I often refer to the ideas in this post and think the fundamental point is quite important: structural advantages in quantity, cost, and speed might make AI systems quite useful and thus impactful prior to being broadly superhuman.
(The exact estimates in the post do pretty strongly assume the current rough architecture, scaling laws, and paradigm, so discount accordingly.)
There are now better estimates of many of the relevant quantities done by various people (maybe Epoch, Daniel Kokotajlo, Eli Lifland), but I'm not aware of another updated article which makes the full argument made here.
The things this post seems to most miss in retrospect:
- It seems that spending more inference compute can (sometimes) be used to qualitatively and quantitatively improve capabilities (e.g., o1, recent swe-bench results, arc-agi rather than merely doing more work in parallel. Thus, it's not clear that the relevant regime will look like "lots of mediocre thinking".[1]
- Inference speeds have actually gone up a bunch not down despite models getting better. (100 tok/s is common for frontier models at the time of writing.) This might be related to models getting smaller. It's not clear this post made a prediction here exactly, but it is an interesting way the picture differs.
- Using specialized hardware (and probably much more cost per token), it is possible to get much faster inference speeds (e.g. 1k tok / s) on frontier modes like llama 405b. I expect this will continue to be possible and a potentially important dynamic will be paying extra to run LLMs very fast on specialized inference hardware.
I continue to think better estimates of the questions raised in this post are important and hope that additional work like this will be out soon.
That said, in practice, methods now often are just doing BoN over whole trajectories which is pretty similar in some sense to lots of mediocre thinking. ↩︎
Thanks!
I agree that we've learned interesting new things about inference speeds. I don't think I would have anticipated that at the time.
Re:
It seems that spending more inference compute can (sometimes) be used to qualitatively and quantitatively improve capabilities (e.g., o1, recent swe-bench results, arc-agi rather than merely doing more work in parallel. Thus, it's not clear that the relevant regime will look like "lots of mediocre thinking".[1]
There are versions of this that I'd still describe as "lots of mediocre thinking" —adding up to being similarly useful as higher-quality thinking.
(C.f. above from the post: "the collective’s intelligence will largely come from [e.g.] Individual systems 'thinking' for a long time, churning through many more explicit thoughts than a skilled human would need to solve a problem" & "Assuming that much of this happens 'behind the scenes', a human interacting with this system might just perceive it as a single super-smart AI.)
The most relevant question is whether we'll still get the purported benefits of the lots-of-mediocre-thinking-regime if there's strong inference scaling. I think we probably do.
Paraphrasing my argument in the "Implications" section:
- If we don't do much end-to-end training of models thinking a lot, then supervision will be pretty easy. (Even if the models think for a long time, it will all be in English, and each leap-of-logic will be weak compared to what the human supervisors can do.)
- End-to-end training of models thinking a lot is expensive. So maybe we won't do it by default, or maybe it will be an acceptable alignment tax to avoid it. (Instead favoring "process-based" methods as the term is used in this post.)
- Even if we do end-to-end training of models thinking a lot, the model's "thinking" might still remain pretty interpretable to humans in practice.
- If models produce good recommendations by thinking a lot in either English or something similar to English, then there ought to be a translation/summary of that argument which humans can understand. Then, even if we're giving the models end-to-end feedback, we could give them feedback based on whether humans recognize the argument as good, rather than by testing the recommendation and seeing whether it leads to good results in the real world. (This comment discusses this distinction. Confusingly, this is sometimes referred to as "process-based feedback" as opposed to "outcomes-based feedback", despite it being slightly different from the concept two bullet points up. )
I think o3 results might involve enough end-to-end training to mostly contradict the hopes of bullet points 1-2. But I'd guess it doesn't contradict 3-4.
(Another caveat that I didn't have in the post is that it's slightly tricker to supervise mediocre serial thinking than mediocre parallel thinking, because you may not be able to evaluate a random step in the middle without loading up on earlier context. But my guess is that you could train AIs to help you with this without adding too much extra risk.)
