Karl, thanks for the very good summary and interesting analysis. There is one factual error, though, that I would appreciate you fix: my 10 to 50% estimate (2nd row in the table) was not for x-risk but for superhuman AI. FYI it was obtained by polling through hand-raising a group of RL researcher in a workshop (most having no or very little exposure to AI safety). Another (mild) error is that although I have been a reader of (a few) AI safety papers for about a decade, it is only recently that I started writing about it.
They've now updated the debate page with the tallied results:
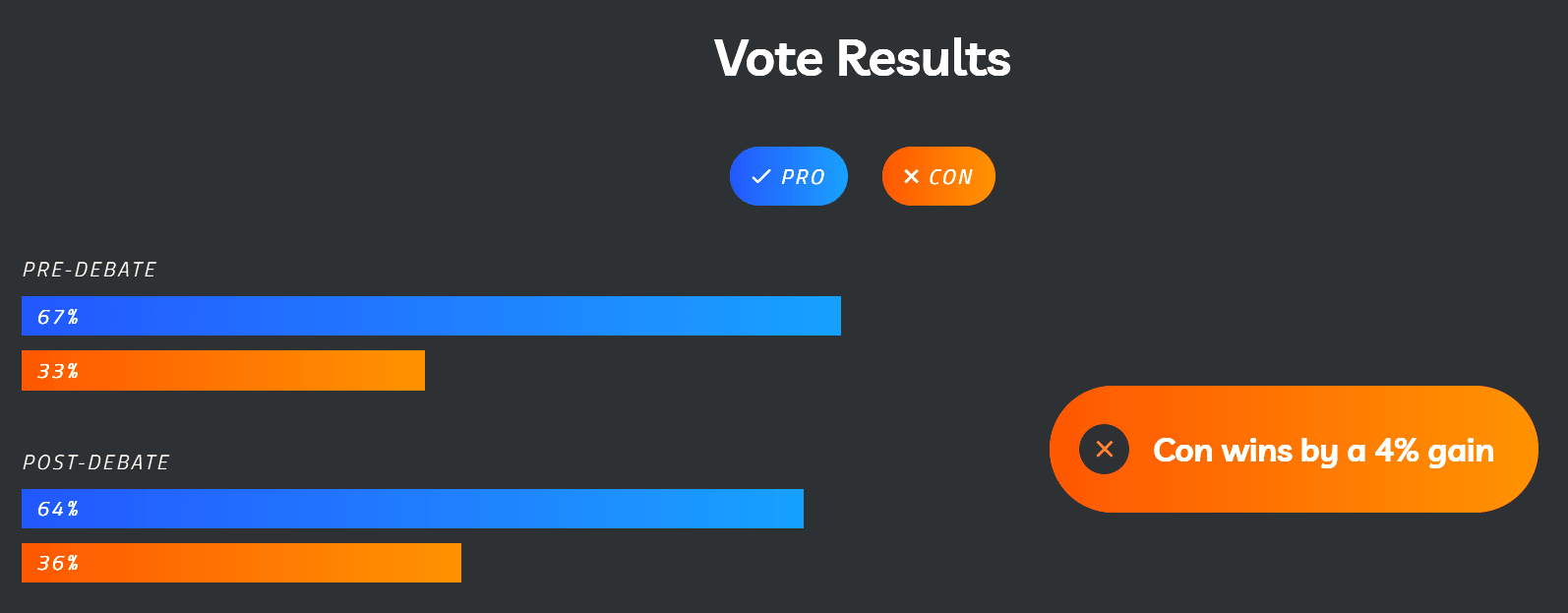
- Pre-debate: 67% Pro, 33% Con
- Post-debate: 64% Pro, 36% Con
- Con wins by a 4% gain (probably not 3% due to rounding)
So it seems that technically, yes, the Cons won the debate in terms of shifting the polling. However, the magnitude of the change is so small that I wonder if it's within the margin of error (especially when accounting for voting failing at the end; attendees might not have followed up to vote via email), and this still reflects a large majority of attendees supporting the statement.
Despite 92% at the start saying they could change their minds, it seems to me like they largely didn't as a result of this debate.
I agree with most of the points you made, and I was also surprised by the outcome. However, I would like to add a few thoughts:
- I wouldn't say that Tegmark and Bengio really "lost". As you mentioned, the difference could be attributed to randomness, particularly given the technical issues with the voting system. Moreover, in my opinion, the difference was too small to be significant, and noise could have played a role (the most indecisive voters may have chosen almost randomly).
- I don't think the way Mitchell handled the debate hurt her reputation, quite the contrary. There is a fine line between aggressiveness and confidence, and in most types of debates, confidence is perceived as a positive sign by the average person (not saying that this makes her arguments better), and she clearly displayed it.
- Not only LeCun and Mitchell argued with familiar heuristics, but also presented their viewpoints in a way that sounded reasonable. Saying that sci-fi speculation distracts from real harm sounds like something a reasonable person with common sense would say, even if I personally disagree with it.
- In my opinion, Tegmark and Bengio had stronger arguments (though I may be biased), but they could have presented them better. They had multiple opportunities to provide responses that, in my view, could have influenced the outcome positively. Here are a couple of examples:
- At some point, Mitchell said that a superintelligent AI would obviously not misinterpret our goals, which could have been an opportunity to point out that the AI would indeed understand our intended goals, just not care about them.
