In this post, I will briefly give my criticism of Singular Learning Theory (SLT), and explain why I am skeptical of its significance. I will especially focus on the question of generalisation --- I do not believe that SLT offers any explanation of generalisation in neural networks. I will also briefly mention some of my other criticisms of SLT, describe some alternative solutions to the problems that SLT aims to tackle, and describe some related research problems which I would be more excited about.
(I have been meaning to write this for almost 6 months now, since I attended the SLT workshop last June, but things have kept coming in the way.)
For an overview of SLT, see this sequence. This post will also refer to the results described in this post, and will also occasionally touch on VC theory. However, I have tried to make it mostly self-contained.
The Mystery of Generalisation
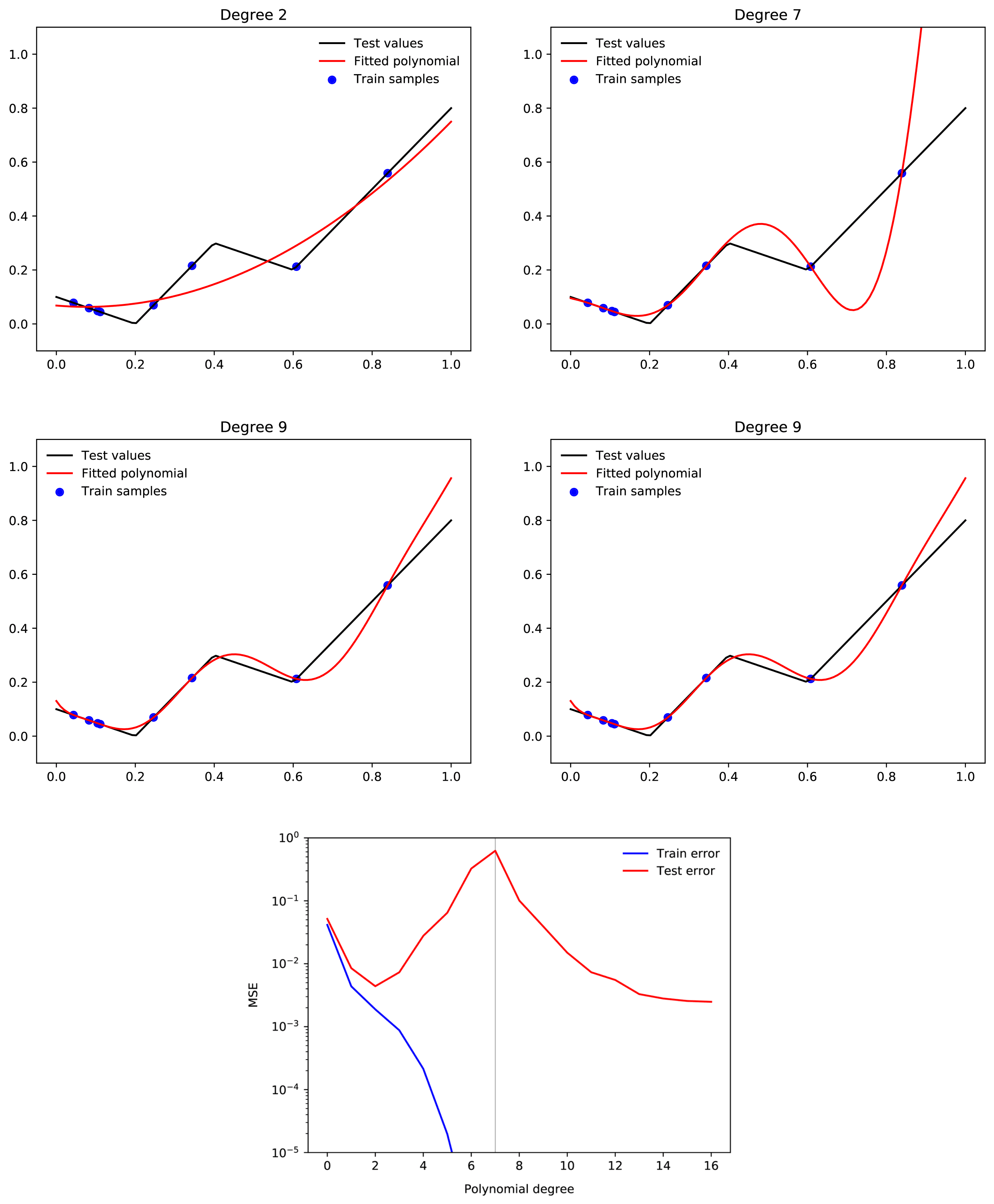
First of all, what is the mystery of generalisation? The issue is this; neural networks are highly expressive, and typically overparameterised. In particular, when a real-world neural network is trained on a real-world dataset, it is typically the case that this network is able to express many functions which would fit the training data well, but which would generalise poorly. Moreover, among all functions which do fit the training data, there are more functions (by number) that generalise poorly, than functions that generalise well. And yet neural networks will typically find functions that generalise well. Why is this?
