The Story as of ~4 Years Ago
Back in 2020, a group at OpenAI ran a conceptually simple test to quantify how much AI progress was attributable to algorithmic improvements. They took ImageNet models which were state-of-the-art at various times between 2012 and 2020, and checked how much compute was needed to train each to the level of AlexNet (the state-of-the-art from 2012). Main finding: over ~7 years, the compute required fell by ~44x. In other words, algorithmic progress yielded a compute-equivalent doubling time of ~16 months (though error bars are large in both directions).
On the compute side of things, in 2018 a group at OpenAI estimated that the compute spent on the largest training runs was growing exponentially with a doubling rate of ~3.4 months, between 2012 and 2018.
So at the time, the rate of improvement from compute scaling was much faster than the rate of improvement from algorithmic progress. (Though algorithmic improvement was still faster than Moore's Law; the compute increases were mostly driven by spending more money.)
... And That Immediately Fell Apart
As is tradition, about 5 minutes after the OpenAI group hit publish on their post estimating a training compute doubling rate of ~3-4 months, that trend completely fell apart. At the time, the largest training run was AlphaGoZero, at about a mole of flops in 2017. Six years later, Metaculus currently estimates that GPT-4 took ~10-20 moles of flops. AlphaGoZero and its brethren were high outliers for the time, and the largest models today are only ~one order of magnitude bigger.
A more recent paper with data through late 2022 separates out the trend of the largest models, and estimates their compute doubling time to be ~10 months. (They also helpfully separate the relative importance of data growth - though they estimate that the contribution of data was relatively small compared to compute growth and algorithmic improvement.)
On the algorithmic side of things, a more recent estimate with more recent data (paper from late 2022) and fancier analysis estimates that algorithmic progress yielded a compute-equivalent doubling time of ~9 months (again with large error bars in both directions).
... and that was just in vision nets. I haven't seen careful analysis of LLMs (probably because they're newer, so harder to fit a trend), but eyeballing it... Chinchilla by itself must have been a factor-of-4 compute-equivalent improvement at least. And then there's been chain-of-thought and all the other progress in prompting and fine-tuning over the past couple years. That's all algorithmic progress, strategically speaking: it's getting better results by using the same amount of compute differently.
Qualitatively: compare the progress in prompt engineering and Chinchilla and whatnot over the past ~year to the leisurely ~2x increase in large model size predicted by recent trends. It looks to me like algorithmic progress is now considerably faster than scaling.
My guess is that compute scaling is probably more important when looking just at pre-training and upstream performance. When looking innovations both pre- and post-training and measures of downstream performance, the relative contributions are probably roughly evenly matched.
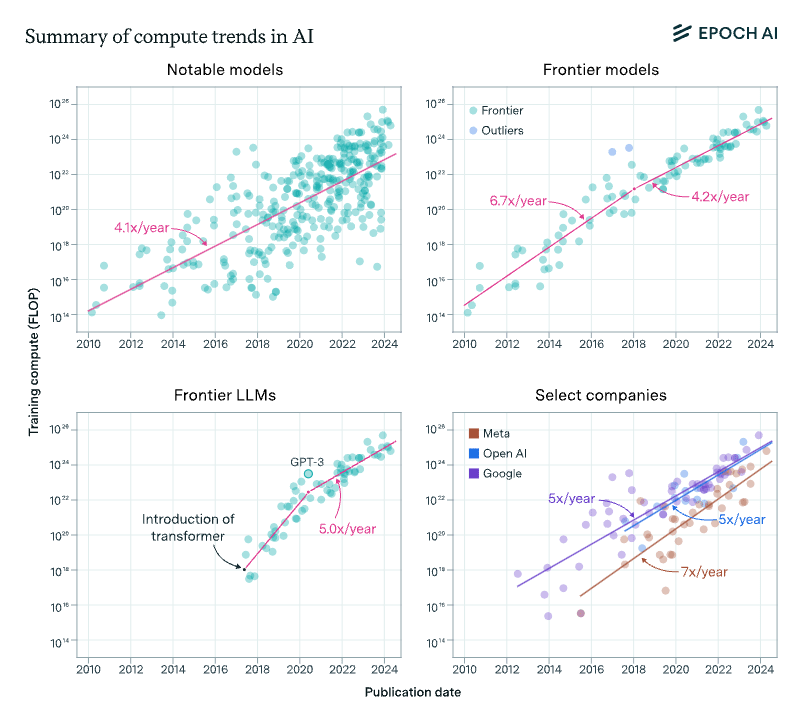
Compute for training runs is increasing at a rate of around 4-5x/year, which amounts to a doubling every 5-6 months, rather than every 10 months. This is what we found in the 2022 paper, and something we recently confirmed using 3x more data up to today.