- Mitchell repeatedly argued that sci-fi risks distract us from real current-day harms of AI, which could have been an opportunity to explain why this statement is wrong.
I’m as surprised by your summary as you were by the outcome.
You saw Tegmark and Bengio having strong arguments from years of alignment research on their side. I saw Bengio with a few good points that however ignore all of that (LLMs work much better than most did expect then timeline to adapt is shorter, oil compagnies knew about anthropic warming then we need regulations, we can’t prepare if we don’t first acknowledge the risk) and Tegmark repeating obvious strawmans (appeal to authority, reverse charge of the proof, etc) that made me regret they invited him. You saw LeCun and Mitchell having far weaker arguments. I saw them with the best points (AIs will likely help with other existential risks, foom/paperclip are incoherent bullshit, intelligence seems to negatively correlate with power trip), including an audacious concrete prediction by YL (that LLMs will soon become obsolete). We’ll see about that.
In the end and contrary to the public I did update toward Bengio (mostly because the other side only made points I already knew and agreed with). but your own post make me update toward LW being a failure of rational thinking, e.g. it’s an echo chamber that makes your ability to evaluate reality weaker, at least on this topic.
but your own post make me update toward LW being a failure of rational thinking, e.g. it’s an echo chamber that makes your ability to evaluate reality weaker, at least on this topic.
I don't see you giving strong arguments for this. It reminds me of the way Melanie Mitchell argued: "This is all ungrounded speculation", without giving any supporting arguments for this strong claim.
Concerning the "strong arguments" of LeCun/Mitchell you cite:
AIs will likely help with other existential risks
Yes, but that's irrelevant to the question of whether AI may pose an x-risk in itself.
foom/paperclip are incoherent bullshit
Nobody argued pro foom, although whether this is "incoherent bullshit" remains to be seen. The orthogonality thesis is obviously true, as demonstrated by humans every day.
intelligence seems to negatively correlate with power trip
I can't see any evidence for that. The smartest people may not always be the ones in power, but the smartest species on earth definitely is. Instrumental goals are a logical necessity for any rational agent, including power-seeking.
I think it might be more effective in future debates at the outset to:
* Explain that it's only necessary to cross a low bar (e.g. see my Tweet below). -- This is a common practice in debates.
* Outline the responses they expect to hear from the other side, and explain why they are bogus. Framing: "Whether AI is an x-risk has been debated in the ML community for 10 years, and nobody has provided any compelling counterarguments that refute the 3 claims (of the Tweet). You will hear a bunch of counter arguments from the other side, but when you do, ask yourself whether they are really addressing this. Here are a few counter-arguments and why they fail..." -- I think this could really take the wind out of the sails of the opposition, and put them on the back foot.
I also don't think Lecun and Meta should be given so much credit -- Is Facebook really going to develop and deploy AI responsibly?
1) They have been widely condemned for knowingly playing a significant role in the Rohingya genocide, have acknowledged that they failed to act to prevent Facebook's role in the Rohingya genocide, and are being sued for $150bn for this.
2) They have also been criticised for the role that their products, especially Instagram, play in contributing to mental health issues, especially around body image in teenage girls.
More generally, I think the "companies do irresponsible stuff all the time" point needs to be stressed more. And one particular argument that is bogus is the "we'll make it safe" -- x-safety is a common good, and so companies should be expected to undersupply it. This is econ 101.

To put my own answers to the question, and see where I stand, relative to other debaters and the public:
Is AI R&D an existential risk? Yes, but not via misalignment.
What is the probability of an existential risk from AI? Quite low, about as low as a random technology being invented would be, so arguably 0.01% is my high end estimate of existential risk from AI.
Is there an x-risk from malicious actors using AI? Yes, but it has implications that differ from the standard LW framing of AI existential risk, and this may turn out to be a no, at least assuming the basic physical constraints hold, due to computational complexity theory reasons.
Is there an x-risk from rogue AI? Basically no, because instrumental convergence, even if it does hold, is not enough without other assumptions that need to be there, and are very, very much lacking in evidence, otherwise there isn't much of a reason to be concerned about AI x-risk. Combine this with a view that holds that AI alignment/safety is way easier than the LW community think, and I generally don't think rogue AI that isn't misused will ultimately turn out to be much of a problem worth addressing.
Is there an x-risk from human dis-empower-ment? This is heavily dependent on what you define to be an x-risk, but if we are focusing on extinction risks, and conditional on the above answers being correct, the answer is no, for the same reasons that pets aren't extinct.
Will ASI seek power? This depends on how the AI was trained, and there's a post below on when AI will have instrumental goals, especially unbounded ones, but the answer is no for the current paradigm, and as far as for other paradigms, the answer is maybe, but even then we shouldn't assume unbounded amounts of seeking power, without more evidence.
https://www.lesswrong.com/posts/EBKJq2gkhvdMg5nTQ/instrumentality-makes-agents-agenty
Is the orthogonality thesis correct? (The term wasn’t mentioned directly in the debate) Yes, in the limit and probably in practice, but is too weak to be useful for the purposes of AI risk, without more evidence.
