The actual result here looks right to me, but kinda surfaces a lot of my confusion about how people in this space use coherence theorems/reinforces my sense they get misused
You say:
This ties to a common criticism: that any system can be well-modeled as a utility maximizer, by simply choosing the utility function which rewards whatever the system in fact does. As far as I can tell, that criticism usually reflects ignorance of what coherence says
My sense of how this conversation goes is as follows:
"Utility maximisers are scary, and here are some theorems that show that anything sufficiently smart/rational (i.e. a superintelligence) will be a utility maximiser. That's scary"
"Literally anything can be modelled as a utility maximiser. It's not the case that literally everything is scary, so something's wrong here"
"Well sure, you can model anything as a utility maximiser technically, but the resource w.r.t which it's being optimal/the way its preferences are carving up state-space will be incredibly awkward/garbled/unnatural (in the extreme, they could just be utility-maximizing over entire universe-histories). But these are unnatural/trivial. If we add constraints over the kind of resources it's caring about/kinds of outcomes it can have preferences over, we constrain the set of what can be a utility-maximiser a lot. And if we constrain it to smth like the set of resources that we think in terms of, the resulting set of possible utility-maximisers do look scary"
Does this seem accurate-ish? If so it feels like this last response is true but also kind of vacuously so, and kind of undercuts the scariness of the coherence theorems in the first place. As in, it seems much more plausible that a utility-maximiser drawn from this constrained set will be scary, but then where's the argument we're sampling from this subset when we make a superintelligence? It feels like there's this weird motte-and-bailey going on where people flip-flop between the very unobjectionable "it's representable as a utility-maximiser" implied by the theorems and "it'll look like a utility-maximiser "internally", or relative to some constrained set of possible resources s.t. it seems scary to us" which feels murky and un-argued for.
Also on the actual theorem you outline here - it looks right, but isn't assuming utilities assigned to outcomes s.t. the agent is trying to maximise over them kind of begging most of the question that coherence theorems are after? i.e. the starting data is usually a set of preferences, with the actual work being proving that this along with some assumptions yields a utility function over outcomes. This also seems why you don't have to use anything like dutch-book arguments etc as you point out - but only because you've kind of skipped over the step where they're used
Well sure, you can model anything as a utility maximiser technically, but the resource w.r.t which it's being optimal/the way its preferences are carving up state-space will be incredibly awkward/garbled/unnatural (in the extreme, they could just be utility-maximizing over entire universe-histories). But these are unnatural/trivial. If we add constraints over the kind of resources it's caring about/kinds of outcomes it can have preferences over, we constrain the set of what can be a utility-maximiser a lot. And if we constrain it to smth like the set of resources that we think in terms of, the resulting set of possible utility-maximisers do look scary.
I would guess that response is memetically largely downstream of my own old take. It's not wrong, and it's pretty easy to argue that future systems will in fact behave efficiently with respect to the resources we care about: we'll design/train the system to behave efficiently with respect to those resources precisely because we care about those resources and resource-usage is very legible/measurable. But over the past year or so I've moved away from that frame, and part of the point of this post is to emphasize the frame I usually use now instead.
In that new frame, here's what I would say instead: "Well sure, you can model anything as a utility maximizer technically, but usually any utility function compatible with the system's behavior is very myopic - it mostly just cares about some details of the world "close to" (in time/space) the system itself, and doesn't involve much optimization pressure against most of the world. If a system is to apply much optimization pressure to parts of the world far away from itself - like e.g. make & execute long-term plans - then the system must be a(n approximate) utility maximizer in a much less trivial sense. It must behave like it's maximizing a utility function specifically over stuff far away."
(... actually that's not a thing I'd say, because right from the start I would have said that I'm using utility maximization mainly because it makes it easy to illustrate various problems. Those problems usually remain even when we don't assume utility maximization, they're just a lot less legible without a mathematical framework. But, y'know, for purposes of this discussion...)
Also on the actual theorem you outline here - it looks right, but isn't assuming utilities assigned to outcomes s.t. the agent is trying to maximise over them kind of begging most of the question that coherence theorems are after?
