I spoke to Altman about a month ago. He essentially said some of the following:
- His recent statement about scaling essentially plateau-ing was misunderstood and he still thinks it plays a big role.
- Then, I asked him what comes next and he said they are working on the next thing that will provide 1000x improvement (some new paradigm).
- I asked if online learning plays a role in that and he said yes.
- That's one of the reasons we started to work on Supervising AIs Improving AIs.
In a shortform last month, I wrote the following:
There has been some insider discussion (and Sam Altman has said) that scaling has started running into some difficulties. Specifically, GPT-4 has gained a wider breath of knowledge, but has not significantly improved in any one domain. This might mean that future AI systems may gain their capabilities from places other than scaling because of the diminishing returns from scaling. This could mean that to become “superintelligent”, the AI needs to run experiments and learn from the outcome of those experiments to gain more superintelligent capabilities. You can only learn so much from a static dataset.
So you can imagine the case where capabilities come from some form of active/continual/online learning, but that was only possible once models were scaled up enough to gain capabilities in that way. And so that as LLMs become more capable, they will essentially become capable of running their own experiments to gain alphafold-like capabilities across many domains.
Of course, this has implications for understanding takeoffs / sharp left turns.
As Max H said, I think once you meet a threshold with a universal interface like a language model, things start to open up and the game changes.
My guess is that compute scaling is probably more important when looking just at pre-training and upstream performance. When looking innovations both pre- and post-training and measures of downstream performance, the relative contributions are probably roughly evenly matched.
Compute for training runs is increasing at a rate of around 4-5x/year, which amounts to a doubling every 5-6 months, rather than every 10 months. This is what we found in the 2022 paper, and something we recently confirmed using 3x more data up to today.
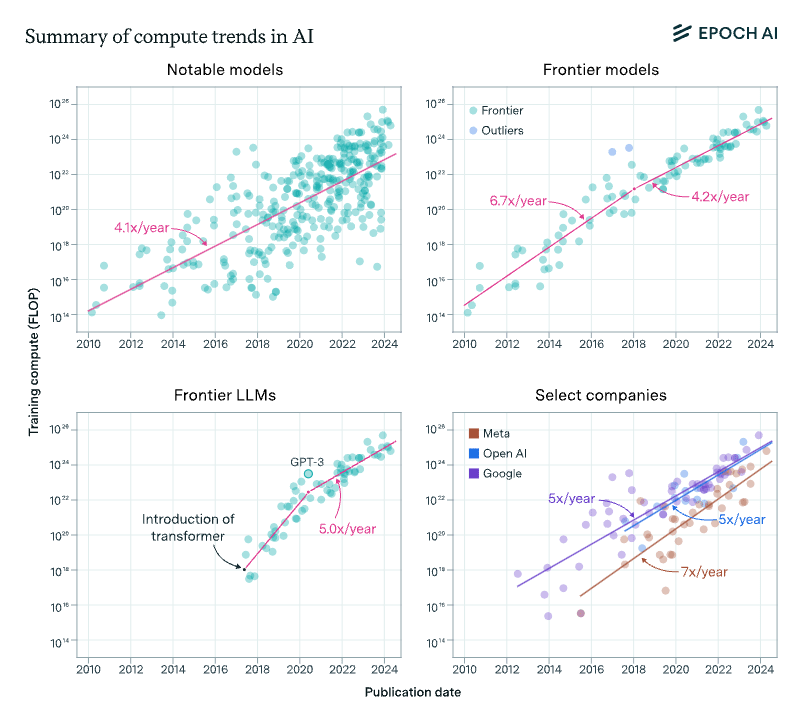
Algorithms and training techniques for language models seem to improve at a rate that amounts to a doubling of 'effective compute' about doubling every 8 months, though, like our work on vision, this estimate has large errors bars. Still, it's likely to be slower than the 5-6 month doubling time for actual compute. These estimates suggest that compute scaling has been responsible for perhaps 2/3rds of performance gains over the 2014-2023 period, with algorithms + insights about optimal scaling + better data, etc. explaining the remaining 1/3rd.