To make this point more intuitive, suppose we have a 500,000-degree polynomial, and that we fit this to 50,000 data points. In this case, we have 450,000 degrees of freedom, and we should by default expect to end up with a function which generalises very poorly. But when we train a neural network with 500,000 parameters on 50,000 MNIST images, we end up with a neural network that generalises well. Moreover, adding more parameters to the neural network will typically make generalisation better, whereas adding more parameters to the polynomial is likely to make generalisation worse. Why is this?
A simple hypothesis might be that some of the parameters in a neural network are redundant, so that even if it has 500,000 parameters, the dimensionality of the space of all functions which it can express is still less than 500,000. This is true. However, the magnitude of this effect is too small to solve the puzzle. If you get the MNIST training set, and assign random labels to the test data, and then try to fit the network to this function, you will find that this often can be done. This means that while neural networks have redundant parameters, they are still able to express more functions which generalise poorly, than functions which generalise well. Hence the puzzle.
The anwer to this puzzle must be that neural networks have an inductive bias towards low-complexity functions. That is, among all functions which fit a given training set, neural networks are more likely to find a low-complexity function (and such functions are more likely to generalise well, as per Occam's Razor). The next question is where this inductive bias comes from, and how it works. Understanding this would let us better understand and predict the behaviour of neural networks, which would be very useful for AI alignment.
I should also mention that generalisation only is mysterious when we have an amount of training data that is small relative to the overall expressivity of the learning machine. Classical statistical learning theory already tells us that any sufficiently well-behaved learning machine will generalise well in the limit of infinite training data. For an overview of these results, see this post. Thus, the question is why neural networks can generalise well, given small amounts of training data.
The SLT Answer
SLT proposes a solution to this puzzle, which I will summarise below. This summary will be very rough --- for more detail, see this sequence and this post.
First of all, we can decompose a neural network into the following components:
1. A parameter space, , corresponding to all possible assignments of values to the weights.
2. A function space, , which contains all functions that the neural network can express.
3. A parameter-function map, , which associates each parameter assignment with a function .
SLT models neural networks (and other learning machines) as Bayesian learners, which have a prior over , and update this prior based on the training data in accordence with Bayes' theorem. Moreover, it also assumes that the loss (ie, the likelihood) of the network is analytic in . This essentially amounts to a kind of smoothness assumption. Moreover, as is typical in the statistical learning theory literature, SLT assumes that the training data (and test data) is drawn i.i.d. from some underlying data distribution (though there are some ways to relax this assumption).
We next observe that a neural network typically is overparameterised, in the sense that there for a particular function typically will be many different parameter assignments such that . For example, we can almost always rescale different parameters without affecting the input-output behaviour of a neural network. There can also be symmetries --- for example, we can always re-shuffle the neurons in a neural network, which would also never affect its input-output behaviour. Finally, there can be redundancies, where some parameters or parts of the network are not used for any piece of training data.
