It makes me a bit worried that this post seems to implicitly assume that SAEs work well at their stated purpose. This seems pretty unclear based on the empirical evidence and I would bet against.[1]
It also seems to assume that "superposition" and "polysemanticity" are good abstractions for understanding what's going on. This seems at least unclear to me, though it's probably at least partially true.
(Precisely, I would bet against "mild tweaks on SAEs will allow for interpretability researchers to produce succinct and human understandable explanations that allow for recovering >75% of the training compute of model components". Some operationalizations of these terms are explained here. I think people have weaker hopes for SAEs than this, but they're trickier to bet on.)
If I was working on this research agenda, I would be very interested in either:
- Finding a downstream task that demonstrates that the core building block works sufficiently. It's unclear what this would be given the overall level of ambitiousness. The closest work thus far is this I think.
- Demonstrating strong performance at good notions of "internal validity" like "we can explain >75% of the training compute of this tiny sub part of a realistic LLM after putting in huge amounts of labor" (>75% of training compute means that if you scaled up this methodology to the whole model you would get performance which is what you would get with >75% of the training compute used on the original model). Note that this doesn't correspond to reconstruction loss and instead corresponds to the performance of human interpretable (e.g. natural language) explanations.
To be clear, the seem like a reasonable direction to explore and they very likely improve on the state of the art in at least some cases. It's just that they don't clearly work that well at an absolute level. ↩︎
Thanks for this feedback! I agree that the task & demo you suggested should be of interest to those working on the agenda.
It makes me a bit worried that this post seems to implicitly assume that SAEs work well at their stated purpose.
There were a few purposes proposed, and at multiple levels of abstraction, e.g.
- The purpose of being the main building block of a mathematical description used in an ambitious mech interp solution
- The purpose of being the main building block of decompiled networks
- The purpose of taking features out of superposition
I'm going to assume you meant the first one (and maybe the second). Lmk if not.
Fwiw I'm not totally convinced that SAEs are the ultimate solution for the purposes in the first two bullet points. But I do think they're currently SOTA for ambitious mech interp purposes, and there is usually scientific benefit of using imperfect but SOTA methods to push the frontier of what we know about network internals. Indeed, I view this as beneficial in the same way that historical applications of (e.g.) causal scrubbing for circuit discovery were beneficial, despite the imperfections of both methods.
I'll also add a persnickety note that I do explicitly say in the agenda that we should be looking for better methods than SAEs: "It would be nice to have a formal justification for why we should expect sparsification to yield short semantic descriptions. Currently, the justification is simply that it appears to work and a vague assumption about the data distribution containing sparse features. I would support work that critically examines this assumption (though I don't currently intend to work on it directly), since it may yield a better criterion to optimize than simply ‘sparsity’ or may yield even better interpretability methods than SAEs."
However, to concede to your overall point, the rest of the article does kinda suggest that we can make progress in interp with SAEs. But as argued above, I'm comfortable that some people in the field proceed with inquiries that use probably imperfect methods.
Precisely, I would bet against "mild tweaks on SAEs will allow for interpretability researchers to produce succinct and human understandable explanations that allow for recovering >75% of the training compute of model components".
I'm curious if you believe that, even if SAEs aren't the right solution, there realistically exists a potential solution that would allow researchers to produce succinct, human understandable explanation that allow for recovering >75% of the training compute of model components?
I'm wondering if the issue you're pointing at is the goal rather than the method.
I'm curious if you believe that, even if SAEs aren't the right solution, there realistically exists a potential solution that would allow researchers to produce succinct, human understandable explanation that allow for recovering >75% of the training compute of model components?
There isn't any clear reason to think this is impossible, but there are multiple reasons to think this is very, very hard.
I think highly ambitious bottom up interpretability (which naturally pursues this sort of goal), seems like an decent bet overall, but seems unlikely to succeed. E.g. more like a 5% chance of full ambitious success prior to the research[1] being massively speed up by AI and maybe a 10% chance of full success prior to humans being obsoleted.
(And there is some chance of less ambitious contributions as a byproduct of this work.)
I just worried because the field is massive and many people seem to think that the field is much further along than it actually is in terms of empirical results. (It's not clear to me that we disagree that much, especially about next steps. However, I worry that this post contributes to a generally over optimistic view of bottom-up interp that is relatively common.)
The research labor, not the interpretability labor. I would count it as success if we know how to do all the interp labor once powerful AIs exist. ↩︎
It seems worth noting that there are good a priori reasons to think that you can't do much better than around the "size of network" if you want a full explanation of the network's behavior. So, for models that are 10 terabytes in size, you should perhaps be expecting a "model manual" which is around 10 terabytes in size. (For scale this is around 10 million books as long as moby dick.)
Perhaps you can reduce this cost by a factor of 100 by taking advantage of human concepts (down to 100,000 moby dicks) and perhaps you can only implicitly represent this structure in a way that allow for lazy construction upon queries.
Or perhaps you don't think you need something which is close in accuracy to a full explanation of the network's behavior.
More discussion of this sort of consideration can be found here.
So, for models that are 10 terabytes in size, you should perhaps be expecting a "model manual" which is around 10 terabytes in size.
Yep, that seems reasonable.
I'm guessing you're not satisfied with the retort that we should expect AIs to do the heavy lifting here?