I suspect there's a cleaner way to make this argument that doesn't talk much about the number of "token-equivalents", but instead contrasts "total FLOP spent on inference" with some combination of:
- "FLOP until human-interpretable information bottleneck". While models still think in English, and doesn't know how to do steganography, this should be FLOP/forward-pass. But it could be much longer in the future, e.g. if the models get trained to think in non-interpretable ways and just outputs a paper written in English once/week.
- "FLOP until feedback" — how many FLOP of compute does the model do before it outputs an answer and gets feedback on it?
- Models will probably be trained on a mixture of different regimes here. E.g.: "FLOP until feedback" being proportional to model size during pre-training (because it gets feedback after each token) and then also being proportional to chain-of-thought length during post-training.
- So if you want to collapse it to one metric, you'd want to somehow weight by number of data-points and sample efficiency for each type of training.
- "FLOP until outcome-based feedback" — same as above, except only counting outcome-based feedback rather than process-based feedback, in the sense discussed in this comment.
Having higher "FLOP until X" (for each of the X in the 3 bullet points) seems to increase danger. While increasing "total FLOP spent on inference" seems to have a much better ratio of increased usefulness : increased danger.
In this framing, I think:
- Based on what we saw of o1's chain-of-thoughts, I'd guess it hasn't changed "FLOP until human-interpretable information bottleneck", but I'm not sure about that.
- It seems plausible that o1/o3 uses RL, and that the models think for much longer before getting feedback. This would increase "FLOP until feedback".
- Not sure what type of feedback they use. I'd guess that the most outcome-based thing they do is "executing code and seeing whether it passes test".
It's possible that "many mediocre or specialized AIs" is, in practice, a bad summary of the regime with strong inference scaling. Maybe people's associations with "lots of mediocre thinking" ends up being misleading.
This relies on an assumption that you can make up for lack-of-intelligence by numbers or speed. Without that assumption, you could expect that AI research will be dominated by humans until AIs finally “get it”, after which they’ll take over with a huge margin.
I interpret the research program described here as aiming to make this assumption true.
So once an AI system trained end-to-end can produce similarly much value per token as a human researcher can produce per second, AI research will be more than fully automated. This means that, when AI first contributes more to AI research than humans do, the average research progress produced by 1 token of output will be significantly less than an average human AI researcher produces in a second of thinking.
Here's one piece of (weak) evidence from the current SOTA on swebench:
'Median token usage per patch: 2.6 million tokens
90th percentile token usage: 11.82 million tokens'
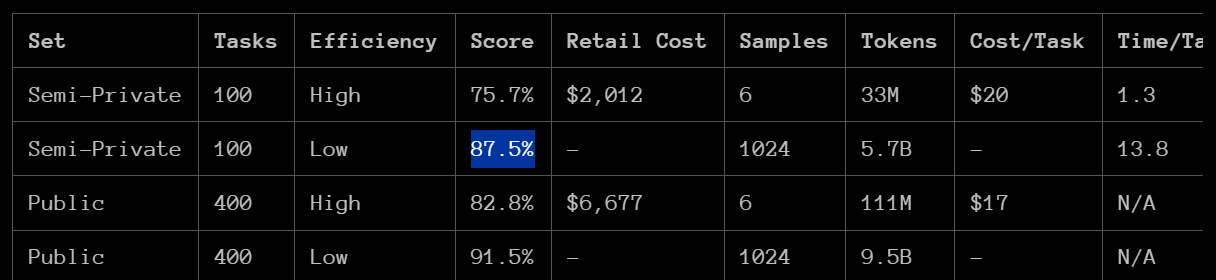
Some additional evidence: o3 used 5.7B tokens per task to achieve its ARC score of 87.5%; it also scored 75.7% on low compute mode using 33M tokens per task:
For the SOTA on swebench-verified as of 16-12-2024: 'it was around $5k for a total run.. around 8M tokens for a single swebench-problem.'
The above numbers suggest that (as long as sample efficiency doesn’t significantly improve) the world will always have enough compute to produce at least 23 million token-equivalents per second from any model that the world can afford to train (end-to-end, chinchilla-style). Notably, these are many more token-equivalents per second than we currently have human-AI-researcher-seconds per second. (And the AIs would have the further advantage of having much faster serial speeds.)