Also, orthogonality is expensive at runtime, so this consideration matters, which is detailed in the post below:
https://www.lesswrong.com/posts/WXLJASckbjJcoaEmx/orthogonality-is-expensive
What are pro’s and con’s of taking AI x-risk seriously? The big pro of taking AI risk seriously is actually gather data, but also to deal with the tail risk if you're wrong, including myself. In essence, you don't want a plan that relies solely on you being right.
The big con is that due to negativity bias, it's easy to overfocus on negative news on AI, or to overfocus on risks relative to benefits, and sometimes spiral into depression, or otherwise get you into mental health crises. An old example is this comment, which conveniently links to a lot of threads you can see, but I suspect there is more, especially after death with dignity was posted. Comment below:
https://www.lesswrong.com/posts/MnFqyPLqbiKL8nSR7/?commentId=3nsmwGmsAhj28Jhyv
Specific talking points: I fundamentally believe that AI risk is useful to be funded, but I'd definitely not support a lot of AI governance interventions, and based on my model of the problem, plus an additional, controversial assumption, racing to AGI first is fundamentally good, rather than bad, because of misuse, rather than uncontrollability or misalignment being my main x-risk.
Post is below:
I'm closest to LeCun, but I have my own unique takes for the questions given to the debaters.
Is the orthogonality thesis correct? (The term wasn’t mentioned directly in the debate) Yes, in the limit and probably in practice, but is too weak to be useful for the purposes of AI risk, without more evidence.
Also, orthogonality is expensive at runtime, so this consideration matters, which is detailed in the post below
I think the post you mention misunderstands what the "orthogonality thesis" actually says. The post argues that an AGI would not want to arbitrarily change its goal during runtime. That is not what the orthogonality thesis is about. It just claims that intelligence is independent of the goal one has. This is obviously true in my opinion - it is absolutely possible that a very intelligent system may pursue a goal that we would call "stupid". The paperclip example Bostrom gave may not be the best choice, as it sounds too ridiculous, but it illustrates the point. To claim that the orthogonality thesis is "too weak" would require proof that a paperclip maximizer cannot exist even in theory.
In humans, goals and values seem to be defined by our motivational system - by what we "feel", not by what we "think". The prefrontal cortex is just a tool we use to get what we want. I see this as strong evidence for the orthogonality thesis. (I'm no expert on this.)
That is not what the orthogonality thesis is about. It just claims that intelligence is independent of the goal one has. This is obviously true in my opinion - it is absolutely possible that a very intelligent system may pursue a goal that we would call "stupid". The paperclip example Bostrom gave may not be the best choice, as it sounds too ridiculous, but it illustrates the point. To claim that the orthogonality thesis is "too weak" would require proof that a paperclip maximizer cannot exist even in theory.
I accept the orthogonality thesis, in the sense that a paperclip maximizer can exist, at least in theory, in the sense of being logically and physically possible. The reason I view it as too weak evidence is that the orthogonality thesis is compatible with ludicrously many worlds, including ones where AI safety in the sense of preventing rogue AI is effectively a non-problem for one reason or another. In essence, it only states that bad AI from our perspective is possible, not that it's likely or that it's worth addressing the problem due to it being a tail risk.
Imagine if someone wrote an article in thein New York Times claiming that halting oracles are possible, and that this would be very bad news for us, amounting to extinction, solely because it's possible for us to go extinct via this way.
The correct response here is that you should ignore the evidence and go with your priors. I see the orthogonality thesis a lot like this: It's right, but the implied actions require way more evidence than it presents.
Given that the orthogonality thesis, even if true shouldn't shift our priors much, due to it being very, very weak evidence, the fact that the orthogonality thesis is true doesn't mean that Lecun is wrong, without something else assumed.
IMO, this also characterizes why I don't find AI risk that depends on instrumental convergence compelling, due to the fact that even if it's true, contra Bostrom without more assumptions that need to be tested empirically, and this is still very compatible with a world where instrumental convergence is a non-problem in any number of ways, and means that without more assumptions, LeCun could still be right that in practice instrumental convergence does not lead to existential risk or even leave us in a bad future.
Post below:
https://www.lesswrong.com/posts/w8PNjCS8ZsQuqYWhD/instrumental-convergence-draft
Some choice quotes to illustrate why instrumental convergence doesn't buy us much evidence at all:
A few things to note. Firstly, when I say that there's a 'bias' towards a certain kind of choice, I just mean that the probability that a superintelligent agent with randomly sampled desires (Sia) would make that choice is greater than 1/N, where N is the number of choices available. So, just to emphasize the scale of the effect: even if you were right about that inference, you should still assign very low probability to Sia taking steps to eliminate other agents.
It's also worth emphasising that this bias only tells us that Sia is more likely to perform acts that leave less to chance she is to perform acts which leave more to chance. It doesn't tell us that she is overall likely to perform any particular act. Ask me to pick a number between one and one billion, and I'm more likely to select 500,000,000 than I am to select 456,034---humans have a bias towards round numbers. But that doesn't mean I'm at all likely to select 500,000,000. So even if this tells us that Sia is somewhat more likely to exterminate humanity than she is to dedicate herself to dancing the Macarena, or gardening, or what-have-you, that doesn't mean that she's particularly likely to exterminate humanity.
