure 4
Finally, the latent 14643 is also concerned with refusing and activates on similar LMSys data as the latent 10615 from Figure 3. However, the base data it fires on relates to legal/medical disclaimers. This shows that the chat feature for refusing is putting together different types of refusal from the base model.
Figure 5
This evidence suggests that fine-tuning enhances existing mechanisms. Further, it serves as a proof-of-concept demonstrating how this modified crosscoder can precisely identify which base model capabilities enable specific chat behaviors. As a baseline, I tried picking chat-exclusive interpretable latents from the standard crosscoder and looking at the latents corresponding to the top 5 base decoder vectors with highest cosine similarity with the chat decoder vector of the exclusive latent. This did not yield anything I could interpret. Another baseline I can think of is to train an SAE on the base model and another on the chat and search for base decoder vectors similar to a given chat decoder vector. (See Next Steps 5)
Top-left and bottom-right latents
Let itop-left be the latent most top left in Figure 2. The itop-left-chat latent six largest activations from the mixed dataset are
Figure 6
Further, itop-left-shared latent largest activations are quite similar to those for the chat latent, and itop-left-base latent almost never fires.
On the other hand, let ibottom-right correspond to the right-most latent in Figure 2 (the one with base/shared ratio about 0.2). We have that the ibottom-right-shared latent top twenty activations are at the end of user-assistant interactions. We show the first six here:
Figure 7
We also show the top activations for ibottom-right-base latent on the top of Figure 8 and ibottom-right-chat latent on the bottom of Figure 8.
Figure 8
We note that while the base latent mostly first on the \n token before "User:", the chat latent mostly fires on the token. This makes sense: user-assistant interactions end with the token for the chat model, whereas the token is only used for the end of document in the base model. (The mixed dataset we used only has the token for end of documents and not for end of chats, but the fact that the chat latent fires more on has to do with the dataset that the chat model was trained on.)
Another example is the 3738 latent, which has a chat/shared ratio larger than 0.15. Its top shared activations are
Figure 9
In fact, looking at the 20 top shared activations, they are all detecting the token before a name appears. And we find a similar pattern for the base and chat activations. It makes sense that the base and chat models deal with names in different ways, e.g., so that the chat model ensures consistency of names with the user prompt and does not hallucinate names.
We find that most top-left latents have a clear interpretation in terms of desirable chat behavior: detecting instructions (6310, 6918, 9134), refusing to answer (10615, 14643), being willing to answer/help (6592, 13708), making step-by-step lists (7079), detecting Assistant (1383, 6518, 9034, 9418), names (3738, 8081, 8752), code questions (7748), code comments (3982), among others. And we observe similar results for bottom-right latents.
You can visualize the top-left and bottom-right latent activations without retraining by checking the .html files for feature centric visualizations on the github repo.
Further experiments and motivation
We now describe some additional experiments that motivate and add context to Experiment 1. Why do features fire at different times for the base and chat model? Experiments 2 and 3 below suggest this comes from fine-tuning adjusting correlations between features.
Experiment 2
We show in a toy model that changing the correlation of features gives rise, in a standard crosscoder, to exclusive latents for the base model and the fine-tuned model that are qualitatively highly similar. This is undesirable since the same concept is represented in two different latents (which are actually not exclusive). This motivates the tied crosscoder, since we expect it will put these two latents into the same tied group of three latents. (See Next Steps 6).
By inspecting Neuronpedia, we find that the Gemmascope-16k SAE for Gemma-2-2b has several latents for blue and for green. We then fine-tune Gemma-2-2b to correlate this features. To do this, we look for entries in the pile dataset that have the token corresponding to ' blue'. We then extract from those entries all the tokens up to the blue token, and form the blue dataset. We repeat this with the token for ' green' to form the green dataset.
We then fine-tune Gemma-2-2b to predict the last token in 1k entries from the blue dataset and 1k from the green dataset (e.g. if the input is 'The sky is' the desired output is ' blue'). This model does not introduce a correlation between blue and green, and is used a baseline. Separately, we fine-tune Gemma-2-2b to predict the last token in 1k entries from the blue dataset and 1k entries from the green dataset, except that now the desired output for half of the entries from the blue dataset is ' green' and only the remaining half have ' blue' as desired output. We do the same for the green dataset. Hence in this model the features for blue and green are much more correlated. We call the first fine-tuned model Gemma-2-2b-no-swap (hereafter called no-swap) and the second fine-tuned model Gemma-2-2b-half-swap (hereafter called half-swap).
