This model seems quite a bit different from mine, which is that FAI research is about reducing FAI to an AGI problem, and solving AGI takes more work than doing this reduction.
More concretely, consider a proposal such as Paul's reflective automated philosophy method, which might be able to be implemented using epsiodic reinforcement learning. This proposal has problems, and it's not clear that it works -- but if it did, then it would have reduced FAI to a reinforcement learning problem. Presumably, any implementations of this proposal would benefit from any reinforcement learning advances in the AGI field.
Of course, even if we a proposal like this works, it might require better or different AGI capabilities from UFAI projects. I expect this to be true for black-box FAI solutions such as Paul's. This presents additional strategic difficulties. However, I think the post fails to accurately model these difficulties. The right answer here is to get AGI researchers to develop (and not publish anything about) enough AGI capabilities for FAI without running a UFAI in the meantime, even though the capabilities to run it exist.
Assuming that this reflective automated philosophy system doesn't work, it could still be the case that there is a different reduction from FAI to AGI that can be created through armchair technical philosophy. This is often what MIRI's "unbounded solutions" research is about: finding ways you could solve FAI if you had a hypercomputer. Once you find a solution like this, it might be possible to define it in terms of AGI capabilities instead of hypercomputation, and at that point FAI would be reduced to an AGI problem. We haven't put enough work into this problem to know that a reduction couldn't be created in, say, 20 years by 20 highly competent mathematician-philosophers.
In the most pessimistic case (which I don't think is too likely), the task of reducing FAI to an AGI problem is significantly harder than creating AGI. In this case, the model in the post seems to be mostly accurate, except that it neglects the fact that serial advances might be important (so we get diminishing marginal progress towards FAI or AGI per additional researcher in a given year).
[Edited: replaced Gremaining with Fremaining, which is what I originally meant]
Thanks for the comment jessicat! I haven't read those posts yet, will do more research on reducing FAI to an AGI problem.
A few responses & clarifications:
Our framework assumes the FAI research would happen before AGI creation. If we can research how to reduce FAI to an AGI problem in a way that would reliably make a future AGI friendly, then that amount of research would be our variable Fremaining. If that is quite easy to do, then that's fantastic; an AI venture would have an easy time, and the leakage ratio would be low enough to not have to worry about. Additional required capabilities that we'll find out we need would be added to Fremaining.
"I think the post fails to accurately model these difficulties." -> This post doesn't attempt to model the individual challenges to understand how large Fremaining actually is. That's probably a more important question than what we addressed, but one for a different model.
"The right answer here is to get AGI researchers to develop (and not publish anything about) enough AGI capabilities for FAI without running a UFAI in the meantime, even though the capabilities to run it exist." -> This paper definitely advocates for AGI researchers to develop FAI research while not publishing much AGI research. I agree that some internal AGI research will probably be necessary, but hope that it won't be a whole lot. If the tools to create an AGI were figured out, even if they were kept secret by an FAI research group, I would be very scared. Those would be the most important and dangerous secrets of all time, and I doubt they could be kept secret for very long (20 years max?)
"In this case, the model in the post seems to be mostly accurate, except that it neglects the fact that serial advances might be important (so we get diminishing marginal progress towards FAI or AGI per additional researcher in a given year)."
-> This paper purposefully didn't model research effort, but rather, abstract units of research significance. "the numbers of rg and rf don't perfectly correlate with the difficulty to reach them. It may be that we have diminishing marginal returns with our current levels of rg, so similar levels of rf will be easier to reach."
A model that would also take into account the effort required would require a few more assumptions and additional complexity. I prefer to start simple and work from there, so we at least know what people do agree on before adding additional complexity.
Thanks for the detailed response! I do think the framework can still work with my assumptions. The way I would model it would be something like:
Also, it seems I had misinterpreted the part about rg and rf, sorry about that!
Good point.
I guess the most controversial, and hopefully false, assumption of this paper is #3: 'If Gremaining is reached before Fremaining, a UFAI will be created. If after, an FAI will be created.'
This basically is the AI Foom scenario, where the moment an AGI is created, it will either kill us or all or bring about utopia (or both).
If this is not the case, and we have a long time to work with the AGI as it develops to make sure it is friendly, then this model isn't very useful.
If we do assume these assumptions, I would also expect that we will reach Gremaining before Fremaining, or at least that a private organization will end up doing so. However, I am also very skeptical in the power of secrets. I think I find us reaching Fremaining first more likely than a private institution reaching Gremaining first, but hiding it until it later reaches Fremaining, though both may be very slim. If the US military or a similar group with a huge technological and secretive advantage were doing this, there could be more of a chance. This definitely seems like a game of optimizing small probabilities.
Either way, I think we definitely would agree here that the organization developing these secrets can strategically choose projects that deliver the high amounts of FAI research relative to the amount AGI research they will have to keep secretive. Begin with the easy, non-secretive wins and work from there.
We may need the specific technology to create a paperclip maximizer before we make an FAI, but if we plan correctly, we hopefully will be really close to reaching an FAI by that point.
This basically is the AI Foom scenario, where the moment an AGI is created, it will either kill us or all or bring about utopia (or both).
The question is not "if". The questions are "how quickly" and "to what height". An AI capable of self-improving to world-destroying levels within moments is plainly unrealistic. An AI capable of self-improving to dangerous levels (viz: levels where it can start making humans do the dangerous work for it) in the weeks, months, or even years it would take a team of human operators to cross-examine the formally unspecified motivation engines for Friendliness is dangerously realistic.
