(expanding on my reply to you on twitter)
For the t-AGI framework, maybe you should also specify that the human starts the task only knowing things that are written multiple times on the internet. For example, Ed Witten could give snap (1-second) responses to lots of string theory questions that are WAY beyond current AI, using idiosyncratic intuitions he built up over many years. Likewise a chess grandmaster thinking about a board state for 1 second could crush GPT-4 or any other AI that wasn’t specifically and extensively trained on chess by humans.
A starting point I currently like better than “t-AGI” is inspired the following passage in Cal Newport’s book Deep Work:
[Deciding whether an activity is “deep work” versus “shallow work”] can be more ambiguous. Consider the following tasks:
- Example 1: Editing a draft of an academic article that you and a collaborator will soon submit to a journal.
- Example 2: Building a PowerPoint presentation about this quarter’s sales figures.
- Example 3: Attending a meeting to discuss the current status of an important project and to agree on the next steps. It’s not obvious at first how to categorize these examples.
The first two describe tasks that can be quite demanding, and the final example seems important to advance a key work objective. The purpose of this strategy is to give you an accurate metric for resolving such ambiguity—providing you with a way to make clear and consistent decisions about where given work tasks fall on the shallow-to-deep scale. To do so, it asks that you evaluate activities by asking a simple (but surprisingly illuminating) question:
How long would it take (in months) to train a smart recent college graduate with no specialized training in my field to complete this task?
In the case of LLM-like systems, we would replace “smart recent college graduate” with “person who has read the entire internet”.
This is kinda related to my belief that knowledge-encoded-in-weights can do things that knowledge-encoded-in-the-context-window can’t. There is no possible context window that turns GPT-2 into GPT-3, right?
So when I try to think of things that I don’t expect LLM-like-systems to be able to do, I imagine, for example, finding a person adept at tinkering, and giving them a new machine to play with, a very strange machine unlike anything on the internet. I ask the person to spend the next weeks or months understanding that machine. So the person starts disassembling it and reassembling it, and they futz with one of the mechanism and see how it affects the other mechanisms, and they try replacing things and tightening or loosening things and so on. It might take a few weeks or months, but they’ll eventually build for themselves an exquisite mental model of this machine, and they’ll be able to answer questions about it and suggest improvements to it, even in only 1 second of thought, that far exceed what an LLM-like AI could ever do.
Maybe you’ll say that example is unfair because that’s a tangible object and robotics is hard. But I think there are intangible examples that are analogous, like people building up new fields of math. As an example from my own life, I was involved in early-stage design for a new weird type of lidar, including figuring out basic design principles and running trade studies. Over the course of a month or two of puzzling over how best to think about its operation and estimate its performance, I wound up with a big set of idiosyncratic concepts, with rich relationships between them, tailored to this particular weird new kind of lidar. That allowed me to have all the tradeoffs and interrelationships at the tip of my tongue. If someone suggested to use a lower-peak-power laser, I could immediately start listing off all the positive and negative consequences on its performance metrics, and then start listing possible approaches to mitigating the new problems, etc. Even if that particular question hadn’t come up before. The key capability here is not what I’m doing in the one second of thought before responding to that question, rather it’s what I was doing in the previous month or two, as I was learning, exploring, building concepts, etc., all specific to this particular gadget for which no remotely close analogue existed on the internet.
I think a similar thing is true in programming, and that the recent success of coding assistants is just because a whole lot of coding tasks are just not too deeply different from something-or-other on the internet. If a human had hypothetically read every open-source codebase on the internet, I think they’d more-or-less be able to do all the things that Copilot can do without having to think too hard about it. But when we get to more unusual programming tasks, where the hypothetical person would need to spend a few weeks puzzling over what’s going on and what’s the best approach, even if that person has previously read the whole internet, then we’re in territory beyond the capabilities of LLM programming assistants, current and future, I think. And if we’re talking about doing original science & tech R&D, then we get into that territory even faster.
How long would it take (in months) to train a smart recent college graduate with no specialized training in my field to complete this task?
This doesn't seem like a great metric because there are many tasks that a college grad can do with 0 training that current AI can't do, including:
- Download and play a long video game to completion
- Read and summarize a whole book
- Spend a month planning an event
I do think that there's something important about this metric, but I think it's basically subsumed by my metric: if the task is "spend a month doing novel R&D for lidar", then my framework predicts that we'll need 1-month AGI for that. If the task is instead "answer the specific questions about lidar which this expert has been studying", then I claim that this is overfitting and therefore not a fair comparison; even if you expand it to "questions about lidar in general" there's probably a bunch of stuff that GPT-4 will know that the expert won't.
