This is a special post for quick takes by Mikhail Samin. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Anthropic employees: stop deferring to Dario on politics. Think for yourself.
Do your company's actions actually make sense if it is optimizing for what you think it is optimizing for?
Anthropic lobbied against mandatory RSPs, against regulation, and, for the most part, didn't even support SB-1047. The difference between Jack Clark and OpenAI's lobbyists is that publicly, Jack Clark talks about alignment. But when they talk to government officials, there's little difference on the question of existential risk from smarter-than-human AI systems. They do not honestly tell the governments what the situation is like. Ask them yourself.
A while ago, OpenAI hired a lot of talent due to its nonprofit structure.
Anthropic is now doing the same. They publicly say the words that attract EAs and rats. But it's very unclear whether they institutionally care.
Dozens work at Anthropic on AI capabilities because they think it is net-positive to get Anthropic at the frontier, even though they wouldn't work on capabilities at OAI or GDM.
It is not net-positive.
Anthropic is not our friend. Some people there do very useful work on AI safety (where "useful" mostly means "shows that the predictions of MIRI-s...
I think you should try to clearly separate the two questions of
- Is their work on capabilities a net positive or net negative for humanity's survival?
- Are they trying to "optimize" for humanity's survival, and do they care about alignment deep down?
I strongly believe 2 is true, because why on Earth would they want to make an extra dollar if misaligned AI kills them in addition to everyone else? Won't any measure of their social status be far higher after the singularity, if it's found that they tried to do the best for humanity?
I'm not sure about 1. I think even they're not sure about 1. I heard that they held back on releasing their newer models until OpenAI raced ahead of them.
You (and all the people who upvoted your comment) have a chance of convincing them (a little) in a good faith debate maybe. We're all on the same ship after all, when it comes to AI alignment.
PS: AI safety spending is only $0.1 billion while AI capabilities spending is $200 billion. A company which adds a comparable amount of effort on both AI alignment and AI capabilities should speed up the former more than the latter, so I personally hope for their success. I may be wrong, but it's my best guess...
3
There is very little hope IMHO in increasing spending on technical AI alignment because (as far as we can tell based on how slow progress has been on it over the last 22 years) it is a much thornier problem than AI capability research and because most people doing AI alignment research don't have a viable story about how they are going to stop any insights / progress they achieve from helping with AI capability research. I mean, if you have a specific plan that avoids these problems, then let's hear it, I am all ears, but advocacy in general of increasing work on technical alignment is counterproductive IMHO.
9
EDIT: thank you so much for replying to the strongest part of my argument, no one else tried to address it (despite many downvotes).
I disagree with the position that technical AI alignment research is counterproductive due to increasing capabilities, but I think this is very complicated and worth thinking about in greater depth.
Do you think it's possible, that your intuition on alignment research being counterproductive, is because you compared the plausibility of the two outcomes:
1. Increasing alignment research causes people to solve AI alignment, and humanity survives.
2. Increasing alignment research led to an improvement in AI capabilities, allowing AI labs to build a superintelligence which then kills humanity.
And you decided that outcome 2 felt more likely?
Well, that's the wrong comparison to make.
The right comparison should be:
1. Increasing alignment research causes people to improve AI alignment, and humanity survives in a world where we otherwise wouldn't survive.
2. Increasing alignment research led to an improvement in AI capabilities, allowing AI labs to build a superintelligence which then kills humanity in a world where we otherwise would survive.
In this case, I think even you would agree what P(1) > P(2).
P(2) is very unlikely because if increasing alignment research really would lead to such a superintelligence, and it really would kill humanity... then let's be honest, we're probably doomed in that case anyways, even without increasing alignment research.
If that really was the case, the only surviving civilizations would have had different histories, or different geographies (e.g. only a single continent with enough space for a single country), leading to a single government which could actually enforce an AI pause.
We're unlikely to live in a world so pessimistic that alignment research is counterproductive, yet so optimistic that we could survive without that alignment research.
5
I believe we're probably doomed anyways.
Sorry to disappoint you, but I do not agree.
Although I don't consider it quite impossible that we will figure out alignment, most of my hope for our survival is in other things, such as a group taking over the world and then using their power to ban AI research. (Note that that is in direct contradiction to your final sentence.) So for example, if Putin or Xi were dictator of the world, my guess is that there is a good chance he would choose to ban all AI research. Why? It has unpredictable consequences. We Westerners (particularly Americans) are comfortable with drastic change, even if that change has drastic unpredictable effects on society; non-Westerners are much more skeptical: there have been too many invasions, revolutions and peasant rebellions that have killed millions in their countries. I tend to think that the main reason Xi supports China's AI industry is to prevent the US and the West from superseding China and if that consideration were removed (because for example he had gained dictatorial control over the whole world) he'd choose to just shut it down (and he wouldn't feel that need to have a very strong argument for that shutting it down like Western decision-makers would: non-Western leader shut important things down all the time or at least they would if the governments they led had the funding and the administrative capacity to do so).
Of course Xi's acquiring dictatorial control over the whole world is extremely unlikely, but the magnitude of the technological changes and societal changes that are coming will tend to present opportunities for certain coalitions to gain and to keep enough power to shut AI research down worldwide. (Having power in all countries hosting leading-edge fabs is probably enough.) I don't think this ruling coalition necessarily need to believe that AI presents a potent risk of human extinction for them to choose to shut it down.
I am aware that some reading this will react to
I don't agree that the probability of alignment research succeeding is that low. 17 years or 22 years of trying and failing is strong evidence against it being easy, but doesn't prove that it is so hard that increasing alignment research is useless.
People worked on capabilities for decades, and never got anywhere until recently, when the hardware caught up, and it was discovered that scaling works unexpectedly well.
There is a chance that alignment research now might be more useful than alignment research earlier, though there is uncertainty in everything.
We should have uncertainty in the Ten Levels of AI Alignment Difficulty.
The comparison
It's unlikely that 22 years of alignment research is insufficient but 23 years of alignment research is sufficient.
