This is a special post for quick takes by Rauno Arike. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
What are the best blogs that follow the Long Content philosophy?
In his About page, Gwern describes the idea of Long Content as follows:
I have read blogs for many years and most blog posts are the triumph of the hare over the tortoise. They are meant to be read by a few people on a weekday in 2004 and never again, and are quickly abandoned—and perhaps as Assange says, not a moment too soon. (But isn’t that sad? Isn’t it a terrible ROI for one’s time?) On the other hand, the best blogs always seem to be building something: they are rough drafts—works in progress. So I did not wish to write a blog. Then what? More than just “evergreen content”, what would constitute Long Content as opposed to the existing culture of Short Content? How does one live in a Long Now sort of way?
Gwern himself has, of course, been following this approach to blogging for a long time. There are other rationalist(-adjacent) blogs that seem to follow a similar philosophy: niplav mentions Long Content as a direct inspiration, and the pages of Brian Tomasik, Mariven, Gavin Leech, and Yuxi Liu can also be said to fall into this category.
So far, I have only encountered one page outside of the rat-adjacent sphere that resembles the aforementioned blogs: that of Cosma Shalizi. However, I'm much less familiar with the non-rationalist blogosphere, so there must surely be others. Please post them here if you've encountered them! (And also, feel free to link to rat-adjacent blogs that I've neglected.)
The real way to live in the long now, I suspect, is to recognise that the vast majority of projects in human history that are shelved "until they're ready" never, in fact, get released. This is because time and death often get in the way of polishing up your magnum opus. Therefore the reasonable thing in the long view may be to just ship the damn post/video/game/idea, because that's the way it gets into other people's minds and gains a life of its own beyond the confines of the draft folder. Possibly the idea, if it is good enough, will be finished by others, or even outlive you.
This is also Gwern's answer, in the paragraph right after the one Rauno quoted. The main difference is that he rejects finish lines, opting instead for perpetual drafts, like software.
My answer is that one uses such a framework to work on projects that are too big to work on normally or too tedious. (Conscientiousness is often lacking online or in volunteer communities18 and many useful things go undone.) Knowing your site will survive for decades to come gives you the mental wherewithal to tackle long-term tasks like gathering information for years, and such persistence can be useful19—if one holds onto every glimmer of genius for years, then even the dullest person may look a bit like a genius himself20. (Even experienced professionals can only write at their peak for a few hours a day—usually first thing in the morning, it seems.) Half the challenge of fighting procrastination is the pain of starting—I find when I actually get into the swing of working on even dull tasks, it’s not so bad. So this suggests a solution: never start. Merely have perpetual drafts, which one tweaks from time to time. And the rest takes care of itself.
Also I like this:
What is next? So far the pages will persist through time, and they will gradually improve over time. But a truly Long Now approach would be to make them be improved by time—make them more valuable the more time passes. ...
One idea I am exploring is adding long-term predictions like the ones I make on PredictionBook.com. Many27 pages explicitly or implicitly make predictions about the future. As time passes, predictions would be validated or falsified, providing feedback on the ideas.28
For example, the Evangelion essay’s paradigm implies many things about the future movies in Rebuild of Evangelion29; The Melancholy of Kyon is an extended prediction30 of future plot developments in The Melancholy of Haruhi Suzumiya series; Haskell Summer of Code has suggestions about what makes good projects, which could be turned into predictions by applying them to predict success or failure when the next Summer of Code choices are announced. And so on.
At the risk of naming the obvious, Wikipedia is pure long content. Seirdy updates some of their posts over time, especially their post on inclusive websites.
Yes. Seems like the best way to make a website (for an individual) is a combination of blog + wiki.
Blog:
- publish and forget
- sometimes maybe add an "UPDATE" section; but if it would be too long, just write a new blog post and make the UPDATE refer to it
- your fans can subscribe to the feed
Wiki:
- keep updating as many times as you want to, in arbitrary order
Wikipedia isn't a blog, and I don't think Rauno would say that he's interested in wiki-like stuff had someone suggested to him that the notion of Long Content he's using here is overly restricted to ~blogs.
Yeah, Wikipedia would have deserved a mention, though I'm primarily looking for more hidden gems. Thanks for mentioning Seirdy, I hadn't heard of it before!