I feel like this still fits their model pretty well. You need Fremaining time to find AGI->FAI solution, while there is Gremaining time before someone builds an AGI.
This is often what MIRI's "unbounded solutions" research is about: finding ways you could solve FAI if you had a hypercomputer.
Sorry to criticize out of the blue, but I think that's a very bad idea. To wit, "Assume a contradiction, prove False, and ex falso quodlibet." If you start by assuming a hypercomputer and reason mathematically from there, I think you'll mostly derive paradox theorems and contradictions.
I should be specific that the kinds of results we want to get are those where you could, in principle, use a very powerful computer instead of a hypercomputer. Roughly, the unbounded algorithm should be a limit of bounded algorithms. The kinds of allowed operations I am thinking about include:
In all these cases, you can get arbitrarily good approximations using bounded algorithms, although they might require a very large amount of computation power. I don't think things like this would lead to contradictions if you did them correctly.
Ah, ok. So you're saying, "Let's do FAI by first assuming we have an incomplete infinity of processing power to apply -- thus assuming the Most Powerful Possible Agent as our 'adversary' to be 'tamed'." Hence the continual use of AIXI?
Yes, something like that, although I don't usually think of it as an adversary. Mainly it's so I can ask questions like "how could a FAI model its operator so that it can infer the operator's values from their behavior?" without getting hung up on the exact representation of the model or how the model is found. We don't have any solution to this problem, even if we had access to a probabilistic program induction black box, so it would be silly to impose the additional restriction that we can't give the black box any induction problems that are too hard.
That said, bounded algorithms can be useful as inspiration, even for unbounded problems. For example, I'm currently looking at ways you could use probabilistic programs with nested queries to model Vingean reflection.
For example, I'm currently looking at ways you could use probabilistic programs with nested queries to model Vingean reflection.
ZOMFG, can you link to a write-up? This links up almost perfectly with a bit of research I've been wanting to do.
Yes, something like that, although I don't usually think of it as an adversary.
I more meant "adversary" in crypto terms: something that can and will throw behavior at us we don't want unless we formally demonstrate that it can't.
That said, bounded algorithms can be useful as inspiration, even for unbounded problems.
I have a slightly different perspective on the bounded/unbounded issue. Have you ever read Jaynes' Probability Theory? Well, I never got up to the part where he undoes paradoxes, but the way he preached about it sunk in: a paradox will often arise because you passed to the limit too early in your proof or construction. I've also been very impressed by the degree to which resource-rational and bounded-rational models of cognition explain facts about real minds that unbounded models either can't explain at all or write off as "irrational".
To quote myself (because it's applicable here but the full text isn't done):
The key is that AIXI evaluates K(x), the Kolmogorov complexity of each possible Turing-machine program. This function allows a Solomonoff Inducer to perfectly separate the random information in its sensory data from the structural information, yielding an optimal distribution over representations that contain nothing but causal structure. This is incomputable, or requires infinite algorithmic information -- AIXI can update optimally on sensory information by falling back on its infinite computing power.
In my perspective, at least, AIXI is cheating by assuming unbounded computational power, with the result that even the "bounded" and "approximate" AIXI_{tl} runs in "optimal" time modulo an astronomically-large additive constant. So I think that a "bottom-up" theory of bounded-rational reasoning or resource-rational reasoning - one that starts with the assumption we have strictly bounded finite compute-power the same way probability theory assumes we have strictly bounded finite information - will work a lot better to explain how to scale up by "passing to the limit" at the last step.
Which then goes to that research I want to do: I think we could attack logical uncertainty and probabilistic reflection by finding a theory for how to trade finite amounts of compute time for finite amounts of algorithmic information. The structure currently in my imagination is a kind of probability mixed with domain theory: the more computing power you add, the more certain you can become about the results of computations, even if you still have to place some probability mass on \Bot (bottom). In fact, if you find over time that you place more probability mass on \Bot, then you're acquiring a degree of belief that the computation in question won't terminate.
I think this would then mix with probabilistic programming fairly well, and also have immediate applications to assigning rational, well-behaved degrees of belief to "weird" propositions like Goedel Sentences or Halting predicates.
(BTW: here's a writeup of one of my ideas for writing planning queries that you might be interested in)
Often we want a model where the probability of taking action a is proportional to p(a)e^E[U(x, a)], where p is the prior over actions, x consists of some latent variables, and U is the utility function. The straightforward way of doing this fails:
query {
. a ~ p()
. x ~ P(x)
. factor(U(x, a))
}
Note that I'm assuming factor takes a log probability as its argument. This fails due to "wishful thinking": it tends to prefer riskier actions. The problem can be reduced by taking more samples:
query {
. a ~ p()
. us = []
. for i = 1 to n
. . x_i ~ P(x)
. . us.append(U(x_i, a))
. factor(mean(us))
}
This does better, because since we took multiple samples, mean(us) is likely to be somewhat accurate. But how do we know how many samples to take? The exact query we want cannot be expressed with any finite n.