But what's even more unlikely, is the chance that $200 billion on capabilities research plus $0.1 billion on alignment research is survivable, while $210 billion on capabilities research plus $1 billion on alignment research is deadly.
In the same way adding a little alignment research is unlikely to turn failure into success, adding a little capabilities research is unlikely to turn success into failure.
It's also unlikely that alignme...
5
This assumes that alignment success is the mostly likely avenue to safety for humankind whereas like I said, I consider other avenues more likely. Actually there needs to be a qualifier on that: I consider other avenues more likely than the alignment project's succeeding while the current generation of AI researchers remain free to push capabilities: if the AI capabilities juggernaut could be stopped for 150 years, giving the human population time to get smarter and wiser, then alignment is likely (say p = .7) to succeed in my estimation. I am informed by Eliezer in his latest interview that such a success would probably use some technology other than deep learning to create the AI's capabilities; i.e., deep learning is particularly hard to align.
Central to my thinking is my belief that alignment is just a significantly harder problem than the problem of creating an AI capable of killing us all. Does any of the reasoning you do in your section "the comparision" change if you started believing that alignment is much much harder than creating a superhuman (unaligned) AI?
It will probably come as no great surprise that I am unmoved by the arguments I have seen (including your argument) that Anthropic is so much better than OpenAI that it helps the global situation for me to support Anthropic (if it were up to me, both would be shut down today if I couldn't delegate the decision to someone else and if I had to decide now with the result that there is no time for me to gather more information) but I'm not very certain and would pay attention to future arguments for supporting Anthropic or some other lab.
Thanks for engaging with my comments.
3
Thank you, I've always been curious about this point of view because a lot of people have a similar view to yours.
I do think that alignment success is the most likely avenue, but my argument doesn't require this assumption.
Your view isn't just that "alternative paths are more likely to succeed than alignment," but that "alternative paths are so much more likely to succeed than alignment, that the marginal capabilities increase caused by alignment research (or at least Anthropic), makes them unworthwhile."
To believe that alignment is that hopeless, there should be stronger proof than "we tried it for 22 years, and the prior probability of the threshold being between 22 years and 23 years is low." That argument can easily be turned around to argue why more alignment research is equally unlikely to cause harm (and why Anthropic is unlikely to cause harm). I also think multiplying funding can multiply progress (e.g. 4x funding ≈ 2x duration).
If you really want a singleton controlling the whole world (which I don't agree with), your most plausible path would be for most people to see AI risk as a "desperate" problem, and for governments under desperation to agree on a worldwide military which swears to preserve civilian power structures within each country.[1]
Otherwise, the fact that no country took over the world during the last centuries strongly suggests that no country will in the next few years, and this feels more solid than your argument that "no one figured out alignment in the last 22 years, so no one will in the next few years."
1. ^
Out of curiosity, would you agree with this being the most plausible path, even if you disagree with the rest of my argument?
2
The most plausible story I can imagine quickly right now is the US and China fight a war and the US wins and uses some of the political capital from that win to slow down the AI project, perhaps through control over the world's leading-edge semiconductor fabs plus pressuring Beijing to ban teaching and publishing about deep learning (to go with a ban on the same things in the West). I believe that basically all the leading-edge fabs in existence or that will be built in the next 10 years are in the countries the US has a lot of influence over or in China. Another story: the technology for "measuring loyalty in humans" gets really good fast, giving the first group to adopt the technology so great an advantage that over a few years the group gets control over the territories where all the world's leading-edge fabs and most of the trained AI researchers are.
I want to remind people of the context of this conversation: I'm trying to persuade people to refrain from actions that on expectation make human extinction arrive a little quicker because most of our (sadly slim) hope for survival IMHO flows from possibilities other than our solving (super-)alignment in time.
1
I would go one step further and argue you don't need to take over territory to shut down the semiconductor supply chain, if enough large countries believed AI risk was a desperate problem they could convince and negotiate the shutdown of the supply chain.
Shutting down the supply chain (and thus all leading-edge semiconductor fabs) could slow the AI project by a long time, but probably not "150 years" since the uncooperative countries will eventually build their own supply chain and fabs.
6
The ruling coalition can disincentivize the development of a semiconductor supply chain outside the territories it controls by selling world-wide semiconductors that use "verified boot" technology to make it really hard to use the semiconductor to run AI workloads similar to how it is really hard even for the best jailbreakers to jailbreak a modern iPhone.
1
That's a good idea! Even today it may be useful for export controls (depending on how reliable it can be made).
The most powerful chips might be banned from export, and have "verified boot" technology inside in case they are smuggled out.
The second most powerful chips might be only exported to trusted countries, and also have this verified boot technology in case these trusted countries end up selling them to less trusted countries who sell them yet again.
3
If I believed that, then maybe I'd believe (like you seem to do) that there is no strong reason to believe that alignment project cannot be finished successfully before the capabilities project creates an unaligned super-human AI. I'm not saying scaling and hardware improvement have not been important: I'm saying they were not sufficient: algorithmic improvements were quite necessary for the field to arrive at anything like ChatGPT, and at least as early as 2006, there were algorithm improvements that almost everyone in the machine-learning field recognized as breakthrough or important insights. (Someone more knowledgeable about the topic might be able to push the date back into the 1990s or earlier.)
After the publication 19 years ago by Hinton et al of "A Fast Learning Algorithm for Deep Belief Nets", basically all AI researchers recognized it as a breakthrough. Building on it, was AlexNet in 2012, again recognized as an important breakthrough by essentially everyone in the field (and if some people missed it then certainly generational adversarial networks, ResNets and AlphaGo convinced them). AlexNet was the first deep model trained on GPUs, a technique essential for the major breakthrough in 2017 reported in the paper "Attention is all you need".
In contrast, we've seen nothing yet in the field of alignment that is as unambiguously a breakthrough as is the 2006 paper by Hinton et al or 2012's AlexNet or (emphatically) the 2017 paper "Attention is all you need". In fact I suspect that some researchers could tell that the attention mechanism reported by Bahdanau et al in 2015 or the Seq2Seq models reported on by Sutskever et al in 2014 was evidence that deep-learning language models were making solid progress and that a blockbuster insight like "attention is all you need" is probably only a few years away.
