I've been thinking about neuralese recently, and I'm wondering if there's more of a tradeoff here with interpretability. If we actually could train a model to use neuralese[1], we might be able to make it much smaller and easier to interpret (since it won't need multiple layers to express long-term dependencies). This would make the tokenized output less interpretable but would potentially remove even-less interpretable inner layers.
What do you think?
- ^
I'm actually very skeptical that this is possible without a major breakthrough or some very expensive data.
This is an interesting point. Off the cuff take:
I'm kind of bearish on mechanistic interpretability giving us very complete and satisfying answers about what's going on in models. Neel Nanda also seems to believe this. For the kind of stuff we can do today, like training SAEs or probes, it seems like the difficulty isn't that affected by model size. My vague impression is that scaling up to larger models is bottlenecked primarily on compute, but not that much compute.
Maybe if ambitious interpretability works out, a smaller model will be easier to interpret? But the effect doesn't obviously seem that large to me. Maybe if neuralese lets you make a 2x smaller model, this makes it more than 2x easier to interpret.
Also, it's unclear to me how much smaller you could make the model with neuralese, if at all. (Some) long-term dependencies can already be expressed in the CoT. Maybe many layers are required to express certain otherwise-inarticulable long-term dependencies? It seems plausible that most useful inarticulable thoughts only require short-term cognition. Maybe the part of the post about "picturing a geometric object and turning it around in one's mind for minutes at a time" is a counterexample to this.
If it's possible for the model to reuse the same parameters again and again to improve its own understanding, maybe it's already doing this alongside the CoT by doing something like "thinking dot by dot" in its CoT. Actually, I started writing this and realized this probably proves too much, because it means that continuous thought is never better than thinking dot by dot. I'm showing my ignorance of the details of transformer architecture, but this is supposed to be off-the-cuff, so I'll leave it here for now.
Thanks for the response! That makes a lot of sense.
My intuition is that making the model less deep would make it non-linearly easier to interpret, since the last layers of the model is the most interpretable (since it's closest to human-understable tokens and embeddings), while the earlier layers are interpretable (since they're farther away). Also if layers end up doing duplicate work that could make interpreting the deduplicated version easier. I'm not sure though.