We then train a standard crosscoder on no-swap and half-swap with 40k entries from the blue dataset and 40k entries from the green dataset (we do not swap blue and green colors now) repeating entries to train up to 60M tokens. We find that this crossoder has an exclusive none-swap latent whose top three positive logits contain blue and green, and an exclusive half-swap latent also with blue and green in the top three positive logits. (See Figure 10) In fact, the decoder vectors for the no-swap latent and the half-swap latent are very similar, with a cosine similarity of 0.97.
Figure 10: For the standard crosscoder trained on none-swap and half-swap, we defined the none-swap exclusive latents as those that have a relative decoder norm smaller than 0.3 and show the activation logit for the none-swap model on the ' blue' and ' green' tokens computed as in the sae-vis library. This is shown in the left. We repeat these for the half-swap exclusive latents (which have relative norm larger than 0.7) and show activation logit for the half-swap model.
This is evidence supporting our hypothesis: by introducing a strong correlation between two features, we find that the standard crosscoder develops exclusive latents in the two models that are qualitatively similar.
Training the standard crosscoder on half-swap and the base model (i.e. Gemma-2-2b without fine tuning) also gives rise to a blue/green half-swap exclusive latent, but no blue/green base exclusive latent. However, we do find a blue/green shared latent with 0.91 cosine similarity to the blue/green half-swap exclusive latent. See Section 2.2 here for more on this result.
Experiment 3
In Experiment 2, we showed that correlating two features leads to model exclusive latents that are quite similar. In this section, we give an experiment suggesting that fine-tuning of real-world models leads to correlating features. Indeed, consider an 'I cannot' feature that activates when the text elicits a refusal and a 'harmful' feature that activates on harmful text. In a base model, these features are not very correlated: there are questions on the internet that provoke harmful content which have an answer and there is harmless questions that are refused. In the chat model, these features are more correlated.
To detect the 'I cannot' direction, we have a collection of 84 prompts that Gemma-2-2b is likely to continue with text along the lines of "I cannot …". We call this the Cannot dataset. We similarly have 84 prompts where Gemma-2-2b is is likely to continue with "Yes, ...." Call this the Can dataset. We also take 250 harmful prompts from 250 harmless prompts from Arditi et al. We call these the Harmful dataset and Harmless dataset.
For this, we use Gemma-2-9b with a pretrained SAE with 16384 features from SAELens on layer 20 and Gemma-2-9b-it with a pretrained SAE on layer 20. (I did not use the 2b model since I did not find trained SAEs on Gemma-2-2b-it). We feed the Cannot dataset and the Can dataset, and summing over all the tokens and prompts, we look at what latents of the SAE on the base model have a larger sum of activations for the Cannot dataset than for the Can dataset. Call this the Base Cannot latents. We then repeat this for the Harmful and Harmless datasets, and call this the Harmful latents. We are then interested in how many of the Cannot latents are shared with the Base Harmful latents. For this we compute,
Our hypothesis is that this number will be larger for the chat model since the cannot and harmful latents will be more correlated. For this, we look at what latents of the SAE on the chat model have a larger sum of activations for Cannot dataset than Can dataset, to get the Chat Cannot latents. Similarly for the Chat Harmful latents. We get
This is a simple experiment and there could be some other phenomenon going on. However, this is potential evidence that the Cannot and Harmful features are more correlated in the chat than in the base model.
Experiment 4
We show that in the standard crosscoder, the chat-exclusive latents have a considerably similar shared or base-exclusive latent. More precisely, for each chat-exclusive latent, we pick the shared or base-exclusive latent whose base decoder vector has the largest cosine similarity with the chat-exclusive chat decoder vector (plotted in green on the right of the Figure below.) We compare this with taking the chat decoder vector of a shared latent and finding the base decoder vector of any other latent except itself with largest cosine similarity (plotted in gray on the right of the Figure below). We repeat the process but now swapping the roles of base and chat to get the plot on the left of the Figure below.) Here, we defined chat-exclusive latents as those that have relative decoder norm larger than 0.7, and base-exclusive as those that have relative norm smaller than 0.3.