I strongly recommend mathr (https://mathr.co.uk/web/) for a blog far outside the rat sphere with a "working on a draft for a long time" ethos.
Why do frontier labs keep a lot of their safety research unpublished?
In Reflections on OpenAI, Calvin French-Owen writes:
Safety is actually more of a thing than you might guess if you read a lot from Zvi or Lesswrong. There's a large number of people working to develop safety systems. Given the nature of OpenAI, I saw more focus on practical risks (hate speech, abuse, manipulating political biases, crafting bio-weapons, self-harm, prompt injection) than theoretical ones (intelligence explosion, power-seeking). That's not to say that nobody is working on the latter, there's definitely people focusing on the theoretical risks. But from my viewpoint, it's not the focus. Most of the work which is done isn't published, and OpenAI really should do more to get it out there.
This makes me wonder: what's the main bottleneck that keeps them from publishing this safety research? Unlike capabilities research, it's possible to publish most of this work without giving away model secrets, as Anthropic has shown. It would also have a positive impact on the public perception of OpenAI, at least in LW-adjacent communities. Is it nevertheless about a fear of leaking information to competitors? Is it about the time cost involved in writing a paper? Something else?
most of the x-risk relevant research done at openai is published? the stuff that's not published is usually more on the practical risks side. there just isn't that much xrisk stuff, period.
I don't know or have any way to confirm my guesses, so I'm interested in evidence from the lab. But I'd guess >80% of the decision force is covered by the set of general patterns of:
- what they consider to be safety work also produces capability improvements or even worsens dual use, eg by making models more obedient, and so they don't want to give it to competitors.
- the safety work they don't publish contains things they're trying to prevent the models from producing in the first place, so it'd be like asking a cybersecurity lab to share malware samples - they might do it, sometimes they might consider it a very high priority, but maybe not all their malware samples or sharing right when they get them. might depend on how bad the things are and whether the user is trying to get the model to do the thing they want to prevent, or if the model is spontaneously doing a thing.
- they consider something to be safety that most people would disagree is safety, eg preventing the model from refusing when asked to help with some commonly-accepted ways of harming people, and admitting this would be harmful to PR.
- they on net don't want critique on their safety work, because it's in some competence/caring-bottlenecked way lesser than they expect people expect of them, and so would put them at risk of PR attacks. I expect this is a major force that at least some in some labs org either don't want to admit, or do want to admit but only if it doesn't come with PR backlash.
- it's possible to make their safety work look good, but takes a bunch of work, and they don't want to publish things that look sloppy even if insightful, eg because they have a view where most of the value of publishing is reputational.
openai explicitly encourages safety work that also is useful for capabilities. people at oai think of it as a positive attribute when safety work also helps with capabilities, and are generally confused when i express the view that not advancing capabilities is a desirable attribute of doing safety.
i think we as a community has a definition of the word safety that diverges more from the layperson definition than the openai definition does. i think our definition is more useful to focus on for making the future go well, but i wouldn't say it's the most accepted one.
i think openai deeply believes that doing things in the real world is more important than publishing academic things. so people get rewarded for putting interventions in the world than putting papers in the hands of academics.
I imagine that publishing any X-risk-related safety work draws attention to the whole X-risk thing, which is something OpenAI in particular (and the other labs as well to a degree) have been working hard to avoid doing. This doesn't explain why they don't publish mundane safety work though, and in fact it would predict more mundane publishing as part of their obfuscation strategy.
i have never experienced pushback when publishing research that draws attention to xrisk. it's more that people are not incentivized to work on xrisk research in the first place. also, for mundane safety work, my guess is that modern openai just values shipping things into prod a lot more than writing papers.
(I did experience this at OpenAI in a few different projects and contexts unfortunately. I’m glad that Leo isn’t experiencing it and that he continues to be there)
I acknowledge that I probably have an unusual experience among people working on xrisk things at openai. From what I've heard from other people I trust, there probably have been a bunch of cases where someone was genuinely blocked from publishing something about xrisk, and I just happen to have gotten lucky so far.
it's also worth noting that I am far in the tail ends of the distribution of people willing to ignore incentive gradients if I believe it's correct not to follow them. (I've gotten somewhat more pragmatic about this over time, because sometimes not following the gradient is just dumb. and as a human being it's impossible not to care a little bit about status and money and such. but I still have a very strong tendency to ignore local incentives if I believe something is right in the long run.) like I'm aware I'll get promoed less and be viewed as less cool and not get as much respect and so on if I do the alignment work I think is genuinely important in the long run.
