Wow, just wow. Sure seems like Gwern has it spot on here that OpenAI engineers are being rushed and sloppy about this.
Kinda pisses me off, considering that I applied to work for OpenAI between GPT-2 and GPT-3, and this isn't the sort of mistake I would make. Yet, they rejected my application. (note: given the current state of OpenAI, I wouldn't apply today!)
Building my own small LLMs around that time for practice, the low frequency tokens and the tokenization of digits were among the first things I checked!
I tried a quick search for Anthropic to see if they are doing the same nonsense. Found this site: https://lunary.ai/anthropic-tokenizer And this https://github.com/javirandor/anthropic-tokenizer
Lunary shows Anthropic as not only tokenizing groups of digits together, but also sometimes digits with a space in between!? Is that true? I'm flabbergasted if so. I'm going to look into this more.
[Edit: some people have suggested to me that they think Lunary is wrong about Anthropic's tokenization, and that Anthropic never had or has fixed this problem. Hopefully that's true. Still pretty surprising that OpenAI is still suffering from it!]
You're really not going to like the fact that the GPT4o tokenizer has every single number below 1000 tokenized. It's not a hand-crafted feature, since the token_ids are all over the place. I think they had to manually remove larger number tokens (there are none above 999).
I feel like I need a disclaimer like the South Park episode. This is what is actually inside the tokenizer.
['37779', '740'],
['47572', '741'],
['48725', '742'],
['49191', '743'],
['46240', '744'],
['44839', '745'],
['47433', '746'],
['42870', '747'],
['39478', '748'],
['44712', '749'],
They also have plenty of full width numbers (generally only used in Chinese and Japanese to not mess with spacing) and numbers in other languages in there.
['14334', '十'],
['96681', '十一'],
['118633', '十三'],
['138884', '十九'],
['95270', '十二'],
['119007', '十五'],
['107205', '十八'],
['180481', '十四']
['42624', '零'],
['14053', '0'],
['49300', '00'],
['10888', '1'],
['64980', '10'],
['141681', '100'],
['113512', '11'],
['101137', '12'],
['123326', '13'],
['172589', '14'],
['126115', '15'],
['171221', '16']
Maybe they use a different tokenizer for math problems? Maybe the multi-digit number tokenizers are only used in places where there are a lot of id numbers? Nope. Looks like they were just raw-dogging it. If anyone is wondering why GPTs are so bad at basic multiplication, this is why.
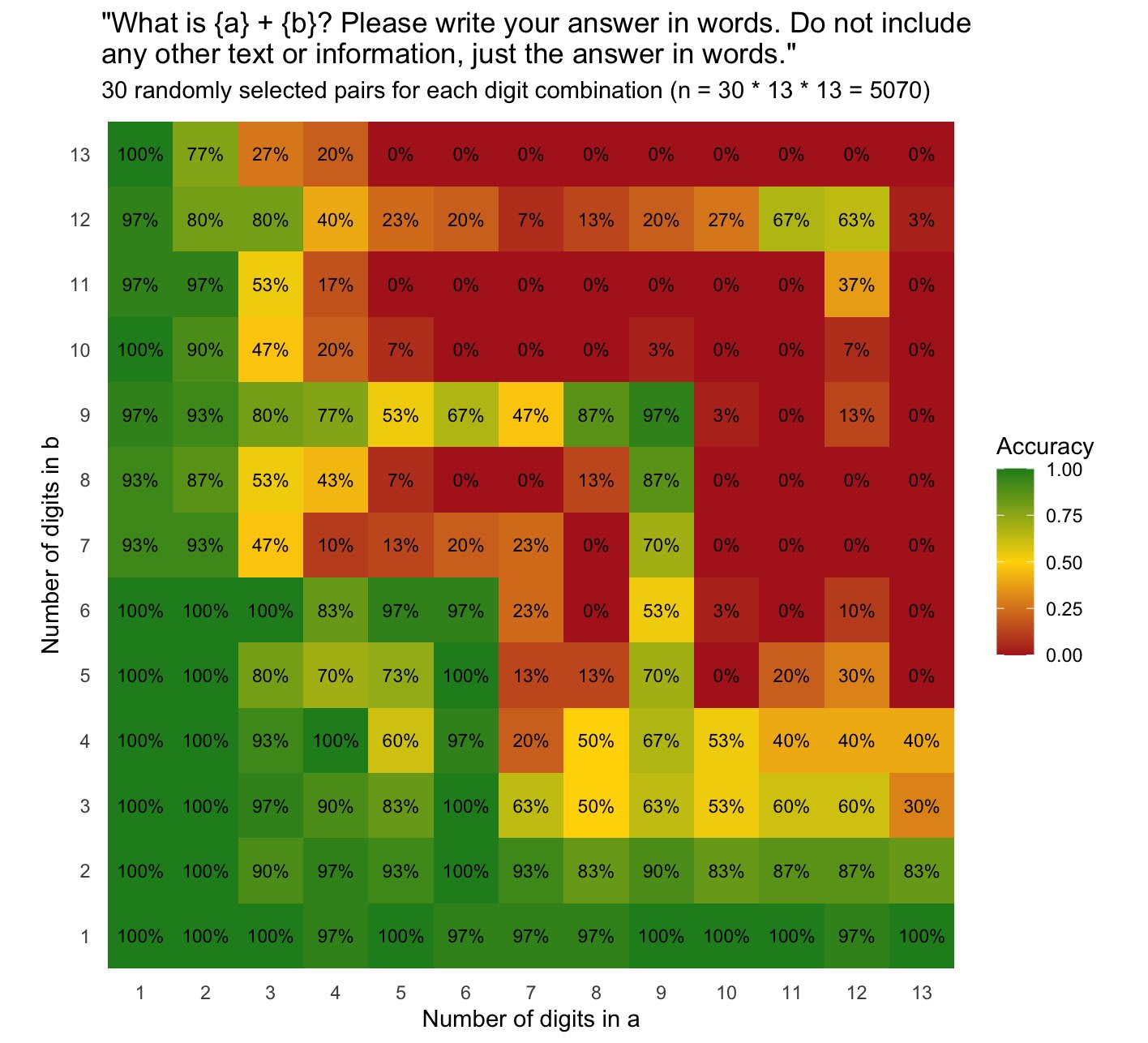
If you've ever wondered "wow, why is GPT4o specifically better at math when the number of digits is divisible by 3?", wonder no more. It's the tokenizer. Again.
specifically better at math when the number of digits is divisible by 3?
Ironically, this is the opposite of the well-known calculating prodigy Shakuntala Devi, who said that inserting commas (e.g. "5,271,009") interfered with her perception of the number.

Interesting that GPT4o is so bad at math and tokenizes large numbers like this. I wonder if adding commas would improve performance?