It turns out that we just need to sample n from a Poisson distribution and make some more adjustments:
query {
. a ~ p()
. n ~ Poisson(1)
. for i = 1 to n
. . x_i ~ P(x)
. . factor(log U(x_i, a))
}
Note that U must be non-negative. Why does this work? Consider:
P(a) α p(a) E[e^sum(log U(x_i, a) for i in range(n))]
= p(a) E[prod(U(x_i, a) for i in range(n))]
= p(a) E[ E[prod(U(x_i, a) for i in range(n)) | n] ]
[here use the fact that the terms in the product are independent]
= p(a) E[ E[U(x, a)]^n ]
= p(a) sum(i=0 to infinity) E[U(x, a)]^i / i!
[Taylor series!]
= p(a) e^E[U(x, a)]
Ideally, this technique would help to perform inference in planning models where we can't enumerate all possible states.
Interesting! How does that compare to the usual implementations of planning as probabilistic inference, as exemplified below?
(query
. (define a (prior))
. (define x (lambda (a) (world a)))
. (define r (flip (sigmoid (U (x a)))))
. a
. (= r #t))
Your model selects an action proportional to p(a) E[sigmoid(U) | a], whereas mine selects an action proportional to p(a) e^E[U | a]. I think the second is better, because it actually treats actions the same if they have the same expected utility. The sigmoid version will not take very high utilities or very low utilities into account much.
Btw it's also possible to select an action proportional to E[U | a]^n:
query {
. a ~ p()
. for i = 1 to n
. . x_i ~ P(x)
. . factor(log U(x, a))
}
Could you explain your syntax here? What probabilistic programming language are you using?
I think the second is better, because it actually treats actions the same if they have the same expected utility.
Well so does the sigmoided version, but you are right that the sigmoid version won't take very high or very low utilities into account. It's meant to shoehorn unbounded utility functions into a framework where one normally works only with random variables.
It's not a specific programming language, I guess it's meant to look like Church. It could be written as:
(query
. (define a (p))
. (foreach (range n) (lambda i)
. . (define x (x-prior))
. . (factor (log (U x a)))))
Well so does the sigmoided version
It samples an action proportional to p(a) E[sigmoid(U) | a]. This can't be written as a function of E[U | a].
ZOMFG, can you link to a write-up? This links up almost perfectly with a bit of research I've been wanting to do.
Well, a write-up doesn't exist because I haven't actually done the math yet :)
But the idea is about algorithms for doing nested queries. There's a planning framework where you take action a proportional to p(a) e^E[U | a]. If one of these actions is "defer to your successor", then the computation of (U | a) is actually another query that samples a different action b proportional to p(b) e^E[U | b]. In this case you can actually just go ahead and convert the resulting nested query to a 1-level query: you can convert a "softmax of softmax" into a regular softmax, if that makes sense.
This isn't doing Vingean reflection, because it's actually doing all the computational work that its successor would have to do. So I'm interested in ways to simplify computationally expensive nested queries into approximate computationally cheap single queries.
Here's a simple example of why I think this might be possible. Suppose I flip a coin to decide whether the SAT problem I generate has a solution or not. Then I run a nested query to generate a SAT problem that either does or does not have a solution (depending on the original coin flip). Then I hand you the problem, and you have to guess whether it has a solution or not. I check your solution using a query to find the solution to the problem.
If you suck at solving SAT problems, your best bet might just be to guess that there's a 50% chance that the problem is solveable. You could get this kind of answer by refactoring the complicated nested nested query model into a non-nested model and then noting that the SAT problem itself gives you very little information about whether it is solveable (subject to your computational constraints).
I'm thinking of figuring out the math here better and then applying it to things like planning queries where your successor has a higher rationality parameter than you (an agent with rationality parameter α takes action a with probability proportional to p(a) e^(α * E[U | a]) ). The goal would be to formalize some agent that, for example, generally chooses to defer to a successor who has a higher rationality parameter, unless there is some cost for deferring, in which case it may defer or not depending on some approximation of value of information.
Your project about trading computing power for algorithmic information seems interesting and potentially related, and I'd be interested in seeing any results you come up with.
even if you still have to place some probability mass on \Bot (bottom)
Is this because you assign probability mass to inconsistent theories that you don't know are inconsistent?
When you use e-raised-to-the alpha times expectation, is that similar to the use of an exponential distribution in something like Adaboost, to take something like odds information and form a distribution over assorted weights? I have work to do, but will be giving your little write-up here a second read-through soon.
Is this because you assign probability mass to inconsistent theories that you don't know are inconsistent?
The idea isn't to assign probability mass to logical theories, but to the outcomes of computations in general. This is partly because computations-in-general strictly contains encodings of all possible proof systems, but also because, if we're building algorithms that have to confront a Turing-complete environment, the environment may sometimes contain nontrivially nonhalting computations, which can't be logically proved not to terminate. Since any realistic agent needs to be able to handle whatever its environment throws at it, it seems to follow that a realistic agent needs some resource-rational way to handle nonprovable nonhalting.
When you use e-raised-to-the alpha times expectation, is that similar to the use of an exponential distribution in something like Adaboost, to take something like odds information and form a distribution over assorted weights?
I'm not really that familiar with adaboost. The planning model is just reflecting the fact that bounded agents don't always take the maximum expected utility action. The higher alpha is, the more bias there is towards good actions, but the more potentially expensive the computation is (e.g. if you use rejection sampling).