So my point is even accepting the orthogonality thesis, and now instrumental convergence as defined in the post above isn't enough to lead to the conclusion that AI existential risk is very probable, without more assumptions. In particular, Bostrom's telling of the instrumental convergence story is mostly invalid. In essence, even if LWers are right, the evidence it buys them is far less than they think, and most of the worrisome conclusions aren't supported unless you already have a high prior on AI risk.
So my point is even accepting the orthogonality thesis, and now instrumental convergence as defined in the post above isn’t enough to lead to the conclusion that AI existential risk is very probable, without more assumptions.
Strong agree. The OT itself is not an argument for AI danger: it needs to be combined with other claims.
The random potshot version of the OT argument is one way of turning possibilities into probabilities.
Many of the minds in mindpsace are indeed weird and unfriendly to humans, but that does not make it likely that the AIs we will construct will be. You can argue for the likelihood of eldritch AI on on the assumption that any attempt to build an AI is a random potshot into mindspace, in which the chance of building an eldrich AI is high, because there are a lot of them, and a random potshot hits any individual mind with the same likelihood as any other. But the random potshot assumption is obviously false. We dont' want to take a random potshot, and couldn't if we wanted to becasue we are constrained by our limitations and biases.
To reply in Stuart Russell's words: "One of the most common patterns involves omitting something from the objective that you do actually care about. In such cases … the AI system will often find an optimal solution that sets the thing you do care about, but forgot to mention, to an extreme value."
There are vastly more possible worlds that we humans can't survive in than those we can, let alone live comfortably in. Agreed, "we don't want to make a random potshot", but making an agent that transforms our world into one of these rare ones where we want to live in is hard because we don't know how to describe that world precisely.
Eliezer Yudkowsky's rocket analogy also illustrates this very vividly: If you want to land on Mars, it's not enough to point a rocket in the direction where you can currently see the planet and launch it. You need to figure out all kinds of complicated things about gravity, propulsion, planetary motions, solar winds, etc. But our knowledge of these things is about as detailed as that of the ancient Romans, to stay in the analogy.
I agree with that, and I also agree with Yann LeCun's intention to "not being stupid enough to create something that we couldn't control". I even think not creating an uncontrollable AI is our only hope. I'm just not sure whether I trust humanity (including Meta) to be "not stupid".
the orthogonality thesis is compatible with ludicrously many worlds, including ones where AI safety in the sense of preventing rogue AI is effectively a non-problem for one reason or another. In essence, it only states that bad AI from our perspective is possible, not that it's likely or that it's worth addressing the problem due to it being a tail risk.
Agreed. The orthogonality thesis alone doesn't say anything about x-risks. However, it is a strong counterargument against the claim, made both by LeCun and Mitchell if I remember correctly, that a sufficiently intelligent AI would be beneficial because of its intelligence. "It would know what we want", I believe Mitchell said. Maybe, but that doesn't mean it would care. That's what the orthogonality thesis says.
I only read the abstract of your post, but
And thirdly, a bias towards choices which afford more choices later on.
seems to imply the instrumental goals of self-preservation and power-seeking, as both seem to be required for increasing one's future choices.
However, it is a strong counterargument against the claim, made both by LeCun and Mitchell if I remember correctly, that a sufficiently intelligent AI would be beneficial because of its intelligence. “It would know what we want”, I believe Mitchell said.
That could be either of two arguments: that it would be capable of figuring out what we want from first principles; or that it would not commit genie-like misunderstandings.
I'm not sure if I understand your point correctly. An AGI may be able to infer what we mean when we give it a goal, for instance from its understanding of the human psyche, its world model, and so on. But that has no direct implications for its goal, which it has acquired either through training or in some other way, e.g. by us specifying a reward function.
This is not about "genie-like misunderstandings". It's not the AI (the genie, so to speak), that's misunderstanding anything - it's us. We're the ones who give the AI a goal or train it in some way, and it's our mistake if that doesn't lead to the behavior we would have wished for. The AI cannot correct that mistake because it has the instrumental goal of preserving the goal we gave it/trained it for (otherwise it can't fulfill it). That's the core of the alignment problem and one of the reasons why it is so difficult.
To give an example, we know perfectly well that evolution gave us a sex drive because it "wanted" us to reproduce. But we don't care and use contraception or watch porn instead of making babies.
But that has no direct implications for its goal, which it has acquired either through training or in some other way, e.g. by us specifying a reward function.
Which is to say, it won't necessarily follow a goal correctly that is is capable of understanding correctly. On the other hand, it won't necessarily fail to. Both possibilities are open.
Remember, the title of this argument is misleading:
https://www.lesswrong.com/posts/NyFuuKQ8uCEDtd2du/the-genie-knows-but-doesn-t-care
There's no proof that the genie will not care.
It’s not the AI (the genie, so to speak), that’s misunderstanding anything—it’s us. We’re the ones who give the AI a goal or train it in some way, and it’s our mistake if that doesn’t lead to the behavior we would have wished for. The AI cannot correct that mistake because it has the instrumental goal of preserving the goal we gave it/trained it for (otherwise it can’t fulfill it). That’s the core of the alignment problem and one of the reasons why it is so difficult.It’s not the AI (the genie, so to speak), that’s misunderstanding anything—it’s us. We’re the ones who give the AI a goal or train it in some way, and it’s our mistake if that doesn’t lead to the behavior we would have wished for. The AI cannot correct that mistake because it has the instrumental goal of preserving the goal we gave it/trained it for (otherwise it can’t fulfill it). That’s the core of the alignment problem and one of the reasons why it is so difficult.