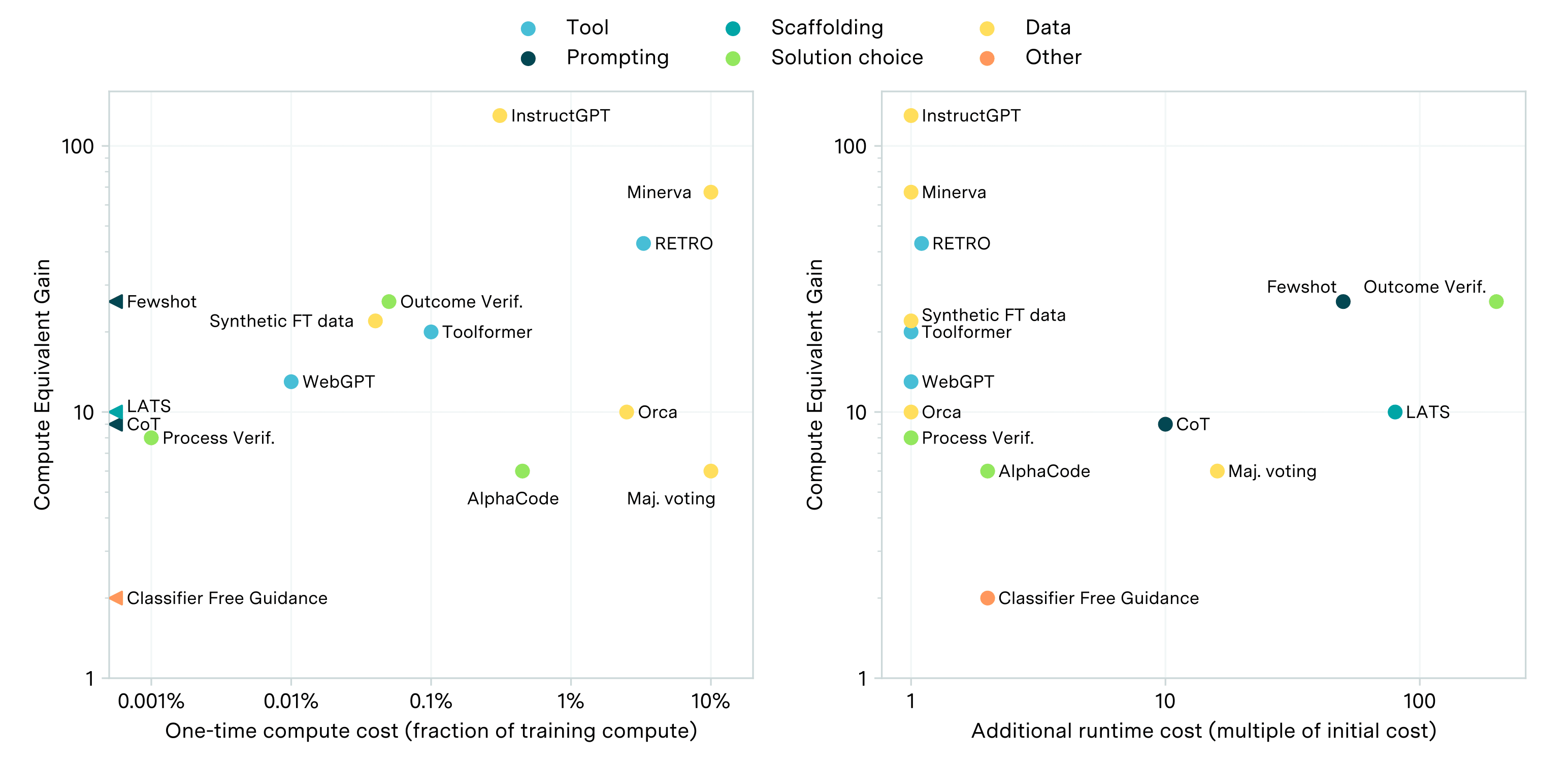
The estimates mentioned only account for the performance gains from pre-training, and do not consider the impact of post-training innovations. Some key post-training techniques, such as prompting, scaffolding, and finetuning, have been estimated to provide performance improvements ranging from 2 to 50 times in units of compute-equivalents, as shown in the plot below. However, these estimates vary substantially depending on the specific technique and domain, and are somewhat unreliable due to their scale-dependence.