Or perhaps you don't think you need something which is close in accuracy to a full explanation of the network's behavior.
I think the accuracy you need will depend on your use case. I don't think of it as a globally applicable quantity for all of interp.
For instance, maybe to 'audit for deception' you really only need identify and detect when the deception circuits are active, which will involve explaining only 0.0001% of the network.
But maybe to make robust-to-training interpretability methods you need to understand 99.99...99%.
It seem likely to me that we can unlock more and more interpretability use cases by understanding more and more of the network.
I'm guessing you're not satisfied with the retort that we should expect AIs to do the heavy lifting here?
I think this presents a plausible approach and is likely needed for ambitious bottom up interp. So this seems like a reasonable plan.
I just think that it's worth acknowledging that "short description length" and "sparse" don't result in something which is overall small in an absolute sense.
The sparsity penalty trains the SAE to activate fewer features for any given datapoint, thus optimizing for shorter mathematical description length.
I'm confused by this claim and some related ones, sorry if this comment is correspondingly confused and rambly.
It's not obvious at all to me that SAEs lead to shorter descriptions in any meaningful sense. We get sparser features (and maybe sparser interactions between features), but in exchange, we have more features and higher loss. Overall, I share Ryan's intuition here that it seems pretty hard to do much better than the total size of the network parameters in terms of description length.
Of course, the actual minimal description length program that achieves the same loss probably looks nothing like a neural network and is much more efficient. But why would SAEs let us get much closer to that? (The reason we use neural networks instead of arbitrary Turing machines in the first place is that optimizing over the latter is intractable.)
One might say that SAEs lead to something like a shorter "description length of what happens on any individual input" (in the sense that fewer features are active). But I don't think there's a formalization of this claim that captures what we want. In the limit of very many SAE features, we can just have one feature active at a time, but clearly that's not helpful.
If you're fine with a significant hit in loss from decompiling networks, then I'm much more sympathetic to the claim that you can reduce description length. But in that case, I could also reduce the description length by training a smaller model.
You might also be using a notion of "mathematical description length" that's a bit different from what I'm was thinking of (which is roughly "how much disk space would the parameters take?"), but I'm not sure what it is. One attempt at an alternative would be something like "length of the shortest efficiently runnable Turing machine that outputs the parameters", in order to not penalize simple repetitive structures, but I have no idea how using that definition would actually shake out.
All that said, I'm very glad you wrote this detailed description of your plans! I'm probably more pessimistic than you about it but still think this is a great post.
Thanks Erik :) And I'm glad you raised this.
One of the things that many researchers I've talked to don't appreciate is that, if we accept networks can do computation in superposition, then we also have to accept that we can't just understand the network alone. We want to understand the network's behaviour on a dataset, where the dataset contains potentially lots of features. And depending on the features that are active in a given datum, the network can do different computations in superposition (unlike in a linear network that can't do superposition). The combined object '(network, dataset)' is much larger than the network itself. Explanations Descriptions of the (network, dataset) object can actually be compressions despite potentially being larger than the network.
So,
One might say that SAEs lead to something like a shorter "description length of what happens on any individual input" (in the sense that fewer features are active). But I don't think there's a formalization of this claim that captures what we want. In the limit of very many SAE features, we can just have one feature active at a time, but clearly that's not helpful.
You can have one feature active for each datapoint, but now we've got an explanation description of the (network, dataset) that scales linearly in the size of the dataset, which sucks! Instead, if we look for regularities (opportunities for compression) in how the network treats data, then we have a better chance at explanations descriptions that scale better with dataset size. Suppose a datum consists of a novel combination of previously explained described circuits. Then our explanation description of the (network, dataset) is much smaller than if we explained described every datapoint anew.
In light of that, you can understand my disagreement with "in that case, I could also reduce the description length by training a smaller model." No! Assuming the network is smaller yet as performant (therefore presumably doing more computation in superposition), then the explanation description of the (network, dataset) is basically unchanged.
Is there some formal-ish definition of "explanation of (network, dataset)" and "mathematical description length of an explanation" such that you think SAEs are especially short explanations? I still don't think I have whatever intuition you're describing, and I feel like the issue is that I don't know how you're measuring description length and what class of "explanations" you're considering.
As naive examples that probably don't work (similar to the ones from my original comment):
- We could consider any Turing machine that approximately outputs (network, dataset) an "explanation", but it seems very likely that SAEs aren't competitive with short TMs of this form (obviously this isn't a fair comparison)
- We could consider fixed computational graphs made out of linear maps and count the number of parameters. I think your objection to this is that these don't "explain the dataset"? (but then I'm not sure in what sense SAEs do)
- We could consider arithmetic circuits that approximate the network on the dataset, and count the number of edges in the circuit to get "description length". This might give some advantage to SAEs if you can get sparse weights in the sparse basis, seems like the best attempt out of these three. But it seems very unclear to me that SAEs are better in this sense than even the original network (let alone stuff like pruning).
Focusing instead on what an "explanation" is: would you say the network itself is an "explanation of (network, dataset)" and just has high description length? If not, then the thing I don't understand is more about what an explanation is and why SAEs are one, rather than how you measure description length.