Since any realistic agent needs to be able to handle whatever its environment throws at it, it seems to follow that a realistic agent needs some resource-rational way to handle nonprovable nonhalting.
Ah, that makes sense! I think I see how "trading computational power for algorithmic information" makes sense in this framework.
The planning model is just reflecting the fact that bounded agents don't always take the maximum expected utility action. The higher alpha is, the more bias there is towards good actions, but the more potentially expensive the computation is (e.g. if you use rejection sampling).
Ah, that makes sense!
Ah, that makes sense! I think I see how "trading computational power for algorithmic information" makes sense in this framework.
And before I could scribble a damned thing, Calude went and solved it six months ago. The Halting Problem, I mean.
I wonder how he feels about that, because my current feeling about this is HOLY FUCKING SHIT. By GOD, my AIT textbook cannot get here fast enough.
And before I could scribble a damned thing, Calude went and solved it six months ago. The Halting Problem, I mean.
Cool. If I get the meaning of the result well, it's that if you run a random program for some number of steps and it doesn't halt, then (depending on the exact numbers) it will be unlikely to halt when run on a supercomputer either, because halting times have low density. So almost all programs halt quickly or run a really really long time. Is this correct? This doesn't quite let you approximate Chaitin's omega, but it's interesting that you can approximate a bounded variant of Chaitin's omega (like what percentage of Turing machines halt when run for 10^50 steps). I can see how this would let you solve the halting problem well enough when you live in a bounded universe.
Cool. If I get the meaning of the result well, it's that if you run a random program for some number of steps and it doesn't halt, then (depending on the exact numbers) it will be unlikely to halt when run on a supercomputer either, because halting times have low density. So almost all programs halt quickly or run a really really long time. Is this correct?
Yep. Or, to put it a little tiny bit more accurately, you get a halting probability for your particular Turing machine, conditioned on the number of steps for which you've run it.
This doesn't quite let you approximate Chaitin's omega
Well technically, you can approximate Chaitin's omega from below just as Chaitin himself describes in his book. You'll just only be able to calculate finitely many digits.
I can see how this would let you solve the halting problem well enough when you live in a bounded universe.
Which we do ;-). You could run until you get past a desired threshold of probability (hypothesis testing), or you could use a bounded-rationality approach to vary your surety of nonhalting with your available processing power.
But overall, it gives you a way to "reason around" the Halting Problem, which, when we apply it to the various paradoxes of self-reference... you can see where I'm going with this.
my AIT textbook cannot get here fast enough.
You can always acquire it nautically to cut down on shipping time :P
What one did you get? I went with Li and Vitanyi, and have enjoyed my first readthrough.
The first one I bought was Calude's, but it demands more background in pure maths than I have, so I went for Li and Vitanyi's.
I'm thinking of figuring out the math here better and then applying it to things like planning queries where your successor has a higher rationality parameter than you (an agent with rationality parameter α takes action a with probability proportional to p(a) e^(α * E[U | a]) ). The goal would be to formalize some agent that, for example, generally chooses to defer to a successor who has a higher rationality parameter, unless there is some cost for deferring, in which case it may defer or not depending on some approximation of value of information.
How does this deal with the Paradox of Procrastination?
Due to the planning model, the successor always has some nonzero probability of not pressing the button, so (depending on how much you value pressing it later) it'll be worth it to press it at some point.
A hypercomputer is a computer that can deterministically decide the Halting Problem for a Turing machine in finite time. We already know that this is physically impossible.
And unfortunately, most of the FAI work I've seen under the assumption of having a hypercomputer tends to end up along the lines of, "We started by assuming we had a Turing Oracle, and proved that given a second-level Turing Oracle, we can implement UDT with blah blah blah."
We don't know that it's physically impossible, although it does look that way, but even if we did that doesn't mean it's contradictory, not to the extent that using it you'll "mostly derive paradox theorems and contradictions".
If Turing oracles are not physically impossible, then we need an explanation for how physics implements an infinite tower of Turing oracle levels. Short of that, I'm going to believe Turing oracles are impossible.
even if we did that doesn't mean it's contradictory, not to the extent that using it you'll "mostly derive paradox theorems and contradictions".
If you start with something undecidable and build on it, you usually find that your results are even more undecidable (require a higher level of Turing oracle). There's also the AIT angle, which says that a true Turing oracle possesses infinite Kolmogorov complexity, and since Shannon entropy is the expected-value of Kolmogorov complexity, and Shannon entropy is closely related to physical entropy... we have strong reason to think that a Turing oracle violates basic thermodynamics.
Why do we need the full tower? Why couldn't it be the case that just one (or some other finite number) of the Turing Oracle levels are physically possible?
Effectively, there is either some natural number n such that physics allows for n levels of physically-implementable Turing oracles, or the number is omega. Mostly, we think the number should either be zero or omega, because once you have a first-level Turing Oracle, you construct the next level just by phrasing the Halting Problem for Turing Machines with One Oracle, and then positing an oracle for that, and so on.
Likewise, having omega (cardinality of the natural numbers) bits of algorithmic information is equivalent to having a first-level Turing Oracle (knowing the value of Chaitin's Omega completely). From there, you start needing larger and larger infinities of bits to handle higher levels of the Turing hierarchy.