In my head, an important complement to this post is Utility Maximization = Description Length Minimization, which basically argues that "optimization" in the usual Flint/Yudkowsky sense is synonymous with optimizing some utility function over the part of the world being optimized. However, that post doesn't involve an optimizer; it just talks about stuff "being optimized" in a way which may or may not involve a separate thing which "does the optimization".
This post adds the optimizer to that picture. We start from utility maximization over some "far away" stuff, in order to express optimization occurring over that far away stuff. Then we can ask "but what's being adjusted to do that optimization?", i.e. in the problem what's ? And if is the "policy" of some system, such that the whole setup is an MDP, then find that there's a nontrivial sense in which the system can be or not be a (long-range) utility maximizer - i.e. an optimizer.
Thanks, I feel like I understand your perspective a bit better now.
Re: your "old" frame: I agree that the fact we're training an AI to be useful from our perspective will certainly constrain its preferences a lot, such that it'll look like it has preferences over resources we think in terms of/won't just be representable as a maximally random utility function. I think there's a huge step from that though to "it's a optimizer with respect to those resources" i.e there are a lot of partial orderings you can put over states where it broadly has preference orderings we like w.r.t resources without looking like a maximizer over those resources, and I don't think that's necessarily scary. I think some of this disagreement may be downstream of how much you think a superintelligence will "iron out wrinkles" like preference gaps internally though which is another can of worms
Re: your new frame: I think I agree that looking like a long-term/distance planner is much scarier. Obviously implicitly assuming we're restricting to some interesting set of resources, because otherwise we can reframe any myopic maximizer as long-term and vice-versa. But this is going round in circles a bit, typing this out I think the main crux here for me is what I said in the previous point in that I think there's too much of a leap from "looks like it has preferences over this resource and long-term plans" vs. "is a hardcore optimizer of said resource". Maybe this is just a separate issue though, not sure I have any local disagreements here
Re: your last pont, thanks - I don't think I have a problem with this, I think I was just misunderstanding the intended scope of the post
Obviously implicitly assuming we're restricting to some interesting set of resources, because otherwise we can reframe any myopic maximizer as long-term and vice-versa.
This part I think is false. The theorem in this post does not need any notion of resources, and neither does Utility Maximization = Description Length Minimization. We do need a notion of spacetime (in order to talk about stuff far away in space/time), but that's a much weaker ontological assumption.
I think what I'm getting at is more general than specifically talking about resources, I'm more getting at the degree of freedom in the problem description that lets you frame anything as technically optimizing something at a distance i.e. in 'Utility Maximization = Description Length Minimization' you can take any system, find its long-term and long-distance effects on some other region of space-time, and find a coding-scheme where those particular states have the shortest descriptions. The description length of the universe will by construction get minimized. Obviously this just corresponds to one of those (to us) very unnatural-looking "utility functions" over universe-histories or w/e
If we're first fixing the coding scheme then this seems to me to be equivalent to constraining the kinds of properties we're allowing as viable targets of optimization
I guess one way of looking at it is I don't think it makes sense to talk about a system as being an optimizer/not an optimizer intrinsically. It's a property of a system relative to a coding scheme/set of interesting properties/resources, everything is an optimizer relative to some encoding scheme. And all of the actual, empirical scariness of AI comes from how close the encoding scheme that by-definition makes it an optimizer is to our native encoding scheme - as you point out they'll probably have some overlap but I don't think that itself is scary
All possible encoding schemes / universal priors differ from each other by at most a finite prefix. You might think this doesn't achieve much, since the length of the prefix can be in principle unbounded; but in practice, the length of the prefix (or rather, the prior itself) is constrained by a system's physical implementation. There are some encoding schemes which neither you nor any other physical entity will ever be able to implement, and so for the purposes of description length minimization these are off the table. And of the encoding schemes that remain on the table, virtually all of them will behave identically with respect to the description lengths they assign to "natural" versus "unnatural" optimization criteria.
The constant bound isn't not that relevant just because of the in principal unbounded size, it also doesn't constrain the induced probabilities in the second coding scheme much at all. It's an upper bound on the maximum length, so you can still have the weightings in codings scheme B differ differ in relative length by a ton, leading to wildly different priors
And of the encoding schemes that remain on the table, virtually all of them will behave identically with respect to the description lengths they assign to "natural" versus "unnatural" optimization criteria.