ETA: On re-reading, the following quote makes me think the issue is that I don't understand what you mean by "the explanation" (is there a single objective explanation of any given network? If so, what is it?) But I'll leave the rest in case it helps clarify where I'm confused.
Assuming the network is smaller yet as performant (therefore presumably doing more computation in superposition), then the explanation of the (network, dataset) is basically unchanged.
Is there some formal-ish definition of "explanation of (network, dataset)" and "mathematical description length of an explanation" such that you think SAEs are especially short explanations? I still don't think I have whatever intuition you're describing, and I feel like the issue is that I don't know how you're measuring description length and what class of "explanations" you're considering.
I'll register that I prefer using 'description' instead of 'explanation' in most places. The reason is that 'explanation' invokes a notion of understanding, which requires both a mathematical description and a semantic description. So I regret using the word explanation in the comment above (although not completely wrong to use it - but it did risk confusion). I'll edit to replace it with 'description' and strikethrough 'explanation'.
"explanation of (network, dataset)": I'm afraid I don't have a great formalish definition beyond just pointing at the intuitive notion. But formalizing what an explanation is seems like a high bar. If it's helpful, a mathematical description is just a statement of what the network is in terms of particular kinds of mathematical objects.
"mathematical description length of an explanation": (Note: Mathematical descriptions are of networks, not of explanations.) It's just the set of objects used to describe the network. Maybe helpful to think in terms of maps between different descriptions: E.g. there is a many-to-one map between a description of a neural network in terms of polytopes and in terms of neurons. There are ~exponentially many more polytopes. Hence the mathematical description of the network in terms of individual polytopes is much larger.
Focusing instead on what an "explanation" is: would you say the network itself is an "explanation of (network, dataset)" and just has high description length?
I would not. So:
If not, then the thing I don't understand is more about what an explanation is and why SAEs are one, rather than how you measure description length.
I think that the confusion might again be from using 'explanation' rather than description.
SAEs (or decompiled networks that use SAEs as the building block) are supposed to approximate the original network behaviour. So SAEs are mathematical descriptions of the network, but not of the (network, dataset). What's a mathematical description of the (network, dataset), then? It's just what you get when you pass the dataset through the network; this datum interacts with this weight to produce this activation, that datum interacts with this weight to produce that activation, and so on. A mathematical description of the (network, dataset) in terms of SAEs are: this datum activates dictionary features xyz (where xyz is just indices and has no semantic info), that datum activates dictionary features abc, and so on.
Lmk if that's any clearer.
Thanks for the detailed responses! I'm happy to talk about "descriptions" throughout.
Trying to summarize my current understanding of what you're saying:
- SAEs themselves aren't meant to be descriptions of (network, dataset). (I'd just misinterpreted your earlier comment.)
- As a description of just the network, SAEs have a higher description length than a naive neuron-based description of the network.
- Given a description of the network in terms of "parts," we can get a description of (network, dataset) by listing out which "parts" are "active" on each sample. I assume we then "compress" this description somehow (e.g. grouping similar samples), since otherwise the description would always have size linear in the dataset size?
- You're then claiming that SAEs are a particularly short description of (network, dataset) in this sense (since they're optimized for not having many parts active).
My confusion mainly comes down to defining the words in quotes above, i.e. "parts", "active", and "compress". My sense is that they are playing a pretty crucial role and that there are important conceptual issues with formalizing them. (So it's not just that we have a great intuition and it's just annoying to spell it out mathematically, I'm not convinced we even have a good intuitive understanding of what these things should mean.)
That said, my sense is you're not claiming any of this is easy to define. I'd guess you have intuitions that the "short description length" framing is philosophically the right one, and I probably don't quite share those and feel more confused how to best think about "short descriptions" if we don't just allow arbitrary Turing machines (basically because deciding what allowable "parts" or mathematical objects are seems to be doing a lot of work). Not sure how feasible converging on this is in this format (though I'm happy to keep trying a bit more in case you're excited to explain).
Trying to summarize my current understanding of what you're saying:
Yes all four sound right to me.
To avoid any confusion, I'd just add an emphasis that the descriptions are mathematical, as opposed semantic.
I'd guess you have intuitions that the "short description length" framing is philosophically the right one, and I probably don't quite share those and feel more confused how to best think about "short descriptions" if we don't just allow arbitrary Turing machines (basically because deciding what allowable "parts" or mathematical objects are seems to be doing a lot of work). Not sure how feasible converging on this is in this format (though I'm happy to keep trying a bit more in case you're excited to explain).
I too am keen to converge on a format in terms of Turing machines or Kolmogorov complexity or something else more formal. But I don't feel very well placed to do that, unfortunately, since thinking in those terms isn't very natural to me yet.
"explanation of (network, dataset)": I'm afraid I don't have a great formalish definition beyond just pointing at the intuitive notion.
What's wrong with "proof" as a formal definition of explanation (of behavior of a network on a dataset)? I claim that description length works pretty well on "formal proof", I'm in the process of producing a write-up on results exploring this.
The combined object '(network, dataset)' is much larger than the network itself
Only by a constant factor with chinchilla scaling laws right (e.g. maybe 20x more tokens than params)? And spiritually, we only need to understand behavior on the training dataset to understand everything that SGD has taught the model.