So once an AI system trained end-to-end can produce similarly much value per token as a human researcher can produce per second, AI research will be more than fully automated. This means that, when AI first contributes more to AI research than humans do, the average research progress produced by 1 token of output will be significantly less than an average human AI researcher produces in a second of thinking.
There's probably a very similarly-shaped argument to be made based on difference in cost per token: because LLMs are much cheaper per token, the first time an LLM is as cost-efficient at producing AI research as a human researcher, it should be using many more tokens in its outputs ('the average research progress produced by 1 token of output will be significantly less than an average human AI researcher produces in 1 token of output'). Which, similarly, should be helpful because 'the token-by-token output of a single AI system should be quite easy for humans to supervise and monitor for danger'.
This framing might be more relevant from the POV of economic incentives to automate AI research (and I'm particularly interested in the analogous incentives to/feasibility of automating AI safety research).
I think this argument is made even stronger by additional similar considerations for input tokens too - given the even lower price of input tokens (compared to output tokens), and the scaling laws for long context windows and for RAG.
From https://epochai.org/blog/optimally-allocating-compute-between-inference-and-training, seems consistent with this post's main assumption: 'If it is feasible to trade off inference and training compute, we find that it is optimal for AI labs to spend similar amounts on training and inference.'
So once an AI system trained end-to-end can produce similarly much value per token as a human researcher can produce per second, AI research will be more than fully automated. This means that, when AI first contributes more to AI research than humans do, the average research progress produced by 1 token of output will be significantly less than an average human AI researcher produces in a second of thinking[6]. Instead, the collective’s intelligence will largely come from a combination of things like:
- Individual systems “thinking” for a long time, churning through many more explicit thoughts than a skilled human would need to solve a problem.[7]
- Splitting up things in more granular subtasks, delegating them to other AI systems.
- Generating huge numbers of possible solutions, and evaluating them all before picking one.
Most obviously, the token-by-token output of a single AI system should be quite easy for humans to supervise and monitor for danger. It will rarely contain any implicit cognitive leaps that a human couldn’t have generated themselves. (C.f. visible thoughts project and translucent thoughts hypothesis.)
I think the paper summarized in this twitter thread provides quite strong theoretical arguments in favor of these points.
Summary:
More expensive AI → you can run more AIs with your training budget
The more expensive it is to train AI an AI, the more copies of that AI system can be run in parallel using your training budget. At least, that's the case if we’re making them more expensive by increasing parameter-count and training data.
We’re currently in a paradigm where:
This means that, once you have trained a highly capable model, you are guaranteed to have the resources to run a huge number of them in parallel. And the bigger and more expensive the model was — the more of them can run in parallel on your training cluster.
Here’s a rough calculation of how many language models you can run in parallel using just your training cluster:
If you take a horizon-length framework seriously, you might expect that we’ll need more training data to handle longer-horizon tasks. Let’s introduce a parameter H that describes how many token-equivalents correspond to one data-point.
Some example numbers (bolded ones are changed from the top one):
In addition, there are various tricks for lowering inference costs. For example, reducing precision (which is less important during training than inference) and knowledge distillation; see here for more discussion. These would further increase the number of models you can run in parallel.
A rough lower bound for number of AIs the world could run
The bigger the training run, the more AIs you can run with your training cluster. Conversely, if human-level AI comes earlier, with smaller training runs, you’ll be able to run fewer of them with your training cluster.
On the other hand, if a training run is very small, then it’s only using a small fraction of the world’s compute. This means that there’s a lot of room to run many models in parallel just by acquiring more compute. (It would certainly be economically efficient for a large fraction of the world’s compute to run AI systems, if we did have human-level AI — whether that happens via the developers+investors buying more compute, the developers selling their software, a government seizing the software, or some other way.)