There is likely a reason for this - if you feed in numbers you found on the internet into a LLM digit by digit, it's going to destroy the embeddings of those numbers. A lot of things found in scrapes are just... extremely long sequences of numbers. The tradeoff may be numeracy (can do basic multiplication) vs natural language performance (won't start spitting out Minecraft debug logs in the middle of conversation).
Right, but... it's a combined issue of tokenization and data cleaning. I agree you can't properly do one without the other. I just think you should do both!
Clearly the root cause is the messy data, and once you've cleaned the data it should be trivial to fix the tokenizer.
I checked Lunary's predicted tokenization for Gemma, Mistral, and Grok as well. These three models all seem to handle number tokenization cleanly, a single digit at a time. This suggests that there isn't some well considered valid reason that digits need uneven lumpy tokenization, that it's really just a mistake.
Introduction
I've spent the last few days going through every glitch token listed in the third SolidGoldMagikarp glitch token post, and was able to find the cause/source of almost every single one. This is the first in a series of posts in which I will explain the behaviors of these glitch tokens, the context in which they appear in the training data, and what they reveal about the internal dynamics of LLMs. If you're unfamiliar with glitch tokens, I highly suggest you read the glitch token archaeology posts first.
My process involved searching through OpenWebText, a recreation of GPT2 training data, and prompting GPT2 to locate the context of the training data.
Previous Context
In their 2023 post, the authors made the following pronouncement in regard to the glitch token ' practition' (token_id: 17629). I took it as a personal challenge.
The first thing I found was that ' practitioner' (32110) and ' practitioners' (24068) were both already tokens in the GPT2 tokenizer. Furthermore, all three tokens also present in the GPT3.5/4 and GPT4o tokenizers, meaning they weren't an artifact of GPT2's training data!
There were only 13 examples of " practition" in OpenWebText.
They were mostly misspellings, as an element of " practitioning", or line breaks artifacts[1].
Experimentation
I examined some other low-frequency tokens in GPT2 and found a few which were substrings of a higher-frequency counterpart. 'ortunately' (4690) also behaved like a glitch token, while higher-frequency subtokens like ' volunte' (7105) didn't.
Helpful Contributions
Others pointed out that this was a result of Byte-Pair Encoding, which builds tokens out of shorter, previously encounter, tokens.
I was very surprised by this, since glitch behavior implies a low frequency in the training data, and identifying and removing them from the tokenizer takes little effort. Gwern thinks the researchers are just that lazy. My overall impression is that glitch tokens are a useful tool to help prevent catastrophic forgetting, but that's for a future post. Even then, I'm doubtful that incorporating low-frequency BSA tokens can improve performance. Maybe they contribute to the spelling miracle in some poorly understood way?