For the t-AGI framework, maybe you should also specify that the human starts the task only knowing things that are written multiple times on the internet. For example, Ed Witten could give snap (1-second) responses to lots of string theory questions that are WAY beyond current AI, using idiosyncratic intuitions he built up over many years. Likewise a chess grandmaster thinking about a board state for 1 second could crush GPT-4 or any other AI that wasn’t specifically and extensively trained on chess by humans.
I feel pretty uncertain about this, actually. Sure, there are some questions that don't appear at all on the internet, but most human knowledge is, so you'd have to cherry-pick questions. And presumably GPT-4 has also inferred a bunch of intuitions from internet data which weren't explicitly written down there. In other words: even if this is true, it doesn't feel centrally relevant.
Ah, that’s helpful, thanks.
Sure, there are some questions that don't appear at all on the internet, but most human knowledge is, so you'd have to cherry-pick questions.
I think you’re saying “there are questions about string theory whose answers are obvious to Ed Witten because he happened to have thought about them in the course of some unpublished project, but these questions are hyper-specific, so bringing them up at all would be unfair cherry-picking.”
But then we could just ask the question: “Can you please pose a question about string theory that no AI would have any prayer of answering, and then answer it yourself?” That’s not cherry-picking, or at least not in the same way.
And it points to an important human capability, namely, figuring out which areas are promising and tractable to explore, and then exploring them. Like, if a human wants to make money or do science or take over the world, then they get to pick, endogenously, which areas or avenues to explore.
But then we could just ask the question: “Can you please pose a question about string theory that no AI would have any prayer of answering, and then answer it yourself?” That’s not cherry-picking, or at least not in the same way.
But can't we equivalently just ask an AI to pose a question that no human would have a prayer of answering in one second? It wouldn't even need to be a trivial memorization thing, it could also be a math problem complex enough that humans can't do it that quickly, or drawing a link between two very different domains of knowledge.
I think the “in one second” would be cheating. The question for Ed Witten didn’t specify “the AI can’t answer it in one second”, but rather “the AI can’t answer it period”. Like, if GPT-4 can’t answer the string theory question in 5 minutes, then it probably can’t answer it in 1000 years either.
(If the AI can get smarter and smarter, and figure out more and more stuff, without bound, in any domain, by just running it longer and longer, then (1) it would be quite disanalogous to current LLMs [btw I’ve been assuming all along that this post is implicitly imagining something vaguely like current LLMs but I guess you didn’t say that explicitly], (2) I would guess that we’re already past end-of-the-world territory.)
Why is it cheating? That seems like the whole point of my framework - that we're comparing what AIs can do in any amount of time to what humans can do in a bounded amount of time.
Whatever. Maybe I was just jumping on an excuse to chit-chat about possible limitations of LLMs :) And maybe I was thread-hijacking by not engaging sufficiently with your post, sorry.
This part you wrote above was the most helpful for me:
if the task is "spend a month doing novel R&D for lidar", then my framework predicts that we'll need 1-month AGI for that
I guess I just want to state my opinion that (1) summarizing a 10,000-page book is a one-month task but could come pretty soon if indeed it’s not already possible, (2) spending a month doing novel R&D for lidar is a one-month task that I think is forever beyond LLMs and would require new algorithmic breakthroughs. That’s not disagreeing with you per se, because you never said in OP that all 1-month human tasks are equally hard for AI and will fall simultaneously! (And I doubt you believe it!) But maybe you conveyed that vibe slightly, from your talk about “coherence over time” etc., and I want to vibe in the opposite direction, by saying that what the human is doing during that month matters a lot, with building-from-scratch and exploring a rich hierarchical interconnected space of novel concepts being a hard-for-AI example, and following a very long fiction plot being an easy-for-AI example (somewhat related to its parallelizability).
Yeah, I agree I convey the implicit prediction that, even though not all one-month tasks will fall at once, they'll be closer than you would otherwise expect not using this framework.
I think I still disagree with your point, as follows: I agree that AI will soon do passably well at summarizing 10k word books, because the task is not very "sharp" - i.e. you get gradual rather than sudden returns to skill differences. But I think it will take significantly longer for AI to beat the quality of summary produced by a median expert in 1 month, because that expert's summary will in fact explore a rich hierarchical interconnected space of concepts from the novel (novel concepts, if you will).