These symmetries and redundancies lead to paths or valleys of constant loss through the loss landscape, which are created by the fact that the parameters can be continuously moved in some direction without affecting the function expressed by the network.
Next, note that if we are in such a valley, then we can think of the neural network as having a local "effective parameter dimension" that is lower than the full dimensionality of . For example, if has 10 dimensions, but there is a (one-dimensional) valley along which (and hence , and hence the loss) is constant, then the effective parameter dimension of the network is only 9. Moreover, this "effective parameter dimension" can be different in different regions of ; if two one-dimensional valleys intersect, then the effective parameter dimension at that point is only 8, since we can move in two directions without changing . And so on. SLT proposes a measurement, called the RLCT, which provides a continuous quantification of the "effective parameter dimension" at different points. If a point or region has a lower RLCT, then that means that there are more redundant parameters in that region, and hence that the effective parameter dimension is lower.
SLT provides a theorem which says that, under the assumptions of the theory, points with low RLCT will eventually dominate the Bayesian posterior, in the limit of infinite data. It is worth noting that this theorem does not require any strong assumptions about the Bayesian prior over . This should be reasonably intuitive. Very loosely speaking, regions with a low RLCT have a larger "volume" than regions with high RLCT, and the impact of this fact eventually dominates other relevant factors. (However, this is a very loose intuition, that comes with several caveats. For a more precise treatment, see the posts linked above.)
Moreover, since regions with a low RLCT roughly can be thought of as corresponding to sub-networks with fewer effective parameter dimensions, we can (perhaps) think of these regions as corresponding to functions with low complexity. Putting this together, it seems like SLT says that overparameterised Bayesian learning machines in the limit will pick functions that have a low complexity, and such functions should also generalise well. Indeed, SLT also provides a theorem which says that the Bayes generalisation loss eventually will be low, where the Bayes generalisation loss is a Bayesian formalisation of prediction error. So this solves the mystery, does it not?
Why the SLT Answer Fails
The SLT answer does not succeed at explaining why neural networks generalise. The easiest way to explain why this is the case will probably be to provide an example. Suppose we have a Bayesian learning machine with 15 parameters, whose parameter-function map is given by
and whose loss function is the KL divergence. This learning machine will learn 4-degree polynomials. Moreover, it is overparameterised, and its loss function is analytic in its parameters, etc, so SLT will apply to it.
For the sake of simplicity suppose we have a single data point, . There is an infinite number of functions which can express that fits this training data, but some natural solutions include:
Intuitively, the best solution is , because this solution has the lowest complexity. However, the solution with the lowest RLCT is in this case . This is fairly easy to see; around , there are many directions in the parameter-space along which the function remains unchanged (and hence, along which loss is constant), whereas around , there are fewer such directions. Hence, this learning machine will in fact be biased towards solutions with high complexity, rather than solutions with low complexity. We should therefore expect it to generalise worse, rather than better, than a simple non-overparameterised learning machine.
To make this less of a toy problem, we can straightforwardly extend the example to a polyfit algorithm with (say) 500,000 parameters, and a dataset with 50,000 data points. The same dynamic will still occur.
Of course, if we get enough training data, then we will eventually rule out all functions that generalise poorly, and start to generalise well. However, this is not mysterious, and is already fully adequately explained by classical statistical learning theory. The question is why we can generalise well, when we have relatively small amounts of training data.
The fundamental thing that goes wrong here is the assumption that regions with a low RLCT correspond to functions that have a low complexity. There is no necessary connection between these two things --- as demonstrated by the example above, we can construct learning machines where a low RLCT corresponds to high complexity, and (using an analogous stategy), we can also construct learning machines where a low RLCT corresponds to low complexity. We can therefore not go between these two things, without making any further assumptions.
To state this differently, the core problem we are running up against is this:
- To understand the generalisation behaviour of a learning machine, we must understand its inductive bias.
- The inductive bias of a parameterised Bayesian learning machine is determined by (a) its Bayesian prior over the parameter-space, and (b) its parameter-function map.