Hm I think of the (network, dataset) as scaling multiplicatively with size of network and size of dataset. In the thread with Erik above, I touched a little bit on why:
"SAEs (or decompiled networks that use SAEs as the building block) are supposed to approximate the original network behaviour. So SAEs are mathematical descriptions of the network, but not of the (network, dataset). What's a mathematical description of the (network, dataset), then? It's just what you get when you pass the dataset through the network; this datum interacts with this weight to produce this activation, that datum interacts with this weight to produce that activation, and so on. A mathematical description of the (network, dataset) in terms of SAEs are: this datum activates dictionary features xyz (where xyz is just indices and has no semantic info), that datum activates dictionary features abc, and so on."
And spiritually, we only need to understand behavior on the training dataset to understand everything that SGD has taught the model.
Yes, I roughly agree with the spirit of this.
description of (network, dataset) for LLMs ?= model that takes as input index of prompt in dataset, then is equivalent to original model conditioned on that prompt
Mechanistic interpretability-based evals could try to find inputs that lead to concerning combinations of features
An early work that does this on the vision model is https://distill.pub/2019/activation-atlas/.
Specifically, in the section on Focusing on a Single Classification, they observe spurious correlations in the activation space, via feature visualization, and use this observation to construct new failure cases of the model.
Cool post! I often find myself confused/unable to guess why people I don't know are excited about SAEs (there seem to be a few vaguely conflicting reasons), and this was a very clear description of your agenda.
I'm a little confused by this point:
> The reconstruction loss trains the SAE features to approximate what the network does, thus optimizing for mathematical description accuracy
It's not clear to me that framing reconstruction loss as 'approximating what the network does' is the correct framing of this loss. In my mind, the reconstruction loss is more of a non-degeneracy control to encourage almost-orthogonality between features; In toy settings, SAEs are able to recover ground truth directions while still having sub-perfect reconstruction loss, and it seems very plausible that we should be able to use this (e.g. maybe through gradient-based attribution) without having to optimise heavily for reconstruction loss, which might degrade scalability (which seems very important for this agenda) and monosemanticity compared to currently-unexplored alternatives.
Thanks Aidan!
I'm not sure I follow this bit:
In my mind, the reconstruction loss is more of a non-degeneracy control to encourage almost-orthogonality between features.
I don't currently see why reconstruction would encourage features to be different directions from each other in any way unless paired with an L_{0<p<1}. And I specifically don't mean L1, because in toy data settings with recon+L1, you can end up with features pointing in exactly the same direction.
We propose a simple fix: Use instead of , which seems to be a Pareto improvement over (at least in some real models, though results might be mixed) in terms of the number of features required to achieve a given reconstruction error.
When I was discussing better sparsity penalties with Lawrence, and the fact that I observed some instability in in toy models of super-position, he pointed out that the gradient of norm explodes near zero, meaning that features with "small errors" that cause them to have very small but non-zero overlap with some activations might be killed off entirely rather than merely having the overlap penalized.
See here for some brief write-up and animations.
Choosing better sparsity penalties than L1 (Upcoming post - Ben Wright & Lee Sharkey): [...] We propose a simple fix: Use instead of , which seems to be a Pareto improvement over
Is there any particular justification for using rather than, e.g., tanh (cf Anthropic's Feb update), log1psum (acts.log1p().sum()), or prod1p (acts.log1p().sum().exp())? The agenda I'm pursuing (write-up in progress) gives theoretical justification for a sparsity penalty that explodes combinatorially in the number of active features, in any case where the downstream computation performed over the feature does not distribute linearly over features. The product-based sparsity penalty seems to perform a bit better than both and tanh on a toy example (sample size 1), see this colab.
This is a paradigm shift for me. When I entered the field, I thought the uniqueness of MechInterp was that it treated AI like natural science (e.g., biology); hence, I assumed the field primarily does hypothesis testing. However, I agree that augmenting it with a big data-driven approach is the way to move forward.
Over the last couple of years, mechanistic interpretability has seen substantial progress. Part of this progress has been enabled by the identification of superposition as a key barrier to understanding neural networks (Elhage et al., 2022) and the identification of sparse autoencoders as a solution to superposition (Sharkey et al., 2022; Cunningham et al., 2023; Bricken et al., 2023).
From our current vantage point, I think there’s a relatively clear roadmap toward a world where mechanistic interpretability is useful for safety. This post outlines my views on what progress in mechanistic interpretability looks like and what I think is achievable by the field in the next 2+ years. It represents a rough outline of what I plan to work on in the near future.
My thinking and work is, of course, very heavily inspired by the work of Chris Olah, other Anthropic researchers, and other early mechanistic interpretability researchers. In addition to sharing some personal takes, this article brings together - in one place - various goals and ideas that are already floating around the community. It proposes a concrete potential path for how we might get from where we are today in mechanistic interpretability to a world where we can meaningfully use it to improve AI safety.
Key frameworks for understanding the agenda
Framework 1: The three steps of mechanistic interpretability
I think of mechanistic interpretability in terms of three steps:
The three steps of mechanistic interpretability[1]:
The field of mechanistic interpretability has repeated this three-step cycle a few times, cycling through explanations given in terms of neurons, then other objects such as SVD/NMF directions or polytopes, and most recently SAE directions.