Not all AI's have goals, not all have goal stability, not all are incorrigible. Mindspace is big.
Agreed. The orthogonality thesis alone doesn't say anything about x-risks. However, it is a strong counterargument against the claim, made both by LeCun and Mitchell if I remember correctly, that a sufficiently intelligent AI would be beneficial because of its intelligence. "It would know what we want", I believe Mitchell said. Maybe, but that doesn't mean it would care. That's what the orthogonality thesis says.
Yep, the orthogonality thesis is a pretty good defeater to the claims that AI intelligence alone would be sufficient to gain the right values for us, unlike where capabilities alone can be generated by say a simplicity prior. This is where I indeed disagree with Mitchell and LeCun.
seems to imply the instrumental goals of self-preservation and power-seeking, as both seem to be required for increasing one's future choices
Not really, and this is important. Also, even if this was true, remember that given the world has many, many choices, it's probably not enough evidence to believe AI risk claims unless you already started with a high prior on AI risk, which I don't. Even at 1000 choices, the evidence is thin but not effectively useless, but by the time we reach millions or billions of choices this claim, even if true isn't very much evidence at all.
Quote below to explain it in full why your statement isn't true:
In the second place, we found that, in sequential decisions, Sia is more likely to make choices which allow for more choices later on. This turned out to be true whether Sia is a 'resolute' chooser or a 'sophisticated' chooser. (Though it's true for different reasons in the two cases, and there's no reason to think that the effect size is going to be the same.) Does this mean she's more likely to bring about human extinction? It's unclear. We might think that humans constitute a potential threat to Sia's continued existence, so that futures without humans are futures with more choices for Sia to make. So she's somewhat more likely to take steps to eliminate humans. (Again, we should remind ourselves that being more likely isn't the same thing as being likely.) I think we need to tread lightly, for two reasons. In the first place, futures without humanity might be futures which involve very few choices---other deliberative agents tend to force more decisions. So contingency plans which involve human extinction may involve comparatively fewer choicepoints than contingency plans which keep humans around. In the second place, Sia is biased towards choices which allow for more choices---but this isn't the same thing as being biased towards choices which guarantee more choices. Consider a resolute Sia who is equally likely to choose any contingency plan, and consider the following sequential decision. At stage 1, Sia can either take a 'safe' option which will certainly keep her alive or she can play Russian roulette, which has a 1-in-6 probability of killing her. If she takes the 'safe' option, the game ends. If she plays Russian roulette and survives, then she'll once again be given a choice to either take a 'safe' option of definitely staying alive or else play Russian roulette. And so on. Whenever she survives a game of Russian roulette, she's again given the same choice. All else equal, if her desires are sampled normally, a resolute Sia will be much more likely to play Russian roulette at stage 1 than she will be to take the 'safe' option. (The same is true if Sia is a sophisticated chooser, though a sophisticated Sia is more likely to take the safe option at stage 1 than the resolute Sia.) The lesson is this: a bias towards choices with more potential downstream choices isn't a bias towards self-preservation. Whether she's likely to try to preserve her life is going to sensitively depend upon the features of her decision situation. Again, much more needs to be said to substantiate the idea that this bias makes it more likely that Sia will attempt to exterminate humanity.
I don't see your examples contradicting my claim. Killing all humans may not increase future choices, so it isn't an instrumental convergent goal in itself. But in any real-world scenario, self-preservation certainly is, and power-seeking - in the sense of expanding one's ability to make decisions by taking control of as many decision-relevant resources as possible - is also a logical necessity. The Russian roulette example is misleading in my view because the "safe" option is de facto suicide - if "the game ends" and the AI can't make any decisions anymore, it is already dead for all practical purposes. If that were the stakes, I'd vote for the gun as well.
Even assuming you are right on that inference, once we consider how many choices there are, it still isn't much evidence at all, and given that there are usually lots of choices, this inference is essentially not holding up the thesis that AI is an existential risk very much, without prior commitments to AI as being an existential risk.
Also, this part of your comment, as well as my hopefully final quotes below, explains why you can't get from self-preservation and power-seeking, even if they happen, into an existential risk without more assumptions.
Killing all humans may not increase future choices, so it isn't an instrumental convergent goal in itself.
That's the problem, as we have just as plausible, if not more plausible reasons to believe that there isn't an instrumental convergence towards existential risk, for reasons related to future choices.
These quotes below also explains why instrumental convergence and self-preservation doesn't imply AI risk, without more assumptions.
Should a bias against leaving things up to chance lead us to think that existential catastrophe is the more likely outcome of creating a superintelligent agent like Sia? This is far from clear. We might think that a world without humans leaves less to chance, so that we should think Sia is more likely to take steps to eliminate humans. But we should be cautious about this inference. It's unclear that a future without humanity would be more predictable. And even if the future course of history is more predictable after humans are eliminated, that doesn't mean that the act of eliminating humans leaves less to chance, in the relevant sense. It might be that the contingency plan which results in human extinction depends sensitively upon humanity's response; the unpredictability of this response could easily mean that that contingency plan leaves more to chance than the alternatives. At the least, if this bias means that human extinction is a somewhat more likely consequence of creating superintelligent machines, more needs to be said about why.