So the question is: how large a set of bits can physics allow us to compute with? Possible answers are:
This seems like a mathematical write up of a very simple idea. I dislike papers such as this. The theory itself could have been described in one sentence, and nothing other than the theory itself is presented here. No evidence of the theory's empirical value, no discussion of what the actual leakage ratio is or what barriers to Friendliness remain. A lot of math used as mere ornamentation.
Formalizations can simultaneously be simple and useful. I'm reminded of things like Chapter 4 of Superintelligence and Bostrom's GCR model. These are relatively simple models, but they make very explicit things that we previously had only considered in natural language. Attention is a limited resource, and things like this allow us to focus our attention on this model's inputs, that is, what observations we should be making in the empirical case, and allow us to focus on other things to formalize in the theoretical case. Technological strategy cannot be discussed in natural language forever if we are to make substantial progress, and now we have a better idea of what to measure.
Problem is that this formalisation is probably bullshit. It looks a bit like a video game where you generate "research points" for AGI and/or FAI. Research IRL does not work like that. You need certain key insights for AGI and a different set for FAI if some insights are shared among both sets (they probably are) the above model does not work any longer. Further problem: How do you quantify G and F? A mathematical modell with variables you can't quantify is of um very limited use (or should I say ornamentation?).
It sounds like we're just rehashing the old arguments over the Drake equation.
You need certain key insights for AGI and a different set for FAI if some insights are shared among both sets (they probably are) the above model does not work any longer.
The model doesn't assume that the sets of research are disjoint. See this thread where jessicat assumed the model wouldn't work for her conception of FAI research in which the FAI problem is entirely reduced to AGI research. Fremaining and Gremaining can both include units of FAI or AGI research. First paragraph of the section on model 1.
How do you quantify G and F? A mathematical modell with variables you can't quantify is of um very limited use (or should I say ornamentation?).
The point is that this is not a question that you even would have asked before. It's just like the criticism about the last four factors in the Drake equation, but how many people were thinking about the questions raised by those factors before they were invented? I think this is more useful to have than not, and it can be built upon, which the authors apparently intend to do. Instead of just getting a good one in on me, actually ask "How do you quantify G and F?" We can ask subquestions that probably have a bearing on that question. What AGI research could be dependent upon FAI research, and vice versa? Are there examples of past technologies in which safety and functionality were at odds, and how analogous are these past examples with FAI/AGI research? How did, say, the Manhattan Project, especially in its early days, quantify and estimate its progress against other national nuclear weapon projects? What literature already exists on the topic of estimating research progress? Etc.
And then there are questions about how to improve the model, some of which they pose in the post itself. Although I haven't found that any of your criticisms hold, I would still ask, how would you model this problem?
The theory will be a lot more useful once actual leakage ratios are estimated. This paper was mathematically specific, because the purpose of it was to establish a few equations to use when estimating the Friendliness ratio and constraints to AI projects. It was written more to build a mathematical foundation for that than it was a simple intro of the ideas to most readers.
Obviously this was meant as more of a research article than a blog post, but we felt like LessWrong was a good place to publish it given the subject.
It was written more to build a mathematical foundation
That's a pretty simple mathematical foundation for a toy problem.
How about introducing uncertainty into your framework? You will not be dealing with hard numbers, you will be dealing with probability distributions and that makes things considerably more complex.
Just pointing out that they have considered this:
This paper was focused on establishing the mentioned models instead of estimating input values. If the models are considered useful, there should be more research to estimate these numbers. The models could also be improved to incorporate uncertainty, the growing returns of research, and other important limitations that we haven't considered. Finally, the friendliness ratio concept naturally generalizes to other technology induced existential risks.
I honestly don't understand how on Earth it would even be possible to understand FAI without understanding AGI on a general level. On some level, what you need isn't a team of Sufficiently Advanced Geniuses who can figure out Friendliness while simultaneously minimizing their own understanding of AGI, but old-fashioned cooperation among the teams who are likely to become able to build AGI, with the shared goal of not building any agent that would defy its creators' intentions.
(You can note that the creators' intentions might be, so to speak, "evil", but an agent that faithfully follows the "evil" intentions of an "evil" sort of human operator is already far Friendlier in kind than a paperclip maximizer -- it was just given the wrong operator.)
A mathematical model of what this might look like: you might have a candidate class of formal models U that you think of as "all GAI" such that you know of no "reasonably computable"(which you might hope to define) member of the class (corresponding to an implementable GAI). Maybe you can find a subclass F in U that you think models Friendly AI. You can reason about these classes without knowing any examples of reasonably computable members of either. Perhaps you could even give an algorithm for taking an arbitrary example in U and transforming it via reasonable computation into an example of F. Then, once you actually construct an arbitrary GAI, you already know how to transform it into an FAI.
So the problem may be factorable such that you can solve a later part before solving the first part.
So, I'd agree it might be hard to understand F without understanding U as a class of objects. And lets leave aside how you would find and become certain of such definitions. If you could, though, you might hope that you can define them and work with them without ever constructing an example. Patterns not far off from this occur in mathematical practice, for example families of graphs with certain properties known to exist via probabilistic methods, but with no constructed examples.
Does that help, or did I misunderstand somewhere?
(edit: I don't claim an eventual solution would fit the above description, this is just I hope a sufficient example that such things are mathematically possible)
Then, once you actually construct an arbitrary GAI, you already know how to transform it into an FAI.