I have no idea how you're getting to this, not sure if it's claiming a formal result or just like a hunch. But I disagree both that there is a neat correspondence between a system being physically realizable and its having a concise implementation as a TM. Even granting that point, I don't think that nearly all or even most of these physically realisable systems will behave identically or even similarly w.r.t. how they assign codes to "natural" optimization criteria
The constant bound isn't not that relevant just because of the in principal unbounded size, it also doesn't constrain the induced probabilities in the second coding scheme much at all. It's an upper bound on the maximum length, so you can still have the weightings in codings scheme B differ differ in relative length by a ton, leading to wildly different priors
Your phrasing here is vague and somewhat convoluted, so I have difficulty telling if what you say is simply misleading, or false. Regardless:
If you have UTM1 and UTM2, there is a constant-length prefix P such that UTM1 with P prepended to some further bitstring as input will compute whatever UTM2 computes with only that bitstring as input; we can say of P that it "encodes" UTM2 relative to UTM1. This being the case, each function indexed by UTM1 differs from its counterpart for UTM2 by a maximum of len(P), because whenever it's the case that a given function would otherwise be encoded in UTM1 by a bitstring longer than len(P + [the shortest bitstring encoding the function in UTM2]), the prefixed version of that function simply is the shortest bitstring encoding it in UTM1.
One of the consequences of this, however, is that this prefix-based encoding method is only optimal for functions whose prefix-free encodings (i.e. encodings that cannot be partitioned into substrings such that one of the substrings encodes another UTM) in UTM1 and UTM2 differ in length by more than len(P). And, since len(P) is a measure of UTM2's complexity relative to UTM1, it follows directly that, for a UTM2 whose "coding scheme" is such that a function whose prefix-free encoding in UTM2 differs in length from its prefix-free encoding in UTM1 by some large constant (say, ~2^10^80), len(P) itself must be on the order of 2^10^80—in other words, UTM2 must have an astronomical complexity relative to UTM1.
I have no idea how you're getting to this, not sure if it's claiming a formal result or just like a hunch. But I disagree both that there is a neat correspondence between a system being physically realizable and its having a concise implementation as a TM. Even granting that point, I don't think that nearly all or even most of these physically realisable systems will behave identically or even similarly w.r.t. how they assign codes to "natural" optimization criteria
For any physically realizable universal computational system, that system can be analogized to UTM1 in the above analysis. If you have some behavioral policy that is e.g. deontological in nature, that behavioral policy can in principle be recast as an optimization criterion over universe histories; however, this criterion will in all likelihood have a prefix-free description in UTM1 of length ~2^10^80. And, crucially, there will be no UTM2 in whose encoding scheme the criterion in question has a prefix-free description of much less than ~2^10^80, without that UTM2 itself having a description complexity of ~2^10^80 relative to UTM1—meaning, there is no physically realizable system that can implement UTM2.
I feel like this could branch out into a lot of small disagreements here but in the interest of keeping it streamlined:
One of the consequences of this, however, is that this prefix-based encoding method is only optimal for functions whose prefix-free encodings (i.e. encodings that cannot be partitioned into substrings such that one of the substrings encodes another UTM) in UTM1 and UTM2 differ in length by more than len(P). And, since len(P) is a measure of UTM2's complexity relative to UTM1, it follows directly that a UTM2 whose "coding scheme" is such that a function whose prefix-free encoding in UTM2 differs in length from its prefix-free encoding in UTM1 by some large constant (say, ~2^10^80), P itself must be on the order of 2^10^80—in other words, UTM2 must have an astronomical complexity relative to UTM1.
I agree with all of this, and wasn't gesturing at anything related to it, so I think we're talking past eachother. My point was simply that two UTMs even with not very-large prefix encodings can wind up with extremely different priors, but I don't think that's too relevant to what your main point is
For any physically realizable universal computational system, that system can be analogized to UTM1 in the above analysis. If you have some behavioral policy that is e.g. deontological in nature, that behavioral policy can in principle be recast as an optimization criterion over universe histories; however, this criterion will in all likelihood have a prefix-free description in UTM1 of length ~2^10^80. And, crucially, there will be no UTM2 in whose encoding scheme the criterion in question has a prefix-free description of much less than ~2^10^80, without that UTM2 itself having a description complexity of ~2^10^80 relative to UTM1—meaning, there is no physically realizable system that can implement UTM2.
