See livestream, site, OpenAI thread, Nat McAleese thread.
OpenAI announced (but isn't yet releasing) o3 and o3-mini (skipping o2 because of telecom company O2's trademark). "We plan to deploy these models early next year." "o3 is powered by further scaling up RL beyond o1"; I don't know whether it's a new base model.
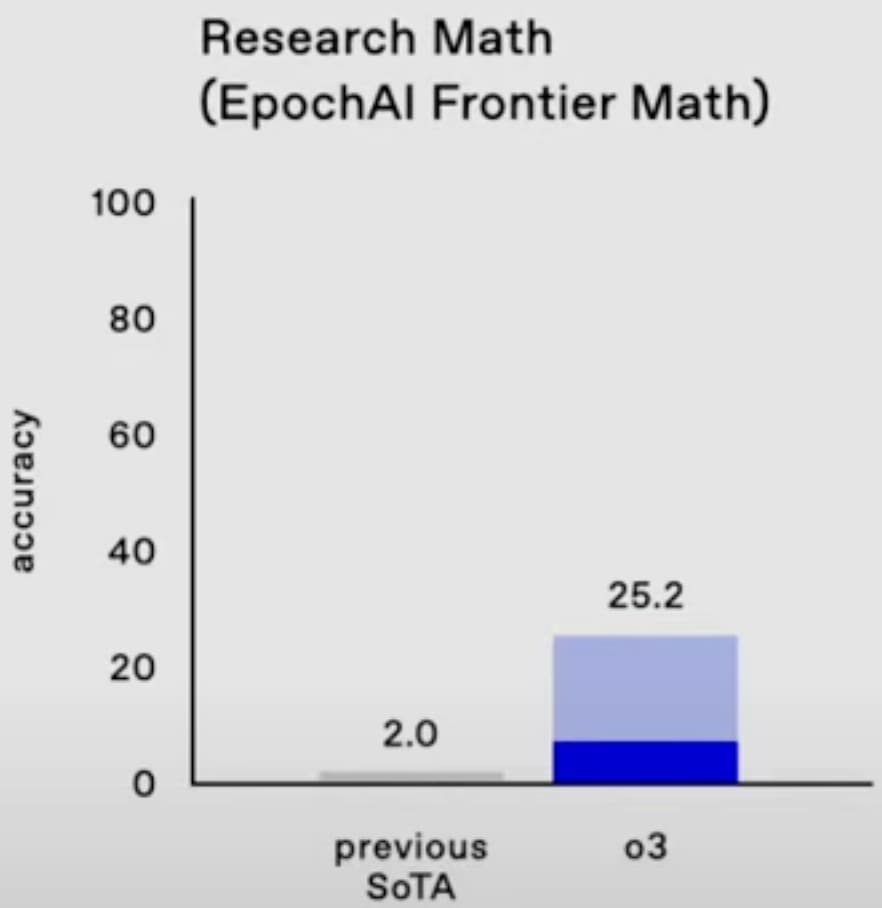
o3 gets 25% on FrontierMath, smashing the previous SoTA. (These are really hard math problems.