My research over the last couple of years has focused primarily on identifying the right mathematical objects for mechanistic explanations. I expect there’s still plenty of work to do on this step in the next two years or so (more on this later). To guide intuitions about how I plan to pursue this, it’s important to understand what makes some mathematical objects better than others. For this, we have to look at the description accuracy vs. description length tradeoff.
Framework 2: The description accuracy vs. description length tradeoff
You would feel pretty dissatisfied if you asked someone for a mechanistic explanation of a neural network and they proceeded to read out of the float values of the weights. But why is this dissatisfying? Two reasons:
Part of our job in mechanistic interpretability (and the framework used in this agenda) is to push the Pareto frontier of current mechanistic interpretability methods toward methods that give us the best tradeoff between description accuracy and description length. We’re therefore not only optimizing for accurate descriptions; we’re also optimizing for shorter descriptions. In other words, we want to find objects that admit mathematical descriptions that use as few objects as possible but that capture as much of what the network is doing as possible. Furthermore, we want short semantic descriptions for these objects, such that we need few words or concepts to describe what they do.
To summarize, we’re in fact optimizing our interpretability methods according to four constraints here:
Inadequacy according to at least one of these constraints has been the downfall of several previous interpretability approaches:
This leads us to one of the core methods in this agenda that so far appears to perform well according to our four constraints: sparse autoencoders (SAEs).
The unreasonable effectiveness of SAEs for mechanistic interpretability
SAEs have risen in popularity over the last year as a candidate solution to the problem of superposition in mechanistic interpretability (Elhage et al., 2022; Sharkey et al., 2022; Cunningham et al., 2023; Bricken et al., 2023)
SAEs are very simple. They consist of an encoder (which is just a linear transformation followed by a nonlinear activation function) and a decoder (or ‘dictionary’) whose features are constrained to have fixed length. The loss function used to train them has two components: (1) The reconstruction loss, so that their output approximates their input; (2) The sparsity loss, which penalizes the encoder outputs to be sparse.
I harp on about SAEs so much that it’s become a point of personal embarrassment. But the reason is because SAEs capture so much of what we want in a mechanistic interpretability method:
It would be nice to have a formal justification for why we should expect sparsification to yield short semantic descriptions. Currently, the justification is simply that it appears to work and a vague assumption about the data distribution containing sparse features. I would support work that critically examines this assumption (though I don't currently intend to work on it directly), since it may yield a better criterion to optimize than simply ‘sparsity’ or may yield even better interpretability methods than SAEs.
The last selling point of SAEs that I'll mention is that the SAE architecture and training method are very flexible: They lend themselves to variants that can be used for much more than merely identifying features in activations. For instance, they could be used to identify interactions between features in adjacent layers (sparse transcoders) or could potentially be used to identify whole circuits (meta-SAEs). We’ll have more to say about transcoders and meta-SAEs later.
Framework 3: Big data-driven science vs. Hypothesis-driven science
The last framework driving this agenda is a piece of ‘science ideology’.
In the last few decades, some branches of science have radically changed. They’ve moved away from purely hypothesis-driven science toward a ‘big data’-driven paradigm.
In hypothesis-driven science, you make an hypothesis about some phenomenon, then collect data that tests the hypothesis (e.g. through experiments or surveys). Think ‘testing general relativity’; ‘testing whether ocean temperature affects atmospheric sulfur levels’; or ‘testing whether smoking causes lung cancer’, etc.
Big Data-driven science does things differently. If Big Data-driven science had a motto, it’d be “Collect data first, ask questions later”. Big Data-driven science collects large datasets, then computationally models the structure in this data. The structure of those computational models suggests hypotheses that can be tested in the traditional way. The Big Data-driven approach has thrived in domains of science where the objects of study are too big, complex, or messy for humans to have much of a chance of comprehending it intuitively, such as genetics, computational neuroscience, or proteomics.
In mechanistic interpretability, I view work such as “Interpretability in the Wild: A Circuit for Indirect Object Identification in GPT-2 small” (Wang et al., 2023) as emblematic of ‘hypothesis-driven science’. They identified a task (‘indirect object identification’ - IOI) and asked if they could identify circuits of nodes (attention heads at particular token positions) that performed this task on a dataset they constructed. This was a very solid contribution to the field. However, to my personal research taste it felt like the wrong way to approach mechanistic interpretability in a few ways:
To me, it felt like coming at mechanistic interpretability from a human perspective when, instead, we should be coming at it from the network’s perspective:
I contend that mechanistic interpretability is a domain that needs a Big Data-driven approach more than usual. Neural networks are too big, too messy, too unintuitive to comprehend unless we map out their components in a principled way. Without mapping the space first, we are flying blind and are bound to get lost. To be absolutely clear, Big Data-driven science does not replace hypothesis-driven science; it just augments hypothesis formation and testing. But I think that without this augmentation, mechanistic interpretability is doomed to flounder (see also Wentworth on this theme).
Fortunately, neural networks are very well suited to Big Data-driven science, because it is so easy to collect data from them. It's even easy to directly collect data about their causal structure (i.e. information about their gradients and architecture), unlike in most areas of science!