I think I disagree with almost all of this. You can fix some gerrymandered extant physical system right now that ends up looking like a garbled world-history optimizer, I doubt that it would take on the order of length ~2^10^80 to specify it. But granting that these systems would in fact have astronomical prefixes, I think this is a ponens/tollens situation: if these systems actually have a huge prefix, that tells me that some the encoding schemes of some physically realisable systems are deeply incompatible with mine, not that those systems which are out there right now aren't physically realisible.
I imagine an objection is that these physical systems are not actually world-history optimizers and are actually going to be much more compressible than I'm making them out to be, so your argument goes through. In which case I'm fine with this, this just seems like a differing definition of what counts as when two schemes are acting "virtually identically" w.r.t to optimization criteria. If your argument is valid but is bounding this similarity to include e.g random chunks of a rock floating through space, then I'm happy to concede that - seems quite trivial and not at all worrying from the original perspective of bounding the kinds of optimization criteria an AI might have
"Utility maximisers are scary, and here are some theorems that show that anything sufficiently smart/rational (i.e. a superintelligence) will be a utility maximiser. That's scary"
I would say "systems that act according to preferences about the state of the world in the distant future are scary", and then that can hopefully lead to a productive and substantive discussion about whether people are likely to build such systems. (See e.g. here where I argue that someone is being too pessimistic about that, & section 1 here where I argue that someone else is being too optimistic.)
Thanks, I think that's a good distinction - I guess I have like 3 issues if we roll with that though
- I don't think a system acting according to preferences over future states entails it is EV-maximising w.r.t. some property/resource of those future states. If it's not doing the latter it seems like it's not necessarily scary, and if it is then I think we're back at the issue that we're making an unjustified leap, this time from "it's a utility maximizer + it has preferences over future-states" (i.e. having preferences over properties of future states is compatible w/ also having preferences over world-histories/all sorts of weird stuff)
- It's not clear to me that specifying "preferences over future states" actually restricts things much - if I have some preferences over the path I take through lotteries, then whether I take path A or path B to reach outcome X will show up as some difference in the final state, so it feels like we can cast a lot (Most? All?) types of preferences as "preferences over future states". I think the implicit response here is that we're categorizing future states by a subset of "interesting-to-us" properties, and the differences in future-states yielded by taking Path A or Path B don't matter to us (in other words, implicitly whenever we talk about these kinds of preferences over states we're taking some equivalence class over actual micro-states relative to some subset of properties). But then again I think the issue recurs that a system having preferences over future states w.r.t. this subset of properties is a stronger claim
- I'm more and more convinced that, even if a system does have preferences over future-states in the scariest sense here, there's not really an overriding normative force for it to update towards being a utility-maximiser. But I think this is maybe a kind of orthogonal issue about the force of exploitability arguments rather than coherence theorems here
I think you've said something along the lines of one or two of these points in your links, sorry! Not expecting this to be super novel to you, half just helpful for me to get my own thoughts down explicitly
It's not clear to me that specifying "preferences over future states" actually restricts things much - if I have some preferences over the path I take through lotteries, then whether I take path A or path B to reach outcome X will show up as some difference in the final state, so it feels like we can cast a lot (Most? All?) types of preferences as "preferences over future states".