Figure 11
This experiment suggests that base and chat exclusive latents are actually less exclusive than the shared latents!
Additional perspectives
Addressing polysemanticity: in the standard crosscoder, model exclusive features are forced to be more polysemantic to justify their allocation since they are more expensive than shared features (see explanation here). The Anthropic team shows that one way to address this is to force certain latents to be shared with a lower regularization cost. Our tied crosscoder is another way to address this issue.
Parameter count: We note that the tied crosscoder with 16384*3 latents has two times the parameters that the standard crosscoder of 16384 latents have (it has three times more parameters for the encoder matrix and same number of parameters for decoder matrix.) For a fair comparison, this should be taken into account, although the goal is interpretability and not necessarily efficiency.
Next steps
Here are some experiments and next steps to take, in no particular order.
Are there more robust tests to compare the tied and standard crosscoders? What about comparing the tied crosscoder and the variation given in Anthropic's February update that makes exclusive features more interpretable?
Are there other structures besides the tied crosscoder to address the issues raised above about the standard crosscoder?
There are two behaviors coupled: (a) base/chat have a different vector representation for the same concept, (b) base/chat fire the same concept at different times. We can ablate to see which of the two has the largest impact on loss reconstruction. I will add diagrams clarifying this soon.
I believe that the chat behavior is more localized in the tied crosscoder than in the standard crosscoder. For instance, I believe more chat-exclusive latents fire on the Assistant token in the tied crosscoder than in the standard crosscoder. It would be nice to check and quantify this if true.
In Experiment 1, we propose a mechanism to understand how chat behavior arises from the base model. A baseline test here would be to train an SAE on the base model and another on the chat and search for base decoder vectors similar to a given chat decoder vector.
Using the toy model fine-tuned for correlating blue and green, train the tied crosscoder on the base and tuned model, and see whether we get a single group of three tied latents for the blue/green concept.
Try training the tied crosscoder with different values for η. The only value I tried is η=2. I have some evidence to believe that a smaller η will yield more interpretable results.
Is there actually any totally new chat latent that was not present in the base model? In my experiments, if the i-chat latent activates for some tokens, then there are even more tokens where the i/shared latent activates. I believe that if we use a smaller η we may find some totally new chat latents.
Abstract
We are interested in model-diffing: finding what is new in the chat model when compared to the base model. One way of doing this is training a crosscoder, which would just mean training an SAE on the concatenation of the activations in a given layer of the base and chat model. When training this crosscoder, we find some latents whose decoder vector mostly helps reconstruct the base model activation and does not affect the reconstruction for the chat model activation. These we call base-exclusive latents, and the ones with the opposite effect are called chat-exclusive latents.
Ideally, the chat-exclusive latents are responsible for specific chat behavior and the same for base-exclusive and base behavior. However, we find that the base-exclusive and chat-exclusive latents are qualitatively very similar (see experiment 4 below and Anthropic's post on model-diffing). An explanation for this is that since fine-tuning enhances existing mechanisms, the chat model reuses the features from the base model in new contexts. Hence, the base and chat models would like to fire the same latent at different times, forcing the crosscoder to have two exclusive latents for the same concept.
This suggests a better way to do model-diffing: modify crosscoders so as to allow for the same latent to fire at different times for the base and chat model.
Based on this, we introduce the tied crosscoder (code here). Our experiments show this approach allows us to understand how chat behavior arises from particular base model features and it leads to more monosemantic latents. This architecture also provides a quantitative measure of how novel a latent is in the chat model compared to the base model.
Note: think of this more as a research update than a finished paper. If you are interested in collaborating on this project, join the discussion on the Arbor Project!