The power of Big Data-driven science is a background assumption for much of my research. For me, it motivated the search for SAEs as a scalable, unsupervised structure-finding method, which can be applied to whole networks and datasets, and which might help reveal the objects that the network considers fundamental. It privileges big datasets that contain all the things that a network does such that, when we analyze these big datasets, the interpretable structure of the network naturally falls out thanks to unsupervised methods. And this bit of science ideology also motivates most of the objectives in the agenda.
Sparsify: The Agenda
I envision a mechanistic interpretability tech tree something like this:
I’ll explain what each of the objectives here mean in more detail below. The main convergent objective of the agenda is satisfactory whole-network mechanistic interpretability, which I think could open up a range of safety-relevant applications. Most of the other objectives can be framed as trying to improve our mathematical and semantic descriptions by improving their accuracy vs. length Pareto frontiers.
The objectives for my research over the next 2+ years are the following (with high-variance estimates for timelines that feel somewhat achievable for a community of researchers):
Objective 1: Improving SAEs
I think there’s lots of room for improvement on current SAEs. In particular,
Benchmarking SAEs
At present, it’s difficult to know when SAEs should be considered ‘good’. We need to devise principled metrics and standardized ways to compare them. This will be important both for identifying good SAEs trained on models and for developing improvements on SAEs and SAE training methods.
Fixing SAE pathologies
Current SAEs exhibit a few pathologies that make them suboptimal as mathematical descriptions in terms of both description accuracy and description length. My collaborators and I (through MATS and Apollo Research) are working on a few posts that aim to address them. Here we share an overview of a few early results:
Applying SAEs to attention
Some work (unrelated to my collaborators and I) demonstrate that SAEs work reasonably well when applied to attention block outputs (Kissane et al., 2024). However, so far, the inner workings of attention blocks remain somewhat enigmatic and attention head superposition (Jermyn et al., 2023) remains unresolved.
How best to apply SAE-like methods to decompose attention blocks? We have investigated two approaches in parallel:
Better hyperparameter selection methods
Training SAEs requires selecting multiple hyperparameters. We don’t know how hyperparameters interact with each other, or how they interact with different data distributions. Thus training SAEs often involves sweeps over hyperparameters to find good combinations. Understanding the relationships between different hyperparameters (similar to Yang et al., (2022)) would let us skip expensive hyperparameter sweeps. This is especially important as we scale our interpretability methods to frontier models, where it may be prohibitively expensive to run SAE hyperparameter sweeps.
Computationally efficient sparse coding
There may be additional tips and tricks for training SAEs in more efficient ways. For instance, informed initialization schemes (such as data initialization or resampling) may improve efficiency. Or perhaps particular methods of data preprocessing might help. There is considerable room for exploration.
On a higher level, there probably exist more efficient sparse coding methods than SAEs trained with SGD. If there are better methods, it’s important that the community not get stuck in a local optimum; we should look for these better methods.
In order to be in a position where the next objective is completable, we would need to see some progress in the above areas. Areas of progress like 'better hyperparameter selection' and 'computational efficiency' would yield quality of life improvements. Others are more important; they are essential before we can be confident in our descriptions: Areas like ‘finding functionally relevant features’ or ‘fixing feature suppression’. Other still are even more essential for progress: Unless we can decompose attention blocks in a satisfying way, we will not be able to complete the next objective, which is to fully ‘decompile networks’.
Objective 2: Decompiled networks
Once we’ve identified the functional units of a neural network, then we can decompile it by making a version of the network where superposition has been removed. In decompiled networks, the forward pass does inference in the interpretable feature basis.
Suppose we have trained e2eSAEs in each layer and identified the functional units. We then want to identify the ‘interaction graph’ that describes how features interact between layers. This is where ‘transcoders’ come in. Transcoders, in contrast to autoencoders, are trained to produce different outputs than their inputs. To get the interaction graph between features in adjacent layers, we would train (or otherwise find, perhaps through cleverly transforming the original network's parameters into sparse feature space) a set of transcoders to produce the same output and intermediate feature activations as in the original network. The result is a sparse model that we can use for inference where we don’t need to transform our activations to the original neuron basis; the decompiled network does inference entirely in the sparse feature basis.
Transcoders may have a variety of architectures, such as a simple matrix (as in Riggs et al., 2024 and Marks et al., 2024). Speculatively, we may prefer using something else, such as another SAE architecture (as briefly explored in Riggs et al., 2024). Unlike a purely linear transcoder, an SAE-architecture-transcoder would be able to model nonlinear feature interactions.
It’s worth noting that such a transcoder's sparsely activating features would be ‘interaction features’, which identify particular combinations of sparse features in one layer that activate particular combinations of sparse features in the next layer. The weights of these interaction features are the ‘interaction strengths’ between features. You can thus study the causal influence between features in adjacent layers by inspecting the weights of the transcoder, without even needing to perform causal intervention experiments. The transcoder’s interaction features thus define the ‘atomic units’ of counterfactual explanations for the conditions under which particular features in one layer would activate features in an adjacent layer.