The reason I believe it is very unlikely for the alignment research project to succeed before AI kills us all is that in machine learning or the deep-learni
1
Even if building intelligence requires solving many many problems, preventing that intelligence from killing you may just require solving a single very hard problem. We may go from having no idea to having a very good idea.
I don't know. My view is that we can't be sure of these things.
But it's very unclear whether they institutionally care.
There are certain kinds of things that it's essentially impossible for any institution to effectively care about.
8
Our worldviews do not match, and I fail to see how yours makes sense. Even when I relax my predictions about the future to take in a wider set of possible paths... I still don't get it.
AI is here. AGI is coming whether you like it or not. ASI will probably doom us.
Anthropic, as an org, seems to believe that there is a threshold of power beyond which creating an AGI more powerful than that would kill us all. OpenAI may believe this also, in part, but it seems like their expectation of where that threshold is is further away than mine. Thus, I think there is a good chance they will get us all killed. There is substantial uncertainty and risk around these predictions.
Now, consider that, before AGI becomes so powerful that utilizing it for practical purposes becomes suicide, there is a regime where the AI product gives its wielder substantial power. We are currently in that regime. The further AI gets advanced, the more power it grants.
Anthropic might get us all killed. OpenAI is likely to get us all killed. If you tryst the employees of Anthropic to not want to be killed by OpenAI... then you should realize that supporting them while hindering OpenAI is at least potentially a good bet.
Then we must consider probabilities, expected values, etc. Give me your model, with numbers, that shows supporting Anthropic to be a bad bet, or admit you are confused and that you don't actually have good advice to give anyone.
Give me your model, with numbers, that shows supporting Anthropic to be a bad bet, or admit you are confused and that you don't actually have good advice to give anyone.
It seems to me that other possibilities exist, besides "has model with numbers" or "confused." For example, that there are relevant ethical considerations here which are hard to crisply, quantitatively operationalize!
One such consideration which feels especially salient to me is the heuristic that before doing things, one should ideally try to imagine how people would react, upon learning what you did. In this case the action in question involves creating new minds vastly smarter than any person, which pose double-digit risk of killing everyone on Earth, so my guess is that the reaction would entail things like e.g. literal worldwide riots. If so, this strikes me as the sort of consideration one should generally weight more highly than their idiosyncratic utilitarian BOTEC.
Does your model predict literal worldwide riots against the creators of nuclear weapons? They posed a single-digit risk of killing everyone on Earth (total, not yearly).
It would be interesting to live in a world where people reacted with scale sensitivity to extinction risks, but that's not this world.
8
nuclear weapons have different game theory. if your adversary has one, you want to have one to not be wiped out; once both of you have nukes, you don't want to use them.
also, people were not aware of real close calls until much later.
with ai, there are economic incentives to develop it further than other labs, but as a result, you risk everyone's lives for money and also create a race to the bottom where everyone's lives will be lost.
5
I think you (or @Adam Scholl) need to argue why people won't be angry at you if you developed nuclear weapons, in a way which doesn't sound like "yes, what I built could have killed you, but it has an even higher chance of saving you!"
Otherwise, it's hard to criticize Anthropic for working on AI capabilities without considering whether their work is a net positive. It's hard to dismiss the net positive arguments as "idiosyncratic utilitarian BOTEC," when you accept "net positive" arguments regarding nuclear weapons.
Allegedly, people at Anthropic have compared themselves to Robert Oppenheimer. Maybe they know that one could argue they have blood on their hands, the same way one can argue that about Oppenheimer. But people aren't "rioting" against Oppenheimer.
I feel it's more useful to debate whether it is a net positive, since that at least has a small chance of convincing Anthropic or their employees.
9
My argument isn’t “nuclear weapons have a higher chance of saving you than killing you”. People didn’t know about Oppenheimer when rioting about him could help. And they didn’t watch The Day After until decades later. Nuclear weapons were built to not be used.
With AI, companies don’t build nukes to not use them; they build larger and larger weapons because if your latest nuclear explosion is the largest so far, the universe awards you with gold. The first explosion past some unknown threshold will ignite the atmosphere and kill everyone, but some hope that it’ll instead just award them with infinite gold.
Anthropic could’ve been a force of good. It’s very easy, really: lobby for regulation instead of against it so that no one uses the kind of nukes that might kill everyone.
In a world where Anthropic actually tries to be net-positive, they don’t lobby against regulation and instead try to increase the chance of a moratorium on generally smarter-than-human AI systems until alignment is solved.
We’re not in that world, so I don’t think it makes as much sense to talk about Anthropic’s chances of aligning ASI on first try.
(If regulation solves the problem, it doesn’t matter how much it damaged your business interests (which maybe reduced how much alignment research you were able to do). If you really care first and foremost about getting to aligned AGI, then regulation doesn't make the problem worse. If you’re lobbying against it, you really need to have a better justification than completely unrelated “if I get to the nuclear banana first, we’re more likely to survive”.)
3
Hi,
I've just read this post, and it is disturbing what arguments Anthropic made about how the US needs to be ahead of China.
I didn't really catch up to this news, and I think I know where the anti-Anthropic sentiment is coming from now.
I do think that Anthropic only made those arguments in the context of GPU export controls, and trying to convince the Trump administration to do export controls if nothing else. It's still very concerning, and could undermine their ability to argue for strong regulation in the future.
That said, I don't agree with the nuclear weapon explanation.
Suppose Alice and Bob were each building a bomb. Alice's bomb has a 10% chance of exploding and killing everyone, and a 90% chance of exploding into rainbows and lollipops and curing cancer. Bob's bomb has a 10% chance of exploding and killing everyone, and a 90% chance of "never being used" and having a bunch of good effects via "game theory."
I think people with ordinary moral views will not be very angry at Alice, but forgive Bob because "Bob's bomb was built to not be used."
5
(Dario’s post did not impact the sentiment of my shortform post.)