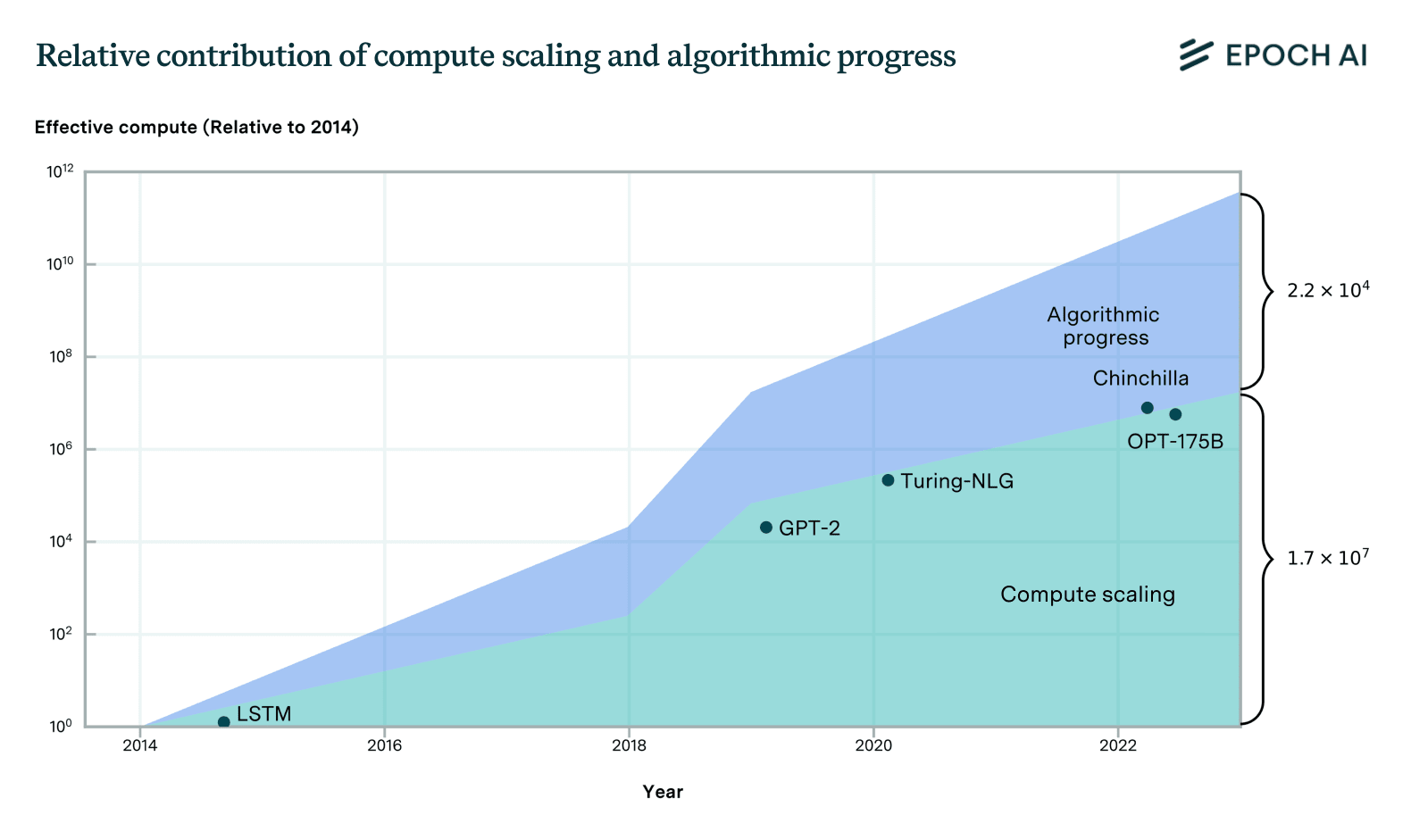
Algorithms and training techniques for language models seem to improve at a rate that amounts to a doubling of 'effective compute' about doubling every 8 months, though, like our work on vision, this estimate has large errors bars. Still, it's likely to be slower than the 5-6 month doubling time for actual compute. These estimates suggest that compute scaling has been responsible for perhaps 2/3rds of performance gains over the 2014-2023 period, with algorithms + insights about optimal scaling + better data, etc. explaining the remaining 1/3rd.