- SLT abstracts away from both the prior and the parameter-function map.
- Hence, SLT is at its core unable to explain generalisation behaviour.
The generalisation bound that SLT proves is a kind of Bayesian sleight of hand, which says that the learning machine will have a good expected generalisation relative to the Bayesian prior that is implicit in the learning machine itself. However, this does basically not tell us anything at all, unless we also separately believe that the Bayesian prior that is implicit in the learning machine also corresponds to the prior that we, as humans, have regarding the kinds of problems that we believe that we are likely to face in the real world.
Thus, SLT does not explain generalisation in neural networks.
The Actual Solution
I worked on the issue of generalisation in neural networks a few years ago, and I believe that I can provide you with the actual explanation for why neural networks generalise. You can read this explanation in depth here, together with the linked posts. In summary:
- The parameter-function map of neural networks is exponentially biased towards functions with low complexity, such that functions in with low (Kolmogorov) complexity have exponentially more parameter assignments in . Very roughly, to a first-order approximation, if we randomly sample a parameter assignment , then the probability that we will obtain a particular function is approximately on the order of , where is the complexity of .
- Training with SGD is (to a first-order approximation) similar to uniform sampling from all parameters that fit the training data (considering only parameters sufficiently close to the origin).
Together, these two facts imply that we are likely to find a low-complexity function that fits the training data, even though the network can express many high-complexity functions which also fit the training data. This, in turn, explains why neural networks generalise well, even when they are overparameterised.
To fix the explanation provided by SLT, we need to add the assumption that the parameter-function map is biased towards low-complexity functions, and that regions with low RLCT typically correspond to functions with low complexity. Both of these assumptions are likely to be true. However, if we add these assumptions, then the machinery of SLT is no longer needed, as demonstrated by the explanation above.
Other Issues With SLT
Besides the fact that SLT does not explain generalisation, I think there are also other issues with SLT. First of all, SLT is largely is based on examining the behaviour of learning machines in the limit of infinite data. I claim that this is fairly uninteresting, because classical statistical learning theory already gives us a fully adequate account of generalisation in this setting which applies to all learning machines, including neural networks. Again, I have written an overview of some of these results here. In short, generalisation in the infinite-data limit is not mysterious.
Next, one of the more tantalising promises of SLT is that the posterior will eventually be dominated by singular points with low RLCT, which correspond to places where multiple valleys of low loss intersect. If this is true, then that suggests that we may be able to understand the possible generalisation behaviours of a neural network by examining a finite number of highly singular points. However, I think that this claim also is false. In particular, the result which says that these intersections eventually will dominate the posterior is heavily dependent on the assumption that the loss landscape is analytic, together with the fact that we are examining the behaviour of the system in the limit of infinite data. If we drop one or both of these assumptions, then the result may no longer hold. This is easy to verify. For example, suppose we have a two-dimensional parameter space, with two parameters , , and that the loss is given by . Here, the most singular point is . However, if we do a random walk in this loss landscape, we will not be close to most of the time. It is true that we will be close to more often than we will be close to any other individual point with low loss, but will not dominate the posterior. This fact is compatible with the mathematical results of SLT, because if we create an analytic approximation of , then this approximation with be "flatter" around , and this flatness creates a basin of attraction that it is easy to get stuck in, but difficult to leave. Moreover, if a neural network uses ReLu activations, then its loss function will not be analytic in the parameters. It is thus questionable to what extent this dynamic will hold in practice.
I should also mention a common piece of criticism of SLT which I do not agree with. SLT models neural networks as Bayesian learning machines, whereas they in reality are trained by gradient descent, rather than Bayesian updating. I do not think that this is a significant issue, because gradient descent is empirically quite similar to Bayesian sampling. For details, see again this post.
SLT is also sometimes criticised because it assumes that the loss function is analytic in the parameters of the network. Moreover, if we use ReLu activations, then this is not the case. I do not think that this necessarily is too concerning, because ReLu functions can be approximated by some analytic activation functions. However, when this assumption is combined with the infinite-data assumption, then we may run into issues, as I outlined above.