In terms of the OP toy model, I think the OP omitted another condition under which the coherence theorem is trivial / doesn’t apply, which is that you always start the MDP in the same place and the MDP graph is a directed tree or directed forest. (i.e., there are no cycles even if you ignore the arrow-heads … I hope I’m getting the graph theory terminology right). In those cases, for any possible end-state, there’s at most one way to get from the start to the end-state; and conversely, for any possible path through the MDP, that’s the path that would result from wanting to get to that end-state. Therefore, you can rationalize any path through the MDP as the optimal way to get to whatever end-state it actually gets to. Right? (cc @johnswentworth @David Lorell )
OK, so what about the real world? The laws of physics are unitary, so it is technically true that if I have some non-distant-future-related preferences (e.g. “I prefer to never tell a lie”, “I prefer to never use my pinky finger”, etc.), this preference can be cast as some inscrutably complicated preference about the state of the world on January 1 2050, assuming omniscient knowledge of the state of the world right now and infinite computational power. For example, “a preference to never use my pinky finger starting right now” might be equivalent to something kinda like “On January 1 2050, IF {air molecule 9834705982347598 has speed between 34.2894583000000 and 34.2894583000001 AND air molecule 8934637823747621 has … [etc. for a googolplex more lines of text]”
This is kind of an irrelevant technicality, I think. The real world MDP in fact is full of (undirected) cycles—i.e. different ways to get to the same endpoint—…as far as anyone can measure it. For example, let’s say that I care about the state of a history ledger on January 1 2050. Then it’s possible for me to do whatever for 25 years … and then hack into the ledger and change it!
However, if the history ledger is completely unbreachable (haha), then I think we should say that this isn’t really a preference about the state of the world in the distant future, but rather an implementation method for making an agent with preferences about trajectories.
In terms of the OP toy model, I think the OP omitted another condition under which the coherence theorem is trivial / doesn’t apply, which is that you always start the MDP in the same place and the MDP graph is a directed tree or directed forest. (i.e., there are no cycles even if you ignore the arrow-heads … I’m hope I’m getting the graph theory terminology right). In those cases, for any possible end-state, there’s at most one way to get from the start to the end-state; and conversely, for any possible path through the MDP, that’s the path that would result from wanting to get to that end-state. Therefore, you can rationalize any path through the MDP as the optimal way to get to whatever end-state it actually gets to. Right?
Technically correct.
I'd emphasize here that this toy theorem is assuming an MDP, which specifically means that the "agent" must be able to observe the entire state at every timestep. If you start thinking about low-level physics and microscopic reversibility, then the entire state is definitely not observable by real agents. In order to properly handle that sort of thing, we'd mostly need to add uncertainty, i.e. shift to POMDPs.
different ways to get to the same endpoint—…as far as anyone can measure it
I would say the territory has no cycles but any map of it does. You can have a butterfly effect where a small nudge is amplified to some measurable difference but you cannot predict the result of that measurement. So the agent's revealed preferences can only be modeled as a graph where some states are reachable through multiple paths.
I actually disagree that there are no cycles/multiple paths to the same endpoint in the territory too.
In particular, I'm thinking of function extensionality, where multiple algorithms with wildly different run-times can compute the same function.
This is an easy source of examples where there are multiple starting points but there exists 1 end result (at least probabilistically).
I think it's both in the map, as a description, but I also think the behavior itself is in the territory, and my point is that you can get the same result but have different paths to get to the result, which is in the territory.
Also, I treat the map-territory difference in a weaker way than LW often assumes, where things in the map can also be in the territory, and vice versa.
In addition to what Steve Byrnes has said, you should also read the answers and associated commentary on my recent question about coherence theorems and agentic behavior.
Notice that we used values over final state, and explicitly set incremental reward at earlier timesteps to zero. That was load-bearing: with arbitrary freedom to choose rewards at earlier timesteps, any policy is optimal for some nontrivial values/rewards. (Proof: just pick the rewards at timestep to reward whatever the policy does enough to overwhelm future value/rewards.)
Do you expect that your methods would generalize over a utility function that was defined as the sum of some utility function over the state at some fixed intermediate timestamp and some utility function over the final state? Naively, I would think one could augment the state space such that the entire state at time became encoded in subsequent states, and the utility function in question could then be expressed soley as a utility function over the final state. But I don't know if that strategy is "allowed".
If this method is "allowed", I don't understand why this theorem doesn't extend to systems where incremental reward is nonzero at arbitrary timesteps.
If this method is not "allowed", does that mean that this particular coherence theorem only holds over policies which care only about the final state of the world, and agents which are coherent in this sense are not allowed to care about world histories and the world state is not allowed to contain information about its history?