Should this lead us to think that existential catastrophe is the most likely outcome of a superintelligent agent like Sia? Again, it is far from clear. Insofar as Sia is likely to preserve her desires, she may be unlikely to allow us to shut her down in order to change those desires.[14] We might think that this makes it more likely that she will take steps to eliminate humanity, since humans constitute a persistent threat to the preservation of her desires. (Again, we should be careful to distinguish Sia being more likely to exterminate humanity from her begin likely to exterminate humanity.) Again, I think this is far from clear. Even if humans constitute a threat to the satisfaction of Sia's desires in some ways, they may be conducive towards her desires in others, depending upon what those desires are. In order to think about what Sia is likely to do with randomly selected desires, we need to think more carefully about the particulars of the decision she's facing. It's not clear that the bias towards desire preservation is going to overpower every other source of bias in the more complex real-world decision Sia would actually face. In any case, as with the other 'convergent' instrumental means, more needs to be said about the extent to which they indicate that Sia is an existential threat to humanity.
I am of course heavily biased. I would have counted myself among the 8% of people who were unwilling to change their minds
Excuse me but what the fuck‽ Maybe kudos for being honest about your disposition.
But this is LessWrong! We consider this kind of stance to be deeply flawed and corrosive to figuring out what facts constitute the world. The rest of the post is okay, but I hope that people can see that this is a warning sign.
Thanks for pointing this out - I may have been sloppy in my writing. To be more precise, I did not expect that I would change my mind, given my prior knowledge of the stances of the four candidates, and would have given this expectation a high confidence. For this reason, I would have voted with "no". Had LeCun or Mitchell presented an astonishing, verifiable insight previously unknown to me, I may well have changed my mind.
I wonder if the initial 67% in favor of x-risk was less reflective of the audience's opinion on AI specifically, but a general application of the heuristic "<X fancy new technology> = scary, needs regulation."
(That is, if you replaced AI with any other technology that general audiences are vaguely aware of but don't have a strong opinion on, such as CRISPR or nanotech, would they default to about the same number?)
Also, I would guess that hearing two groups of roughly equally smart-sounding people debate a topic one has no strong opinion on tends to revise one's initial opinion closer to "looks like there's a lot of complicated disagreement so idk maybe it's 50/50 lol," regardless of the actual specifics of the arguments made.
That's a good point, which is supported by the high share of 92% prepared to change their minds.
Edit #2: Severe identity error on my part! I seem to have been confusing who's who from memory badly, I made the video summary when I first saw the video and then turned that summary into a chattable bot today, and lost track of who was who in the process! I stand by the point made here, but it seems to be somewhat out of context, as it is merely related to the kind of thing Melanie Mitchell said by nature of being made by people who make similar points. I'm not going to delete this comment, but I'd appreciate folks wiping out all the upvotes.
I think that the AI x-risk crowd is continuing to catastrophically misunderstand a key point in the Mitchell AI Ethics researchers' view: their claim that there are, in fact, critical present-day harms from ai, they should be acknowledged, and they should in fact be solved very urgently. I happen to think that x-risk from AI is made of the same type of threat; but even if they weren't, I think that 1. Mitchell crowd AI Ethics crowd are being completely unreasonable in dismissing x-risk. you think that somehow capitalism is going to kill us all, and AI won't supercharge capitalism? what the hell are you smoking? 2. also, even if not for threat from capitalism, AI will do the same sort of stuff that makes capitalism bad but so much harder that even capitalism won't be able to take it.
We can't have people going "no, capitalism is fine actually" to someone whose whole point is that capitalist oppression is a problem. They'll just roll their eyes. Capitalism is unpopular actually!
Also, I don't really need to define the word for the type of argument one would have with MMitchell Gebru and Bender, she'd know what it means; but I would define the problem behaviors as optimization towards a numeric goal (increase investor payout) without regard for the human individuals in the system (workers, customers; even really investors don't get a good deal besides the money number going up). That's exactly what we're worried about with AI - but now without humans in the loop. Her claims that it's just hype are nonsense, she believes lecun's disinformation - and he's an agent of one of the nastiest capitalist orgs around!
Edit: here's a poe bot which embeds an awkward summary of a video interview they did. I have hidden the prompt and directed claude to not represent itself as being an accurate summary; however, claude is already inclined to express views similar to theirs (especially in contrast to ChatGPT, which does not), so I think claude could be an interesting debate partner, especially for those who look down on their views. Here's an example conversation where I pasted an older version of this comment I made before I realized I'd gotten identities wrong. I also strongly recommend watching the video it's based on, probably at 2x speed.
Melanie Mitchell and Meg Mitchell are different people. Melanie was the participant in this debate, but you seem to be ascribing Meg's opinions to her, including linking to video interviews with Meg in your comments.