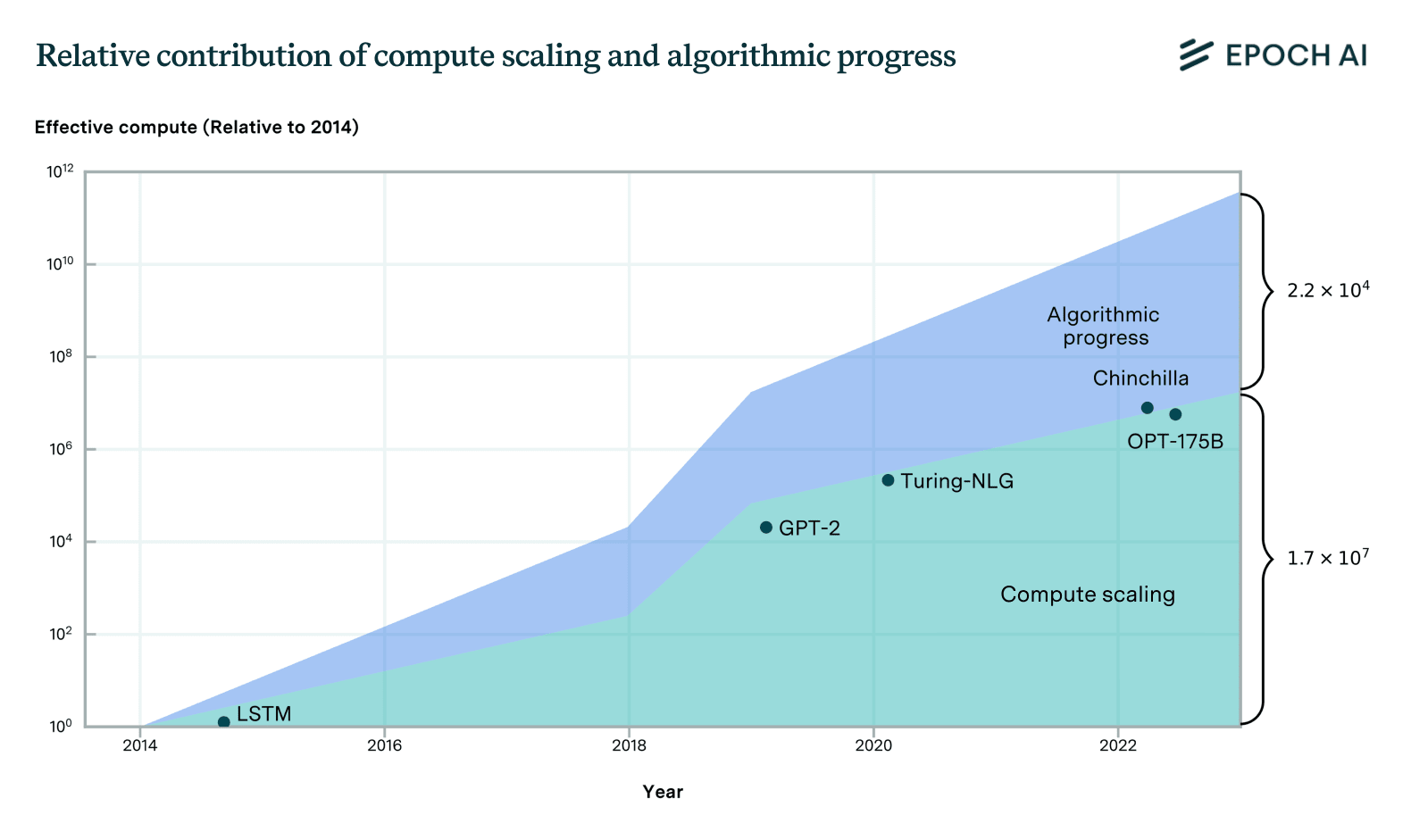
Naively adding these up with the estimates from the progress from pre-training suggests that compute scaling likely still acounts for most of the performance gains, though it looks more evenly matched.