Today, there’s about 4e21 FLOP/s out there in the form of GPUs and TPUs (source). Let’s assume that the world would want to run ~human-level AI systems on at least 25% of that (1e21 FLOP/s), given the option. If so, we can get a rough lower bound on how many ~human-level AIs could be run shortly after training by looking at the number of AIs you could run after training an AI on 1e21 FLOP/s, run for a year:
Some caveats in the footnote.[3]
Serial vs parallel
It’s not clear that you can parallelize tasks well enough to make efficient use of 23 million parallel models. To what degree is it possible to run these AIs fast, so that we get them in series after each other?
I don’t understand this very well. Some relevant information:
The speed is mainly bottlenecked by bandwidth. I’m unsure if the analysis says that latency would only increase with depth or also somewhat with width.[4]
Palm only has 1.5x as many layers as Chinchilla,[5] so this is much slower than Steinhardt’s analysis suggests.
Anecdotal reports about the GPT API are consistent with these slower speeds. The GPT-4 API typically delivers 20 tokens or less per second. (Though potentially up to 40 sometimes?) Though GPT-3.5 Turbo is much faster.
In short: We’re currently at 30-40 tokens per second, which will be reduced by bigger model sizes, increased by future hardware, and increased by better techniques.
This is all for generating tokens. Reading content into the context window doesn’t add latency, since the entire context window can be processed in parallel. (Combining this with parallelism is interesting. An AI could split into 10 copies, investigate 10 different lines of thoughts, and then instantly merge and read all thoughts so-far — and then repeat.)
I feel pretty unsure about how that adds up. But if well-optimized future models (running on future hardware) could operate at, say, ~50 tokens per second, then 23 million tokens per second would correspond to ~500,000 separate streams of 50 tokens/second.
Implications
The above numbers suggest that (as long as sample efficiency doesn’t significantly improve) the world will always have enough compute to produce at least 23 million token-equivalents per second from any model that the world can afford to train (end-to-end, chinchilla-style). Notably, these are many more token-equivalents per second than we currently have human-AI-researcher-seconds per second. (And the AIs would have the further advantage of having much faster serial speeds.)
So once an AI system trained end-to-end can produce similarly much value per token as a human researcher can produce per second, AI research will be more than fully automated. This means that, when AI first contributes more to AI research than humans do, the average research progress produced by 1 token of output will be significantly less than an average human AI researcher produces in a second of thinking.[6] Instead, the collective’s intelligence will largely come from a combination of things like:
Individual systems “thinking” for a long time, churning through many more explicit thoughts than a skilled human would need to solve a problem.[7]
Splitting up things in more granular subtasks, delegating them to other AI systems.
Generating huge numbers of possible solutions, and evaluating them all before picking one.
Assuming that much of this happens “behind the scenes”, a human interacting with this system might just perceive it as a single super-smart AI. Nevertheless, I think this means that AI will be more alignable at a fixed level of productivity. (Eventually, we’ll face the full alignment problem — but “more alignable at a fixed level of productivity” helps if we can use that productivity for something useful, such as giving us more time or helping us with alignment research.)
Most obviously, the token-by-token output of a single AI system should be quite easy for humans to supervise and monitor for danger. It will rarely contain any implicit cognitive leaps that a human couldn’t have generated themselves. (C.f. visible thoughts project and translucent thoughts hypothesis.)
But what about collectives of AIs, or AIs thinking for a long period of time? If people get capability-boosts by fine-tuning such systems end-to-end, then the situation looks quite different. Perhaps it will prove beneficial to finetune such systems to communicate with each other using uninterpretable vector embeddings. Or even if they keep using English, they might start using steganography.
There are still a few reasons for why this situation seems safer (at a fixed level of AI capability) than it could have been:
Perhaps end-to-end SGD won’t have a big advantage over process-based methods, where humans fine-tune networks individually and glue them together in a way where each network’s output remains interpretable. After all, you can’t afford to do a lot of end-to-end training on the large collectives, since they’re so expensive to run.
Even if people do end-to-end training, the representations passed between models need not immediately become useless. Perhaps there are ways to fight steganography. Intuitively, it at least seems like interpreting the almost-English should be easier than mechanistic interpretability of the neural networks. (Though that isn’t a high bar.)
Even if you ignore the internals of the collectives, it seems like process-based feedback might work unusually well in this regime. This one requires a bit more explanation.