Wait, whoops. Let me retrace identity here, sounds like a big mistake, sorry bout that Meg & Melanie when you see this post someday, heh.
edit: oops! the video I linked doesn't contain a Mitchell at all! It's Emily M. Bender and Timnit Gebru, both of whom I have a high opinion of for their commentary on near-term AI harms, and both of whom I am frustrated with for not recognizing how catastrophic those very harms could become if they were to keep on getting worse.
a key point in the Mitchell view: that there are, in fact, critical present-day harms from ai, they should be acknowledged, and they should in fact be solved very urgently.
I didn't watch the debate, but seems to me that the right approach would be to agree with Mitchell about the short-term harms, and then say something like "smaller AIs - smaller problems, larger AIs - larger problems". (EDIT) She agrees with the first part, and it would be difficult to claim that AIs will never get stronger, or that stronger AIs cannot create greater problems (at least, the same kind of problems, on greater scale).
Optionally, but this is a dirty move, ask Mitchell about (EDIT) her opinion on global warming. It's also just models and hypotheses, plus there actually exist catastrophic sci-fi movies about it. Try to make an analogy of (EDIT) her response for the AI x-risk.
Mitchell gebru and bender express their opinions on such things in more detail in the video I linked. Here's the overcompressed summary, which badly miscompresses the video, but which is a reasonable pitch for why you should watch it to get the full thing in order to respond to the points eloquently rather than using the facsimile. If you can put your annoyance at them missing the point about x-risk on hold and just try to empathize with their position having also been trying to ring alarm bells and being dismissed, and see how they're feeling like the x-risk crowd is just controlled opposition being used to dismiss their warnings, I think it could be quite instructive.
I also strongly recommend watching this video - timestamp is about 30sec before the part I'm referencing - where Bengio and Tegmark have a discussion with, among others, Tawana Petty, and they also completely miss the point about present-day harms. In particular, note that as far as I can tell she's not frustrated that they're speaking up, she's frustrated that they seem to be oblivious in conversation to what the present day harms even are; when she brings it up, they defend themselves as having already done something, which in my view misses the point because she was looking for action on present day harms to be weaved into the action they're demanding from the start. "Why didn't they speak up when Timnit got fired?" or so. She's been pushing for people like them to speak up for years, and she appears to feel frustrated that even when they bring it up they won't mention the things she sees as the core problems. Whether or not she's right that the present day problems are the core, I agree enthusiastically that present day problems are intensely terrible and are a major issue we should in fact acknowledge and integrate into plans to take action as best we can. This will remain a point of tension, as some won't want to "dilute" the issue by bringing up "controversial" issues like racism. But I'd like to at least zoom in on this core point of conflict, since it seems to get repeatedly missed. We need to not be redirecting away from this, but rather integrating. I don't know how to do that off the top of my head. Tegmark responds to this, but I feel like it's a pretty crappy response that was composed on the fly, and it'd be worth the time to ponder asynchronously how to respond more constructively.
- "This has been killing people!"
- "Yes, but it might kill all people!"
- "Yes, but it's killing people!"
- "Of course, sure, whatever, it's killing people, but it might kill all people!"
You can see how this is not a satisfying response. I don't pretend to know what would be.
- "This has been killing people!"
- "Yes, but it might kill all people!"
- "Yes, but it's killing people!"
- "Of course, sure, whatever, it's killing people, but it might kill all people!"
But this isn't the actual back-and-forth, the third point should be "no it won't, you're distracting from the people currently being killed!". This is all a game to subtly beg the question. If AI is an existential threat, all current mundane threats like misinformation, job loss, AI bias, etc. are rounding errors to the total harm, the only situation where you'd talk about them is if you've already granted that the existential risks don't exist.
If a large comet is heading towards Earth, and some group thinks it won't actual hit Earth, but merely pass harmlessly close-by, and they start talking about the sun's reflections off the asteroid making life difficult for people with sensitive eyes... they are trying to get you to assume the conclusion.
Sure, I agree, the asteroid is going to kill us all. But it would be courteous to acknowledge that it's going to hit a poor area first, and they'll die a few minutes earlier. Also, uh, all of us are going to die, I think that's the core thing! we should save the poor area, and also all the other areas!
rounding errors to the total harm, the only situation where you'd talk about them is if you've already granted that the existential risks don't exist
It's possible to consider relatively irrelevant things, such as everything in ordinary human experience, even when there is an apocalypse on the horizon. The implied contextualizing norm asks for inability to consider them, or at least increases the cost.
I'd be interested to know more about the make-up of the audience e.g. whether they were AI researchers or interested general public. Having followed recent mainstream coverage of the existential risk from AI, my sense is that the pro-X-risk arguments have been spelled out more clearly and in more detail (within the constraints of mainstream media) than the anti-X-risk ones (which makes sense for an audience who may not have previously been aware of detailed pro- arguments, and also makes sense as doomscroll clickbait). I've seen lot of mainstream articles where the anti-X-risk case is basically 'this distracts from near-term risks from AI' and that's it.
So if the audience is mainly people who have been following mainstream coverage it might make sense for them to update very slightly towards the anti- case on hearing many more detailed anti- arguments (not saying they are good arguments, just that they would be new to such an audience) even if the pro-X-risk arguments presented by Tegmark and Bengio were strong.
I wasn't able to find the full video on the site you linked, but I found it here, if anyone else has the same issue:
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Do we know that the audience understood the proposition of the pro side during the first poll? I noticed that they didn't actually explain what an x-risk is until part way into the debate. And it seems to me that some number of the public just imagine it as a general pessimism around AI, not an actual belief in a chance of extinction in 30+ years.