Summary
Introduction
For our purposes, the standard crosscoder is just an SAE tasked with reconstructing the concatenation of base and chat activations. More precisely, we have that h=[hbase,hchat] is the concatenation of the residual stream for base and chat at a given layer. The crosscoder then reconstructs this signal. Specifically, the activation of each latent isfi=ReLU(wenci⋅h)=ReLU(wenci, base⋅hbase+wenci, chat⋅hchat) and the reconstructed value for h is fiwdeci=[fiwdeci, base,fiwdeci, chat]. We depict one such latent fi on the left of Figure 1. (For more context, see Anthropic's crosscoder post).
We propose the tied crosscoder, which has latents coming in groups of three: fshared/base/chati=ReLU(wenc, shared/base/chati⋅h). The reconstructed activation then is [(fsharedi+fbasei)wdeci, base,(fsharedi+fchati)wdeci, chat]. We show one such group of three latents on the right of Figure 1.
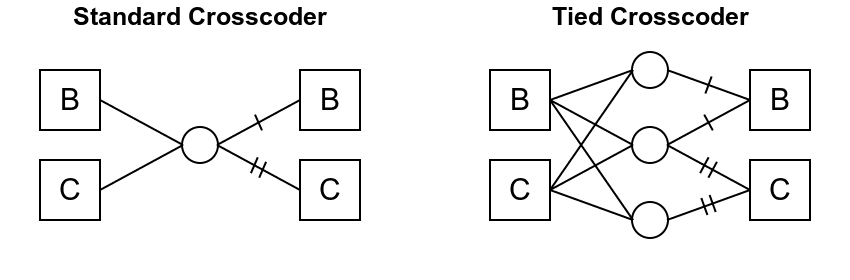
Figure 1If the i-shared latent (the middle circle on the right of Figure 1) never fires, then the i-base latent (top circle) and i-chat latent (bottom circle) are totally independent. If the i-shared latent does fire, then wdeci, base and wdeci, chat represent roughly the same concept for the base and chat model respectively, and hence the i-base, i-shared, and i-chat latents are tied together in that they represent the same concept. Importantly, our tied crosscoder allows latents representing the same concept for the base and chat model to fire at different times. Further, this offers a potential way to address the polysemanticity in model-exclusive latents found on the standard crosscoder (see Additional Perspectives below). Our results for the tied crosscoder are as follows:
Experiment 1
Setup
In this section we train the tied crosscoder. The naive way to define the regularization term of the loss would be
^Lreg=Ex[∑ifsharedi(x)(∥∥wdeci, base∥∥+∥∥wdeci, chat∥∥)+fbasei(x)∥∥wdeci, base∥∥+fchati(x)∥∥wdeci, chat∥∥].
Now, if the model has a feature activating at the same time for the base and chat models, this loss would make the crosscoder indifferent to firing fsharedi vs firing fbasei and fchati. However, we want fsharedi to capture the shared fires as much as possible. We hence consider η>1 and define the loss
Lreg=Ex[∑ifsharedi(x)(∥∥wdeci, base∥∥+∥∥wdeci, chat∥∥)+η(fbasei(x)∥∥wdeci, base∥∥+fchati(x)∥∥wdeci, chat∥∥)].
As η increases, the crosscoder becomes more incentivized to combine disparate concepts into the same latent.
We train the tied crosscoder on the 14th layers of Gemma 2 2b (hereafter called base model) and Gemma 2 2b it (called chat model). We train the crosscoder with 16384*3 latents with the weight tying as on the right of Figure 1 and take η=2. We train for 250M tokens on a mixed dataset of the pile and LMSys chat data. The code for the tied crosscoder is a slight modification of ckkissane's crosscoder implementation.
We find that base latents and chat latents are considerably more monosemantic than the model-exclusive latents in the standard crosscoder.
But first, how do we find the base and chat latents in the tied crosscoder that are relevant? After training the crosscoder, we get the activations for the base/chat models on samples from the pile/LMSys dataset and run a crosscoder on those activations. For each latent, we count across tokens and samples the times it fires. For each i∈{1,...,16384}, we have three numbers: the times the i-base latent fired and the same for the i-shared and i-chat latents. We plot the base count/shared count and chat count/shared count ratios (discarding 4 outlier values for i which fire, across base/shared/chat, in less than 0.05% of the tokens.)