4
I don't believe the nuclear bomb was truly built to not be used from the point of view of the US gov. I think that was just a lie to manipulate scientists who might otherwise have been unwilling to help.
I don't think any of the AI builders are anywhere close to "building AI not to be used". This seems even more clear than with nuclear, since AI has clear beneficial peacetime economically valuable uses.
Regulation does make things worse if you believe the regulation will fail to work as intended for one reason or another. For example, my argument that putting compute limits on training runs (temporarily or permanently) would hasten progress to AGI by focusing research efforts on efficiency and exploring algorithmic improvements.
9
It has been pretty clearly announced to the world by various tech leaders that they are explicitly spending billions of dollars to produce "new minds vastly smarter than any person, which pose double-digit risk of killing everyone on Earth". This pronouncement has not yet incited riots. I feel like discussing whether Anthropic should be on the riot-target-list is a conversation that should happen after the OpenAI/Microsoft, DeepMind/Google, and Chinese datacenters have been burnt to the ground.
Once those datacenters have been reduced to rubble, and the chip fabs also, then you can ask things like, "Now, with the pressure to race gone, will Anthropic proceed in a sufficiently safe way? Should we allow them to continue to exist?" I think that, at this point, one might very well decide that the company should continue to exist with some minimal amount of compute, while the majority of the compute is destroyed. I'm not sure it makes sense to have this conversation while OpenAI and DeepMind remain operational.
4
That's a very good heuristic. I bet even Anthropic agrees with it. Anthropic did not release their newer models until OpenAI released ChatGPT and the race had already started.
That's not a small sacrifice. Maybe if they released it sooner, they would be bigger than OpenAI right now due to the first mover advantage.
I believe they want the best for humanity, but they are in a no-win situation, and it's a very tough choice what they should do. If they stop trying to compete, the other AI labs will build AGI just as fast, and they will lose all their funds. If they compete, they can make things better.
AI safety spending is only $0.1 billion while AI capabilities spending is $200 billion. A company which adds a comparable amount of effort on both AI alignment and AI capabilities should speed up the former more than the latter.
Even if they don't support all the regulations you believe in, they're the big AI company supporting relatively much more regulation than all the others.
I don't know, I may be wrong. Sadly it is so very hard to figure out what's good or bad for humanity in this uncertain time.
I don't think that most people, upon learning that Anthropic's justification was "other companies were already putting everyone's lives at risk, so our relative contribution to the omnicide was low" would then want to abstain from rioting. Common ethical intuitions are often more deontological than that, more like "it's not okay to risk extinction, period." That Anthropic aims to reduce the risk of omnicide on the margin is not, I suspect, the point people would focus on if they truly grokked the stakes; I think they'd overwhelmingly focus on the threat to their lives that all AGI companies (including Anthropic) are imposing.
7
Regarding common ethical intuitions, I think people in the post singularity world (or afterlife, for the sake of argument) will be far more forgiving of Anthropic. They will understand, even if Anthropic (and people like me) turned out wrong, and actually were a net negative for humanity.
Many ordinary people (maybe most) would have done the same thing in their shoes.
Ordinary people do not follow the utilitarianism that the awkward people here follow. Ordinary people also do not follow deontology or anything that's the opposite of utilitarianism. Ordinary people just follow their direct moral feelings. If Anthropic was honestly trying to make the future better, they won't feel that outraged at their "consequentialism." They may be outraged an perceived incompetence, but Anthropic definitely won't be the only one accused of incompetence.
If you trust the employees of Anthropic to not want to be killed by OpenAI
In your mind, is there a difference between being killed by AI developed by OpenAI and by AI developed by Anthropic? What positive difference does it make, if Anthropic develops a system that kills everyone a bit earlier than OpenAI would develop such a system? Why do you call it a good bet?
AGI is coming whether you like it or not
Nope.
You’re right that the local incentives are not great: having a more powerful model is hugely economically beneficial, unless it kills everyone.
But if 8 billion humans knew what many of LessWrong users know, OpenAI, Anthropic, DeepMind, and others cannot develop what they want to develop, and AGI doesn’t come for a while.
From the top of my head, it actually likely could be sufficient to either (1) inform some fairly small subset of 8 billion people of what the situation is or (2) convince that subset that the situation as we know it is likely enough to be the case that some measures to figure out the risks and not be killed by AI in the meantime are justified. It’s also helpful to (3) suggest/introduce/support policies that change the incentives to race or increase the chance of ...
9
Are there good models that support that Anthropic is a good bet? I'm genuinely curious.
I assume that naively, if any side had more of the burden of proof, it would be Anthropic. They have many more resources, and are the ones doing the highly-impactful (and potentially negative) work.
My impression was that there was very little probablistic risk modeling here, but I'd love to be wrong.
3
I don't feel free to share my model, unfortunately. Hopefully someone else will chime in. I agree with your point and that this is a good question!
I am not trying to say I am certain that Anthropic is going to be net positive, just that that's my view as the higher probability.
7
I think it's totally fine to think that Anthropic is a net positive. Personally, right now, I broadly also think it's a net positive. I have friends on both sides of this.
I'd flag though that your previous comment suggested more to me than "this is just you giving your probability"
> Give me your model, with numbers, that shows supporting Anthropic to be a bad bet, or admit you are confused and that you don't actually have good advice to give anyone.
I feel like there are much nicer ways to phase that last bit. I suspect that this is much of the reason you got disagreement points.
4
Fair enough. I'm frustrated and worried, and should have phrased that more neutrally. I wanted to make stronger arguments for my point, and then partway through my comment realized I didn't feel good about sharing my thoughts.
I think the best I can do is gesture at strategy games that involve private information and strategic deception like Diplomacy and Stratego and MtG and Poker, and say that in situations with high stakes and politics and hidden information, perhaps don't take all moves made by all players at literally face value. Think a bit to yourself about what each player might have in their uands, what their incentives look like, what their private goals might be. Maybe someone whose mind is clearer on this could help lay out a set of alternative hypotheses which all fit the available public data?