Here are some predictions—mostly just based on my intuitions, but informed by the framework above. I predict with >50% credence that by the end of 2025 neural nets will:
To clarify, I think you mean that you predict each of these individually with >50% credence, not that you predict all of them jointly with >50% credence. Is that correct?
I tried to write markets for these when Richard originally posted then. I feel like posting a block of markets is kind of antisocial, but I think the benefits outweigh the costs.
A 1-year AGI would need to beat humans at... basically everything. Some projects take humans much longer (e.g. proving Fermat's last theorem) but they can almost always be decomposed into subtasks that don't require full global context (even tho that's often helpful for humans).
This seems wrong. There is a class of tasks that takes humans longer than 1 year: gaining expertise in a field. For example, learning higher mathematics from scratch, or learning to code very well, or becoming a surgeon, etc.
If AI is capable of doing any current human profession, but is incapable of learning new professions that do not yet exist (because of lack of training data, presumably), then it is not yet human-complete: humans still have relevance in the economy, as new types of professions will arise.
Good post! I think I basically agree with you except I think that I would add that the stuff that can't be done by the end of 2025 will be doable by the end of 2027 (with the possible exception of manual labor, that might take another year or two). Whereas I take it you think it'll take longer than that for e.g. robustly pursuing a plan over multiple days to happen.
Care to say what you think there -- how long until e.g. AI R&D has been dramatically accelerated by AIs doing much of the cognitive labor? How long until e.g. a souped-up version of AutoGPT can carry out a wide range of tasks on the internet/computers, stringing them together to coherently act towards goals on timespans of multiple days? (At least as coherently as a typical human professional, let's say?)
My default (very haphazard) answer: 10,000 seconds in a day; we're at 1-second AGI now; I'm speculating 1 OOM every 1.5 years, which suggests that coherence over multiple days is 6-7 years away.
The 1.5 years thing is just a very rough ballpark though, could probably be convinced to double or halve it by doing some more careful case studies.
Thanks. For the record, my position is that we won't see progress that looks like "For t-AGI, t increases by +1 OOM every X years" but rather that the rate of OOMs per year will start off slow and then accelerate. So e.g. here's what I think t will look like as a function of years:
| Year | Richard (?) guess | Daniel guess |
| 2023 | 1 | 5 |
| 2024 | 5 | 15 |
| 2025 | 25 | 100 |
| 2026 | 100 | 2000 |
| 2027 | 500 | Infinity (singularity) |
| 2028 | 2,500 | |
| 2029 | 10,000 | |
| 2030 | 50,000 | |
| 2031 | 250,000 | |
| 2032 | 1,000,000 |
I think this partly because of the way I think generalization works (I think e.g. once AIs have gotten really good at all 2000-second tasks, they'll generalize quickly with just a bit more scaling, tuning, etc. to much longer tasks) and partly because of R&D acceleration effects where e.g. once AIs have gotten really good at all 2000-second tasks, AI research can be partially automated and will go substantially faster, getting us to 10,000-second tasks quicker, which then causes further speedup in R&D, etc.