[1]) Wow. (The dark blue bar, about 7%, is presumably one-attempt and most comparable to the old SoTA; unfortunately OpenAI didn't say what the light blue bar is, but I think it doesn't really matter and the 25% is for real.[2])
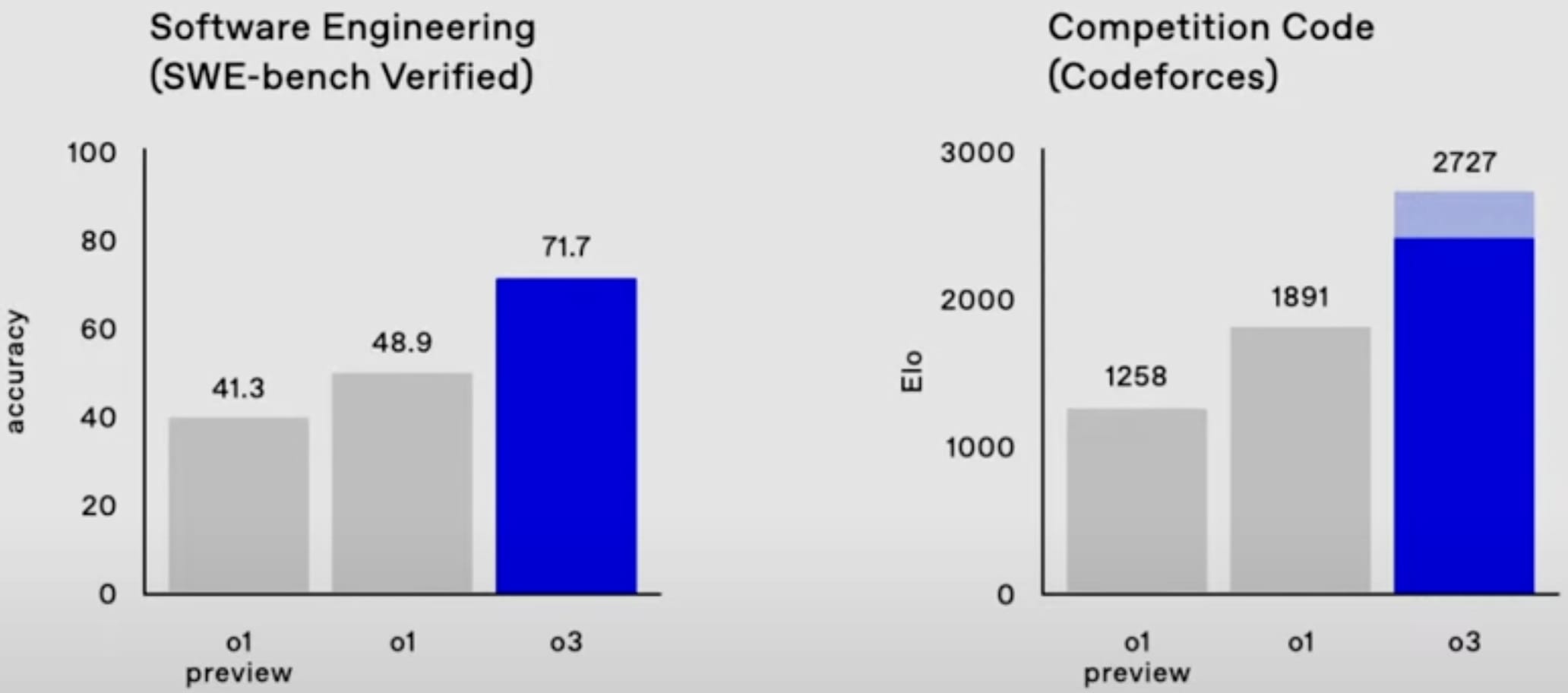
o3 also is easily SoTA on SWE-bench Verified and Codeforces.
It's also easily SoTA on ARC-AGI, after doing RL on the public ARC-AGI problems[3] + when spending $4,000 per task on inference (!).[4] (And at less inference cost.)