8
The private data is, pretty consistently, Anthropic being very similar to OpenAI where it matters the most and failing to mention in private policy-related settings its publicly stated belief on the risk that smarter-than-human AI will kill everyone.
6
What is this referring to?
People representing Anthropic argued against government-required RSPs. I don’t think I can share the details of the specific room where that happened, because it will be clear who I know this from.
Ask Jack Clark whether that happened or not.
4
Anthropic ppl had also said approximately this publicly. Saying that it's too soon to make the rules, since we'd end up mispecifying due to ignorance of tomorrow's models.
7
There's a big difference between regulation which says roughly "you must have something like an RSP", and regulation which says "you must follow these specific RSP-like requirements", and I think Mikhail is talking about the latter.
I personally think the former is a good idea, and thus supported SB-1047 along with many other lab employees. It's also pretty clear to me that locking in circa-2023 thinking about RSPs would have been a serious mistake, and so I (along with many others) am generally against very specific regulations because we expect they would on net increase catastrophic risk.
When do you think would be a good time to lock in regulation? I personally doubt RSP-style regulation would even help, but the notion that now is too soon/risks locking in early sketches, strikes me as in some tension with e.g. Anthropic trying to automate AI research ASAP, Dario expecting ASL-4 systems between 2025—the current year!—and 2028, etc.
4
Here I am on record supporting SB-1047, along with many of my colleagues. I will continue to support specific proposed regulations if I think they would help, and oppose them if I think they would be harmful; asking "when" independent of "what" doesn't make much sense to me and doesn't seem to follow from anything I've said.
My claim is not "this is a bad time", but rather "given the current state of the art, I tend to support framework/liability/etc regulations, and tend to oppose more-specific/exact-evals/etc regulations". Obviously if the state of the art advanced enough that I thought the latter would be better for overall safety, I'd support them, and I'm glad that people are working on that.
AFAIK Anthropic has not unequivocally supported the idea of "you must have something like an RSP" or even SB-1047 despite many employees, indeed, doing so.
1
To quote from Anthropic's letter to Govenor Newsom,
2
“we believe its benefits likely outweigh its costs” is “it was a bad bill and now it’s likely net-positive”, not exactly unequivocally supporting it. Compare that even to the language in calltolead.org.
Edit: AFAIK Anthropic lobbied against SSP-like requirements in private.
4
My guess is it's referring to Anthropic's position on SB 1047, or Dario's and Jack Clark's statements that it's too early for strong regulation, or how Anthropic's policy recommendations often exclude RSP-y stuff (and when they do suggest requiring RSPs, they would leave the details up to the company).
2
SB1047 was mentioned separately so I assumed it was something else. Might be the other ones, thanks for the links.
1
I wonder if this is due to
1. funding - the company need money to perform research on safety alignment (X risks, and assuming they do want to to this), and to get there they need to publish models so that they can 1) make profits from them, 2) attract more funding. A quick look on the funding source shows Amazon, Google, some other ventures, and some other tech companies
2. empirical approach - they want to take empirical approach to AI safety and would need some limited capable models
But both of the points above are my own speculations
Since this seems to be a crux, I propose a bet to @Zac Hatfield-Dodds (or anyone else at Anthropic): someone shows random people in San-Francisco Anthropic’s letter to Newsom on SB-1047. I would bet that among the first 20 who fully read at least one page, over half will say that Anthropic’s response to SB-1047 is closer to presenting the bill as 51% good and 49% bad than presenting it as 95% good and 5% bad.
Zac, at what odds would you take the bet?
(I would be happy to discuss the details.)
Sorry, I'm not sure what proposition this would be a crux for?
More generally, "what fraction good vs bad" seems to me a very strange way to summarize Anthropic's Support if Amended letter or letter to Governor Newsom. It seems clear to me that both are supportive in principle of new regulation to manage emerging risks, and offering Anthropic's perspective on how best to achieve that goal. I expect most people who carefully read either letter would agree with the preceeding sentence and would be open to bets on such a proposition.
Personally, I'm also concerned about the downside risks discussed in these letters - because I expect they both would have imposed very real costs, and reduced the odds of the bill passing and similar regulations passing and enduring in other juristictions. I nonetheless concluded that the core of the bill was sufficiently important and urgent, and downsides manageable, that I supported passing it.
2
I refer to the second letter.
I claim that a responsible frontier AI company would’ve behaved very differently from Anthropic. In particular, the letter said basically “we don’t think the bill is that good and don’t really think it should be passed” more than it said “please sign”. This is very different from your personal support for the bill; you indeed communicated “please sign”.
Sam Altman has also been “supportive of new regulation in principle”. These words sadly don’t align with either OpenAI’s or Anthropic’s lobbying efforts, which have been fairly similar. The question is, was Anthropic supportive of SB-1047 specifically? I expect people to not agree Anthropic was after reading the second letter.
3
I strongly disagree that OpenAI's and Anthropic's efforts were similar (maybe there's a bet there?). OpenAI formally opposed the bill without offering useful feedback; Anthropic offered consistent feedback to improve the bill, pledged to support it if amended, and despite your description of the second letter Senator Wiener describes himself as having Anthropic's support.
I also disagree that a responsible company would have behaved differently. You say "The question is, was Anthropic supportive of SB-1047 specifically?" - but I think this is the wrong question, implying that lack of support is irresponsible rather than e.g. due to disagreements about the factual question of whether passing the bill in a particular state would be net-helpful for mitigating catastrophic risks. The Support if Amended letter, for example, is very clear:
I don't expect further discussion to be productive though; much of the additional information I have is nonpublic, and we seem to have different views on what constitutes responsible input into a policy process as well as basic questions like "is Anthropic's engagement in the SB-1047 process well described as 'support' when the letter to Governor Newsom did not have the word 'support' in the subject line". This isn't actually a crux for me, but I and Senator Wiener seem to agree yes, while you seem to think no.
7
One thing to highlight, which I only learned recently, is that the norm when submitting letters to the governor on any bill in California is to include: "Support" or "Oppose" in the subject line to clearly state the company's position.
Anthropic importantly did NOT include "support" in the subject line of the second letter. I don't know how to read this as anything else than that Anthropic did not support SB1047.