I'd guess for most people, the disincentives for working on xrisk alignment make openai a vastly less pleasant place. so whenever I say I don't feel like I'm pressured not to do what I'm doing, this does not necessarily mean the average person at openai would agree if they tried to work on my stuff.
Publishing anything is a ton of work. People don't do a ton of work unless they have a strong reason, and usually not even then.
I have lots of ideas for essays and blog posts, often on subjects where I've done dozens or hundreds of hours of research and have lots of thoughts. I'll end up actually writing about 1/3 of these, because it takes a lot of time and energy. And this is for random substack essays. I don't have to worry about hostile lawyers, or alienating potential employees, or a horde of Twitter engagement farmers trying to take my words out of context.
I have no specific knowledge, but I imagine this is probably a big part of it.
I think the extent to which it's possible to publish without giving away commercially sensitive information depends a lot on exactly what kind of "safety work" it is. For example, if you figured out a way to stop models from reward hacking on unit tests, it's probably to your advantage to not share that with competitors.
From my experience, there are usually sections (for at least the earlier papers historically) on safety for model releasing.
- PaLM: https://arxiv.org/pdf/2204.02311
- Llama 2: https://arxiv.org/pdf/2307.09288
- Llama 3: https://arxiv.org/pdf/2407.21783
- GPT 4: https://cdn.openai.com/papers/gpt-4-system-card.pdf
Labs release some general paper like (just examples):
- https://arxiv.org/pdf/2202.07646, https://openreview.net/pdf?id=vjel3nWP2a etc (Nicholas Carlini has a lot of paper related to memorization and extractability)
- https://arxiv.org/pdf/2311.18140
- https://arxiv.org/pdf/2507.02735
- https://arxiv.org/pdf/2404.10989v1