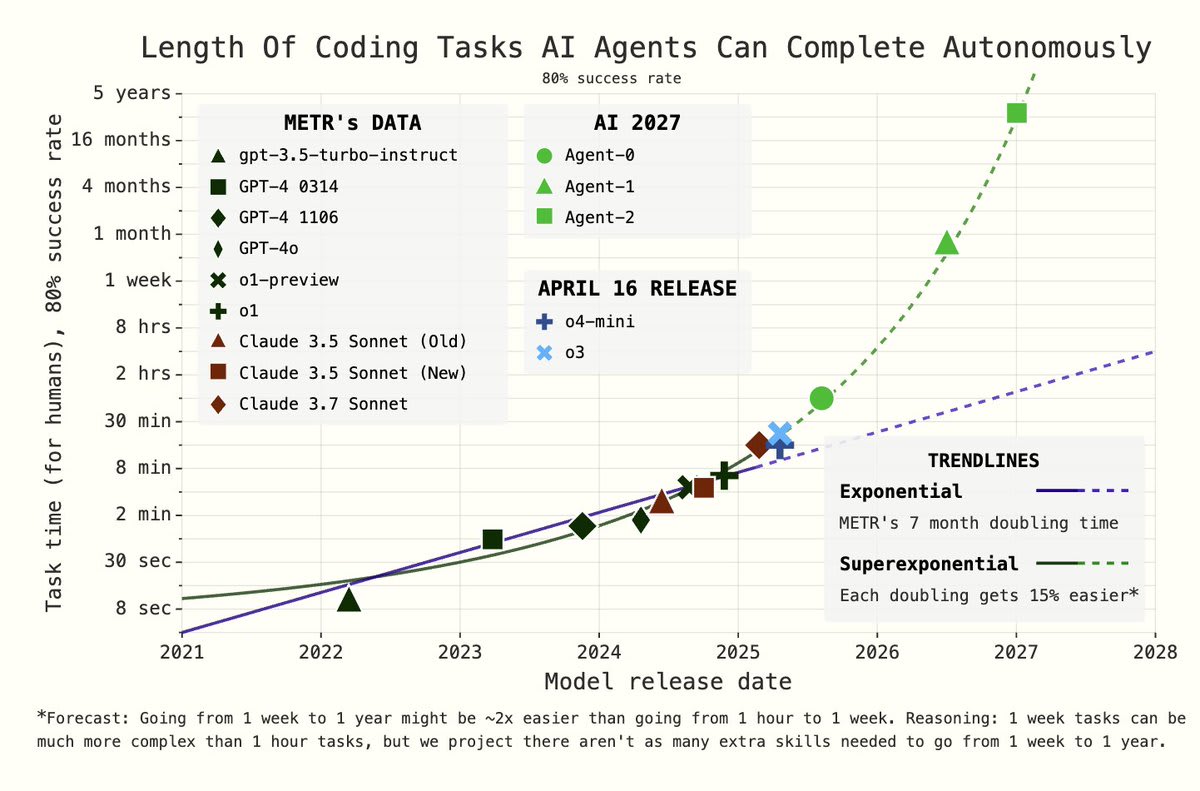
@Richard_Ngo Seems like we should revisit these predictions now in light of the METR report https://metr.org/AI_R_D_Evaluation_Report.pdf
This comment seems to be holding up pretty well. Horizon lengths have indeed been increasing and moreover the trend is plausibly superexponential: https://x.com/DKokotajlo/status/1916520276843782582
This also is related to the crux between me and Ajeya Cotra, between me and Paul Christiano, between me and Rohin Shah... I think their view is that the "2020 AGI/TAI training requirements" variable is a lot higher than I think (they are thinking something like 1e36 FLOP, I'm thinking something like 1e29) because they are thinking you'll need to do lots and lots of long-horizon training to get systems that are good at long-horizon tasks, whereas I'm thinking you'll be able to get away with mostly training on shorter tasks and then a bit of fine-tuning on longer tasks.
Sorry for a slightly dumb question but in your part of the table you set 2000 as the year before singularity and your explanation is that 2000-second tasks jump to singularity. Is your model of fast take-off then contingent on there being more special sauce for intelligence being somewhat redundant as a crux because recursive self-improvement is just much more effective. I'm having trouble envisioning a 2000-second task + more scaling and tuning --> singularity.
Additional question is what your model of falsification is for let's say 25-second task vs. 100-second task in 2025 because it seems like reading your old vignettes you really nailed the diplomacy AI part.
Also slightly pedantic but there's a typo on 2029 on Richard's guess.
Oooh, thanks for pointing out the typo! Fixed.
I'm not sure I understand your questions, can you elaborate/explain them more?
Note that the numbers in this chart don't represent "There is at least one task of length X that AI can do" but rather "There exist AGIs which can do pretty much all relevant intellectual tasks of length X or less." So my claim is, by the time we get to 2000 in that, such AGIs will be automating huge portions of AI R&D, which will speed it up, which will get us to 10,000 in less than a year, which will speed things up even more, etc.
Yeah, re-reading I realise I was unclear. Given your claim: "by the time we get to 2000 in that, such AGIs will be automating huge portions of AI R&D,". I'm asking the following:
- Is the 2000 mark predicated on automation of things we can't envision now (finding secret sauce to singularity) or is it predicated off pushing existing things like AI R&D finds better compute or is it a combination of both?
- What's the empirical on the ground representative modal action you're seeing at 2025 from either your vignette (e.g. I found the diplomacy AI super important for grokking what short timelines were to me). I guess it's more asking what you see as the divergence between you and Richard at 2025 that's represented by the difference of 25 and 100.
Hopefully that made the questions clearer.
- A bit of both I guess? Insofar as there are things we can't imagine now, but that a smart hardworking human expert could do in 2000 seconds if and when the situation arose / if and when they put their mind to it, then those things will be doable by AI in 2026 in my median projection.