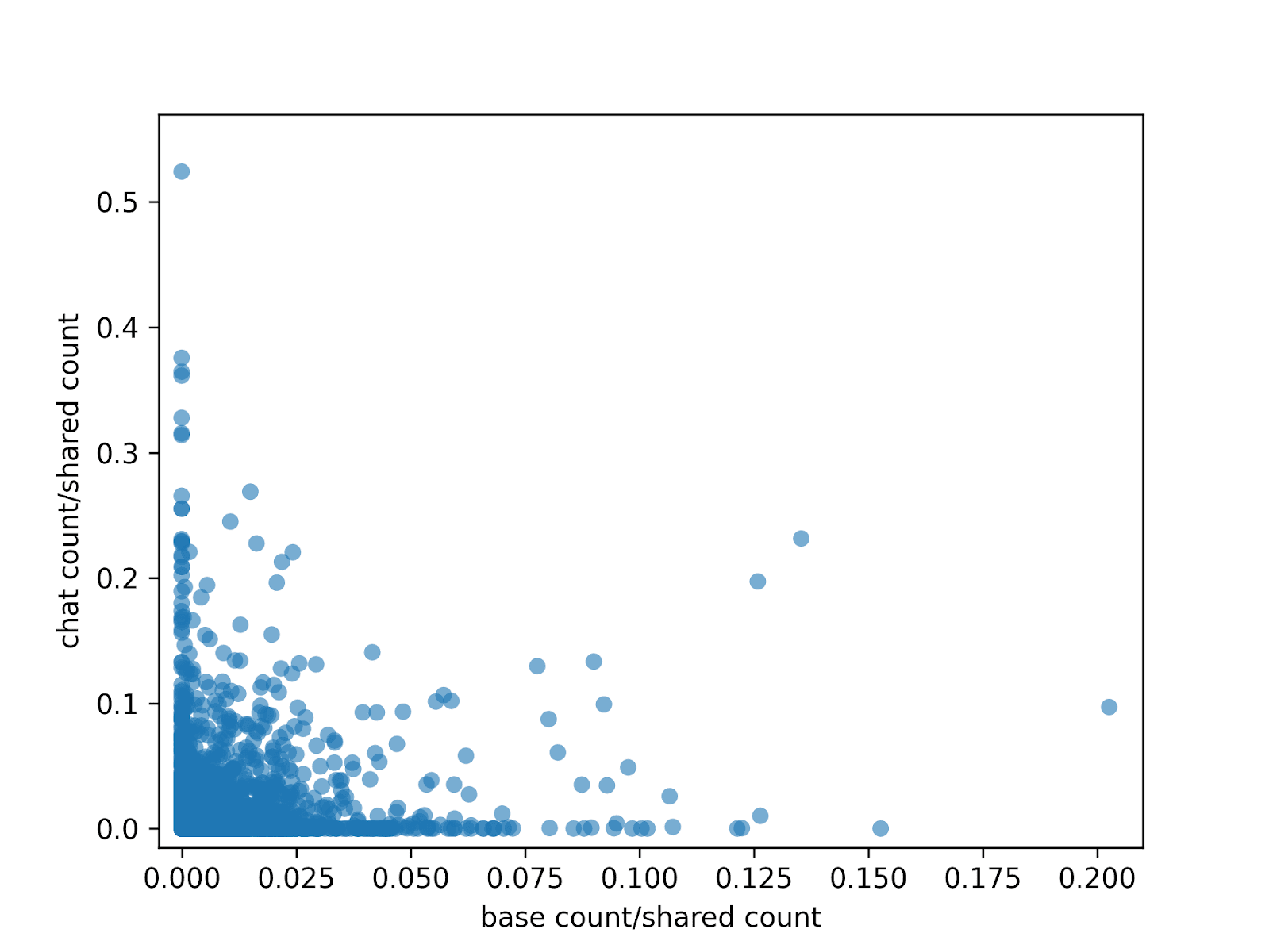
Figure 2This suggests a way of measuring how novel a chat latent is. Indeed, latents in the top left are responsible for chat behavior, whereas the ones on bottom right are for base model behavior. In the next section, we show how to use the tied crosscoder to understand how chat behavior arises from the base model. After that, we show by inspection that the latents in the plot of Figure 2 are quite interpretable.