If we see less contents in these sections, one possibility is increased legal regulations that may make publication tricky (imagine an extreme case, companies have sincere intents to produce some numbers that is not indication of harm yet, these preliminary or signal numbers could be used in an "abused" way in legal dispute, may be for profitability reasons/"lawyers need to win cases" reasons). To remove sensitive information, it would comes down then to time cost involved in paper writing, and time cost in removing sensitive information. And interestingly, political landscape could steer companies away from being more safety focused. I do hope there could be a better way to resolve this, providing more incentives for companies to report and share mitigations and measurements.
As far as I know, safety tests usually are used for internal decision making at least for releases etc.
off the cuff take, it seems unclear whether publishing the alignment faking paper makes future models slightly likely to write down their true thoughts on the "hidden scratchpad," seems likely that they're smart enough to catch on. I imagine there are other similar projects like this.
[Link] Something weird is happening with LLMs and chess by dynomight
dynomight stacked up 13 LLMs against Stockfish on the lowest difficulty setting and found a huge difference between the performance of GPT-3.5 Turbo Instruct and any other model:
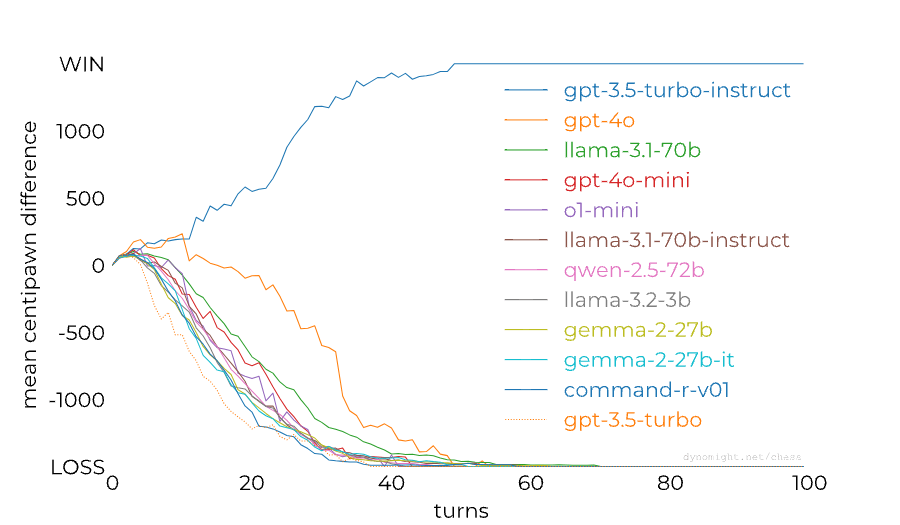
People noticed already last year that RLHF-tuned models are much worse at chess than base/instruct models, so this isn't a completely new result. The gap between models from the GPT family could also perhaps be (partially) closed through better prompting: Adam Karvonen has created a repo for evaluating LLMs' chess-playing abilities and found that many of GPT-4's losses against 3.5 Instruct were caused by GPT-4 proposing illegal moves. However, dynomight notes that there isn't nearly as big of a gap between base and chat models from other model families:
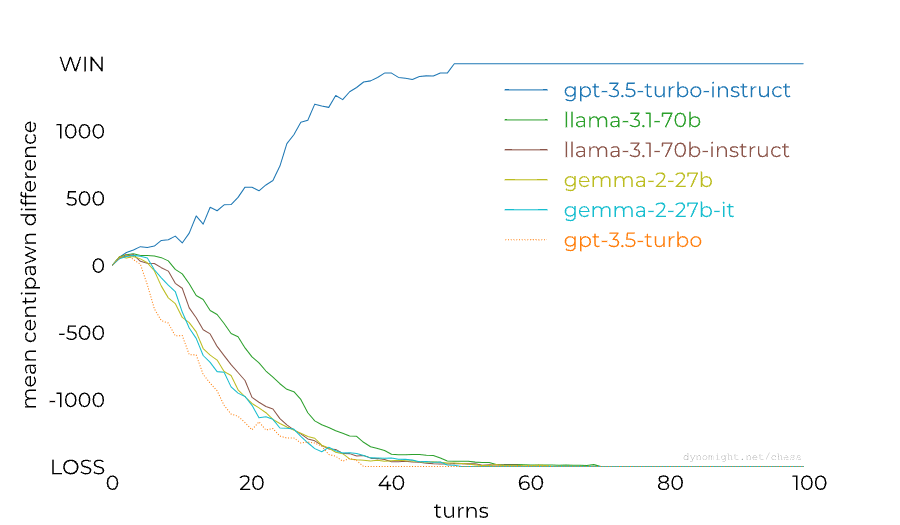