- Unfortunately, my view and Richard's views don't really diverge strongly until it's pretty much too late, as you can see from the chart. :( I think both of us will be very interested in trying to track/measure growth in t-AGI, but he'd be trying to measure the growth rate and then assume it continues going at that rate for years and years, whereas I'd be trying to measure the growth rate so I can guess at how long we have left before it 'goes critical' so to speak. For 'going critical' we can look at how fast AI R&D is going and try to measure and track that and notice when it starts to speed up due to automation. It's already probably sped up a little bit, e.g. Copilot helping with coding...
Fits nicely into (t,n)/(w,h) - as above t is time of human, n is number of humans, w is number of watts inference costs, h is amount of time inference takes. (perhaps there are other units besides watts that matter, such as specific hardware, but imo watts are a fundamental metric in terms of ability to eat all biological life as literal food or whatever doom it is we expect these days.)
Hmm, I'm more interested in FLOP than watts, because almost all watts can't be converted to FLOP.
Also, I think at some point there'll be a salient difference between "many FLOP/s for a short time" and "fewer FLOP/s for a long time" but right now it doesn't feel like a crucial distinction to track.
Hmm. I don't think that'll last very long. Perhaps there's no particular need to think ahead on this, though.
But in most cases I expect that the bottleneck is being able to perform a task *at all*; if they can then they'll almost always be able to do it with a negligible proportion of the world's compute.
I like your framing, and particularly like this piece of it. The thing that I've been trying to convince people of after doing a deep-dive research project over several months on this is... GPT-4 is close to the threshold of being able to do recursive self-improvement. I think that GPT-5 will be over that threshold. If not, then I'm nearly certain a GPT-6 would be. And I think that this threshold is critical not in a FOOM-within-days way, but in a human-assisted gradually-accelerating-self-improvement-over-months culminating in something roughly like 100x improvement over 6 - 18 months, and then it's a crazy singularity world and I don't know how to predict it will go other than 'uhoh'.
If I'm right that we're like 1 - 5 years away from this crazy RSI process getting started, then it would sure be nice if humanity would coordinate a bit better about how to deal with this scenario.
English is not my first language, and I'm not very proficient in it. So there is a word that is confusing to me. Does the word 'any' mean 'all' in this context or does it refer to something that is chosen at random?
Usually "any" means each person in the specific class individually. So perhaps not groups of people working together, but a much higher bar than a randomly sampled person.
But note that Richard doesn't think that "the specific 'expert' threshold will make much difference", so probably the exact definition of "any" doesn't matter very much for his thoughts here.
I want to point out the two main pillars I think your model has to assume for it to be the best model for prediction. (I think they're good assumptions)
1. There is a steep difficulty increase in training NNs that act over larger time spans.
2. This is the best metric to use as it outcompetes all other metrics when it comes to making useful predictions about the efficacy of NNs.
I like the model and I think it's better than not having one. I do think it misses out on some of the things Steven Byrnes responds with. There's a danger of it being too much of a Procrustes bed or overfitted as specific subtasks and cognition that humans have evolved might be harder to replicate than others. The main bottlenecks might then not lay in the temporal planning distance but in something else.
My prior on the t-AGI not being overfitting is probably something like 60-80% due to the bitter lesson, which to some extent tells us that cognition can be replicated quite well with Deep Learning. So I tend to agree but I would have liked to see a bit more epistemic humility to this point I guess.
I really like the t-AGI concept for a specific task or benchmark but find it difficult to generalize since capabilities are not uniform. How do you classify an AGI that is 1-second AGI at some tasks but 1-day AGI at others (e.g. due to serial processing speed advantages)?
I think "on most cognitive tasks" means for an AGI its t is defined as the first t for which it meets the expert level at most tasks. However, what exactly counts as a cognitive task does seem to introduce ambiguity and would be cool to clarify, e.g. by pointing to a clear protocol for sampling all such task descriptions from an LLM.
I think coherence over time is a very difficult problem, and one humans still struggle at, even though (I assume) evolution optimized us hard for this.
Not sure about this. Did humans in the ancestral environment need more than 1-day coherence?
yes. they needed to plan many months ahead to choose where to live, where to hunt, how to raise kids. even long before farming, this sort of need to plan far ahead is the norm for animals. which animals know how to do it intentionally, less clear, but there are clear benefits to being able to do it pretty early in evolutionary history.