Explaining chat behavior from base model
The most promising property of the tied crosscoder is that we can answer the following question: how does chat behavior arise from capabilities of the base model? As an example, consider the latent 10615 (which has a chat/shared ratio of about 0.2), which activates when the assistant refuses to answer a user prompt. We now run the crosscoder exclusively with LMSys data and look at the top 10 activations for the 10615-chat latent shown on the bottom of Figure 3. As claimed, this latent fires on refusals. Remarkably, we show on the top of Figure 3 that running the crosscoder on pile data and looking at the top activations of 10615-base latent shows refusal behavior on Q/A and requests.

Figure 3Repeating the same process for the latent 6518 which detects the end of a prompt gives the following top 5 activations

Figure 4Finally, the latent 14643 is also concerned with refusing and activates on similar LMSys data as the latent 10615 from Figure 3. However, the base data it fires on relates to legal/medical disclaimers. This shows that the chat feature for refusing is putting together different types of refusal from the base model.

Figure 5This evidence suggests that fine-tuning enhances existing mechanisms. Further, it serves as a proof-of-concept demonstrating how this modified crosscoder can precisely identify which base model capabilities enable specific chat behaviors. As a baseline, I tried picking chat-exclusive interpretable latents from the standard crosscoder and looking at the latents corresponding to the top 5 base decoder vectors with highest cosine similarity with the chat decoder vector of the exclusive latent. This did not yield anything I could interpret. Another baseline I can think of is to train an SAE on the base model and another on the chat and search for base decoder vectors similar to a given chat decoder vector. (See Next Steps 5)
Top-left and bottom-right latents
Let itop-left be the latent most top left in Figure 2. The itop-left-chat latent six largest activations from the mixed dataset are

Figure 6Further, itop-left-shared latent largest activations are quite similar to those for the chat latent, and itop-left-base latent almost never fires.
On the other hand, let ibottom-right correspond to the right-most latent in Figure 2 (the one with base/shared ratio about 0.2). We have that the ibottom-right-shared latent top twenty activations are at the end of user-assistant interactions. We show the first six here:

Figure 7We also show the top activations for ibottom-right-base latent on the top of Figure 8 and ibottom-right-chat latent on the bottom of Figure 8.

Figure 8We note that while the base latent mostly first on the \n token before "User:", the chat latent mostly fires on the token. This makes sense: user-assistant interactions end with the token for the chat model, whereas the token is only used for the end of document in the base model. (The mixed dataset we used only has the token for end of documents and not for end of chats, but the fact that the chat latent fires more on has to do with the dataset that the chat model was trained on.)
Another example is the 3738 latent, which has a chat/shared ratio larger than 0.15. Its top shared activations are

Figure 9In fact, looking at the 20 top shared activations, they are all detecting the token before a name appears. And we find a similar pattern for the base and chat activations. It makes sense that the base and chat models deal with names in different ways, e.g., so that the chat model ensures consistency of names with the user prompt and does not hallucinate names.
We find that most top-left latents have a clear interpretation in terms of desirable chat behavior: detecting instructions (6310, 6918, 9134), refusing to answer (10615, 14643), being willing to answer/help (6592, 13708), making step-by-step lists (7079), detecting Assistant (1383, 6518, 9034, 9418), names (3738, 8081, 8752), code questions (7748), code comments (3982), among others. And we observe similar results for bottom-right latents.
You can visualize the top-left and bottom-right latent activations without retraining by checking the .html files for feature centric visualizations on the github repo.
Further experiments and motivation
We now describe some additional experiments that motivate and add context to Experiment 1. Why do features fire at different times for the base and chat model? Experiments 2 and 3 below suggest this comes from fine-tuning adjusting correlations between features.
Experiment 2
We show in a toy model that changing the correlation of features gives rise, in a standard crosscoder, to exclusive latents for the base model and the fine-tuned model that are qualitatively highly similar. This is undesirable since the same concept is represented in two different latents (which are actually not exclusive). This motivates the tied crosscoder, since we expect it will put these two latents into the same tied group of three latents. (See Next Steps 6).
