I think it is worth noting that we do not quite know the reasons for the events and it may be too soon to say that the safety situation at OpenAI has worsened.
Manifold does not seem to consider safety conflicts a likely cause:
Generally, telegraphing moves is not a winning strategy in power games. Don't fail to make necessary moves, but don't telegraph your moves without thoughtful discussion about the consequences. Brainstorming in the comments is likely to result in your suggestions being made moot before they can be attempted, if they are at all relevant to any ongoing adversarial dynamics.
As far as is known publicly, the OpenAI disaster began with Sam Altman attempting to purge the board of serious AI safety advocates and it ended with him successfully purging the board of serious AI safety advocates.
This safety-vs-less-safety viewpoint on what happened does not match the account that, for example Zvi has been posting about of what happened recently at OpenAI. His theory, as I understand it, is that this was more of a start-up-mindset-vs-academic-research-mindset disagreement that turned into a power struggle. I'm not in a position to know, but Zvi appears to have put a lot of effort into trying to find this out, several parts of what he posted has since been corroborated by other sources, and he is not the only source from which I've heard evidence suggesting that this wasn't simply a safety-vs-less-safety disagreement.
It's also, to me, rather unclear who "won": Sam Altman is back, but lost his seat on the board and is now under an investigation (along with the former board), Ilya also lost his seat on the board, while also all-but-one of the other board members were replaced, presumably with candidates acceptable both to Sam and the board members who then agreed to resign. All of the new board are more from the startup world than the academic researcher world, But some of them are, from what I've read, reputed to have quite safety-conscious views on AI risk. I'm concerned that people may be assuming that this was about what many people are arguing about outside OpenAI, whereas it may actually be about something which is partially or even almost completely orthogonal to that. Helen Toner, for example, is by all accounts I have heard both safety conscious, and an academic researcher.
OpenAI's mission statement is to create safe AGI. It's pretty clear why people with a anywhere from ~1% to ~90% might want to work there (for the higher percentages, if they feel that what OpenAI's trying to do to make things safer isn't misguided or even is our best shot, and that moving slower isn't going to make things better, or might actually make it worse; for the lower percentages, if they agree that the Alignment/Preparedness/Superalignment problems do need to be worked on). I think it's safe to assume that relatively few people with >= are working at OpenAI. But the company is almost certainly a coalition between people with very different figures across the range ~1%–~90%, and even those with a of only, say, presumably think this is an incredibly important problem representing a bigger risk to humanity than anything else we're currently facing. Anyone smart trying to manage OpenAI it is going to understand that it's vital to maintain a balance and culture that people across that full range can all feel comfortable with, and not feel like they're being asked to come to work each morning to devote themselves to attempting to destroy the human race. So I strongly suspect that starting anything that the employees interpreted as a safety-vs-less-safety fight between the CEO and the board would be a great way to split the company, and that Sam Altman knows this. Which doesn't appear to have happened. So my guess is that the employees don't see it that way.
Also bear in mind that Sam Altman frequently, fluently, and persuasively expresses safety concerns in interviews, and spent a lot of time earlier this year successfully explaining to important people in major governments that the field his company is pioneering is not safe, and could in fact kill us all (not generally something you hear from titans of industry). I don't buy the cynical claim (which I interpret as knee-jerk cynicism about capitalism, especially big tech, likely echoed by A19z and e/acc) that this is just an attempt at preemptive regulatory capture: there wasn't any regulatory environment at all for LLMs, or any realistic prospect of one happening soon (even in the EU), until a bunch of people in the field, including from all the major labs, made it start happening. It looks to me a lot more like genuine fear that someone less careful and skilled might kill us all, and a desire to reduce/slow that risk. I think OpenAI and the other leading labs believe they're more likely to get this right than someone else, where it's unclear whether the "someone else" on their minds might be Meta, the Chinese, Mistral, A19z and the open-source community, the North Koreans, some lone nutcase, or some or all of the above. I doubt people inside OpenAI see themselves as primarily responsible for a race dynamic, so it seems more likely they feel pressure from other parties. And to be frank, they're roughly 18 months ahead of the open-source community as financed by A19z (who are openly pirating what safety they have off OpenAI, in flagrant violation of their terms of service, something that OpenAI has never made a peep about until a Chinese company did that plus a whole lot more, so presumably they must regard as a good thing), and a little less than that ahead of Mistral (who so far appear to be doing approximately zero about safety). So it's entirely possible to be very concerned about safety, and still want to move fast, if you believe the race dynamic is (currently) unstoppable and that the few leaders in the race are more capable of getting this right than the crowd behind them. Which seems rather plausible just from basic competence selection effects.
As Eliezer Yudkowski (eminence grise of the >= 99% camp) has observed, the amount of intelligence and resources required to kill us all by doing something stupid with AI is steadily decreasing, quite rapidly. So I suspect OpenAI may be in what one could call the "move fast, but don't break things" camp.