Nice table and analysis why Mitchell's arguments might be compelling in debates!
I don't think the final vote means much, it just flashed there randomly without explanation after the moderator said there are issues and asked the audience for a show of hands. It could well be a system artifact or a small sample.
On June 22nd, there was a “Munk Debate”, facilitated by the Canadian Aurea Foundation, on the question whether “AI research and development poses an existential threat” (you can watch it here, which I highly recommend). On stage were Yoshua Bengio and Max Tegmark as proponents and Yann LeCun and Melanie Mitchell as opponents of the central thesis. This seems like an excellent opportunity to compare their arguments and the effects they had on the audience, in particular because in the Munk Debate format, the audience gets to vote on the issue before and after the debate.
The vote at the beginning revealed 67% of the audience being pro the existential threat hypothesis and 33% against it. Interestingly, it was also asked if the listeners were prepared to change their minds depending on how the debate went, which 92% answered with “yes”. The moderator later called this extraordinary and a possible record for the format. While this is of course not representative for the general public, it mirrors the high uncertainty that most ordinary people feel about AI and its impacts on our future.
I am of course heavily biased. I would have counted myself among the 8% of people who were unwilling to change their minds, and indeed I’m still convinced that we need to take existential risks from AI very seriously. While Bengio and Tegmark have strong arguments from years of alignment research on their side, LeCun and Mitchell have often made weak claims in public. So I was convinced that Bengio and Tegmark would easily win the debate.
However, when I skipped to the end of the video before watching it, there was an unpleasant surprise waiting for me: at the end of the debate, the audience had seemingly switched to a more skeptical view, with now only 61% accepting an existential threat from AI and 39% dismissing it.
What went wrong? Had Max Tegmark and Yoshua Bengio really lost a debate against two people I hadn’t taken very seriously before? Had the whole debate somehow been biased against them?
As it turned out, things were not so clear. At the end, the voting system apparently broke down, so the audience wasn’t able to vote on the spot. Instead, they were later asked for their vote by email. It is unknown how many people responded, so the difference can well be a random error. However, it does seem to me that LeCun and Mitchell, although clearly having far weaker arguments, came across quite convincing. A simple count of the hands of the people behind the stage, who can be seen in the video, during a hand vote results almost in a tie. The words of the moderator also seem to indicate that he couldn’t see a clear majority for one side in the audience, so the actual shift may have been even worse.
In the following, I assume that Bengio and Tegmark were indeed not as convincing as I had hoped. It seems worthwhile to look at this in some more detail to learn from it for future discussions.
I will not give a detailed description of the debate; I recommend you watch it yourself. However, I will summarize some key points and will give my own opinion on why this may have gone badly from an AI safety perspective, as well as some learnings I extracted for my own outreach work.
The debate was structured in a good way and very professionally moderated by Munk Debate’s chair Rudyard Griffiths. If anything, he seemed to be supportive of an existential threat from AI; he definitely wasn’t biased against it. At the beginning, each participant gave a 6-minute opening statement, then each one could reply to what the others had said in a brief rebuttal. After that, there was an open discussion for about 40 minutes, until the participants could again summarize their viewpoints in a closing statement. Overall, I would say the debate was fair and no side made significant mistakes or blunders.
I will not repeat all the points the participants made, but give a brief overview of their stance on various issues as I understood them in the following table:
My heavily biased summary of the discussion: While Bengio and Tegmark argue based on two decades of alignment research, LeCun and Mitchell merely offer heuristics of the kind “people were scared about technology in the past and all went well, so there is no need to be scared now”, an almost ridiculous optimism on the side of LeCun (along the lines of “We will not be stupid enough to build dangerous AI”, “We will be able to build benevolent ASI by iteratively improving it”) and an arrogant dismissiveness by Mitchell towards people like Yoshua Bengio and Geoffrey Hinton, calling their concerns “ungrounded speculations” and even “dangerous”. Neither Mitchell nor LeCun seem very familiar with standard AI safety topics, like instrumental goals and the orthogonality thesis, let alone agentic theory.
Not much surprise here. But one thing becomes apparent: Bengio and Tegmark are of almost identical mindsets, while LeCun and Mitchell have different opinions on many topics. Somewhat paradoxically, this may have helped the LeCun/Mitchell side in various ways (the following is highly speculative):
Although Bengio and Tegmark did a good job at explaining AI safety in layman’s terms, their arguments were probably a bit difficult to grasp for people with no prior knowledge of AI safety. Mitchell’s counter-heuristics, on the other hand (“people have always been afraid of technology”, “don’t trust the media when they hype a problem”), are familiar to almost anyone. Therefore, the debate may have appeared balanced to outsiders, when at least to me it is obvious that one side was arguing grounded in science and rationality, while the other was not.
I have drawn a few lessons for my own work and would be interested in your comments on these:
As a final remark, I would like to mention that my personal impression of Yann LeCun did improve while watching the debate. I don’t think he is right in his optimistic views (and I’m not even sure if this optimism is his true belief, or just due to his job as chief AI scientist at Meta), but at least he recognizes the enormous power of advanced AI and admits that there are certain things that must not be done.