Some Research I Would Be Excited About
I worked on issues related to generalisation and the science of deep learning a few years ago. I have not actively worked on it very much since, and instead prioritised research around reward learning and outer alignment. However, there are still multiple research directions in this area that I think are promising, and which I would encourage people to explore, but which do not fall under the umbrella of SLT.
First of all, the results presented in this line of research suggest that the generalisation behaviour (and hence the inductive bias) of neural networks is primarily determined by their parameter-function map. This should in fact be quite intuitive, because;
- If we change the architecture of a neural network, then this can often have a very large impact on its generalisation behaviour and inductive bias. For example, fully connected networks and CNNs have very different generalisation behaviour. Moreover, changing the architecture is equivalent to changing the parameter-function map.
- If we change other components of a neural network, such as what type of optimiser we are using, then this will typically have a comparatively small impact on its generalisation behaviour and inductive bias.
Therefore, if we want to understand generalisation and inductive bias, then we should study the properties of the parameter-function map. Moreover, there are many open questions on this topic, that it would be fairly tractable to tackle. For example, the results in this post suggest that the parameter-function maps of many different neural network architectures are exponentially biased towards low complexity. However, they do not give a detailed answer to the question of precisely which complexity measure they minimise --- they merely show that this result holds for many different complexity measures. For example, I would expect that fully connected neural networks are biased towards functions with low Boolean circuit complexity, or something very close to that. Verifying this claim, and deriving similar results about other kinds of network architectures, would make it easier to reason about what kinds of functions we should expect a neural network to be likely or unlikely to learn. This would also make it easier to reason about out-of-distribution generalisation, etc.
Another area which I think is promising is the study of random networks and random features. The results in this post suggest that training a neural network is functionally similar to randomly initialising it until you find a function that fits the training data. This suggests that we may be able to draw conclusions about what kinds of features a neural network is likely to learn, based on what kinds of features are likely to be created randomly. There are also other results that are relevant to this topic. For example, this paper shows that a randomly initialised neural network with high probability contains a sub-network that fits the training data well and generalises well. Specifically, if we randomly initialise a neural network, and then use a traning method which only allows us to set weights to 0, then we will find a reasonably good network. Note that this result is not the same as the result from the Lottery Ticket paper. Similarly, the fact that sufficiently large extreme learning machines attain similar performance to neural networks that have been trained normally, also suggests that this may be a fruitful angle of attack.
Another interesting question might be to try to quantify exactly how much of the generalisation behaviour is determined by different sources. For example, how much data augmentation would we need to do, before the effect of that data augmentation is comparable to the effect that we would get from changing the optimiser, or changing the network architecture? Etc.
What I Think SLT Can Do
This being said, I think there are many questions that are relevant to generalisation and inductive bias, which I think SLT may be able to help with. For example, it seems like it would be difficult to get a good angle on the question of phase shifts based on studying the parameter-function map. Moreover, SLT is a good candidate for a framework from which to analyse these questions. Therefore, I would not be that surprised if SLT could provide a good account of phenomena such as double descent or grokking, for example.
Closing Remarks
In summary, I think that the significance of SLT is somewhat over-hyped at the moment. I do not think that SLT will provide anything like a "unified theory of deep learning", and specifically, I do not think that it can explain generalisation or inductive bias in a satisfactory way. I still think there are questions that SLT can help to solve, but I see its significance as being more limited to certain specific problems.
If there are any important errors in this post, then please let me know in the comments.
EDIT: For those reading on the Alignment Forum, I want to highlight this conversation thread, and especially this comment; Daniel Murfet clarified my point very well.
Did you see my earlier post? Your explanation seems related to mine, but I also said that generalization capability depends on activation function choice. (There are lots of activation functions that don't work for neural networks, in different ways.)
I think I recall reading that, but I'm not completely sure.
Note that the activation function affects the parameter-function map, and so the influence of the activation function is subsumed by the general question of what the parameter-function map looks like.