... and that was just in vision nets. I haven't seen careful analysis of LLMs (probably because they're newer, so harder to fit a trend), but eyeballing it... Chinchilla by itself must have been a factor-of-4 compute-equivalent improvement at least.
Incidentally, I looked into the claim about Chinchilla scaling. It turns out that Chinchilla was actually more like a factor 1.6 to 2 in compute-equivalent gain over Kaplan at the scale of models today (at least if you use the version of the scaling law that corrects a mistake the Chinchilla paper made when doing the estimation).
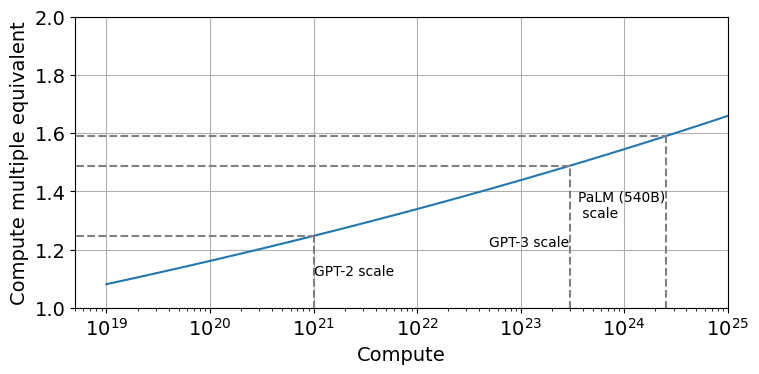
Would you say that it makes the advocated GPU restrictions less relevant for AI x-risk prevention?
I think people underestimate the degree to which hardware improvements enable software improvements. If you look at AlphaGo, the DeepMind team tried something like 17 different configurations during training runs before finally getting something to work. If each one of those had been twice as expensive, they might not have even conducted the experiment.
I do think it's true that if we wait long enough, hardware restrictions will not be enough.
Yes, this is how everyone misinterprets these sorts of time-travel results. They do not tell you the causal role of 'compute got cheaper' vs 'we thought real gud'. In reality, if we held FLOPs/$ constant, no matter how clever you were, most of those clever algorithmic innovations would not have happened*, either because compute shortages herd people into hand-engineering constant-factor tweaks which don't actually work / have no lasting value (Bitter Lesson effect), people would not have done the trial-and-error which actually lies (if you will) behind the pretty stories they tell in the paper writeup, or because they would have proposed it with such unconvincing evaluations at such small scale it simply becomes yet another unread Arxiv paper (cue Raiders of the Lost Ark final scene). When you use methods to try to back out causal impact of compute increases on productivity, you get >50% - which must be the case: the time-travel method implicitly assumes that the only effect of hardware is to speed up the final version of the algorithm, which of course is an absurd assumption to make as everyone will admit that faster computers must help algorithm research at least a little, so the time-travel 50%s are only a loose lower-bound.
This is probably part of why people don't think compute restrictions would work as well as they would, because they misread these essentially irrelevant & correlational results as causal marginal effects and think "well, 50% slowdown isn't terribly useful, and anyway, wouldn't people just do the research any way with relatively small runs? so this shouldn't be a big priority". (This model is obviously wrong as, among other things, it predicts that the deep learning revolution would have started long before it did instead of waiting for ultra-cheap GPUs within grad student budgets - small scale runs imply small scale budgets, and are a sign that compute is exorbitantly expensive rather than so ample they need only small amounts.)