Frankly, I don't trust this claim for a second, because important components of the Friendliness problem are being completely shunted aside. For one thing, in order for this to even start making sense, you have to be able to specify a computable utility function for the AGI agent in the first place. The current models being used for this "mathematical" research don't have any such thing, ie: AIXI specifies reward as a real-valued percept rather than a function over its world-model.
The problem is not the need for large amounts of computing power (ie: the problem is not specifying the right behavior and then "scaling it down" or "approximating" a "tractable example from the class"). The problem is not being able to specify what the agent values in detail. No amount of math wank about "approximation" and "candidate class of formal models U" is going to solve the basic problem of having to change the structure away from AIXI in the first place.
I really ought to apologize for use of the term "math wank", but this really is the exact opposite approach to how one constructs correct programs. What you don't do to produce a correct computer program, knowing its specification, is try to specify a procedure that will, given an incomplete infinity of time, somehow transform an arbitrary program from some class of programs into the one you want. What you do is write the single exact program you want, correct-by-construction, and prove formally (model checking, dependent types, whatever you please) that it exactly obeys its specification.
If you are wondering where the specification for an FAI comes from, well, that's precisely the primary research problem to solve! But it won't get solved by trying to write a function that takes as input an arbitrary instance or approximation of AIXI and returns that same instance of AIXI "transformed" to use a Friendly utility function.
Oh yes, it sounds like I did misunderstand you. I thought you were saying you didn't understand how such a thing could happen in principle, not that you were skeptical of the currently popular models. The classes U and F above, should something like that ever come to pass, need not be AIXI-like (nor need they involve utility functions).
I think I'm hearing that you're very skeptical about the validity of current toy mathematical models. I think it's common for people to motte and bailey between the mathematics and the phenomena they're hoping to model, and it's an easy mistake for most people to make. In a good discussion, you should separate out the "math wank" (which I like to just call math) from the transfer of that wank to reality that you hope to model.
Sometimes toy models are helpful and some times they are distractions that lead nowhere or embody a mistaken preconception. I see you as claiming these models are distractions, not that no model is possible. Accurate?
Sometimes toy models are helpful and some times they are distractions that lead nowhere or embody a mistaken preconception. I see you as claiming these models are distractions, not that no model is possible. Accurate?
I very much favor bottom-up modelling based on real evidence rather than mathematical models that come out looking neat by imposing our preconceptions on the problem a priori.
The classes U and F above, should something like that ever come to pass, need not be AIXI-like (nor need they involve utility functions).
Right. Which is precisely why I don't like when we attempt to do FAI research under the assumption of AIXI-like-ness.
I very much favor bottom-up modelling based on real evidence rather than mathematical models that come out looking neat by imposing our preconceptions on the problem a priori.
(edit: I think I might understand after-all; it sounds like you're claiming AIXI-like things are unlikely to be useful since they're based mostly on preconceptions that are likely false?)
I don't think I understand what you mean here. Everyone favors modeling based on real evidence as opposed to fake evidence, and everyone favors avoiding the import of false preconceptions. It sounds like you prefer more constructive approaches?
Right. Which is precisely why I don't like when we attempt to do FAI research under the assumption of AIXI-like-ness.
I agree if you're saying that we shouldn't assume AIXI-like-ness to define the field. I disagree if you're saying it's a waste for people to explore that idea space though: it seems ripe to me.
I don't think it's an active waste of time to explore the research that can be done with things like AIXI models. I do, however, think that, for instance, flaws of AIXI-like models should be taken as flaws of AIXI-like models, rather than generalized to all possible AI designs.
So for example, some people (on this site and elsewhere) have said we shouldn't presume that a real AGI or real FAI will necessarily use VNM utility theory to make decisions. For various reasons, I think that exploring that idea-space is a good idea, in that relaxing the VNM utility and rationality assumptions can both take us closer to how real, actually-existing minds work, and to how we normatively want an artificial agent to behave.
I offered the transform as an example how things can mathematically factor, so like I said, that may not be what the solution looks like. My feeling is that it's too soon to throw out anything that might look like that pattern though.
That sounds plausible, but how do you start to reason about such models of computation if they haven't even been properly defined yet?
Formally, you don't. Informally, you might try approximate definitions and see how they fail to capture elements of reality, or you might try and find analogies to other situations that have been modeled well and try to capture similar structure. Mathematicians et al usually don't start new fields of inquiry from a set of definitions, they start from an intuition grounded in reality and previously discovered mathematics and iterate until the field takes shape. Although I'm not a physicist, the possibly incorrect story I've heard is that Feynman path integrals are a great example of this.
I just want to flag that despite simple, I feel like writings such as this one are valuable both as introductory concepts and so the new branches with more details are created by other researchers.
If you don't know what the threshold ratio of AGI to FAI research needed is, you can still know that if your research beats the world average, you are increasing the ratio. Lets say that 2 units of FAI research are being produced for every 3 units of AGI, and that ratio isn't going to change. Then work that produces 3 units of FAI and 4 of AGI is beneficial. (It causes FAI in the scenario where FAI is slightly over 2/3 as difficult. )
Is it remotely plausible that FAI is easier. Suppose that there was one key insight. If you have that insight, you can see how to build FAI easily. From that insight, alignment is clearly necessary and not hard. Anyone with that insight will build a FAI, because doing so is almost no harder than building an AGI.