Policy goals for network decompilation
Once we as a community get network decompilation working, we hope that it becomes a standard for developers of big models to produce decompiled versions of their networks alongside the original, 'compiled' networks. Some of the arguments for such a standard are as follows:
Objective 3: Abstraction above raw decompilations
Although we expect decompiled neural networks to be much more interpretable than the original networks, we may wish to engage in further abstractions for two reasons:
The best abstractions are those that reduce [mathematical or semantic] description length as much as possible while sacrificing as little [mathematical or semantic] description accuracy as possible. We previously used sparse coding for this exact purpose (see section The Unreasonable Effectiveness of SAEs for Mechanistic interpretability), so perhaps we can use them for that purpose again. So, at risk of losing all personal credibility to suggest it, SAEs may be reusable on this level of abstraction[4]. It may be possible to train meta-SAEs to identify groups of transcoder features (which represent interactions between SAE features) that commonly activate together in different layers of the network (figure 5). The transcoder features in different layers could be concatenated together to achieve this, echoing the approach taken by Yun et al. (2021) (although they did not apply sparse coding to interactions between features in decompiled networks, only to raw activations at each layer). Going further still, it may be possible to climb to higher levels of abstraction using further sparse coding, which might describe interactions between circuits, and so on.
Objective 4: Deep Description
So far in this agenda, we haven’t really done any (semantic) ‘interpretation’ of networks. We’ve simply decompiled the networks, putting them in a format that’s easier to interpret. Now we’re ready to start semantically describing what the different parts of the decompiled network actually do.
In mechanistic interpretability, we want a mechanistic description of all the network’s features and their interactions. On a high level, it’s important to ask what we’re actually looking for here. What is a mechanistic description of a feature?
A complete mechanistic description of a feature is ideally a description of what causes it to activate and what it subsequently does. Sometimes it makes sense to describe what a feature does in terms of which kinds of input data make it activate (e.g. feature visualization, Olah et al., 2017). Other times it makes more sense to describe what a feature does in terms of the output it tends to lead to. Other times still, it is hard or incomplete to describe things in terms of either the input or output, and instead it only makes sense to describe what a feature does in terms of other hidden features.
There exists some previous work that aims to automate the labeling of features (e.g. Bills et al., 2023). But this work has only described neurons in terms of either the input or output of the network. These descriptions are shallow. Instead, we want deep descriptions. Deep descriptions iteratively build on shallow descriptions and bring in information about how features connect together and participate in particular circuits together.
Early ventures into deep description have already been made, but there is potentially much, much further to go. One of these early ventures is Cammarata et al. (2021) (Curve Circuits). In this work, they used feature visualization to get a first pass of shallow descriptions of all the relevant neurons. In the next iteration of description, they showed how features in one layer get used by particular weights to construct features in the next layer; in doing so, they showed that some ‘curve features’ were not merely excited by curves in particular orientations, but also inhibited by curves in opposite orientations, thus adding more semantic detail.
This foray into deep description showed how we can use descriptions to build on each other iteratively. But these were only an initial step into deep description. This example only explained a hidden feature (a curve) in terms of features (early curves) in a previous layer; it didn’t, for instance, ‘go backward’, explaining early curves in terms of the curves they participate in. Being so early in the network, this might not be as informative an exercise as going in the forward direction. But there will exist features, particularly those toward the output of the network, where it makes more sense to go in the backwards direction, explaining hidden features in terms of their downstream causes.
What description depths might we be able to achieve if we automate the description process, and what might automating such a process look like? Here is a sketch for how we might automate deeper description.
A sketch of an automated process for deep description: The Iterative-Forward-Backwards procedure
This procedure has three loops. Intuitively:
Suppose we have a network with L layers (where layer 0 is the input data and L is the output layer) and a number of repeats for the iterative loop, R. Then, slightly more formally:
When we say ‘Explain feature X in terms of features Y’, we’re leaving a lot undefined. This step is doing a lot of work. It may take several forms. For instance:
To add to the intuitions of what this procedure is doing, it is helpful to describe previous interpretability methods in terms of it (Figure 6):
I expect the procedure that we end up doing to look substantially different from this (and include a lot more detail). But this sketch is merely supposed to point toward algorithms that could let us automate a lot of semantic description in interpretability.
Objective 5: Mechanistic interpretability-based evals & other applications of mechanistic interpretability
If we figure out how to automate deep description of decompiled networks, then we’ll have satisfactory mechanistic interpretability. This could be used for a number of applications, including:
We think of mech-interp based model evaluations as falling into two broad categories:
I think AI safety would be in a pretty great place if we achieved these objectives. And, to me, most feel within reach - even on reasonably short timelines - though not for a single researcher or even a single research team. It will require a concentrated research program and an ecosystem of researchers. I hope some of them will find this roadmap useful. I plan to work on it over the next few years, although some deviations are inevitable. And if others are interested in collaborating on parts of it, I'd love to hear from you! Send me a message or join the #sparse-autoencoders channel on the Open Source Mechanistic Interpretability Slack workspace.
Acknowledgements: I'm very grateful for helpful discussions and useful feedback and comments on previous drafts, which greatly improved the quality of this post, from Marius Hobbhahn, Daniel Braun, Lucius Bushnaq, Stefan Heimersheim, Jérémy Scheurer, Jordan Taylor, Jake Mendel, and Nix Goldowsky-Dill.
