Lukeprog posted this today on the blog at OpenPhil. I've quoted the opening section, and footnote 17 which has an interesting graph I haven't seen before.
How accurate do long-range (≥10yr) forecasts tend to be, and how much should we rely on them?
As an initial exploration of this question, I sought to study the track record of long-range forecasting exercises from the past. Unfortunately, my key finding so far is that it is difficult to learn much of value from those exercises, for the following reasons:
- Long-range forecasts are often stated too imprecisely to be judged for accuracy.
- Even if a forecast is stated precisely, it might be difficult to find the information needed to check the forecast for accuracy.
- Degrees of confidence for long-range forecasts are rarely quantified.
- In most cases, no comparison to a “baseline method” or “null model” is possible, which makes it difficult to assess how easy or difficult the original forecasts were.
- Incentives for forecaster accuracy are usually unclear or weak.
- Very few studies have been designed so as to allow confident inference about which factors contributed to forecasting accuracy.
- It’s difficult to know how comparable past forecasting exercises are to the forecasting we do for grantmaking purposes, e.g. because the forecasts we make are of a different type, and because the forecasting training and methods we use are different.
Despite this, I think we can learn a little from GJP about the feasibility of long-range forecasting. Good Judgment Project’s Year 4 annual report to IARPA (unpublished), titled “Exploring the Optimal Forecasting Frontier,” examines forecasting accuracy as a function of forecasting horizon in this figure (reproduced with permission):
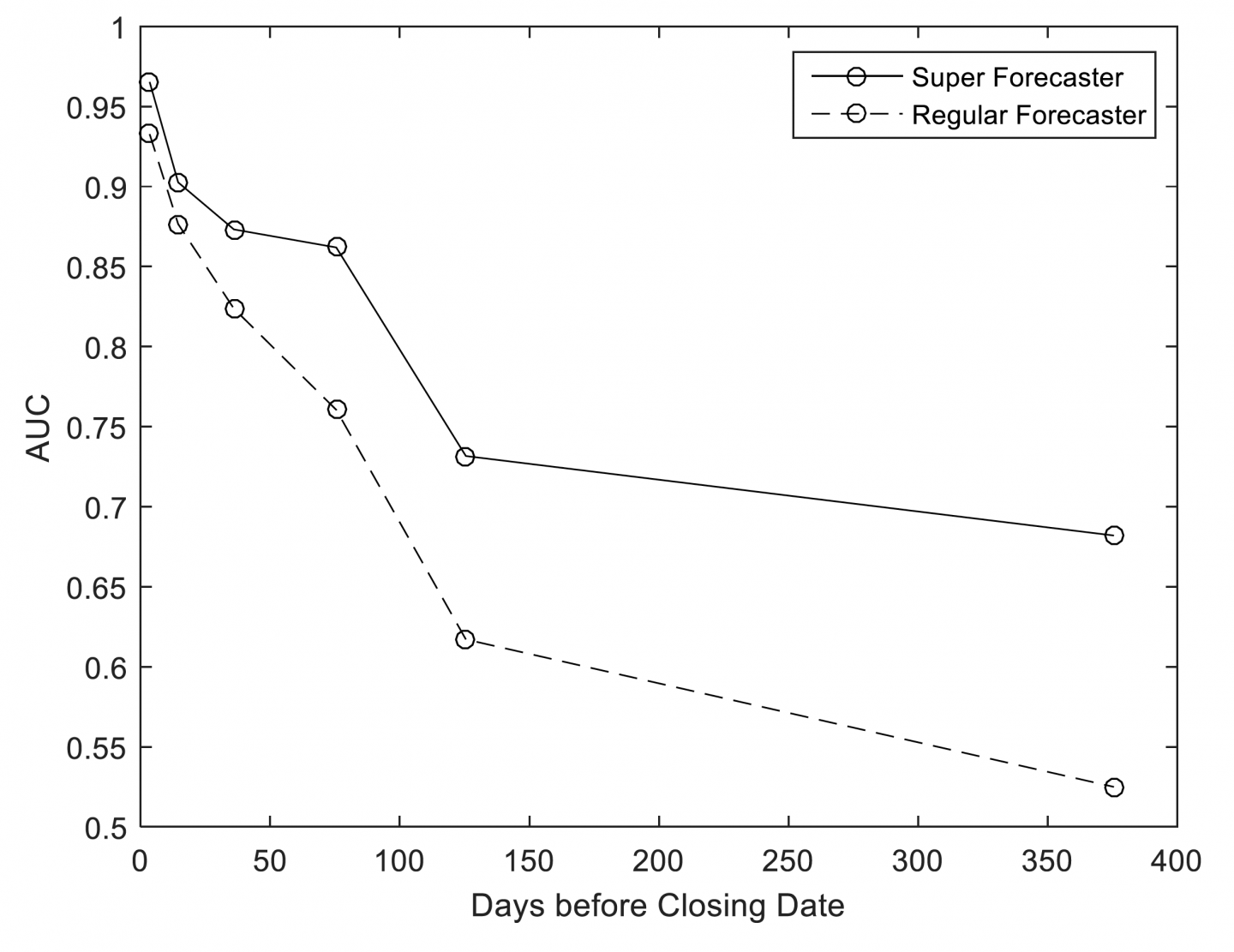
This chart uses an accuracy statistic known as AUC/ROC (see Steyvers et al. 2014) to represent the accuracy of binary, non-conditional forecasts, at different time horizons, throughout years 2-4 of GJP. Roughly speaking, this chart addresses the question: “At different forecasting horizons, how often (on average) were forecasters on ‘the right side of maybe’ (i.e. above 50% confidence in the binary option that turned out to be correct), where 0.5 represents ‘no better than chance’ and 1 represents ‘always on the right side of maybe’?”
For our purposes here, the key results shown above are, roughly speaking, that (1) regular forecasters did approximately no better than chance on this metric at ~375 days before each question closed, (2) superforecasters did substantially better than chance on this metric at ~375 days before each question closed, (3) both regular forecasters and superforecasters were almost always “on the right side of maybe” immediately before each question closed, and (4) superforecasters were roughly as accurate on this metric at ~125 days before each question closed as they were at ~375 days before each question closed.
If GJP had involved questions with substantially longer time horizons, how quickly would superforecaster accuracy declined with longer time horizons? We can’t know, but an extrapolation of the results above is at least compatible with an answer of “fairly slowly.”