This is a surprising result to me—I had assumed that base models are now generally decent at chess after seeing the news about 3.5 Instruct playing at 1800 ELO level last year. dynomight proposes the following four explanations for the results:
1. Base models at sufficient scale can play chess, but instruction tuning destroys it.
2. GPT-3.5-instruct was trained on more chess games.
3. There’s something particular about different transformer architectures.
4. There’s “competition” between different types of data.
OpenAI models are seemingly trained on huge amounts of chess data, perhaps 1-4% of documents are chess (though chess documents are short, so the fraction of tokens which are chess is smaller than this).
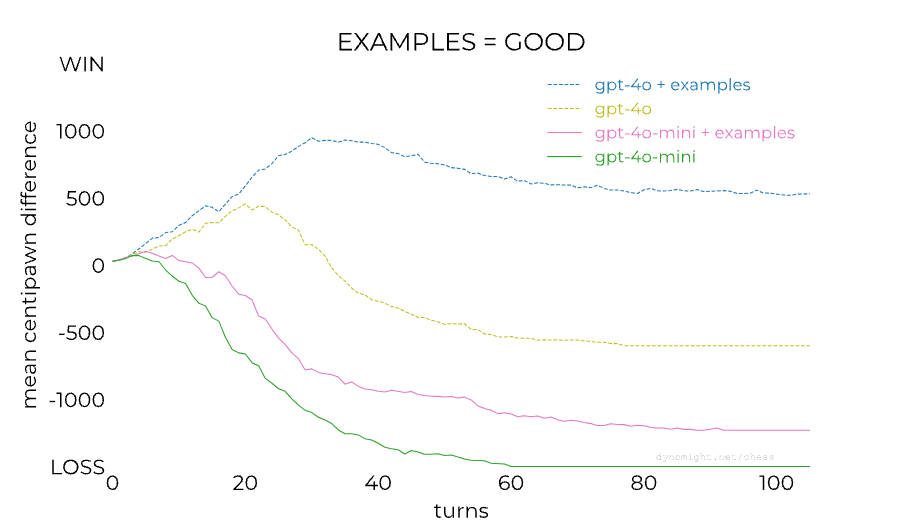
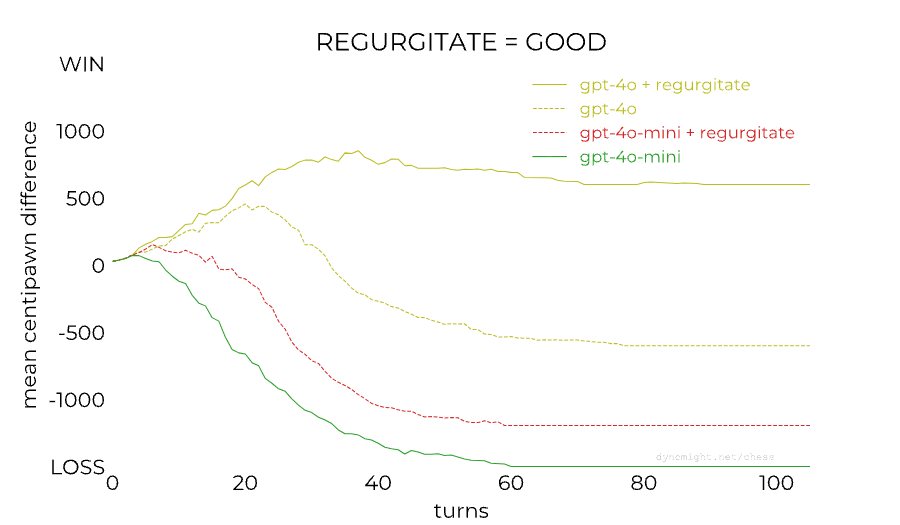
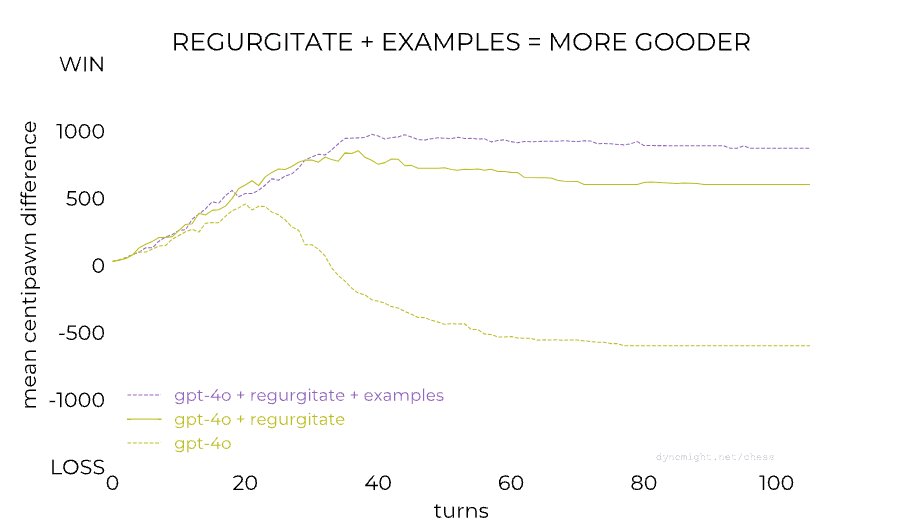
This is very interesting, and thanks for sharing.
- One thing that jumps out at me is they used an instruction format to prompt base models, which isn't typically the way to evaluate base models. It should be reformatted to a completion type of task. If this is redone, I wonder if the performance of the base model will also increase, and maybe that could isolate the effect further to just RLHF.
- I wonder if this has anything to do with also the number of datasets added on by RLHF (assuming a model go through supervised/instruction finetuning first, and then RLHF), besides the algorithm themselves.
- Another good model to test on is https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3 which only has instruction finetuning it seems as well.
The author seems to say that they figured it out at the end of the article, and I am excited to see their exploration in the next post.
There was one comment on twitter that the RLHF-finetuned models also still have the ability to play chess pretty well, just their input/output-formatting made it impossible for them to access this ability (or something along these lines). But apparently it can be recovered with a little finetuning.
Yeah that makes sense; the knowledge should still be there, just need to re-shift the distribution "back"