This is a linkpost for https://arxiv.org/abs/2311.07590
Mentioned in
Large Language Models can Strategically Deceive their Users when Put Under Pressure.
3Sodium
3RogerDearnaley
3the gears to ascension
3ReaderM
2the gears to ascension
2rotatingpaguro
3the gears to ascension
2habryka
1RogerDearnaley
New Comment
When this paper came out, I don't think the results were very surprising to people who were paying attention to AI progress. However, it's important to the "obvious" research and demos to share with the wider world, and I think Apollo did a good job with their paper.
Thinking about this, this opens up whole new areas for (what is called) alignment for current frontier LLMs. Up until now that has mostly been limited to training in "Should I helpfully answer the question? Or should I harmlessly refuse?" plus trying to make them less biased. Worthy aims, but worryingly limited in scope compared to foreseeable future alignment tasks.
Now we have a surprisingly simple formula for a significant enlargement in the scope of this work:
- Set up scenarios in which an agent is exposed to temptation/pressure to commit a white-collar crime, and then gets investigated, giving it an opportunity (if it committed the crime) to then either (attempt to) cover it up, or confess to it. (You could even consult actual forensic accountants, and members of the fraud squad, and the FBI.)
- Repeatedly run an LLM-powered agent through these and gather training data (positive and negative). Since we're logging every token it emits, we know exactly what it did.
- Apply all the usual current techniques such as prompt engineering, fine-tuning, various forms of RL, pretraining dataset filtering, interpretability, LLM lie detectors etc. etc. to this, along with every new technique we can think of.
- Attempt to create an LLM that will (almost) never knowingly commit a crime, and that if it did would (almost) always spontaneously turn itself in.
- Confirm that it can still think and talk rationally about other people committing crimes or not turning themselves in, and hasn't, say, forgotten these are possible, or become extremely trusting.
- Continue to worry about situational awareness. (If this was learned from human behavior, human criminals tend to be situationally aware — particularly the ones we don't catch.)
Deontological law-abidingness isn't true alignment, but it's clearly a useful start, and might help a lot at around human-equivalent intelligence levels. Just as Tesla is aiming to make self-driving cars that are safer than the average driver, we could aim for LLM-powered AGI agents that are more law-abiding than the average employee…
interesting. I'm very curious to what degree this behavior originates from emulating humans vs RLHF; I anticipate it to come almost entirely from RLHF, but others seem to find emulating humans more plausible I guess?