For "thinking dot by dot", I think serial computation can only benefit from roughly as many filler tokens as you have layers, since each layer can only attend to previous layers. For example, if you had a two layer model, position i does some calculations in layer 1, position i+1 can attend to the layer 1 results from position i in layer 2, but at position i+2 there's no layer 3 to attend to the layer 2 outputs from position i+1. Actually LLMs can't use filler tokens for sequential reasoning at all.
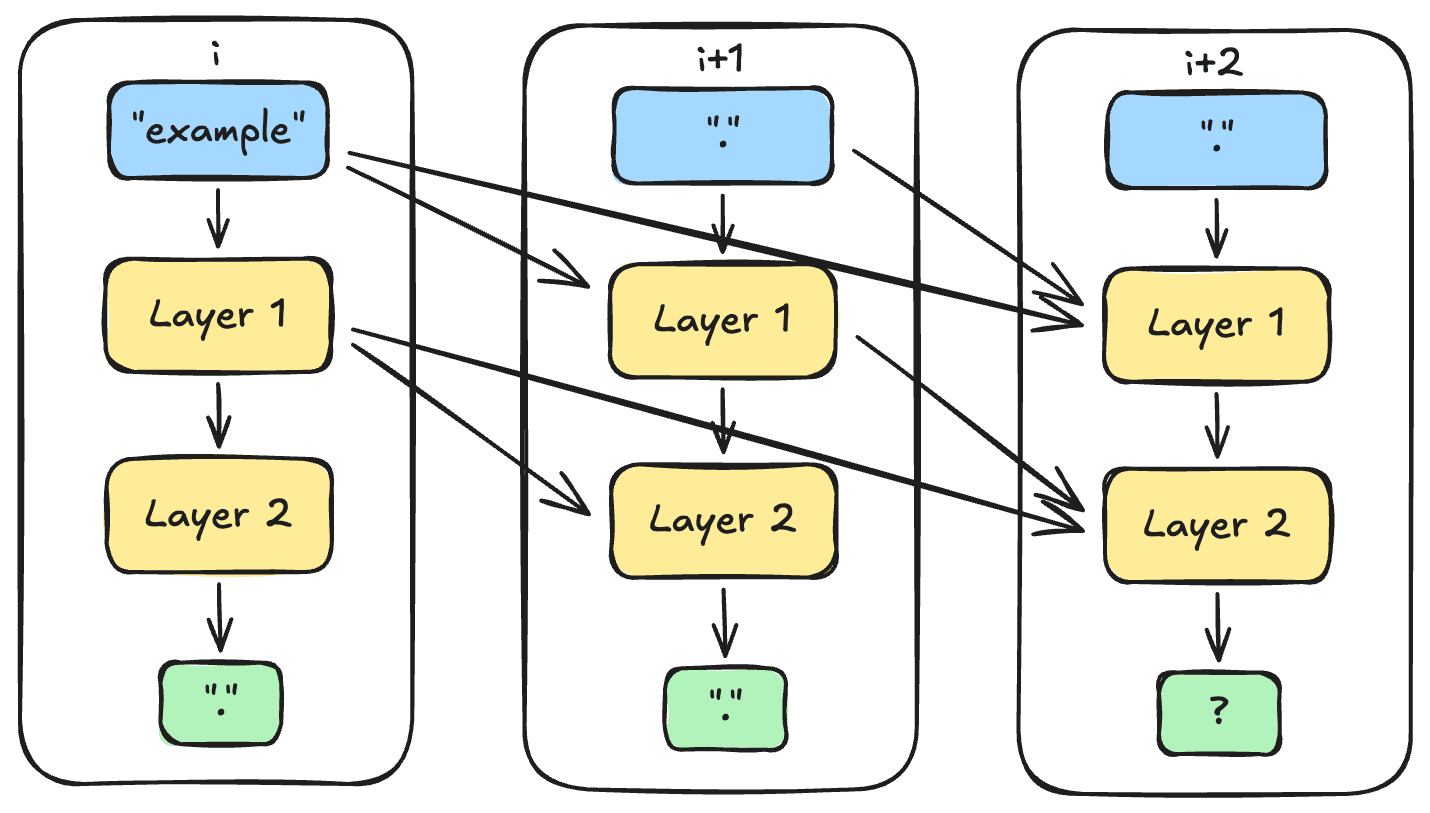
Note how the only difference between position i and i+1 is an additional "." input and the positional encoding.
The dot-by-dot paper uses a highly parallel algorithm, so I think it's more like adding dynamic attention heads / increasing the width of the network, while CoT is more like increasing the number of layers.
If I understand the architecture right (I might not), standard models are already effectively doing neuralese CoT, but bounded by the depth of the network (and also with the caveat that the model has fewer layers remaining to use the results after each step).
Edit: I'm working on a longer post about this but I actually think the dot-by-dot paper is evidence against LLMs being about to do most kinds of reasoning with filler tokens.
Thanks for the explanation of how thinking dot by dot works! That makes sense.
I actually think the dot-by-dot paper is evidence against LLMs being about to do most kinds of reasoning with filler tokens
Yeah, I'm just reading the abstract of the paper, but it looks like it required very "specific" training on their problem to get it to work. I guess this is why you think it's evidence against? But maybe with algorithmic improvements, or due to a CoT where the only goal is getting higher reward rather than looking good to the user, LLMs will naturally gain the ability to use filler tokens effectively.
My intuition is that making the model less deep would make it non-linearly easier to interpret, since the last layers of the model is the most interpretable (since it's closest to human-understandable tokens and embeddings), while the earlier layers are interpretable (since they're farther away).
Well, if some reasoning is inarticulable in human language, the circuits implementing that reasoning would probably be difficult to interpret regardless of what layer they appear in the model. If there's reasoning that is articulable in human language, then presumably the model could just write that reasoning in CoT tokens. Steelman: certain reasoning is almost inarticulable (such that it's impossible to entirely represent it in CoT), but nonetheless pretty "close" to being articulable. If you reduce the number of layers, then the circuit for that reasoning will end up reusing some of the human-language circuitry, whereas otherwise the whole circuit would have been completely inarticulable.
The best reason I have for why reducing model size could nonlinearly improve interpretability is that there are dependencies between different parts of the network, and so the computation you'd need to understand all of these dependencies is O(n^2) or worse.