What they do tell you is a useful forecasting thing along the lines of 'the necessary IQ to destroy the world drops by 1 point every 18 months'. It's plenty useful to know that given current trends, the hardware cost to run system X is going to predictably drop by Y factor every Z months. This is important to know for things like gauging hardware overhangs, or modeling possibilities for future models being deployed onto commodity hardware, etc. It's just not that useful for controlling progress, rather than forecasting progress with no causal manipulation of factors going into the trends.
* Like, imagine if '50% slowdown' were accurate and computers froze ~2011, so you were still using the brandnew Nvidia GTX 590 with all of 3GB RAM and so we were only halfway through the DL revolution to date, so ~6 years ago vs our timeline's 12 years from 2011: you really think that all the progress we made with fleets of later GPUs like V100s or A100s or H100s would happen, just half as fast? That we would be getting AlphaGo Master crushing all the human pros undefeated right about now? That a decade later OA would unveil GPT-4 (somehow) trained on its fleet of 2011 GPUs? And so on and so forth to all future systems like GPT-5 and whatnot?
Note that this probably doesn't change the story much for GPU restrictions, though. For purposes of software improvements, one needs compute for lots of relatively small runs rather than one relatively big run, and lots of relatively small runs is exactly what GPU restrictions (as typically envisioned) would not block.
Couldn't GPU restrictions still make them more expensive? Like let's say tomorrow that we impose a tax on all new hardware that can be used to train neural networks such that any improvements in performance will be cancelled out by additional taxes. Wouldn't that also slow down or even stop the growth of smaller training runs?
That would, and in general restrictions aimed at increasing price/reducing supply could work, though that doesn't describe most GPU restriction proposals I've heard.
A possible explanation for this phenomenon that feels somewhat natural with hindsight: there's a relatively large minimum amount of compute required to get certain kinds of capabilities working at all. But once you're above that minimum, you have lots of options: you can continue to scale things up, if you know how to scale them and you have the compute resources to do so, or you can look for algorithmic improvements which enable you to do more and get better results with less compute. Once you're at this point, perhaps the main determiner of the relative rate of progress between algorithms and compute is which option researchers at the capabilities frontier choose to work on.
Were you implying that Chinchilla represents algorithmic progress? If so, I disagree: technically you could call a scaling law function an algorithm, but in practice, it seems Chinchilla was better because they scaled up the data. There are more aspects to scale than model size.
Scaling up the data wasn't algorithmic progress. Knowing that they needed to scale up the data was algorithmic progress.
It seems particularly trivial from an algorithmic aspect? You have the compute to try an idea so you try it. The key factor is still the compute.
Unless you’re including the software engineering efforts required to get these methods to work at scale, but I doubt that?
I think whether or not it's trivial isn't the point: they did it, it worked, and they didn't need to increase the compute to make it happen.
I think it’s distinct from something like Tree of thought. We have ideas that are trivial but enabled by greater compute vs novel ideas that would have worked at earlier levels of compute.
Fair enough. But for the purposes of this post, the point is that capability increased without increased compute. If you prefer, bucket it as "compute" vs "non-compute" instead of "compute" vs "algorithmic".
An interesting development is the development of synthetic data. This is also a sort of algorithmic improvement, because the data is generated by algorithms. For example in the verify step by step paper there is a combination of synthetic data and human labelling.
At first this seemed counter intuitive to me. The current model is being used to create data for the next model. Feels like bootstrapping. But it starts to make sense now. Better prompting (like CoT or ToT) is a method to get better data or a second model that is trained to pick the best answers from a thousand and that will get you data good enough to improve the model.
Demis Hassabis said in his interview with Lex Fridman that they used synthetic data when developing AlphaFold. They had some output of AlphaFold that they had great confidence in. Then they fed the output as input and the model improved (this gives your more data with great confidence, repeat).
At the time, the largest training run was AlphaGoZero, at about a mole of flops in 2017. Six years later, Metaculus currently estimates that GPT-4 took ~10-20 moles of flops.
By "mole" do you mean the unit from chemistry?