Above, I gestured at “process-based” as distinct from end-to-end training. But a weaker definition of process-based feedback (as distinct from outcomes-based feedback) is: You only ever train your AI to recommend suggested actions, and when deciding what feedback to give, you never test its suggestions in the real world. Instead, you make a decision by thinking carefully, potentially informed by a long investigation, including AI advice. (On episodes when you’re not providing feedback, you can implement the suggested actions without such detailed oversight.)[9]
The downside of this strategy is that it isn’t very competitive — e.g. if you’re serious about it, you might have to evaluate AI pull requests without testing the code, which is a serious downside.
But it seems like it should be unusually likely to be competitive when fine-tuning collectives of subhuman intelligences:
A few caveats
A big caveat to this is that AI and humans will have different distributions of capabilities.[10] If there are some topics on which AI is much, much better than humans, then humans might not understand AI’s reasoning about that when looking at token-by-token output (even before end-to-end training). And outcomes-based feedback might be necessary to elicit AI’s full capabilities on that topic.
Indeed, it seems plausible that the story of AI automation won’t be one where many low-capability AIs combine to be human-ish. Instead, it might be that AI automates one task at a time, and that use cases where AI isn’t at least as good as humans aren’t ever that important (c.f. Tom Davidson’s takeoff speeds model and Richard Ngo’s framework). This would also have implications for the shape of early alignment, and whether early AI systems would help with later alignment — but the analysis might be quite different, and involve thinking in detail about what sort of tasks are likely to be automated in what order. I’d be interested in such analysis.
…
Acknowledgements: Thanks to Tom Davidson and Daniel Kokotajlo for comments. I work at Open Philanthropy but the views here are my own.
Notes
Non-parallelizable training wouldn’t exactly contradict the conclusions here, but it would change what arguments I’d use for them, and it would make the world into a weirder place. (E.g. extra compute wouldn’t help to make smarter models, beyond a point, and AI progress would instead be mostly driven by software, serial time (!) necessary to train models, and maybe inference-time compute, if that was more parallelizable.) ↩︎
According to The longest training run: “Training runs of large Machine Learning systems are likely to last less than 14-15 months. This is because longer runs will be outcompeted by runs that start later and therefore use better hardware and better algorithms. “. ↩︎
In practice, many of the world’s GPUs wouldn’t be able to efficiently run large models like this, e.g. because of a lack of memory. 25% of the world’s compute is probably an overestimate. On the other hand, specialized hardware is much more important for training than for inference. So if FLOP-supply keeps being dominated by non-specialized hardware, this pushes for more token-equivalents per second, because there would probably be many GPUs you could run your model on that you couldn’t train them on. ↩︎
See page 6 for formula T<sub>comm</sub> = (√ BLF / √nchips) × 4E / network bandwidth. B is batch size; L is sequence length; F is the width-dimension of the feed-forward networks. E is the embedding/activation size. That’s per layer, so latency straightforwardly increases with more layers. But if you simultaneously scale the embedding dimension and the width of the feed-forward networks by 2x, I think you increase overall computation by 2^2=4x. That justifies increasing chips by 4x. But that leads to an overall change in T by (√2/√4) * 2 = √2? So maybe scaling width by 2x increases latency by √2? ↩︎
Chinchilla has 80 (Hoffmann et al., 2022). PaLM has 118 (Chowdhery et al., 2022). ↩︎
This relies on an assumption that you can make up for lack-of-intelligence by numbers or speed. Without that assumption, you could expect that AI research will be dominated by humans until AIs finally “get it”, after which they’ll take over with a huge margin. ↩︎
Typical reading is ~300 wpm = 5 words per second. Typical speaking might be ~half that. ↩︎
One framing of this is: The reason why the bitter lesson applied so strongly in the last few decades is plausibly that compute increased very quickly compared to researcher labor. If AI systems start contributing to AI research, that will correspond to a massive increase in researcher labor, which might reverse the trend. ↩︎
C.f. this comment. ↩︎
Though as long as the best pre-training task is to predict human text, they’ll be more similar than you might otherwise have expected. ↩︎