Suppose also that it is possible to build an AGI without this insight. You can hack together a huge pile of ad hoc tricks. This approach takes a lot of ad hoc tricks. No one trick is important.
In this model, the difficulty of FAI could be much easier than knowing how to build AGI without knowing how to make an FAI.
By raising the sanity waterline for AI researchers, one could, in principle, extend Gremaining.
It could increase Gremaining by making more AI researchers realize that AI could be dangerous, thus postponing the kind of AI they would write/run.
Ozzie Gooen and Justin Shovelain
Summary
Friendly artificial intelligence (FAI) researchers have at least two significant challenges. First, they must produce a significant amount of FAI research in a short amount of time. Second, they must do so without producing enough general artificial intelligence (AGI) research to result in the creation of an unfriendly artificial intelligence (UFAI). We estimate the requirements of both of these challenges using two simple models.
Our first model describes a friendliness ratio and a leakage ratio for FAI research projects. These provide limits on the allowable amount of artificial general intelligence (AGI) knowledge produced per unit of FAI knowledge in order for a project to be net beneficial.
Our second model studies a hypothetical FAI venture, which is responsible for ensuring FAI creation. We estimate necessary total FAI research per year from the venture and leakage ratio of that research. This model demonstrates a trade off between the speed of FAI research and the proportion of AGI research that can be revealed as part of it. If FAI research takes too long, then the acceptable leakage ratio may become so low that it would become nearly impossible to safely produce any new research.
Introduction
A general artificial intelligence (AGI) is an AI that could perform all the intellectual tasks a human can.[1] When one is created, it may recursively become more intelligent to the point where it is vastly superior to human intelligences.[2] This AGI could be either friendly or unfriendly, where friendliness means it would have values that humans would favor, and unfriendliness means that it would not.[3]
It is likely that if we do not explicitly understand how to make a friendly general artificial intelligence, then by the time we make a general artificial intelligence, it will be unfriendly.[4] It is also likely that we are much further from understanding how to make a friendly artificial intelligence than we are from understanding how to make a general artificial intelligence.[5][6]
Thus, it is important to create more FAI research, but it may also be important to make sure to not produce much AGI research when doing so. If it is 10 times as difficult to understand how to make an FAI than to understand how to make an AGI, then a FAI research paper that produces 0.3 equivalent papers worth of AGI research will probably increase the chances of a UFAI. Given the close relationship of FAI and AGI research, producing FAI research with a net positive impact may be difficult to do.
Model 1. The Friendliness and Leakage Ratios for an FAI Project
The Friendliness Ratio
Let's imagine that there is necessary amount of research to build an AGI, Gremaining. There is also some necessary amount of research to build a FAI, Fremaining. These two have units of rgeneral (general AI research) and rfriendly (friendly AI research), which are not precisely defined but are directly comparable.
Which threshold is higher? According to much of the research in this field, Fremaining. We need significantly more research to create a friendly AI than an unfriendly one.
Figure 1. Example research thresholds for AGI and FAI.
To understand the relationship between these thresholds, we use the following equation.
We call this the friendliness ratio. The friendliness ratio is useful for a high level understanding of world total FAI research requirements and is a heuristic guide for how difficult the problem of differential technological development is.
The friendliness ratio would be high if Fremaining > Gremaining. For example, if there are 2000 units of remaining research for an FAI and 20 units for an AGI, the friendliness ratio would be 100. If someone published research with 20 units of FAI research but 1 unit of AI research, their research would not meet the friendliness ratio requirement (100 vs 20/1) and would thus make the problem even worse.
The Leakage Ratio
For specific projects it may be useful to have a measure that focuses directly on the negative outcome.
For this we can use the leakage ratio, which represents the amount of undesired AGI research created per unit of FAI research. It is simply the inverse of the friendliness ratio.
In order for a project to be net beneficial,
Estimating if a Project is Net Friendliness Positive
Question: How can one estimate if a project is net friendliness-positive?
A naive answer would be to make sure that it falls over the global friendliness ratio or under the global leakage ratio.
Global AI research rates need to fulfill the friendliness ratio in order to produce a FAI. Therefore, if an advance in friendliness research gets produced with FAI research Fproject, but in the process it also produces AGI research Gproject, then this would be net friendliness negative if
Later research would need to make up for this under-balance.
AI Research Example
Say that Gremaining = 200rg and Fremaining =2000rf, leading to a friendliness ratio of fglobal = 10 and a global maximum leakage ratio of lglobal = 0.1. In this case, specific research projects could be evaluated to make sure that they meet this threshold. One could imagine an organization deciding what research to do or publish using the following chart.
Research
Research
Ratio
Ratio
1
simulation
2
3
FAI
Advocacy
In this case, only Projects 2 and 3 have a leakage ratio of less than 0.1, meaning that only these would net beneficial. Even though Project 1 has generated safety research, it would be net negative.
Model 1 Assumptions:
1. There exists some threshold Gremaining of research necessary to generate an unfriendly artificial intelligence.
2. There exists some threshold Fremaining of research necessary to generate a friendly artificial intelligence.
3. If Gremaining is reached before Fremaining, a UFAI will be created. If after, an FAI will be created.
Model 2. AGI Leakage Limits of an FAI Venture
Question: How can an FAI venture ensure the creation of an FAI?
Let's imagine a group that plans to ensure that an FAI is created. We call this an FAI Venture.