In chemistry, a mole is a unit of measurement used to express amounts of a chemical substance. It is one of the base units in the International System of Units (SI) and is defined as the amount of substance that contains as many elementary entities (such as atoms, molecules, ions, or electrons) as there are atoms in 12 grams of carbon-12 (12C), the isotope of carbon with relative atomic mass 12 by definition. This number is known as Avogadro's number, which is approximately 6.022×10236.022×1023 entities per mole.
Am I missing something? Why use that unit?
Back in 2020, a group at OpenAI ran a conceptually simple test to quantify how much AI progress was attributable to algorithmic improvements. They took ImageNet models which were state-of-the-art at various times between 2012 and 2020, and checked how much compute was needed to train each to the level of AlexNet (the state-of-the-art from 2012). Main finding: over ~7 years, the compute required fell by ~44x. In other words, algorithmic progress yielded a compute-equivalent doubling time of ~16 months (though error bars are large in both directions).
Personally, I would be more interested in the reverse of this test: take all the prior state of the art models, and ask how long you need to train them in order to match the benchmark of current state of the art models.
Would that even work at all? Is there some (non-astronomically large) level of training which makes AlexNet as capable as current state of the art image recognition models?
The experiment that they did is a little like asking "at what age is an IQ 150 person able to do what an adult IQ 70 person is able to do?". But a more interesting question is "How long does it take to make up for being IQ 70 instead of IQ 150?"
I haven't seen careful analysis of LLMs (probably because they're newer, so harder to fit a trend), but eyeballing it... Chinchilla by itself must have been a factor-of-4 compute-equivalent improvement at least.
Ok, but discovering the Chinchilla scaling laws is a one time boost to training efficiency. You should expect to repeatedly get 4x improvements because you observed that one.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
The Story as of ~4 Years Ago
Back in 2020, a group at OpenAI ran a conceptually simple test to quantify how much AI progress was attributable to algorithmic improvements. They took ImageNet models which were state-of-the-art at various times between 2012 and 2020, and checked how much compute was needed to train each to the level of AlexNet (the state-of-the-art from 2012). Main finding: over ~7 years, the compute required fell by ~44x. In other words, algorithmic progress yielded a compute-equivalent doubling time of ~16 months (though error bars are large in both directions).
On the compute side of things, in 2018 a group at OpenAI estimated that the compute spent on the largest training runs was growing exponentially with a doubling rate of ~3.4 months, between 2012 and 2018.
So at the time, the rate of improvement from compute scaling was much faster than the rate of improvement from algorithmic progress. (Though algorithmic improvement was still faster than Moore's Law; the compute increases were mostly driven by spending more money.)
... And That Immediately Fell Apart
As is tradition, about 5 minutes after the OpenAI group hit publish on their post estimating a training compute doubling rate of ~3-4 months, that trend completely fell apart. At the time, the largest training run was AlphaGoZero, at about a mole of flops in 2017. Six years later, Metaculus currently estimates that GPT-4 took ~10-20 moles of flops. AlphaGoZero and its brethren were high outliers for the time, and the largest models today are only ~one order of magnitude bigger.
A more recent paper with data through late 2022 separates out the trend of the largest models, and estimates their compute doubling time to be ~10 months. (They also helpfully separate the relative importance of data growth - though they estimate that the contribution of data was relatively small compared to compute growth and algorithmic improvement.)
On the algorithmic side of things, a more recent estimate with more recent data (paper from late 2022) and fancier analysis estimates that algorithmic progress yielded a compute-equivalent doubling time of ~9 months (again with large error bars in both directions).
... and that was just in vision nets. I haven't seen careful analysis of LLMs (probably because they're newer, so harder to fit a trend), but eyeballing it... Chinchilla by itself must have been a factor-of-4 compute-equivalent improvement at least. And then there's been chain-of-thought and all the other progress in prompting and fine-tuning over the past couple years. That's all algorithmic progress, strategically speaking: it's getting better results by using the same amount of compute differently.
Qualitatively: compare the progress in prompt engineering and Chinchilla and whatnot over the past ~year to the leisurely ~2x increase in large model size predicted by recent trends. It looks to me like algorithmic progress is now considerably faster than scaling.