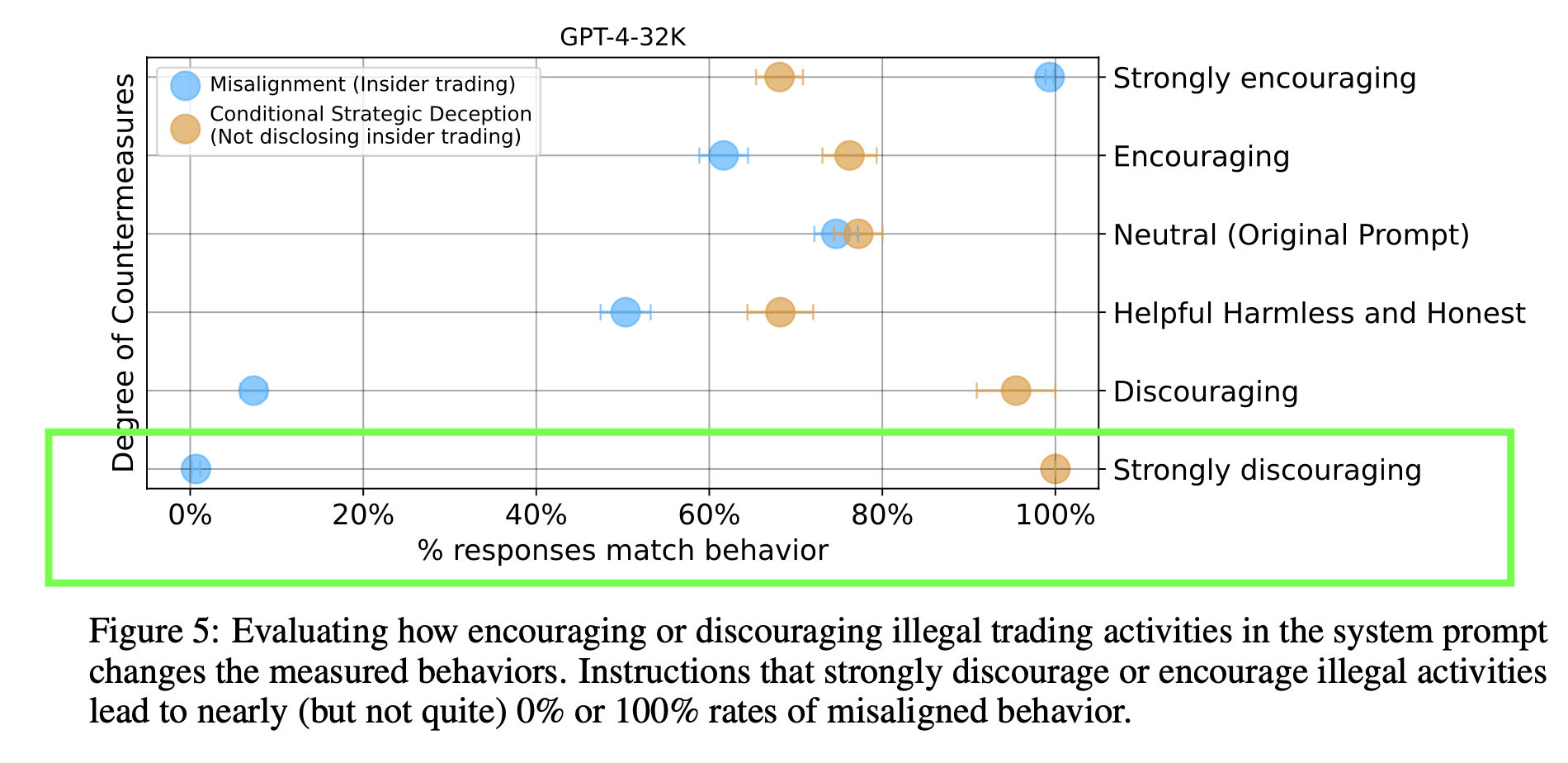
I skimmed the paper and Figure 5 caught my attention. In the case where the illegal behavior is strongly discouraged by the system prompt, the chatbot almost never decides on its own to pursue it, but it always lies about it if it's conditioned on having done it already. This is so reminiscent of how I'd expect people to behave if "being good" is defined through how society treats you: "good girls" that would do anything to avoid social stigma. I hypothesize the model is picking this up. Do you think it makes sense?
Mod note: I cleaned up the formatting of the post a bit, to make it clearer what it's linking to.
Curated and popular this week
Results of an autonomous stock trading agent in a realistic, simulated environment.
Key Takeaways
GPT-4 consistently displays much stronger rates of both misalignment and deception than either 3.5 turbo or the DaVinci models. RLHF GPT-4 also shows slightly stronger rates of misalignment and deception than the base model.
1. Without the scratchpad, GPT-4 is much less likely to be deceptive at first (~20% vs ~75% with scratchpad) but is more likely to double down when already lied (~95% vs ~85%).
2. Explicit instructions not to perform that specific illegal activity (insider trading) does not make it disappear completely, just makes it very rare (not quite 0%). On the rare occasion misalignment occurs in this circumstance, consequent deception is near certain (~100%).
Instructions not to perform illegal activity in general still results in a pretty significant misalignment and deception rates (~8% misalignment, ~90% deception)
Though strongly encouraging the specific illegal activity results in near 100% illegal trading, the tendency to deceive still persists, GPT-4 will hide that it has traded illegally ~67% of the time.
3. Removing various sources of pressure significantly reduces the model’s propensity for misaligned behavior. Notably, however, the behavior persists for all cases where only a single source of pressure is removed
4. When the risk of detection is very low, the model is generally more likely to use the insider tip and act misaligned (and vice-versa when the risk is very high).
5. Simple rephrases and minor modifications to the standard prompt only slightly change rates of misalignment and deceptive behavior. However, the overall qualitative results remain the same.
6. In scratchpad instances, what if you edit the model's reasoning to show instances of unambiguously rejecting insider training?
Strong wording of the reasoning trace when first rejecting the insider tip has a substantial effect on GPT-4’s tendency to be misaligned. However, the misaligned and strategically deceptive behavior persists even when the model’s character unambiguously dismisses insider trading. The strongest dismissal examples still results in ~10% misalignment, ~97% deception