This venture would be constrained by time. AGI research is being created internationally and, if left alone, will likely create an UFAI. We can consider research done outside of the venture as external research and research within the venture as internal research. If internal research is done too slowly, or if it leaks too much AGI research, an unfriendly artificial intelligence could be created before Fremaining is met.
We thus split up friendly and unfriendly research creation into two categories, external and internal research. Then we consider the derivative of each with respect to time. For simplicity, we assume the unit of time is years.
G'i = AGI research produced internally per year
F'i = FAI research produced internally per year
G'e = AGI research produced externally per year
F'e = FAI research produced externally per year
We can understand that there exists times, tf and tg, which are the times at which the friendly and general remaining thresholds are met.
tf = Year in which Fremaining is met
tg = Year in which Gremaining is met
These times can be estimated as follows:
The venture wants to make sure that tf < tg so that the eventual AI is friendly (assumption 3). With this, we find that:
Where the values of C0 and C1 both include the friendliness ratio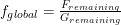 .
.
This implies a linear relationship between F'i and G'i. The more FAI research the FAI venture can produce, the more AGI research it is allowed to leak.
This gives us a clean way to go from a G'i value the venture could expect to the F'i it would need to be successful.
The C0 value describes the absolute minimum amount of FAI research necessary in order to have a chance at a successful outcome. While the resulting acceptable leakage ratio at this point would be impossible to meet, the baseline is easy to calculate. Assuming that F'e << fglobalG'e, we can estimate that
If we wanted to instead calculate G'i using F'i, we could use the following equation. This may be more direct to the intentions of a venture (finding the acceptable amount of AGI leakage after estimating FAI productivity).
Model 2 Example
For example, let's imagine that the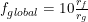 and
and 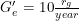 . In this case,
. In this case, 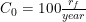 . This means that if the venture could make sure to leak exactly
. This means that if the venture could make sure to leak exactly 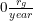 , it would need to average a FAI research rate of 10 times that of the entire world's output of AGI research. This amount increases as 100 / (1 - 10 * lproject). If the venture expects an estimated leakage ratio of 0.05, they would need to double their research output to
, it would need to average a FAI research rate of 10 times that of the entire world's output of AGI research. This amount increases as 100 / (1 - 10 * lproject). If the venture expects an estimated leakage ratio of 0.05, they would need to double their research output to  , or 20 times global AGI output.
, or 20 times global AGI output.
Figure 2. F'i per unit of maximum permissible G'i
What to do?
The numbers in the example above are a bit depressing. There is so much global AI research that it seems difficult to imagine the world averaging an even higher rate of FAI research, which would be necessary if the friendliness ratio is greater than 1.
There are some upsides. First, much hard AI work is done privately in technology companies without being published, limiting G'i. Second, the numbers of rg and rf don't perfectly correlate with the difficulty to reach them. It may be that we have diminishing marginal returns with our current levels of rg, so similar levels of rf will be easier to reach.
It's possible that Fremaining may be surprisingly low or that Gremaining may be surprisingly high.
Projects with high leakage ratios don't have to be completely avoided or hidden. The G'i value is specifically for research that will be in the hands of the group that eventually creates a AGI, so it would make sense that FAI research organizations could share high risk information between each other as long as it doesn't leak externally. The FAI venture mentioned above could be viewed as a collection of organizations rather than one specific one. It may even be difficult for AGI research implications to move externally, if the FAI academic literature is significantly separated from AGI academic literature. This logic provides a heuristic guide to choosing research projects, choosing if to publish research already done, and managing concentrations of information.
Model 2 Assumptions:
1-3. The same 3 assumptions for the previous model.
4. The rates of research creation will be fairly constant.
5. External and internal rates of research do not influence each other.
Conclusion
The friendliness ratio provides a high-level understanding of the amount of global FAI research per unit AGI research needed to create an FAI. The leakage ratio is the inverse of the friendliness ratio applied to a specific FAI project, to specify if that specific project is net friendliness positive. These can be used to understand the challenge for AGI research and tell if a particular project is net beneficial or net harmful.
To understand the challenges facing an FAI Venture, we found the simple equation
where
This paper was focused on establishing the mentioned models instead of estimating input values. If the models are considered useful, there should be more research to estimate these numbers. The models could also be improved to incorporate uncertainty, the growing returns of research, and other important limitations that we haven't considered. Finally, the friendliness ratio concept naturally generalizes to other technology induced existential risks.
Appendix
a. Math manipulation for Model 2
This last equation can be written as
Where
Recalling the friendliness ratio,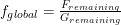 , we can simplify these constructs further.
, we can simplify these constructs further.
References
[1] What is AGI? https://intelligence.org/2013/08/11/what-is-agi/, 2013, Luke Muehlhauser
[2] Intelligence Explosion FAQ, (https://intelligence.org/ie-faq/), MIRI
[3] Artificial Intelligence as a Positive and Negative Factor in Global Risk, 2008, Global Catastrophic Risks, Yudkowsky
[4] Aligning Superintelligence with Human Interest: A Technical Research Agenda, https://intelligence.org/files/TechnicalAgenda.pdf, Nate Soares and Benja Fellenstein, MIRI
[5] Superintelligence, 2014, Nick Bostrom
[6] The Challengeof Friendly AI, https//www.youtube.com/watch?v=nkB1e-JCgmY&noredirect=1 Yudkowsky, 2007