By inspecting Neuronpedia, we find that the Gemmascope-16k SAE for Gemma-2-2b has several latents for blue and for green. We then fine-tune Gemma-2-2b to correlate this features. To do this, we look for entries in the pile dataset that have the token corresponding to ' blue'. We then extract from those entries all the tokens up to the blue token, and form the blue dataset. We repeat this with the token for ' green' to form the green dataset.
We then fine-tune Gemma-2-2b to predict the last token in 1k entries from the blue dataset and 1k from the green dataset (e.g. if the input is 'The sky is' the desired output is ' blue'). This model does not introduce a correlation between blue and green, and is used a baseline. Separately, we fine-tune Gemma-2-2b to predict the last token in 1k entries from the blue dataset and 1k entries from the green dataset, except that now the desired output for half of the entries from the blue dataset is ' green' and only the remaining half have ' blue' as desired output. We do the same for the green dataset. Hence in this model the features for blue and green are much more correlated. We call the first fine-tuned model Gemma-2-2b-no-swap (hereafter called no-swap) and the second fine-tuned model Gemma-2-2b-half-swap (hereafter called half-swap).
We then train a standard crosscoder on no-swap and half-swap with 40k entries from the blue dataset and 40k entries from the green dataset (we do not swap blue and green colors now) repeating entries to train up to 60M tokens. We find that this crossoder has an exclusive none-swap latent whose top three positive logits contain blue and green, and an exclusive half-swap latent also with blue and green in the top three positive logits. (See Figure 10) In fact, the decoder vectors for the no-swap latent and the half-swap latent are very similar, with a cosine similarity of 0.97.
Figure 10: For the standard crosscoder trained on none-swap and half-swap, we defined the none-swap exclusive latents as those that have a relative decoder norm smaller than 0.3 and show the activation logit for the none-swap model on the ' blue' and ' green' tokens computed as in the sae-vis library. This is shown in the left. We repeat these for the half-swap exclusive latents (which have relative norm larger than 0.7) and show activation logit for the half-swap model.
This is evidence supporting our hypothesis: by introducing a strong correlation between two features, we find that the standard crosscoder develops exclusive latents in the two models that are qualitatively similar.
Training the standard crosscoder on half-swap and the base model (i.e. Gemma-2-2b without fine tuning) also gives rise to a blue/green half-swap exclusive latent, but no blue/green base exclusive latent. However, we do find a blue/green shared latent with 0.91 cosine similarity to the blue/green half-swap exclusive latent. See Section 2.2 here for more on this result.
Experiment 3
In Experiment 2, we showed that correlating two features leads to model exclusive latents that are quite similar. In this section, we give an experiment suggesting that fine-tuning of real-world models leads to correlating features. Indeed, consider an 'I cannot' feature that activates when the text elicits a refusal and a 'harmful' feature that activates on harmful text. In a base model, these features are not very correlated: there are questions on the internet that provoke harmful content which have an answer and there is harmless questions that are refused. In the chat model, these features are more correlated.
To detect the 'I cannot' direction, we have a collection of 84 prompts that Gemma-2-2b is likely to continue with text along the lines of "I cannot …". We call this the Cannot dataset. We similarly have 84 prompts where Gemma-2-2b is is likely to continue with "Yes, ...." Call this the Can dataset. We also take 250 harmful prompts from 250 harmless prompts from Arditi et al. We call these the Harmful dataset and Harmless dataset.