The analogy between mechanistic interpretability and software reverse engineering
Mechanistic interpretability has been compared to software reverse engineering, where you start with a compiled program binary and try to reconstruct the software’s source code. The analogy is that a neural network is a program that we have to decompile and reverse engineer. On a high level, software reverse engineering comprises three steps, which (not coincidentally) neatly map onto the three steps of mechanistic interpretability:
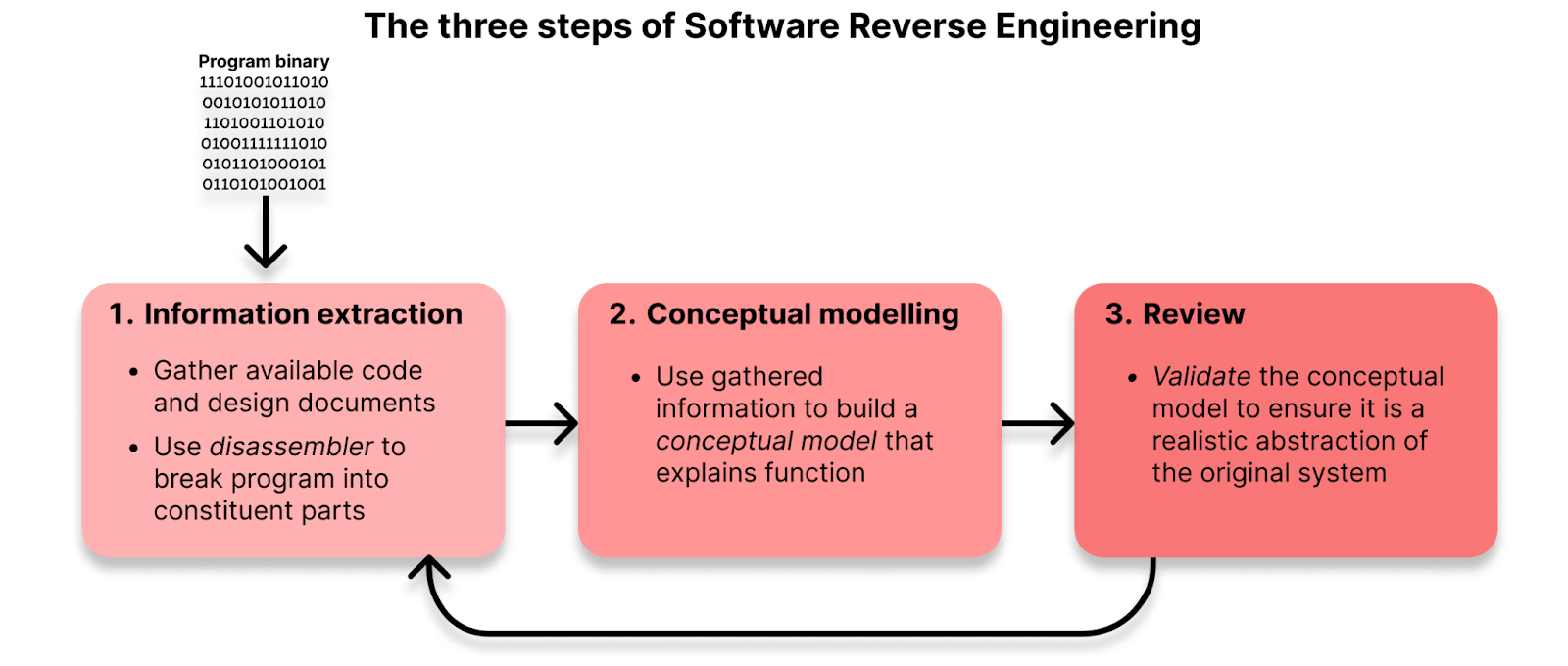
The three steps of Software Reverse engineering
1) Information extraction: In the first step, you gather what information you can that might help you understand what the program is doing. It might involve the use of a ‘disassembler’, breaks the program into its constituent parts by converting binary code into assembly code or converting machine language into a user friendly format (source). Or it may involve gathering other information such as design documents.
2) Conceptual modeling: Using the gathered information, create a conceptual model of what the program is doing. Software reverse engineering may implement this conceptual model in code that they write themselves or as a flow diagram.
3) Review: Then the conceptual model is validated to check how well it explains the original program. If it performs well, then there’s no need to keep going. If it performs poorly, then either new information will need to be extracted and/or a new conceptual model built.
To the best of my understanding, ARC's work on heuristic arguments could be described as aiming to formalize semantic description. This seems like a very good idea.
Previous interpretability research that aimed to use polytopes as the unit of explanation(Black et al., 2022) grouped polytopes using clustering methods, which, unlike SAEs, offer no way to ‘factorize’ a network’s function into compositional components. This yielded too long mathematical descriptions. However, it may be possible to group polytopes using other methods that are more compositional than clustering.
Although meta-SAEs might be useful here, it may not be advisable to use them. The inputs to meta-SAEs may become too wide for computational tractability, for instance. Alternatively, there may simply be better tools available: Meta-SAEs are solving a slightly different optimization problem compared with base/feature-level SAEs; on the base level, they’re solving a sparse optimization problem (where we’re looking for sparsely activating features in neural activations); on the meta-SAE level, it’s a doubly sparse optimization problem (where we’re looking for sparsely activating combinations of sparse feature activations). It’s plausible that other unsupervised methods are better suited to this task.