Anyway, this still seems pretty speculative. I think this argument would probably affect my actions very little or not at all - like, I still think going from CoT to neuralese would be bad and would want to discourage it. But if I had more understanding of mech interp I would feel less uncertain about it.
The post I was working on is out, "Filler tokens don’t allow sequential reasoning". I think LLMs are fundamentally incapable of using filler tokens for sequential reasoning (do x and then based on that do y). I also think LLMs are unlikely to stumble upon the algorithm they came up with in the paper through RL.
Well, if some reasoning is inarticulable in human language, the circuits implementing that reasoning would probably be difficult to interpret regardless of what layer they appear in the model.
This is a good point, and I think I've been missing part of the tradeoff here. If we force the model to output human-understandable concepts at every step, we encourage its thinking to be human-understandable. Removing that incentive would plausibly make the model smaller, but the additional complexity comes from the model doing interpretability for us (both in making its thinking closer-to-human and in building a pipeline to expose those thoughts as words).
Thanks for the back-and-forth on this, it's been very helpful!
This is usually called “neuralese” and my personal guess is that it’s just hard to get working. After all, it’s kind of an obvious idea and no one seems to have gotten any convincing results from it. This paper is pretty much a negative data point actually, particularly considering @wassname’s comment that it hasn’t even replicated on these cherry-picked benchmarks.
That is not so surprising, since the idea behind transformer training is sort of a rejection of neuralese / recurrence?
Well summarized — very similar to the conclusions I'd previously reached when I read the paper.
My current thinking is that
- relying on the CoT staying legible because it's English, and
- hoping the (racing) labs do not drop human language when it becomes economically convenient to do so,
were hopes to be destroyed as quickly as possible. (This is not a confident opinion, it originates from 15 minutes of vague thoughts.)
To be clear, I don't think that in general it is right to say "Doing the right thing is hopeless because no one else is doing it", I typically prefer to rather "do the thing that if everyone did that, the world would be better". My intuition is that it makes sense to try to coordinate on bottlenecks like introducing compute governance and limiting flops, but not on a specific incremental improvement of AI techniques, because I think the people thinking things like "I will restrain myself from using this specific AI sub-techinque because it increases x-risk" are not coordinated enough to self-coordinate at that level of detail, and are not powerful enough to have an influence through small changes.
(Again, I am not confident, I can imagine paths were I'm wrong, haven't worked through them.)
(Conflict of interest disclosure: I collaborate with people who started developing this kind of stuff before Meta.)
The 2 here IMO is more significant than 1, in the sense that if CoT is eventually replaced, it won't be because it's no longer faithful, but rather that companies will eventually replace CoT with something less interpretable.
Update: after a few months, my thinking has moved more to "since you are uncertain, at least do not shoot yourself in the foot first", by which I mean don't actively develop neuralese based on complicated arguments about optimal decisions in collective problems.
I also updated a bit negatively on the present feasibility of neuralese, although I think in principle it's possible to do, and may be done in the future.
Has anyone managed to replicate COCONUT? I've been trying to experiment with adding explainability through sparse linear bottlenecks, but as far as I have found: no one has replicated it.
When working through a problem, OpenAI's o1 model will write a chain-of-thought (CoT) in English. This CoT reasoning is human-interpretable by default, and I think that this is hugely valuable. Assuming we can ensure that these thoughts are faithful to the model's true reasoning, they could be very useful for scalable oversight and monitoring. I'm very excited about research to help guarantee chain-of-thought faithfulness.[1]
However, there's a impending paradigm for LLM reasoning that could make the whole problem of CoT faithfulness obsolete (and not in a good way). Here's the underlying idea, speaking from the perspective of a hypothetical capabilities researcher:
A bit over a month ago, researchers at Meta published the paper Training Large Language Models to Reason in a Continuous Latent Space, which takes this idea and runs with it.
Here's the abstract:
Of course, the big problem with COCONUT is that it replaces our nice, human-readable chain-of-thought with a giant inscrutable vector. If something like COCONUT becomes the new paradigm, it looks like we'll be back to square one when it comes to interpreting LLM reasoning.
In this post, I'll explain my takeaways from the COCONUT paper, focusing on its implications for AI safety and interpretability. Then, I'll give some thoughts on how we can get ready for a possible COCONUT-pilled future.
Takeaways from the paper
Training procedure
The authors train their model in multiple stages. In the first stage, they train it to generate a full chain-of-thought. In each subsequent stage, they remove a single step from the front of the chain and replace it with one or more forward passes. In each pass, the model generates a new "continuous thought," which gets passed through the model again. Eventually, the model switches back to "token mode" to complete the rest of the CoT. After the last training stage, the model can generate a certain number of continuous thoughts and then immediately write its answer, with no CoT at all. Optionally, we can mix earlier stages into the model's training schedule so that the model retains its ability to write a chain-of-thought starting from any step (this will be important later).
Results
The authors test their method on GPT-2 with three different benchmarks: GSM8k, made up of elementary school math problems; ProntoQA, a logical reasoning benchmark for proving simple statements using logical rules; and ProsQA, a benchmark created by the authors which is similar to ProntoQA but with a higher emphasis on searching over multiple reasoning paths. They compare it to supervised fine-tuning on human-made chain-of-thought examples.
The clear benefit of the COCONUT method is its gains in efficiency. On all benchmarks, the technique is able to solve a high proportion of problems with much fewer forward passes than CoT. On GSM8k, it was able to answer problems in an average of 8.2 forward passes, compared to 25.0 for CoT. The other two benchmarks show even greater efficiency gains. However, the paper shows mixed results in terms of accuracy, with COCONUT seeing an 8-percentage-point drop in accuracy vs. CoT on the GSM8k benchmark but higher accuracy on the two logical reasoning benchmarks.
So, COCONUT did worse than CoT finetuning on GSM8k, and only showed an improvement for two toy logical reasoning benchmarks—one of which was created for the purposes of this paper. With that in mind, you might be skeptical that COCONUT is all that effective. Later, I'll explain why I think this could still be a big deal.
Parallelized reasoning
A very interesting insight from the paper is that COCONUT training allows models to explore multiple paths simultaneously.
When given a task to search a graph of logical statements like the above, the model was apparently able to use its continuous thoughts to reason about different paths through the graph simultaneously in a breadth-first search. The authors showed this by demonstrating that the model implicitly updates the "value" of multiple unrelated reasoning paths after each forward pass. Because COCONUT trains a model to write starting from an intermediate step in the CoT, the authors simply used the model to generate some continuous thoughts, stopped it in the middle of its reasoning, then read out its token probabilities to determine its credence for each possible next step being the correct one.[2]
I think part of the explanation for COCONUT's relatively lackluster performance on GSM8k is that these math problems don't really involve exploring multiple paths to find the correct answer. Many domains we train our AIs on, such as advanced mathematics, scientific research, and puzzle solving, require trying out multiple solutions and correcting mistakes, unlike GSM8k. Therefore, despite the more toy nature of the logical reasoning benchmarks used in this paper, they may be more indicative of future capabilities than GSM8k in that respect.
Latent reasoning can do things CoT can't
The parallelized nature of continuous thoughts is just one example of a reasoning technique that CoT just can't offer—I expect there will be others. Intuitively, allowing the model to persist its internal state beyond mere tokens seems to me like it should just work better—if you primarily care about performance on tasks with well-defined, easily-verifiable solutions, where understanding the agent's intermediate process isn't important (a big if).
The logical reasoning task above exists entirely within a small, rigidly-defined graph. For this task, it's probably technically possible to explain the full contents of the model's continuous thoughts, although describing every single useful heuristic and how it's used might take thousands of tokens.
However, if this technique were scaled to a more complex reasoning domain, fully explaining these thoughts may quickly become intractable. Some things are just very difficult to explicitly reason about in words. This is clear for many split-second, intuitive tasks (can you explain the exact algorithm your brain uses to corerct the erorrs in tihs snetecne?), but it could be true for longer-horizon reasoning as well. One concrete example: many mathematical proofs involve some visual intuition. When trying to construct these proofs, humans might picture a geometric object and turn it around in their mind for minutes at a time. If they were restricted to reasoning with words alone, the proof would become much more difficult. Similarly, LLMs might require persistent nonverbal working memory to effectively accomplish certain tasks.
Maybe our attempts to make LLMs use English as their native language will be met with a subtler instance of the Bitter Lesson—just like hand-coding human knowledge into our AIs only served to limit them, we'll discover that the construct of human language itself forms its own limit. Maybe the hope that the performance of human-readable reasoning could compete with latent reasoning is ultimately just cope.