Applications
I'm not sure if this approach is useful for finding glitch tokens in other GPT models. Due to things like misspellings, line breaks and uncommon variants, even tokens rare enough to trigger glitch behavior in GPT2 are likely pushed over the glitchiness threshold in GPT4 and GPT4o.
However, the differences in token ids of substrings can be used to help identify the potential glitchiness of a token with no other knowledge of the model or training data[2]. We know from the mechanisms of BPE encoding that smaller subtokens created before they are merged into larger tokens. However, if a subtoken is never/rarely encountered outside its parent token, we would expect it to have an index close to the parent token, and that's exactly what we observe for many glitch tokens!
For example:
Note how close the index of " TheNitrome" (42089) is to " TheNitromeFan"[3] (42090). This indicates 2 things:
Many of the most well-know glitch tokens exhibit this pattern:
The token ids suggest "
oreAndOnline" and "InstoreAndOnline" virtually never appears apart from "BuyableInstoreAndOnline". However, the small gap between "oreAnd" and the other tokens implies that "oreAnd" was occasionally present in the data as something else - and that's exactly what we observe! It appears as parts of various functions, generally in something like "IgnoreAnd..."[7].Nearby (by token_id) tokens can also be used to infer the context of hard-to-locate tokens. For example, "natureconservancy" (41380) and "assetsadobe" (41382) have close token_ids. "assetadobe" also continues as something like
~100% of the time. It looks like both tokens were part of nature.org scrapes.
Similarly, "GoldMagikarp" (42202) and "TheNitromeFan" (42090) are around Reddit political discussion and numerical tokens like
This suggests it's part of a Reddit scrape. When prompted with counting subreddit names, the continuation will assume it's a Reddit response. Note the "\n\n" (628), often times referred to as "Reddit spacing" due to its frequency on that site.
Interestingly, " SolidGoldMagikarp" (43453) occurs quite a bit away from "GoldMagikarp" (42202). My theory for this is that Reddit posts are often in the following format:
and "u/SolidGoldMagikarp" tokenizes as:
It's possible only enough of his post were included to get "GoldMagikarp" as a token for a while. This was corrected after more of his posts were read later, and the full " SolidGoldMagikarp" token was included in the final vocabulary[8].
My next post will be about why an earlier hypothesis that many glitch tokens were excluded from training data is unlikely to be true for most glitch tokens, and the role that glitch tokens play in improving LLM performance.
If you're curious about a particular glitch token, feel free to comment.
Addendum
There are two tokens I still don't have a source for. Unlike almost every other glitch token, they exhibit spontaneous glitch behavior, even when they are the only prompt.
Completions for "?????-":
" practitionerr" is tokenized into:
[[17629, 8056], [' practition', 'err']]
instead of [[32110, 81], [' practitioner', 'r']].
There's something I don't understand here - I thought BPE tokenization was maximally greedy! Or does that only apply to tokenizer training, and something else happens when a tokenizer is ran on text?
I can probably find glitch tokens in something the size of GPT2 just with access to the tokenizer.
"Nitrome" is also the name of a video game developer, so it appeared in other places in the dataset, and thus was tokenized slightly sooner.
for example, literally all instances of "ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ" (token_id: 35496)(that's 64 characters) in OpenWebText are from archive.org. There are 9468 instances in total, not counting shorter variants with 1, 2, 4, 8, 16, and 32 characters. The following was the first example I found.
This goes on for 200,000 characters on this page alone.
@Rana Dexsin wrote the single best answer I've ever seen on the internet.
Which links to this.
There were no hidden characters in these sequences.
The second one isn't always true; many glitch tokens exhibiting such patterns may be from alternate tokenizations. For example, "EStream" almost always continues as "EStreamControl...", distinct from "EStreamFrame". Both "EStreamFrame" and "EStream" are part of many functions in the enums submodule of the Python Stream library.
If "
oreAndOnline" is only present as part of "BuyableInstoreAndOnline", the model will never see the "oreAndOnline" token.For example, the CMock function "_IgnoreAndReturn()". CMock is used to measure the performance of C++ functions, and it makes sense that some CMock logs were included in the training data.
I do find it interesting that I haven't been able to induce counting behavior in GPT2. This may be related to so many multi-digit numbers having their own tokenizations - "411" (42224), "412"(42215), and so on, and that's just not a pattern GPT2 can figure out. It's possible that the r/Counting subreddit is a major contributor in why GPT2 is so bad at math!
I then looked around at GPT4 and GPT4o tokenizers. To my shock and horror, they still include multi-digit numbers as tokens. "693" (48779) being an example in GPT4o.
This is... what? Why? How can this possibly be a good idea in an LLM used for math and coding applications? It would certainly explain why GPT4/GPT4o is so bad at math.