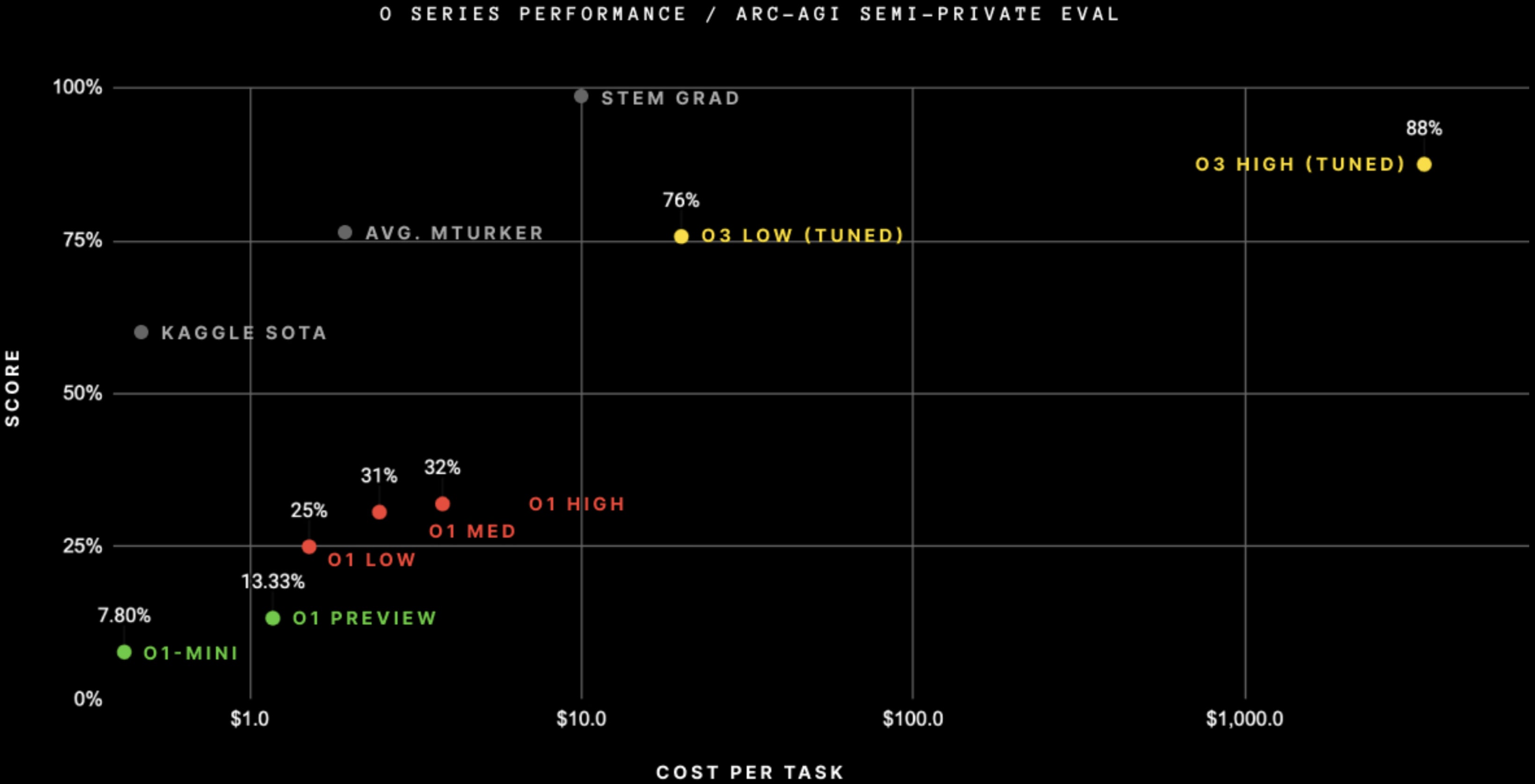
ARC Prize says:
At OpenAI's direction, we tested at two levels of compute with variable sample sizes: 6 (high-efficiency) and 1024 (low-efficiency, 172x compute).
OpenAI has a "new alignment strategy." (Just about the "modern LLMs still comply with malicious prompts, overrefuse benign queries, and fall victim to jailbreak attacks" problem.) It looks like RLAIF/Constitutional AI. See Lawrence Chan's thread.[5]
OpenAI says "We're offering safety and security researchers early access to our next frontier models"; yay.