I'd be interested to hear others' thoughts on the general question, and any opinions on the linked piece.
I spent years trading in prediction markets so I can offer some perspective.
If you step back and think about it, the question 'How well can the long-term future be forecasted?' doesn't really have an answer. The reason for this is that it completely depends on the domain of the forecasts. Like, consider all facts about the universe. Some facts are very, very predictable. In 10 years, I predict the Sun will exist with 99.99%+ probability. Some facts are very, very unpredictable. In 10 years, I have no clue whether the coin you flip will come up heads or tails. As a result, you cannot really say the future is predictable or not predictable. It depends on which aspect of the future you are predicting. And even if you say, ok sure it depends, but like what's the average answer - even then, the only the way to arrive at some unbiased global sense of whether the future is predictable is to come up with some way of enumerating and weighing all possible facts about the future universe... which is an impossible problem. So we're left with the unsatisfying truth that the future is neither predictable or unpredictable - it depends on which features of the future you are considering.
So when you show the plot above, you have to realize it doesn't generalize very well to other domains. For example, if the questions were about certain things - e.g., will the sun exist in 10 years - it would look high and flat. If the questions were about fundamentally uncertain things - e.g., what will the coin flip be 10 years from now - it would look low and flat. The slope we observe in that plot is less a property of how well the future can be predicted and more a property of the limited set of questions that were asked. If the questions were about uncertain near-term geopolitical events, then that graph shows the rate that information came in to the market consensus. It doesn't really tell us about the bigger picture of predicting the future.
Incidentally, this was my biggest gripe with Tetlock and Gardner's Superforecasting book. They spent a lot of time talking about how Superforecasters could predict the future, but almost no time talking about how the questions were selected and how if you choose different sets of counterfactual questions you can get totally different results (e.g., experts cannot predict the future vs rando smart people can predict the future). I don't really fault them for this, because it's a slippery thorny issue to discuss. I hope I have given you some flavor of it here.
I've been thinking similar things about predictability recently. Different variables have different levels of predictability, it seems very clear. I'm also under the impression that the examples in the Superforecasting study were quite specific. It seems likely that similar problems to what they studied have essentially low predictability 5-10 years out (and that is interesting information!), but this has limited relevance on other possible interesting questions.