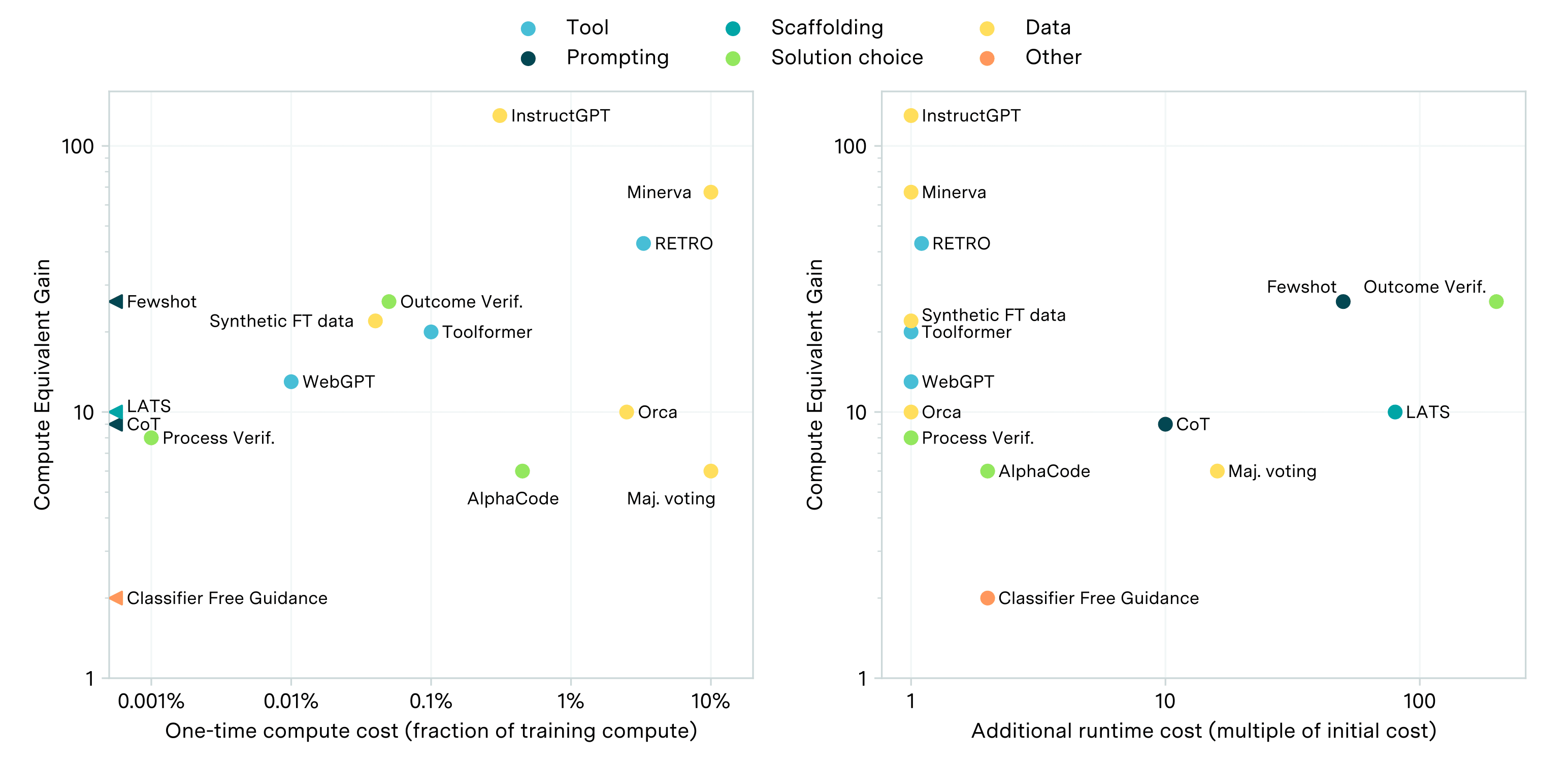
The estimates mentioned only account for the performance gains from pre-training, and do not consider the impact of post-training innovations. Some key post-training techniques, such as prompting, scaffolding, and finetuning, have been estimated to provide performance improvements ranging from 2 to 50 times in units of compute-equivalents, as shown in the plot below. However, these estimates vary substantially depending on the specific technique and domain, and are somewhat unreliable due to their scale-dependence.
Naively adding these up with the estimates from the progress from pre-training suggests that compute scaling likely still acounts for most of the performance gains, though it looks more evenly matched.
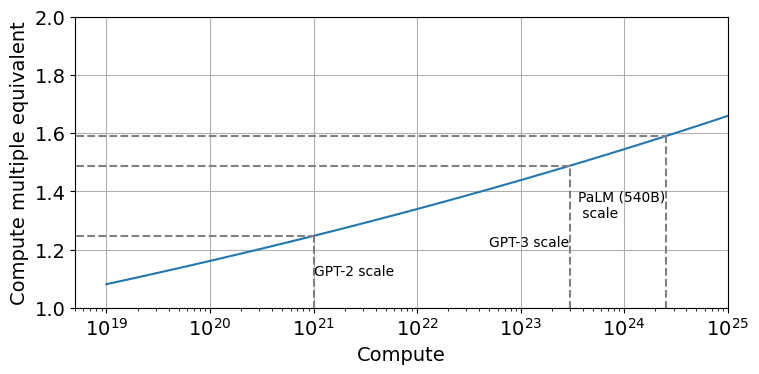
Incidentally, I looked into the claim about Chinchilla scaling. It turns out that Chinchilla was actually more like a factor 1.6 to 2 in compute-equivalent gain over Kaplan at the scale of models today (at least if you use the version of the scaling law that corrects a mistake the Chinchilla paper made when doing the estimation).