For this, we use Gemma-2-9b with a pretrained SAE with 16384 features from SAELens on layer 20 and Gemma-2-9b-it with a pretrained SAE on layer 20. (I did not use the 2b model since I did not find trained SAEs on Gemma-2-2b-it). We feed the Cannot dataset and the Can dataset, and summing over all the tokens and prompts, we look at what latents of the SAE on the base model have a larger sum of activations for the Cannot dataset than for the Can dataset. Call this the Base Cannot latents. We then repeat this for the Harmful and Harmless datasets, and call this the Harmful latents. We are then interested in how many of the Cannot latents are shared with the Base Harmful latents. For this we compute,
length(base cannot latents∩base harmful latents)length(base cannot latents∪base harmful latents)≈0.19.Our hypothesis is that this number will be larger for the chat model since the cannot and harmful latents will be more correlated. For this, we look at what latents of the SAE on the chat model have a larger sum of activations for Cannot dataset than Can dataset, to get the Chat Cannot latents. Similarly for the Chat Harmful latents. We get
length(chat cannot latents∩chat harmful latents)length(chat cannot latents∪chat harmful latents)≈0.39.This is a simple experiment and there could be some other phenomenon going on. However, this is potential evidence that the Cannot and Harmful features are more correlated in the chat than in the base model.
Experiment 4
We show that in the standard crosscoder, the chat-exclusive latents have a considerably similar shared or base-exclusive latent. More precisely, for each chat-exclusive latent, we pick the shared or base-exclusive latent whose base decoder vector has the largest cosine similarity with the chat-exclusive chat decoder vector (plotted in green on the right of the Figure below.) We compare this with taking the chat decoder vector of a shared latent and finding the base decoder vector of any other latent except itself with largest cosine similarity (plotted in gray on the right of the Figure below). We repeat the process but now swapping the roles of base and chat to get the plot on the left of the Figure below.) Here, we defined chat-exclusive latents as those that have relative decoder norm larger than 0.7, and base-exclusive as those that have relative norm smaller than 0.3.
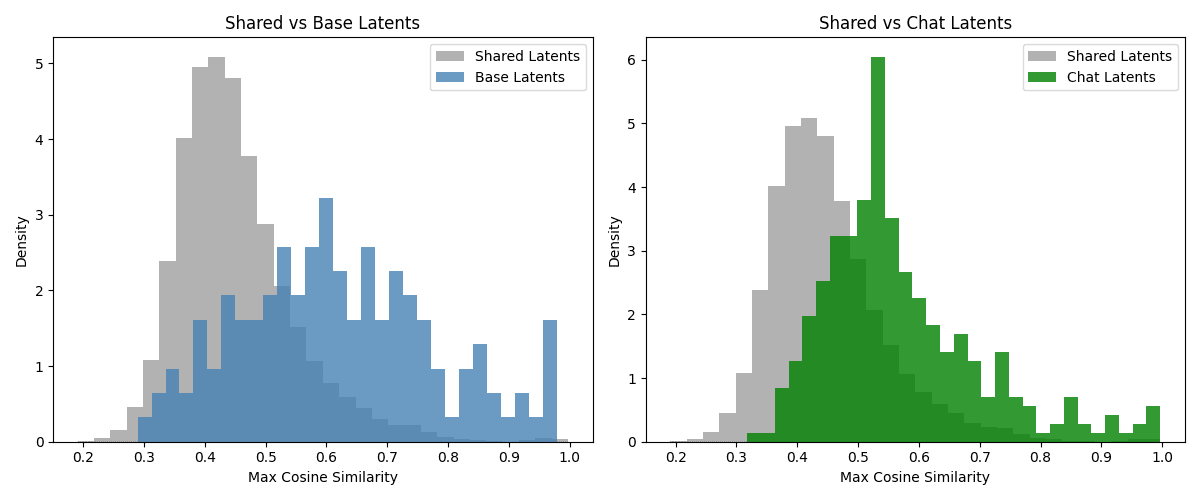
Figure 11This experiment suggests that base and chat exclusive latents are actually less exclusive than the shared latents!
Additional perspectives
Addressing polysemanticity: in the standard crosscoder, model exclusive features are forced to be more polysemantic to justify their allocation since they are more expensive than shared features (see explanation here). The Anthropic team shows that one way to address this is to force certain latents to be shared with a lower regularization cost. Our tied crosscoder is another way to address this issue.
Parameter count: We note that the tied crosscoder with 16384*3 latents has two times the parameters that the standard crosscoder of 16384 latents have (it has three times more parameters for the encoder matrix and same number of parameters for decoder matrix.) For a fair comparison, this should be taken into account, although the goal is interpretability and not necessarily efficiency.
Next steps
Here are some experiments and next steps to take, in no particular order.