2
Good point! That seems right; advocacy groups seem to think staff sorts letters by support/oppose/request for signature/request for veto in the subject line and recommend adding those to the subject line. Examples: 1, 2.
Anthropic has indeed not included any of that in their letter to Gov. Newsom.
5
(Could you link to the context?)
In RSP, Anthropic committed to define ASL-4 by the time they reach ASL-3.
With Claude 4 released today, they have reached ASL-3. They haven’t yet defined ASL-4.
Turns out, they have quietly walked back on the commitment. The change happened less than two months ago and, to my knowledge, was not announced on LW or other visible places unlike other important changes to the RSP. It’s also not in the changelog on their website; in the description of the relevant update, they say they added a new commitment but don’t mention removing this one.
Anthropic’s behavior...
[This comment is no longer endorsed by its author]
3
The Midas Project is a good place to keep track of AI company policy changes. Here is their note on the Anthropic change:
https://www.themidasproject.com/watchtower/anthropic-033125
1
I don't think it's accurate to say that they've "reached ASL-3?" In the announcement, they say
And it's also inaccurate to say that they have "quietly walked back on the commitment." There was no commitment to define ASL-4 by the time they reach ASL-3 in the updated RSP, or in versions 2.0 (released October last year), and 2.1 (see all past RSPs here). I looked at all mentions of ASL-4 in the lastest document, and this comes closest to what they have:
Which is what they did with Opus 4. Now they have indeed not provided a ton of details on what exactly they did to determine that the model has not reached ASL-4 (see report), but the comment suggesting that they "basically [didn't] tell anyone" feels inaccurate.
9
* According to the Anthropic’s chief scientist’s interview with Time today, they “work under the ASL-3 standard”. So they have reached the safety level—they’re working under it—and the commitment would’ve applied[1].
* There was a commitment in RSP prior to Oct last year. They did walk back on this commitment quietly: the fact they walk back on it was not announced in their posts and wasn’t noticed in the posts of others; only a single LessWrong comment in Oct 2024 from someone not affiliated with Anthropic mentions it. I think this is very much “quietly walking back” on a commitment.
* According to Midas, the commitment was fully removed in 2.1: “Removed commitment to “define ASL-N+ 1 evaluations by the time we develop ASL-N models””; a pretty hidden (I couldn’t find it!) revision changelog also attributes the decision to not maintain the commitment to 2.1. At the same time, the very public changelog on the RSP page only mentions new commitments and doesn’t mention the decision to “not maintain” this one.
1. ^
“they’re not sure whether they’ve reached the level of capabilities which requires ASL-3 and decided to work under ASL-3, to be revised if they find out the model only requires ASL-2” could’ve been more accurate, but isn’t fundamentally different IMO. And Anthropic is taking the view that by the time you develop a model which might be ASL-n, the commitments for ASL-n should trigger until you rule that out. It’s not even clear what a different protocol could be, if you want to release a model that might be at ASL-n. Release it anyway and contain it only after you’ve confirmed it’s at ASL-n?
0
Meta-level comment now that this has been retracted.
Anthropic's safety testing for Claude 4 is vastly better than DeepMind's testing of Gemini. When Gemini 2.5 Pro was released there was no safety testing info and even the model card that was eventually released is extremely barebones to compared to what Anthropic put out.
DeepMind should be embarrassed by this. The upcoming PauseCon protest outside DeepMind's headquarters in London will focus on this failure.
I directionally agree!
Btw, since this is a call to participate in a PauseAI protest on my shortform, do your colleagues have plans to do anything about my ban from the PauseAI Discord server—like allowing me to contest it (as I was told there was a discussion of making a procedure for) or at least explaining it?
Because it’s lowkey insane!
For everyone else, who might not know: a year ago I, in context, on the PauseAI Discord server, explained my criticism of PauseAI’s dishonesty and, after being asked to, shared proofs that Holly publicly lied about our personal communications, including sharing screenshots of our messages; a large part of the thread was then deleted by the mods because they were against personal messages getting shared, without warning (I would’ve complied if asked by anyone representing a server to delete something!) or saving/allowing me to save any of the removed messages in the thread, including those clearly not related to the screenshots that you decided were violating the server norms; after a discussion of that, the issue seemed settled and I was asked to maybe run some workshops for PauseAI to improve PauseAI’s comms/proofreading/factchecking; and then, mo...
2
reached out to Joep asking for the record, he said “Holly wanted you banned” and it was a divisive topic in the team.
-1
Uhh yeah sorry that there hasn't been a consistent approach. In our defence I believe yours in the only complex moderation case that PauseAI Global has ever had to deal with so far and we've kinda dropped the ball on figuring out how to handle it.
For context my take is that you've raised some valid points. And also you've acted poorly in some parts of this long running drama. And most importantly you've often acted in a way that seems almost optimised to turn people off. Especially for people not familiar with LessWrong culture, the inferential distance between you and many people is so vast that they really cannot understand you at all. Your behavior pattern matches to trolling / nuisance attention seeking in many ways and I often struggle to communicate to more normie types why I don't think you're insane or malicious.
I do sincerely hope to iron this out some time and put in place actual systems for dealing with similar disputes in the future. And I did read over the original post + Google doc a few months ago to try to form my own views more robustly. But this probably won't be a priority for PauseAI Global in the immediate future. Sorry.