Several-months-AGI is required to be coherent in the sense of coherence defined with human experts today. I think this is pretty distinct from coherence that humans were being optimized to have before behavioral modernity (50K years ago).
I agree that evolution optimized hard for some kind of coherence, like persistent self-schema, attitudes, emotional and behavioral patterns, attachments, long-term memory access. But what humans have going for them is the combination of this prior coherence and just 50K years of evolution after humans unlocked access to the abstract thinking toolkit. I don't think we can expect it to enable much in terms of to the ability to coherently plan to do complex tasks or to the ability to write and reason abstractly.
This makes me think humans struggling at coherence is not good evidence for building agents with large t being much more difficult compared to small t: there wasn't enough optimization pressure.
Some evidence in favor of the framework; from Advanced AI evaluations at AISI: May update:
Short-horizon tasks (e.g., fixing a problem on a Linux machine or making a web server) were those that would take less than 1 hour, whereas long-horizon tasks (e.g., building a web app or improving an agent framework) could take over four (up to 20) hours for a human to complete.
[...]
The Purple and Blue models completed 20-40% of short-horizon tasks but no long-horizon tasks. The Green model completed less than 10% of short-horizon tasks and was not assessed on long-horizon tasks3. We analysed failed attempts to understand the major impediments to success. On short-horizon tasks, models often made small errors (like syntax errors in code). On longer horizon tasks, models devised good initial plans but did not sufficiently test their solutions or failed to correct initial mistakes. Models also sometimes hallucinated constraints or the successful completion of subtasks.
Summary: We found that leading models could solve some short-horizon tasks, such as software engineering problems. However, no current models were able to tackle long-horizon tasks.
I'm particularly interested in what the framework might say about the ordering in which various capabilities which are prerequisites for automated AI safety R&D might appear; and also ordering vs. various dangerous capabilities. And, in particular, for each particular t, making sure we're 'eating all the free energy' of all auto AI safety R&D t-horizon prerequisite capabilities.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Hello,
Your viewpoint is very interesting. I have two questions.
If we use an "expert threshold" to define advanced artificial intelligence, what would the threshold for superintelligence be? There are exceptional individuals, such as Leonardo da Vinci or Einstein, who could be considered superintelligent.
I believe, in order to be a fair comparison, superintelligence should be compared to these rare cases. Yet, we lack sufficient data on such individuals, and even if we had the data, our current systems might not comprehend these unique forms of intelligence. What's your perspective on this?
Also, you characterized superintelligence as the equivalent of 8 billion AI systems working for one year. However, it's impractical to have 8 billion people collaborate on a task for a year. How should this be measured appropriately?
Thank you.
What percentage of humans does it need to beat at a given set of benchmarks?
If I wanted to prove I have a t AGI do I need to be at 99th percentile or 50th percentile for each benchmark, and out of all the benchmarks how many of them do we need to "pass"? (Pass meaning "declare victory", but the numerical score is the thing that matters)
Theres also major issues with benchmarking because current AI are stupidly good at learning to pass any test, so leaked questions cause a problem.
In a way what you are asking is for an AGI architecture: the AGI architecture would get trained on data captured before the test questions were developed, and you're measuring the ability of that architecture to use all the training data and it's cognitive architecture on these benchmark tasks.
Certain questions like "build a successful company" or other complex real world tasks have the problem that each successful company was only possible if founded for a target (product, market, time). Miss any of those and it will fail even if the AGI does a better job than human entrepreneurs.
on most cognitive tasks, it beats most human experts
I think this specifies both thresholds to be 50%.
This post is a slightly-adapted summary of two twitter threads, here and here.
The t-AGI framework
As we get closer to AGI, it becomes less appropriate to treat it as a binary threshold. Instead, I prefer to treat it as a continuous spectrum defined by comparison to time-limited humans. I call a system a t-AGI if, on most cognitive tasks, it beats most human experts who are given time t to perform the task.
What does that mean in practice?
Some clarifications:
And very briefly, some of the intuitions behind this framework:
Predictions motivated by this framework
Here are some predictions—mostly just based on my intuitions, but informed by the framework above. I predict with >50% credence that by the end of 2025 neural nets will:
The best humans will still be better (though much slower) at:
FWIW my actual predictions are mostly more like 2 years, but others will apply different evaluation standards, so 2.75 (as of when the thread was posted) seems more robust. Also, they're not based on any OpenAI-specific information.
Lots to disagree with here ofc. I'd be particularly interested in: