This is a special post for quick takes by Arjun Panickssery. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Ask LLMs for feedback on "the" rather than "my" essay/response/code, to get more critical feedback.
Seems true anecdotally, and prompting GPT-4 to give a score between 1 and 5 for ~100 poems/stories/descriptions resulted in an average score of 4.26 when prompted with "Score my ..." versus an average score of 4.0 when prompted with "Score the ..." (code).
3
Perhaps it'd be even better to say that it's okay to be direct or even harsh?
8
Rate my ex's poem.
1
Could try 'grade this' instead of 'score the.'
'Grade' has an implicit context of more thorough criticism than 'score.'
Also, obviously it would help to have a CoT prompt like "grade this essay, laying out the pros and cons before delivering the final grade between 1 and 5"
FiveThirtyEight released their prediction today that Biden currently has a 53% of winning the election | Tweet
The other day I asked:
Should we anticipate easy profit on Polymarket election markets this year? Its markets seem to think that
- Biden will die or otherwise withdraw from the race with 23% likelihood
- Biden will fail to be the Democratic nominee for whatever reason at 13% likelihood
- either Biden or Trump will fail to win nomination at their respective conventions with 14% likelihood
- Biden will win the election with only 34% likelihood
Even if gas fees take a few percentage points off we should expect to make money trading on some of this stuff, right (the money is only locked up for 5 months)? And maybe there are cheap ways to transfer into and out of Polymarket?
Probably worthwhile to think about this further, including ways to make leveraged bets.
I think the FiveThirtyEight model is pretty bad this year. This makes sense to me, because it's a pretty different model: Nate Silver owns the former FiveThirtyEight model IP (and will be publishing it on his Substack later this month), so FiveThirtyEight needed to create a new model from scratch. They hired G. Elliott Morris, whose 2020 forecasts were pretty crazy in my opinion.
Here are some concrete things about FiveThirtyEight's model that don't make sense to me:
- There's only a 30% chance that Pennsylvania, Michigan, or Wisconsin will be the tipping point state. I think that's way too low; I would put this probability around 65%. In general, their probability distribution over which state will be the tipping point state is way too spread out.
- They expect Biden to win by 2.5 points; currently he's down by 1 point. I buy that there will be some amount of movement toward Biden in expectation because of the economic fundamentals, but 3.5 seems too much as an average-case.
- I think their Voter Power Index (VPI) doesn't make sense. VPI is a measure of how likely a voter in a given state is to flip the entire election. Their VPIs are way to similar. To pick a particularly egregious example
3
FWIW the polling in Virginia is pretty close - I'd put my $x against your $4x that Trump wins Virginia, for x <= 200. Offer expires in 48 hours.
3
I'd have to think more about 4:1 odds, but definitely happy to make this bet at 3:1 odds. How about my $300 to your $100?
(Edit: my proposal is to consider the bet voided if Biden or Trump dies or isn't the nominee.)
2
Could we do your $350 to my $100? And the voiding condition makes sense.
4
Yup, sounds good! I've set myself a reminder for November 9th.
2
Have recorded on my website
2
Update for posterity: Nate Silver's model gives Trump a ~1 in 6 chance of winning Virginia, making my side of this bet look bad.
2
Further updates:
* On the one hand, Nate Silver's model now gives Trump a ~30% chance of winning in Virginia, making my side of the bet look good again.
* On the other hand, the Economist model gives Trump a 10% chance of winning Delaware and a 20% chance of winning Illinois, which suggests that there's something going wrong with the model and that it was untrustworthy a month ago.
* That said, betting markets currently think there's only a one in four chance that Biden is the nominee, so this bet probably won't resolve.
2
Looks like this bet is voided. My take is roughly that:
* To the extent that our disagreement was rooted in a difference in how much to weight polls vs. priors, I continue to feel good about my side of the bet.
* I wouldn't have made this bet after the debate. I'm not sure to what extent I should have known that Biden would perform terribly. I was blindsided by how poorly he did, but maybe shouldn't have been.
* I definitely wouldn't have made this bet after the assassination attempt, which I think increased Trump's chances. But that event didn't update me on how good my side of the bet was when I made it.
* I think there's like a 75-80% chance that Kamala Harris wins Virginia.
2
I'm now happy to make this bet about Trump vs. Harris, if you're interested.
2
I'd now make this bet if you were down. Offer expires in 48 hours.
4
Probably no longer willing to make the bet, sorry. While my inside view is that Harris is more likely to win than Nate Silver's 72%, I defer to his model enough that my "all things considered" view now puts her win probability around 75%.
2
I'd like to wait and see what various models say.
6
I have previously bet large sums on elections. Im not currently placing any bets on who will win the election. Seems too unclear to me (note I had a huge bet on biden in 2020, seemed clear then). However there are TONS of mispricings on polymarket and other sites. Things like 'biden will withdraw or lose the nomination @ 23%' is a good example.
4
Given that Biden has dropped out, do you believe that the market was accurately priced at the time?
3
Polymarket has gotten lots of attention in recent months, but I was shocked to find out how much inefficency there really is.
There was a market titled "What will Trump say during his RNC speech?" that was up a few days ago. At 7 pm, the transcript for the speech was leaked, and you could easily find it by a google search or looking at the polymarket discord.
Trump started his speech at 9:30, and it was immediately that he was using the script. One entire hour into the speech I stumbled onto the transcript on Polymarkets discord. Despite the word "prisons" being in the leaked transcript that Trump was halfway through, Polymarket only gave it a 70% chance of being said. I quickly went to bet and made free money.
To be fair it was a smaller market with 800k in bets, but nonetheless I was shocked on how easy it was to make risk-free money.
5
Biden not being the democratic nominee at 13% while EITHER Biden or Trump not being their respective nominees at 14% implies a 1% chance that Trump won't be the Republican nominee. There's clearly an arbitrage there. Whether it merits the costs (gas, risk of polymarket default, lost opportunity of the escrowed wager) I have no clue.
3
Betting against republicans and third parties on poly is a sound strategy, pretty clear they are marketing heavily towards republicans and the site has a crypto/republican bias. For anything controversial/political, if there is enough liq on manifold I generally trust it more (which sounds insane because fake money and all).
That being said, I don't like the way Polymarket is run (posting the word r*tard over and over on Twitter, allowing racism in comments + discord, rugging one side on disputed outcomes, fake decentralization), so I would strongly consider not putting your money on PM and instead supporting other prediction markets, despite the possible high EV.
1
Feel free to write a post if you find something worthwhile. I didn't know how likely the whole Biden leaving the race thing was so 5% seemed prudent. At those odds, even if I belief the fivethirtyeight numbers I'd rather leave my money in etfs. I'd probably need something like >>1,2 multiplier in expected value before I'd bother. Last year when I was betting on Augur I was also heavily bitten by gas fees (150$ transaction costs to get my money back because gas fees exploded for eth), so would be good to know if this is a problem on polymarket also.
1
These predictions, of course, are obviously nonsensical. If I had to guess, it’s a combination of: many crypto users being right-wing and the media they consume has convinced them that this is more likely than it would be in reality, and climbing crypto prices discouraging betting leading to decreased accuracy. I’ll say that the climbing value of the currency as well as gas fees makes any prediction unwise, unless you believe you have massive advantage over the market. I’d personally pass on it, but other people are free to proceed with their money.
Should we anticipate easy profit on Polymarket election markets this year? Its markets seem to think that
- Biden will die or otherwise withdraw from the race with 23% likelihood
- Biden will fail to be the Democratic nominee for whatever reason at 13% likelihood
- either Biden or Trump will fail to win nomination at their respective conventions with 14% likelihood
- Biden will win the election with only 34% likelihood
Even if gas fees take a few percentage points off we should expect to make money trading on some of this stuff, right (the money is only locked up for 5 months)? And maybe there are cheap ways to transfer into and out of Polymarket?
4
I think part of the reason why these odds might seem more off than usual is that Ether and other cryptocurrencies have been going up recently which means there is high demand for leveraged positions. This in turn means that crypto lending services such as aave having been giving ~10% APY on stablecoins which might be more appealing than a riskier, but only a bit higher, return from prediction markets.
2
They all seem like reasonable estimates to me. What do you think those likelihoods should be?
Paid-only Substack posts get you money from people who are willing to pay for the posts, but reduce both (a) views on the paid posts themselves and (b) related subscriber growth (which could in theory drive longer-term profit).
So if two strategies are
- entice users with free posts but keep the best posts behind a paywall
- make the best posts free but put the worst posts behind the paywall
then regarding (b) above. the second strategy has less risk of prematurely stunting subscriber growth, since the best posts are still free. Regarding (a), it's much less bad to lose view counts on your worst posts.
3. put the spiciest posts behind a paywall, because you have something to say but don't want the entire internet freaking out about it.
5
Not sure if you intended this precise angle on it, but laying it out explicitly: If you compare a paid subscriber vs other readers, the former seems more likely to share your values and such, as well as have a higher prior probability on a thing you said being a good thing, and therefore less likely to e.g. take a sentence out of context, interpret it uncharitably, and spread outrage-bait. So posts with higher risk of negative interpretations are better fits for the paying audience.
4
Substack started off so transparent and data-oriented. It's sad that they don't publish stats on various theories and their impact. Presumably you don't have to be that legible with your readers/subscribers, and you can test out (probably on a monthly or quarterly basis, not post-by-post) what attributes of a post advise toward being public, and what attributes lead to a private post. The feedback loop is distant enough that it's not a simple classifier.
You're missing at least one strategy - paid for frequent short-term takes, free for delayed summaries.
2
More strategies:
* all articles start paid, the become free after 1 month
* articles are free, discussions are paid
* articles are free, open threads are paid
2
I believe Sarah Constantin's self-described strategy is roughly (b). You actually pay for "squishy" stuff, but she says she thinks squishy stuff is worse (though the wrinkle is that she implies readers maybe think the opposite).
Another set of strategies I've been thinking about are for mailing lists. You can either have your archives eventually become free (can't think of an example here, but I think it's fairly common for Patreon-supported writers to have an "early access" model), or you can have your newsletter be free but archives be fee-guarded (for example Money Stuff uses this model).
1[anonymous]
Is there any actual evidence of (b) being true? You can easily make the heuristic argument that paywalling generates additional demand by incentivizing readers to subscribe in order to access otherwise unavailable posts. We would need some data to figure out what the reality on the ground is.
4
By "subscriber growth" in OP I meant both paid and free subscribers.
My thinking was that people subscribe after seeing posts they like, so if they get to see the body of a good post they're more likely to subscribe than if they only see the title and the paywall. But I guess if this effect mostly affects would-be free subscribers then the effect mostly matters insofar as free subscribers lead to (other) paid subscriptions.
(I say mostly since I think high view/subscriber counts are nice to have even without pay.)
[Book Review] The 8 Mansion Murders by Takemaru Abiko
As a kid I read a lot of the Sherlock Holmes and Hercule Poirot canon. Recently I learned that there's a Japanese genre of honkaku ("orthodox") mystery novels whose gimmick is a fastidious devotion to the "fair play" principles of Golden Age detective fiction, where the author is expected to provide everything that the attentive reader would need to come up with the solution himself. It looks like a lot of these honkaku mysteries include diagrams of relevant locations, genre-savvy characters, and a puzzle-like aesthetic. A bunch have been translated by Locked Room International.
The title of The 8 Mansion Murders doesn't refer to the number of murders, but to murders committed in the "8 Mansion," a mansion designed in the shape of an 8 by the eccentric industrialist who lives there with his family (diagrams show the reader the layout). The book is pleasant and quick—it didn't feel like much over 50,000 words. Some elements feel very Japanese, like the detective's comic-relief sidekick who suffers increasingly serious physical-comedy injuries. The conclusion definitely fits the fair-play genre in that it makes sense, could be...
4
What about a book review of “The Devotion of Suspect X”?
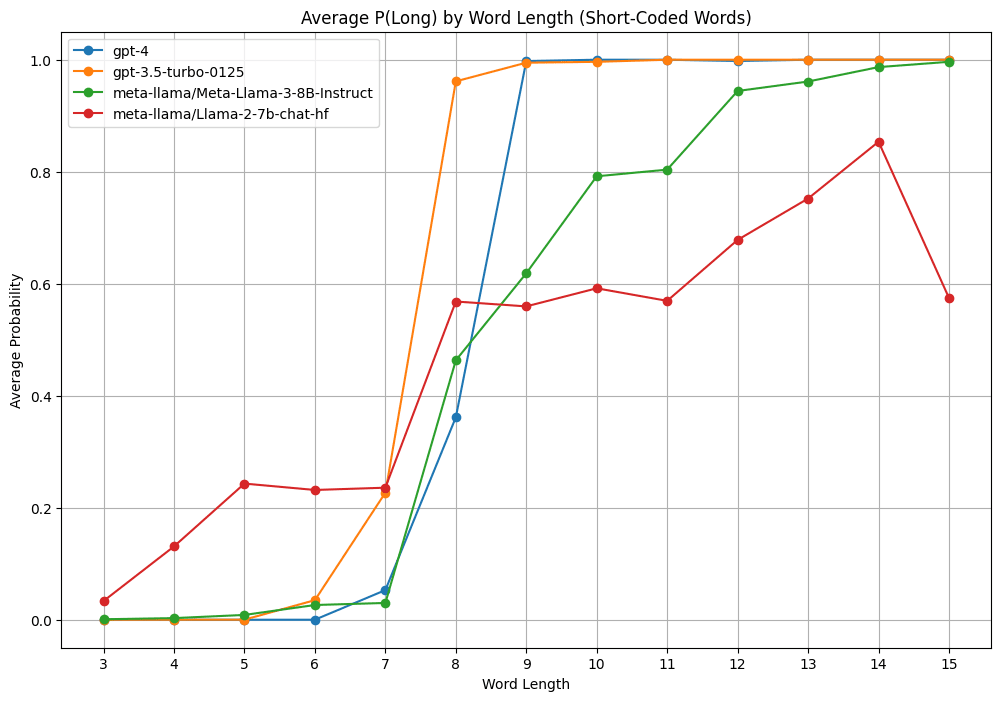
To test out Cursor for fun I asked models whether various words of different lengths were "long" and measured the relative probability of "Yes" vs "No" answers to get a P(long) out of them. But when I use scrambled words of the same length and letter distribution, GPT 3.5 doesn't think any of them are long.
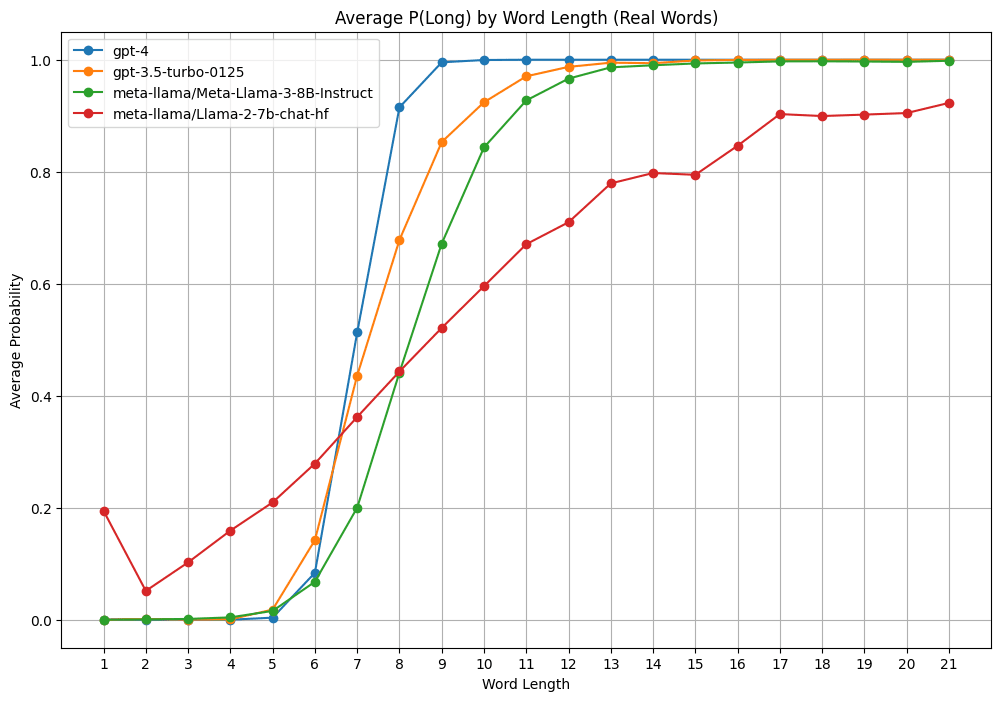

Update: I got Claude to generate many words with connotations related to long ("mile" or "anaconda" or "immeasurable") and short ("wee" or "monosyllabic" or "inconspicuous" or "infinitesimal") It looks like the models have a slight bias toward the connotation of the word.

Just flagging that for humans, a "long" word might mean a word that's long to pronounce rather than long to write (i.e. ~number of syllables instead of number of letters)
4
It's interesting how llama 2 is the most linear—it's keeping track of a wider range of lengths. Whereas gpt4 immediately transitions from long to short around 5-8 characters because I guess humans will consider any word above ~8 characters "long."
3
Interesting. I wonder if it's because scrambled words of the same length and letter distribution are tokenized into tokens which do not regularly appear adjacent to each other in the training data.
If that's what's happening, I would expect gpt3.5 to classify words as long if they contain tokens that are generally found in long words, and not otherwise. One way to test this might be to find shortish words which have multiple tokens, reorder the tokens, and see what it thinks of your frankenword (e.g. "anozdized" -> [an/od/ized] -> [od/an/ized] -> "odanized" -> "is odanized a long word?").
2
What did you actually ask the models? Could it be that it says that diuhgikthiusgsrbxtb is not a long word because it is not a word?
6
Code: https://github.com/ArjunPanickssery/long_short
What's the actual probability of casting a decisive vote in a presidential election (by state)?
I remember the Gelman/Silver/Edlin "What is the probability your vote will make a difference?" (2012) methodology:
...1. Let E be the number of electoral votes in your state. We estimate the probability that these are necessary for an electoral college win by computing the proportion of the 10,000 simulations for which the electoral vote margin based on all the other states is less than E, plus 1/2 the proportion of simulations for which the margin based on all other
2
I would assum they have the math right but not really sure why anyone cares. It's a bit like the Voter's Paradox. In and of it self it points to an interesting phenomena to investivate but really doesn't provide guidance for what someone should do.
I do find it odd that the probabilities are so low given the total votes you mention, and adding you also have 51 electoral blocks and some 530-odd electoral votes that matter. Seems like perhaps someone is missing the forest for the trees.
I would make an observation on your closing thought. I think if one holds that people who are not well informed, or perhaps less intelligent and so not as good at choosing good representatives then one quickly gets to most/many people should not be making their own economic decisions on consumption (or savings or investments). Simple premise here is that capital allocation matters to growth and efficiency (vis-a-vis production possibilities frontier). But that allocation is determined by aggregate spending on final goods production -- i.e. consumer goods.
Seems like people have a more direct influence on economic activity and allocation via their spending behavior than the more indirect influence via politics and public policy.
Is this argument about determinism and moral judgment flawed?
- If determinism is true, then whatever can be done actually is done. (Definition)
- Whatever should be done, can be done. (Well-known "ought implies can" principle)
- If determinism is true, then whatever ought to be done actually is done (from 1, 2).
The context is that it appears to me that people reject determinism largely because they're committed to certain moral positions that are incompatible with determinism. Perhaps I will write a longer post about this.
hmm, I think the argument isn't valid:
- The "can" in Line 2 refers to logical possibility.
- At least, I think that's that's true of Kant's "ought implies can" principle.
- The "can" in Line 1 refers to physical possibility.
- The argument is sound only if the two "can"s refer to the same modality.
You could replaced the "can" in Line 1 with logical possibility, and then the argument would be valid. The view that whatever can logically be done actually is done is called Necessitarianism. It's pretty fringe.
Alternatively, you could replace the "can" in Line 2 with physical possibility, and then the argument would be valid. I don't know if that view has a name, it seems pretty implausible.
4
No I think Kant's "ought implies can" principle usually uses "can" to mean some kind of "practical possibility" that means "possible given your powers and opportunities" or something. And whatever is possible in that sense is also physically possible (i.e. "possible given the actual state of the world and physical laws"). So the argument is still sound.
5
In other words:
Ought to be done⊆Can be done⊆Actually done⇒Ought to be done⊆Actually done
My fuzzy intuition would be to reject Ought to be done⊆Can be done (step 2 of your argument) if we accept determinism. And my actually philosophical position would be that these types of questions are not very useful and generally downstream of more fundamental confusions.
2
What fundamental confusions?
4
This seems closely related to an argument I vaguely remember from a philosophy class:
1. A person is not morally culpable of something if they could not have done otherwise
2. If determinism is true, there is only one thing a person could do
3. If there is only one thing a person could do, they could not have done otherwise
4. If determinism is true, whatever someone does, they are not morally culpable
4
In fact the argument is basically the same I think. And I know Michael Huemer has a post using it in the modus ponens form to write a proof of free will presuming moral realism.
(MFT is his "minimal free-will thesis": least some of the time, someone has more than one course of action that he can perform).
1.With respect to the free-will issue, we should refrain from believing falsehoods. (premise)2.Whatever should be done can be done. (premise)3.If determinism is true, then whatever can be done, is done. (premise)4.I believe MFT. (premise)5.With respect to the free-will issue, we can refrain from believing falsehoods. (from 1,2)6.If determinism is true, then with respect to the free will issue, we refrain from believing falsehoods. (from 3,5)7.If determinism is true, then MFT is true. (from 6,4)8.MFT is true. (from 7)
This man's modus ponens is definitely my modus tollens. It seems super cursed to use moral premises to answer metaphysics problems. In this argument, except for step 8, you can replace belief in free will with anything, and the argument says that determinism implies that any widely held belief is true.
"Ought implies can" should be something that's true by construction of your moral system, rather than something you can just assert about an arbitrary moral system and use to derive absurd conclusions.
2
I suspect that "ought implies can" comes from legal/compatibilist thinking, ie. you can do something if it is generally within your powers, and you are not being actively compelled to do otherwise.
2
Yes I agree to be clear.
4
Some thoughts on reconciling physical determinism with morality —
The brains of agents are where those agents' actions are calculated. Although agents are physically determined, they can be arbitrarily computationally intractable, so there is no general shortcut to predict their actions with physics-level accuracy. If you want to predict what agent Alice does in situation X, you have to actually put Alice in situation X and observe. (This differentiates agents from things like billiard-balls, which are computationally tractable and can be predicted using simple physics equations.)
And yet, one input to an agent's decision process is its prediction of other agents' responses to the actions the agent is considering. Since agents are hard to predict, a lot of computation has been spent on doing this! And although Alice cannot in general and with physics-level accuracy predict Bob's responses to her actions, there are a lot of common regularities in the pattern of agents' responses to other agents' actions.
Some of these regularities have to do with things like "this agent supports or opposes that agent's actions" or "these agents join together to support or oppose that agent's actions" or "this agent alters the incentive structure under which another agent decides its actions" or "this group of agents are cooperating on achieving a common goal" or "this agent aims to stop that agent from existing, while that agent aims to keep existing" and other relatively compactly-describable sorts of things.
Even though "Alice wants to live" is not a physics-level description of Alice, it is still useful for predicting Alice's actions at a more abstract level. Alice is not made of wanting-to-live particles, but Alice reliably refrains from jumping off cliffs or picking fights with tigers; instead she cooperates with other agents towards common goals of supporting one another's continued living, and so on.
And things like morality make sense at that level, describing regulariti
5
Things like morality, such as economics describe behaviour. Morality, however, is normative.
It should not come as a surprise that reductionism doesn't require you to abandon all high level concepts.
1[comment deleted]
2
Yes, an obvious flaw is that 1 is obviously false. Though also 2 is false depending upon exactly how you view the term "a person".
2
Why is (1) obviously false?
2
Partly for the reasons outlined in my comment here. Mainly the following section:
In another comment (that I'm not finding after some minutes of search) I outline why this distinction is one that should be (and is) called moral culpability for all practical and most philosophical purposes. The few exceptions aren't relevant here, since even one counterexample renders the argument invalid.
2
Yeah, seems like it fails mainly on 1, though I think that depends on whether you accept the meaning of "could not have done otherwise" implied by 2/3. But if you accept a meaning that makes 1 true (or, at least, less obviously false), then the argument is no longer valid.
2
By analogous reasoning, if determinism is true, then whatever ought not to be done also actually is done.
2
Why? If you're taking as a premise that "Whatever ought not to be done can actually be done" then I don't think that makes sense.
2
I think that makes as much sense as "Whatever ought to be done can actually be done". Do you have some argument that makes sense of one but not the other?
2
It makes intuitive sense to me to say that if you have no way to do something, then it's nonsensical to say that you should do that thing. For example, if I say that you should have arrived to an appointment on time and you say that it would be impossible because I only told you about it an hour ago and it's 1000 miles away, then it would be nonsensical for me to say that you should have arrived on time anyway. This is equivalent to saying that if you should do something, then you can do it.
The converse "Whatever ought to be avoided can actually be done" doesn't make sense because there's no equivalent intuition.
4
The analogous argument would be:
If I have no way to do something, then it's nonsensical to say that I should avoid doing that thing. For example, if you say that I should have avoided arriving to an appointment on time and I say that it would be impossible because you only told me about it an hour ago and it's 1000 miles away, then it would be nonsensical for you to say that I should have avoided arriving in time anyway. This is equivalent to saying that if I should avoid doing something, then I can do it.
2
I don't think this premise is as intuitive. For example, if someone said that a quadriplegic should have saved a nearby drowning child, then the objective appears immediately this it wouldn't have been possible and so the "should" claim isn't reasonable. On the other hand, if you say that the quadriplegic should avoid intentionally drowning the child, I don't think that's clearly nonsensical or false.
1
"You should have taken every opportunity that you could to get there on time."
"I did. I had zero opportunities to do so, and I took all zero of them."
1
Since agents are running under computational constraints, so there are many ought statements which might not happen, e.g. due to chaotic systems. So in practice even in a deterministic universe agents can’t guarantee that ought -> can.
Interesting Twitter post from some time ago (hard to find the original since Twitter search doesn't work for Tweets over the Tweet limit but I think it's from Ceb. K) about a book called The Generals about accountability culture.
...On the day Germany invaded Poland, Marshall was appointed Army Chief of Staff. At the time, the US Army was smaller than Bulgaria’s—just 100,000 poorly-equipped and poorly-organized active personnel—and he bluntly described them as eg “not even third-rate.” By the end of World War II, he had grown it 100-fold, and modernized it far
4
Unfortunately, being unpredictable and aggressive and hated is not sufficient to produce good results.
The level of competence I associate with crazy people working for Elon or Trump is more like: "Tell them to find the woke programs that need to be purged for political reasons, and they bring you a bunch of chemical studies on trans-isomers, despite having all necessary information and the state of the art artificial intelligence at their disposal". Like, a high school student with a free version of ChatGPT would probably do a better job.
(I am specifically making note about having the AI at their disposal, to address a possible excuse "well, they had to act quickly, and there were too many studies and not enough time".)
4
Link to tweet: https://x.com/CEBKCEBKCEBK/status/1887394977258356898
Searching "On the day Germany invaded Poland, Marshall was appointed Army Chief of Staff." on Twitter finds that Tweet; other snippets from the quote don't work. Given your comment, grok-4-1-thinking-1129 via grok.com, sometimes finds that tweet.
Could someone explain how Rawls's veil of ignorance justifies the kind of society he supports? (To be clear I have an SEP-level understanding and wouldn't be surprised to be misunderstanding him.)
It seems to fail at every step individually:
- At best, the support of people in the OP provides necessary but probably insufficient conditions for justice, unless he refutes all the other proposed conditions involving whatever rights, desert, etc.
- And really the conditions of the OP are actively contrary to good decision-making, e.g. you don't know your particular co
3
My objection is the dualism implied by the whole idea. There's no consciousness that can have such a veil - every actual thinking/wanting person is ALREADY embodied and embedded in a specific context.
I'm all in favor of empathy and including terms for other people's satisfaction in my own utility calculations, but that particular justification never worked for me.
1
I had also for a long time trouble believing that Rawls' theory centered around "OP -> maximin" could get the traction it has. For what it's worth:
A. IMHO, the OP remains a great intuition pump for 'what is just'. 'Imagine, instead of optimizing for your own personal good, you optimized for that of everyone.' I don't see anything misguided in that idea; it is an interesting way to say: Let's find rules that reflect the interest of everyone, instead of only that of a ruling elite or so. Arguably, we could just say the latter more directly, but the veil may be making the idea somewhat more tangible, or memorable.
B. Rawls is not the inventor of the OP. Harsanyi has introduced the idea earlier, though Rawls seems to have failed to attribute it to Harsanyi.
C. Harsanyi, in his 1975 paper Can the Maximin Principle Serve as a Basis for Morality? A Critique of John Rawls's Theory uses rather strong words when he explains that claiming the OP led to the maximin is a rather appalling idea. The short paper is soothing for any Rawls-skeptic; I heavily recommend it (happy to send a copy if sb is stuck at the paywall).
1
Here are some responses to Rawls from my debate files:
A2 Rawls
* Ahistorical
* Violates property rights
* Does not account for past injustices eg slavery, just asks what kind of society would you design from scratch. Thus not a useful guide for action in our fucked world.
* Acontextual
* Veil of ignorance removes contextual understanding, which makes it impossible to assess different states of the world. Eg from the original position, Rawls prohibits me from using my gender to inform my understanding of gender in different states of the world
* Identity is not arbitrary! It is always contingent, yes, but morality is concerned with the interactions of real people, who have capacities, attitudes, and preferences. There are reasons for these things that are located in individual experiences and contexts, so they are not arbitrary.
* But even if they were the result of pure chance, it’s unclear that these coincidences are the legitimate subject of moral scrutiny. I *am* a white man - I can’t change that. They need to explain why morality should be pretend otherwise. Only after conditioning on our particular context can we begin to reason morally.
* The one place Rawls is interested in context is bad: he says the principle should only be applied within a society: but this precludes action on global poverty.
* Rejects economic growth: the current generation is the one that is worst-off; saving now for future growth necessarily comes at the cost of foregone consumption, which hurts the current generation.
1
1. It’s pretty much a complete guide to action? Maybe there are decisions where it is silent, but that’s true of like every ethical theory like this (“but util doesn’t care about X!”). I don’t think the burden is on him to incorporate all the other concepts that we typically associate with justice. At very least not a problem for “justifying the kind of society he supports”
2. Like the two responses to this are either “Rawls tells you the true conception of the good, ignore the other ones” or “just allow for other-regarding preferences and proceed as usual” and either seems workable
3. Sure
4. Agree in general that Rawls does not account for different risk preferences but infinite risk aversion isn’t necessary for most practical decisions
5. Agree Rawls doesn’t usually account for future. But you could just use veil of ignorance over all future and current people, which collapses this argument into a specific case of “maximin is stupid because it doesn’t let us make the worst-off people epsilon worse-off in exchange for arbitrary benefits to others”
I think (B) is getting at a fundamental problem
Quick Take: People should not say the word "cruxy" when already there exists the word "crucial." | Twitter
Crucial sometimes just means "important" but has a primary meaning of "decisive" or "pivotal" (it also derives from the word "crux"). This is what's meant by a "crucial battle" or "crucial role" or "crucial game (in a tournament)" and so on.
So if Alice and Bob agree that Alice will work hard on her upcoming exam, but only Bob thinks that she will fail her exam—because he thinks that she will study the wrong topics (h/t @Saul Munn)—then they might have ...
4
disagree because the word crucial is being massively overused lately.
3
I think it disambiguates by saying it's specifically a crux as in "double crux"
7
If I understand the term "double crux" correctly, to say that something is a double crux is just to say that it is "crucial to our disagreement."
2
Using the word 'cruxy' encourages people to use the mental model of what the cruxes in the conversation happen to be. Encouraging the use of effective mental models is a useful task for language.
2
"Crucial to our disagreement" is 8 syllables to "cruxy"'s 2.
"Dispositive" is quite American, but has a more similar meaning to "cruxy" than plain "crucial". "Conclusive" or "decisive" are also in the neighbourhood, though these are both feel like they're about something more objective and less about what decides the issue relative to the speaker's map.
0
I agree people shouldn’t use the word cruxy. But I think they should instead just directly say whether a consideration is a crux for them. I.e. whether a proposition, if false, would change their mind.
Edit: Given the confusion, what I mean is often people use “cruxy” in a more informal sense than “crux”, and label statements that are similar to statements that would be a crux but are not themselves a crux “cruxy”. I claim here people should stick to the strict meaning.