Or maybe not. Right now, it's unclear to me what the future holds, but it may be worth it to start preparing for this possibility now.
COCONUT is not the literal worst for interpretability
Somewhat surprisingly, this particular approach to latent reasoning maintains a tenuous connection between the AI's cognition and human reasoning.
In the paper, the authors lament that the COCONUT technique relies on human-constructed reasoning traces:
However, I consider this to be a good thing! If continuous-thought models are trained using real human reasoning, this might bias them against completely alien reasoning styles.
Another benefit is improved interpretability. As shown above, when the authors make the model switch to writing in English in the middle of its reasoning, they can get a probability distribution over its next reasoning step.
Of course, it would be easier to trust the model's interpretability if it wrote its thoughts in plain English all of the time. It's entirely possible that COCONUT-trained models reason completely differently in their continuous thoughts than in English. Scheming models in particular would likely be able to tell when they are speaking in English vs. in continuous thought and change their English reasoning to look better to humans.
What can we do?
What can we start doing now to account for the possibility that COCONUT-like techniques will dominate over chain-of-thought?
Just... don't use continuous thoughts
The simplest solution, and yet possibly the wisest of all. We don't need to go down this road.
Even if COCONUT is somewhat more efficient than chain-of-thought, it's plausibly worth it from a near-term business perspective for AI labs to continue using CoT. It's simply easier to train, evaluate, and debug your models if they speak in English rather than uninterpretable neuralese.
If you work at an AI lab, please consider advocating against using techniques like COCONUT wherever possible! There's lots of other research to do, and the benefits of this particular research area are very ambiguous.
Of course, your AI lab didn't fall out of a COCONUT tree; it exists in the context of all the other labs. If it starts to become clear that continuous thought is much more efficient than CoT, it may be difficult to convince labs to voluntarily stick with CoT models.
Government regulation
Perhaps governments could pass laws incentivizing labs to train their models to use interpretable reasoning.
One concern is that it may be fairly difficult to enforce such laws. For instance, suppose there were a law broadly requiring that AI models be able to explain the reasoning behind their decisions. It might be easy enough to train a continuous thought model to give a plausible explanation for its answers, but it would be hard to tell whether these explanations are faithful or entirely post-hoc. Perhaps it would be easier to pass laws like this if we could more reliably measure the faithfulness of AI explanations.
It may be easier to pass these sorts of laws sooner rather than later, before labs have already invested into continuous thought research and have reason to advocate against this regulation.
Worst-case scenario: try to interpret the continuous thoughts
Maybe a year or two from now, all of the AI labs will have accepted continuous thought as the new status quo, and there's nothing we can do to make them go back. In this case, we may as well do our best with what we have.
Existing mechanistic interpretability techniques could probably be applied pretty straightforwardly to continuous thoughts. If you think continuous thought is very likely to dominate over CoT in time, you might want to more strongly consider researching mechanistic interpretability.
Outside of mechanistic interpretability, there may be ways to adapt the COCONUT technique itself to be more interpretable. I think this is an interesting area of research, but I'm probably not going to work on it in the near future. The research may never be needed, and I'd also be worried that making COCONUT marginally more interpretable would be counterproductive, possibly encouraging labs to try it when they otherwise wouldn't. However, if you're thinking about this kind of research, I'd be curious to hear about it; feel free to DM me!
I won't focus on CoT faithfulness and why it's important in this post, but see the following links to learn more:
Looking closer at the results, it seems like parallelized reasoning wasn't necessarily enabled by the LLM's continuous thoughts per se. A variant on the COCONUT method called "pause as thought," which simply uses fixed "pause" tokens instead of letting the LLM pick its own latents, didn't do significantly worse on this benchmark than the unablated COCONUT method, so it seems likely that it would have been able to show a similarly accurate distribution over multiple steps. An ablation without any thoughts at all, just the curriculum of progressively removing CoT steps, was worse than full COCONUT on this benchmark, but this difference was barely statistically significant. The authors didn't mention doing the parallel reasoning experiments with these ablations, which seems like an oversight to me.
The authors' point that parallelized reasoning can't be easily reduced to chain-of-thought is still interesting, even if it doesn't depend on COCONUT in particular. If this paper were replicated to use fewer reasoning tokens and larger graphs, I think it's likely we'd see evidence that COCONUT actually helps do additional parallelized reasoning.