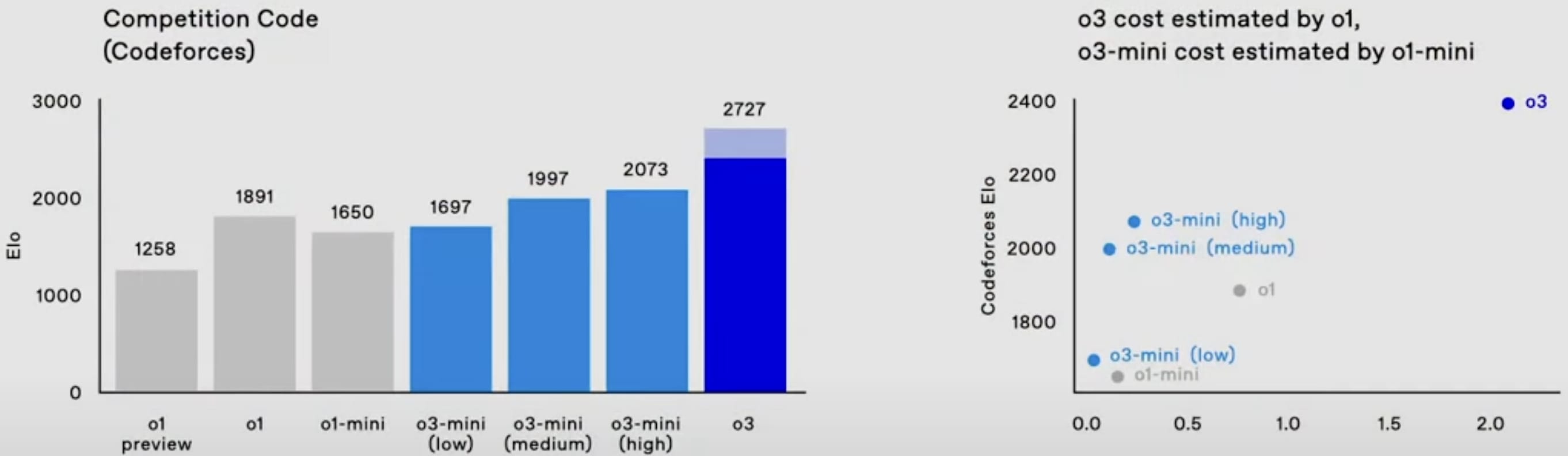
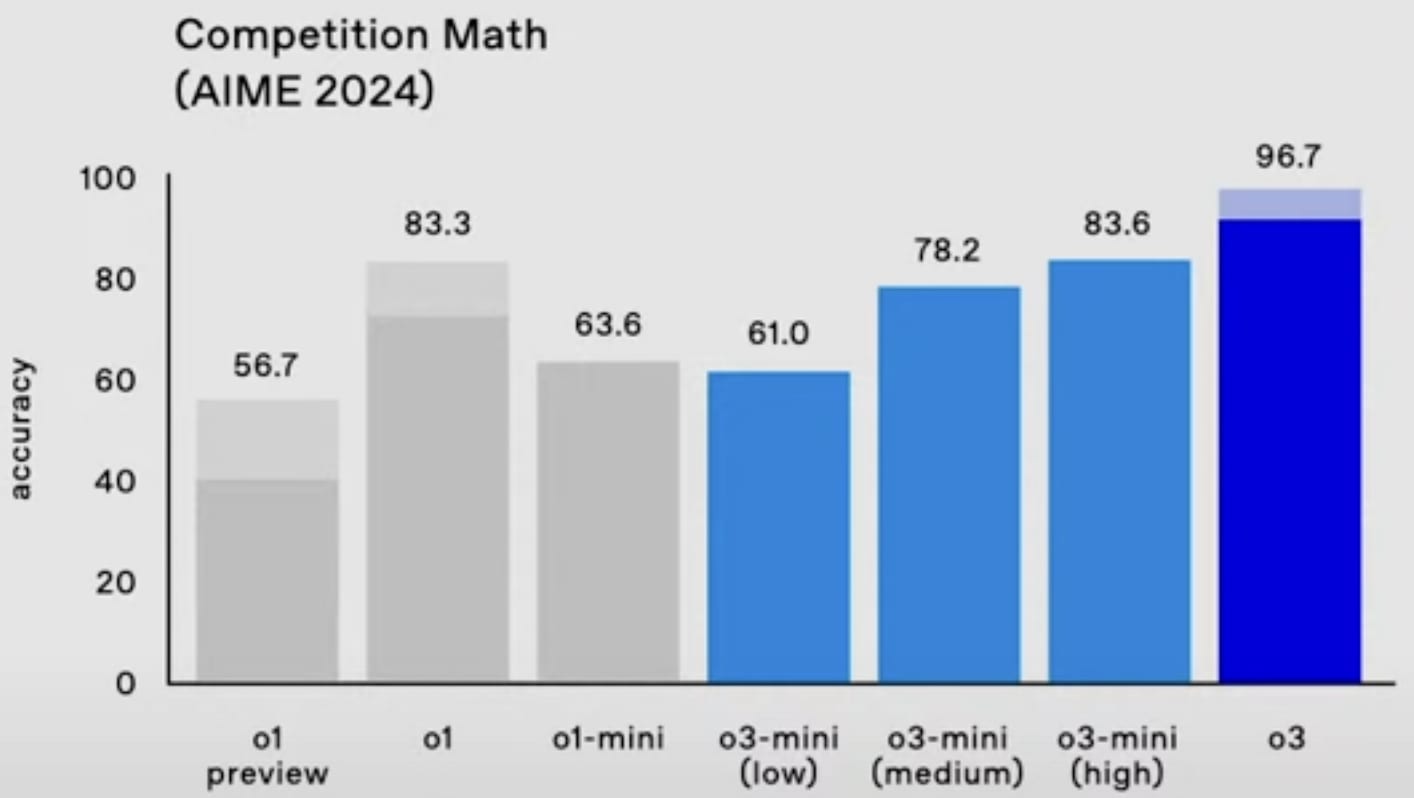
o3-mini will be able to use a low, medium, or high amount of inference compute, depending on the task and the user's preferences. o3-mini (medium) outperforms o1 (at least on Codeforces and the 2024 AIME) with less inference cost.
GPQA Diamond:
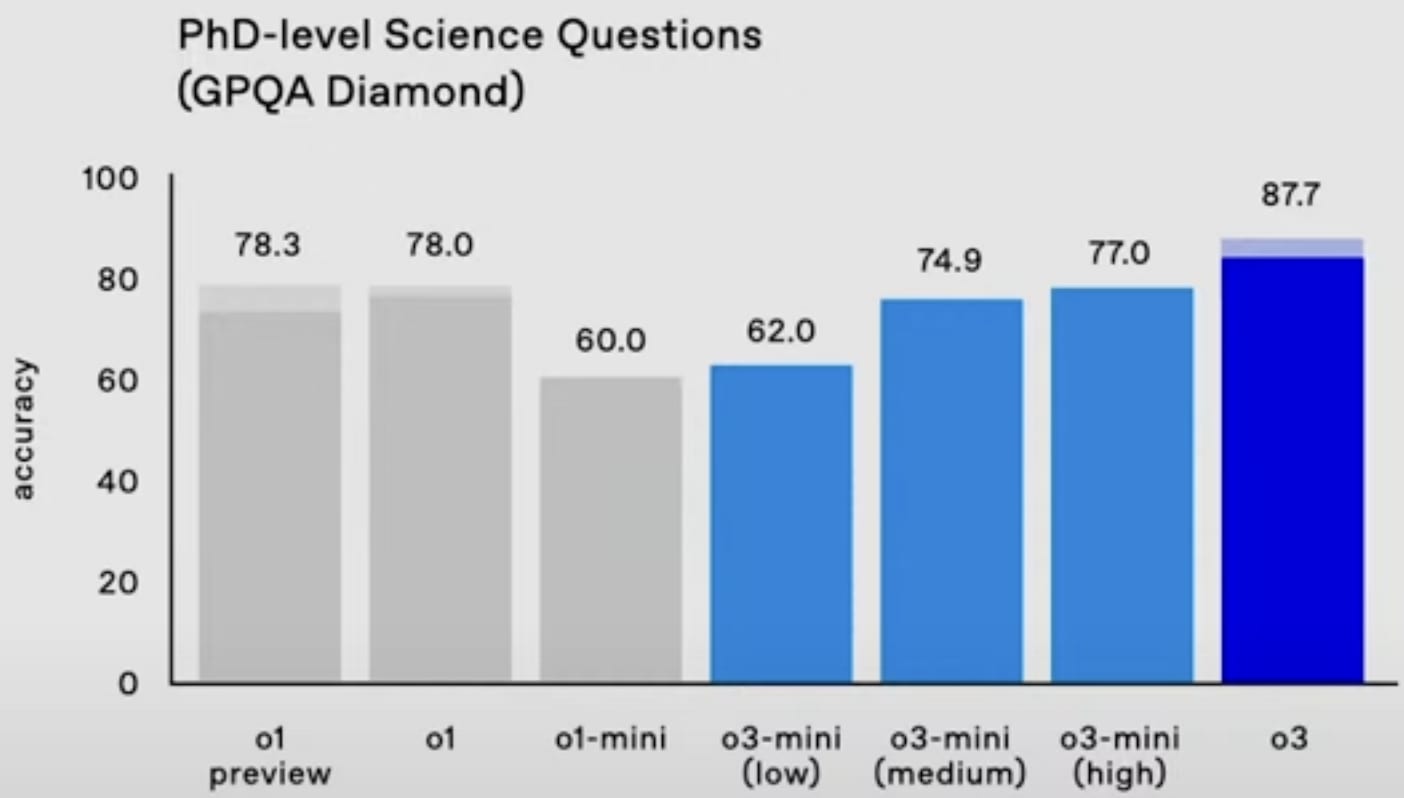
- ^
Update: most of them are not as hard as I thought:
There are 3 tiers of difficulty within FrontierMath: 25% T1 = IMO/undergrad style problems, 50% T2 = grad/qualifying exam style [problems], 25% T3 = early researcher problems.
- ^
My guess is it's consensus@128 or something (i.e. write 128 answers and submit the most common one). Even if it's pass@n (i.e. submit n tries) rather than consensus@n, that's likely reasonable because I heard FrontierMath is designed to have easier-to-verify numerical-ish answers.