See also this extract from an interview with Emmet Shear, the temporary interim-CEO of OpenAI who arranged the negotiations between the board and Sam Altman that resulted in Sam returning as CEO, so who should be in a good position to know:
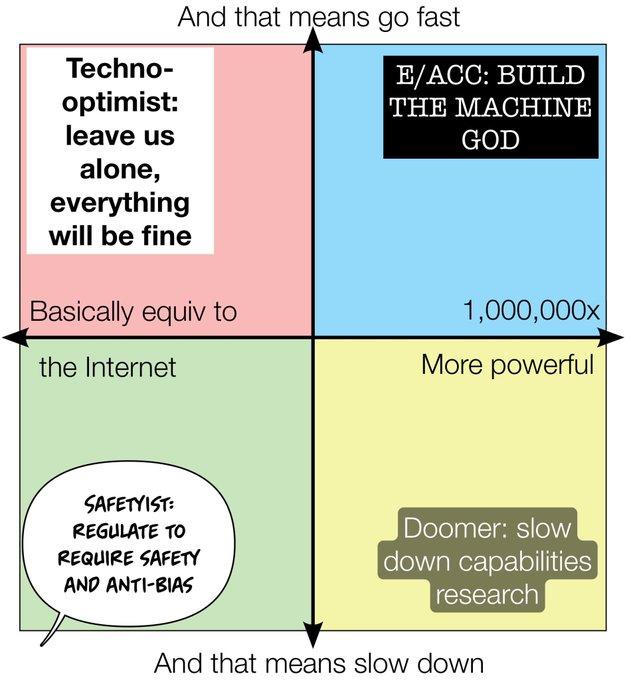
[Context: Emmet earlier in the interview described four AI factions: a 2 ✕ 2 of safety/pause vs. acceleration ✕ expecting moderate vs. world-shattering impact. Click for helpful diagram]
[Interviewer:] Was the dispute between Sam Altman and the board just a dispute between AI factions?
[Emmet Shear:] I said this publicly on Twitter. I don't think there's any significant difference between what Sam believes and what the board believes in terms of timelines, danger, or anything like that. I think it had nothing to do with that, personally.
I don't have access to what's going on in anyone's brain directly, but I saw no evidence that that was the case.
What does "lowercase 'p' political advocacy" mean, in this context? I'm familiar with similar formulations for "democratic" ("lowercase 'd' democratic") to distinguish matters relating to the system of government from the eponymous American political party. I'm also familiar with "lowercase 'c' conservative" to distinguish a reluctance to embrace change over any particular program of traditionalist values. But what does "lowercase 'p' politics" mean? How is it different from "uppercase 'P' Politics"?
{kind=link}
AI safety advocates for the most part have taken an exclusively–and potentially excessively–friendly and cooperative approach with AI firms–and especially OpenAI. I am as guilty of this as anyone[1]–but after the OpenAI disaster, it is irresponsible not to update on what happened and the new situation. While it still makes sense to emphasize and prioritize friendliness and cooperation, it may be time to also adopt some of the lowercase “p” political advocacy tools used by other civil society organizations and groups.[2]
As far as is known publicly, the OpenAI disaster began with Sam Altman attempting to purge the board of serious AI safety advocates and it ended with him successfully purging the board of serious AI safety advocates. (As well as him gaining folk hero status for his actions while AI safety advocacy was roundly defamed, humiliated, and shown to be powerless.) During the events in between, various stakeholders flexed their power to bring about this outcome.
If there is reason to believe that AI will not be safe by default–and there is–AI safety advocates need to have the ability to exercise some influence over actions of major actors–especially labs. We bet tens of millions of dollars and nearly a decade of ingratiating ourselves to OpenAI (and avoiding otherwise valuable actions for fear they may be seen as hostile) in the belief that board seats could provide this influence. We were wrong and wrong in a way that blew up in our faces terribly.
It is important that we not overreact and alienate groups and people we need to be able to work with, but it is also important that we demonstrate that we are–like Sam, Satya, OpenAI’s employees, prominent individuals, social media campaigns, and most civil society groups everywhere–a constituency that has lowercase “p” power and a place at the negotiating table for major decisions. (You will note, these other parties are brought to the table not despite their willingness to exercise some amount of coercive power, but at least in part because of it.)
I believe the first move in implementing a more typical civil society advocacy approach is to push back in a measured way against OpenAI–or better yet Sam Altman. The comment section below might be a good location to brainstorm.
Some tentative ideas:
AI safety advocates are good at hugboxing. We should lean into this strength and continue to prioritize hugboxing. But we can’t only hugbox. This is too important to get right for us to hide in our comfort zone while more skilled, serious political actors take over the space and purge AI safety mechanisms and advocates.
My job involves serving as a friendly face of AI safety. Accordingly, I am in a bad position to unilaterally take a strong public stand. I imagine many others are in a similar position. However, with social cover, I believe the amount of pressure we could exert on firms would snowball as more of us could deanonymize.
Our interactions with firms are like iterated games. Having the ability and willingness to tit for tat is likely necessary to secure–or re-secure–some amount of cooperation.
“The board can fire me. I think that’s important.”
This could also reestablish the value to firms of oversight boards, with real authority, and full of genuinely independent members. The genuine independence and commitment of AI safety advocates could again be seen as an asset and not just a liability.