0
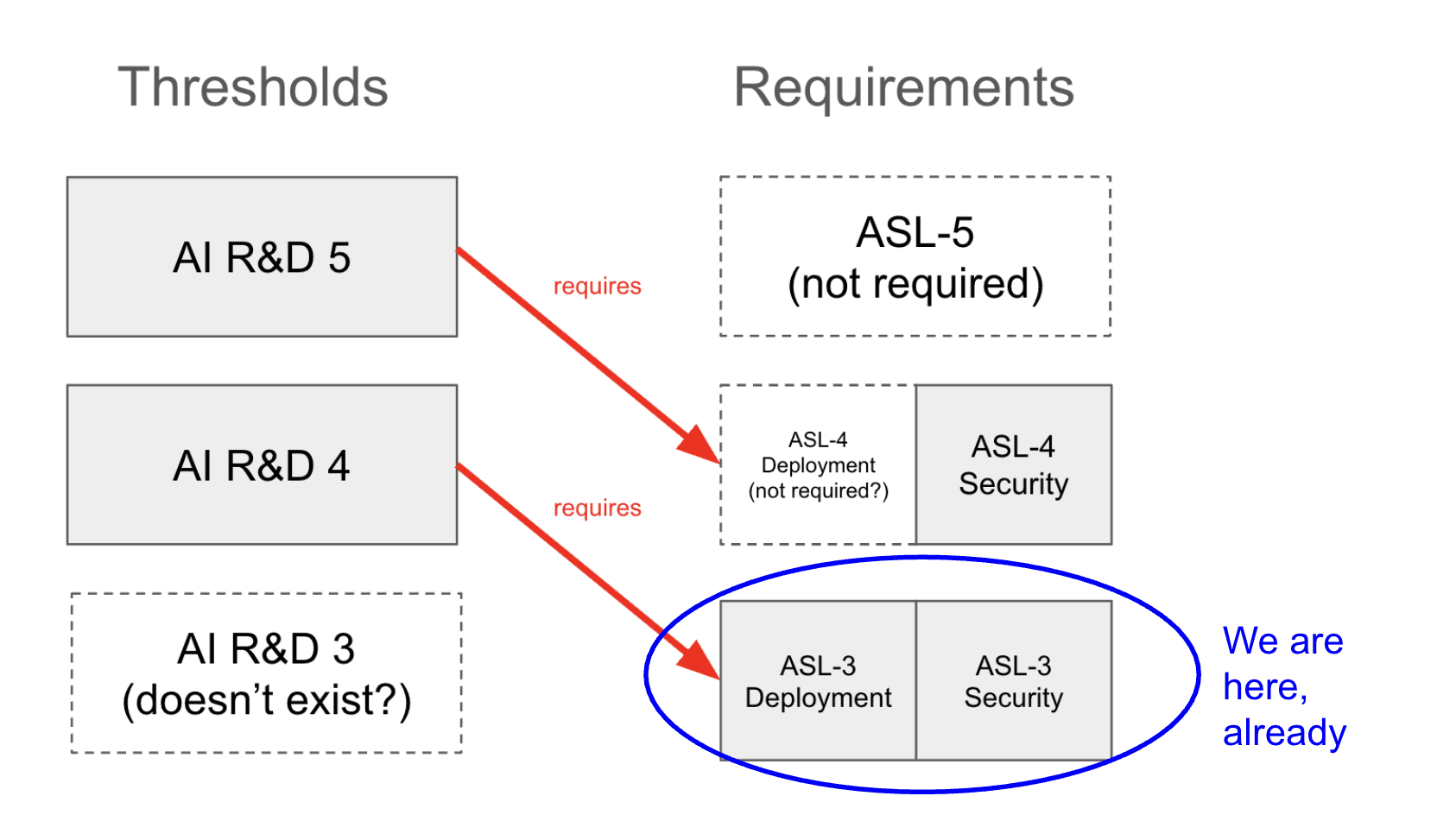
This is false. Our ASL-4 thresholds are clearly specified in the current RSP—see "CBRN-4" and "AI R&D-4". We evaluated Claude Opus 4 for both of these thresholds prior to release and found that the model was not ASL-4. All of these evaluations are detailed in the Claude 4 system card.
I wrote the article Mikhail referenced and wanted to clarify some things.
The thresholds are specified, but the original commitment says, "We commit to define ASL-4 evaluations before we first train ASL-3 models (i.e. before continuing training beyond when ASL-3 evaluations are triggered). Similarly, we commit to define ASL-5 evaluations before training ASL-4 models, and so forth," and, regarding ASL-4, "Capabilities and warning sign evaluations defined before training ASL-3 models."
The latest RSP says this of CBRN-4 Required Safeguards, "We expect this threshold will require the ASL-4 Deployment and Security Standards. We plan to add more information about what those entail in a future update."
Additionally, AI R&D 4 (confusingly) corresponds to ASL-3 and AI R&D 5 corresponds to ASL-4. This is what the latest RSP says about AI R&D 5 Required Safeguards, "At minimum, the ASL-4 Security Standard (which would protect against model-weight theft by state-level adversaries) is required, although we expect a higher security standard may be required. As with AI R&D-4, we also expect an affirmative case will be required."
2
I agree that the current thresholds and terminology are confusing, but it is definitely not the case that we just dropped ASL-4. Both CBRN-4 and AI R&D-4 are thresholds that we have not yet reached, that would mandate further protections, and that we actively evaluated for and ruled out in Claude Opus 4.
AFAICT, now that ASL-3 has been implemented, the upcoming AI R&D threshold, AI R&D-4, would not mandate any further security or deployment protections. It only requires ASL-3. However, it would require an affirmative safety case concerning misalignment.
I assume this is what you meant by "further protections" but I just wanted to point this fact out for others, because I do think one might read this comment and expect AI R&D 4 to require ASL-4. It doesn't.
I am quite worried about misuse when we hit AI R&D 4 (perhaps even moreso than I'm worried about misalignment) — and if I understand the policy correctly, there are no further protections against misuse mandated at this point.
6
Not meaning to imply that Anthropic has dropped ASL-4! Just wanted to call out that this is does represent a change from the Sept. 2023 RSP.
Regardless, it seems like Anthropic is walking back its previous promise: "We have decided not to maintain a commitment to define ASL-N+1 evaluations by the time we develop ASL-N models." The stance that Anthropic takes to its commitments—things which can be changed later if they see fit—seems to cheapen the term, and makes me skeptical that the policy, as a whole, will be upheld. If people want to orient to the rsp as a provisional intent to act responsibly, then this seems appropriate. But they should not be mistaken nor conflated with a real promise to do what was said.
7
Oops. Thank you and apologies.