Update: it's not pass@n.
- ^
Correction: no RL! See comment.
Correction to correction: nevermind, I'm confused.
- ^
It's not clear how they can leverage so much inference compute; they must be doing more than consensus@n. See Vladimir_Nesov's comment.
- ^
Update: see also disagreement from one of the authors.
As I say here https://x.com/boazbaraktcs/status/1870369979369128314
Constitutional AI is a great work but Deliberative Alignment is fundamentally different. The difference is basically system 1 vs system 2. In RLAIF ultimately the generative model that answers user prompt is trained with (prompt, good response, bad response). Even if the good and bad responses were generated based on some constitution, the generative model is not taught the text of this constitution, and most importantly how to reason about this text in the context of a particular example.
This ability to reason is crucial to OOD performance such as training only on English and generalizing to other languages or encoded output.
See also https://x.com/boazbaraktcs/status/1870285696998817958
Hi Boaz, first let me say that I really like Deliberative Alignment. Introducing a system 2 element is great, not only for higher-quality reasoning, but also for producing a legible, auditable chain of though. That said, I have a couple questions I'm hoping you might be able to answer.
- I read through the model spec (which DA uses, or at least a closely-related spec). It seems well-suited and fairly comprehensive for answering user questions, but not sufficient for a model acting as an agent (which I expect to see more and more). An agent acting in the real
... (read more)