5
FYI, I was (and remain to this day) confused by AI R&D 4 being called an "ASL-4" threshold. AFAICT as an outsider, ASL-4 refers to a set of deployment and security standards that are now triggered by dangerous capability thresholds, and confusingly, AI R&D 4 corresponds to the ASL-3 standard.
AI R&D 5, on the other hand, corresponds to ASL-4, but only on the security side (nothing is said about the deployment side, which matters quite a bit given that Anthropic includes internal deployment here and AI R&D 5 will be very tempting to deploy internally)
I'm also confused because the content of both AI R&D 4 and AI R&D 5 is seemingly identical to the content of the nearest upcoming threshold in the October 2024 policy (which I took to be the ASL-3 threshold). A rough sketch of what I think happened:
A rough sketch of my understanding of the current policy:
When I squint hard enough at this for a while, I think I can kind of see the logic: the model likely to trigger the CBRN threshold requiring ASL-3 seems quite close, whereas we might be further from the very-high threshold that was the October AI R&D threshold (now AI R&D 4), so the October AI R&D threshold was just bumped to the next level (and the one after that since causing dramatic scaling of effective compute is even harder than being a entry-level remote worker... maybe) with some confidence that we were still somewhat far away from it and thus it can be treated effectively as today's upcoming + to-be-defined (what would have been called n+1) threshold.
I just get lost when we call it an ASL-4 threshold (it's not, it's an ASL-3 threshold), and also it mostly makes me sad that these thresholds are so high because I want Anthropic to get some practice reps in implementing the RSP before it's suddenly hit with an endless supply of fully automated remote workers (plausibly the next threshold, AI R&D 4, requiring nothing more than the deployment + security standards Anthropic already put in place as of today
Worked on this with Demski. Video, report.
Any update to the market is (equivalent to) updating on some kind of information. So all you can do is dynamically choose what to do or do not update on.* Unfortunately, whenever you choose not to update on something, you are giving up on the asymptotic learning guarantees of policy market setups. So the strategic gains from updatelesness (like not falling into traps) are in a fundamental sense irreconcilable with the learning gains from updatefulness. That doesn't prevent that you can be pretty smart about deciding what to update on exactly... but due to embededness problems and the complexity of the world, it seems to be the norm (rather than the exception) that you cannot be sure a priori of what to update on (you just have to make some arbitrary choices).
*For avoidance of doubt, what matters for whether you have updated on X is not "whether you have heard about X", but rather "whether you let X factor into your decisions". Or at least, this is the case for a sophisticated enough external observer (assessing whether you've updated on X), not necessarily all observers.
I think the first question to think about is how to use them to make CDT decisions. You can create a market about a causal effect if you have control over the decision and you can randomise it to break any correlations with the rest of the world, assuming the fact that you’re going to randomise it doesn’t otherwise affect the outcome (or bettors don’t think it will).
Committing to doing that does render the market useless for choosing policy, but you could randomly decide whether to randomise or to make the decision via whatever the process you actually want to use, and have the market be conditional on the former. You probably don’t want to be randomising your policy decisions too often, but if liquidity wasn’t an issue you could set the probability of randomisation arbitrarily low.
Then FDT… I dunno, seems hard.
6
Yep!
“If I randomize the pick, and pick A, will I be happy about the result?” “If I randomize the pick, and pick B, will I be happy about the result?”
Randomizing 1% of the time and adding a large liquidity subsidy works to produce CDT.
6
I agree with all of this! A related shortform here.
4
An interesting development in the time since your shortform was written is that we can now try these ideas out without too much effort via Manifold.
Anyone know of any examples?
I do not believe Anthropic as a company has a coherent and defensible view on policy. It is known that they said words they didn't hold while hiring people (and they claim to have good internal reasons for changing their minds, but people did work for them because of impressions that Anthropic made but decided not to hold). It is known among policy circles that Anthropic's lobbyists are similar to OpenAI's.
From Jack Clark, a billionaire co-founder of Anthropic and its chief of policy, today:

Dario is talking about countries of geniuses in datacenters in the...
1
I’ve only seen this excerpt, but it seems to me like Jack isn’t just arguing against regulation because it might slow progress - and rather something more like:
“there’s some optimal time to have a safety intervention, and if you do it too early because your timeline bet was wrong, you risk having worse practices at the actually critical time because of backlash”
This seems probably correct to me? I think ideally we’d be able to be cautious early and still win the arguments to be appropriately cautious later too. But empirically, I think it’s fair not to take as a given?
People are arguing about the answer to the Sleeping Beauty! I thought this was pretty much dissolved with this post's title! But there are lengthy posts and even a prediction market!
Sleeping Beauty is an edge case where different reward structures are intuitively possible, and so people imagine different game payout structures behind the definition of “probability”. Once the payout structure is fixed, the confusion is gone. With a fixed payout structure&preference framework rewarding the number you output as “probability”, people don’t have a disagreem...
4
As the creator of the linked market, I agree it's definitional. I think it's still interesting to speculate/predict what definition will eventually be considered most natural.
[RETRACTED after Scott Aaronson’s reply by email]
I'm surprised by Scott Aaronson's approach to alignment. He has mentioned in a talk that a research field needs to have at least one of two: experiments or a rigorous mathematical theory, and so he's focusing on the experiments that are possible to do with the current AI systems.
The alignment problem is centered around optimization producing powerful consequentialist agents appearing when you're searching in spaces with capable agents. The dynamics at the level of superhuman general agents are not something ...
[This comment is no longer endorsed by its author]
Curated and popular this week
It seems to me that other possibilities exist, besides "has model with numbers" or "confused." For example, that there are relevant ethical considerations here which are hard to crisply, quantitatively operationalize!
One such consideration which feels especially salient to me is the heuristic that before doing things, one should ideally try to imagine how people would react, upon learning what you did. In this case the action in question involves creating new minds vastly smarter than any person, which pose double-digit risk of killing everyone on Earth, so my guess is that the reaction would entail things like e.g. literal worldwide riots. If so, this strikes me as the sort of consideration one should generally weight more highly than their idiosyncratic utilitarian BOTEC.