You could extend it that way, and more generally you could extend it to sparse rewards. As the post says, coherence tells us about optimal policies away from the things which the goals care about directly. But in order for the theorem to say something substantive, there has to be lots of "empty space" where the incremental reward is zero. It's in the empty space where coherence has substantive things to say.
So if I understand correctly, optimal policies specifically have to be coherent in their decision-making when all information about which decision was made is destroyed, and only information about the outcome remains. The load-bearing part being:
Now, suppose that at timestep there are two different states either of which can reach either state or state in the next timestep. From one of those states the policy chooses ; from the other the policy chooses . This is an inconsistent revealed preference between and at time : sometimes the policy has a revealed preference for over , sometimes for over .
Concrete example:
Start with the state diagram
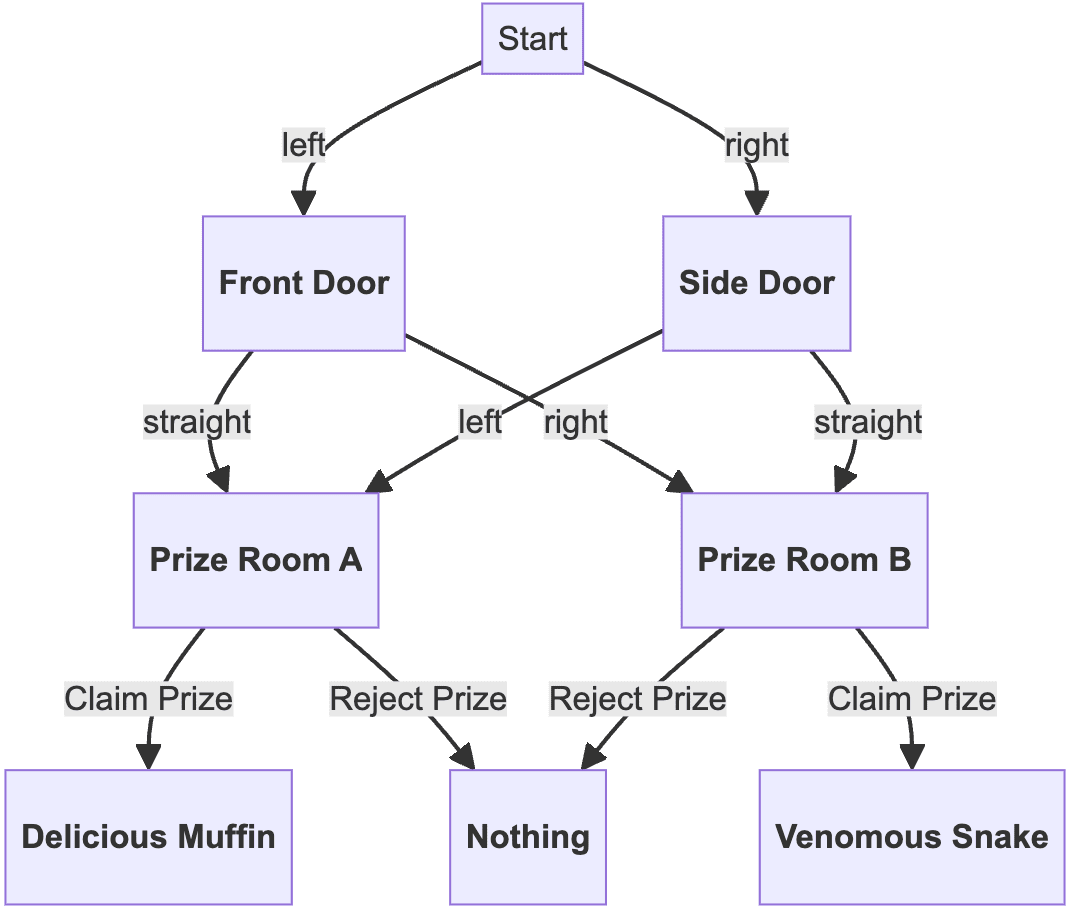
We assign values to the final states, and then do
start from those values over final state and compute the best value achievable starting from each state at each earlier time. That's just dynamic programming:
where are the values over final states.
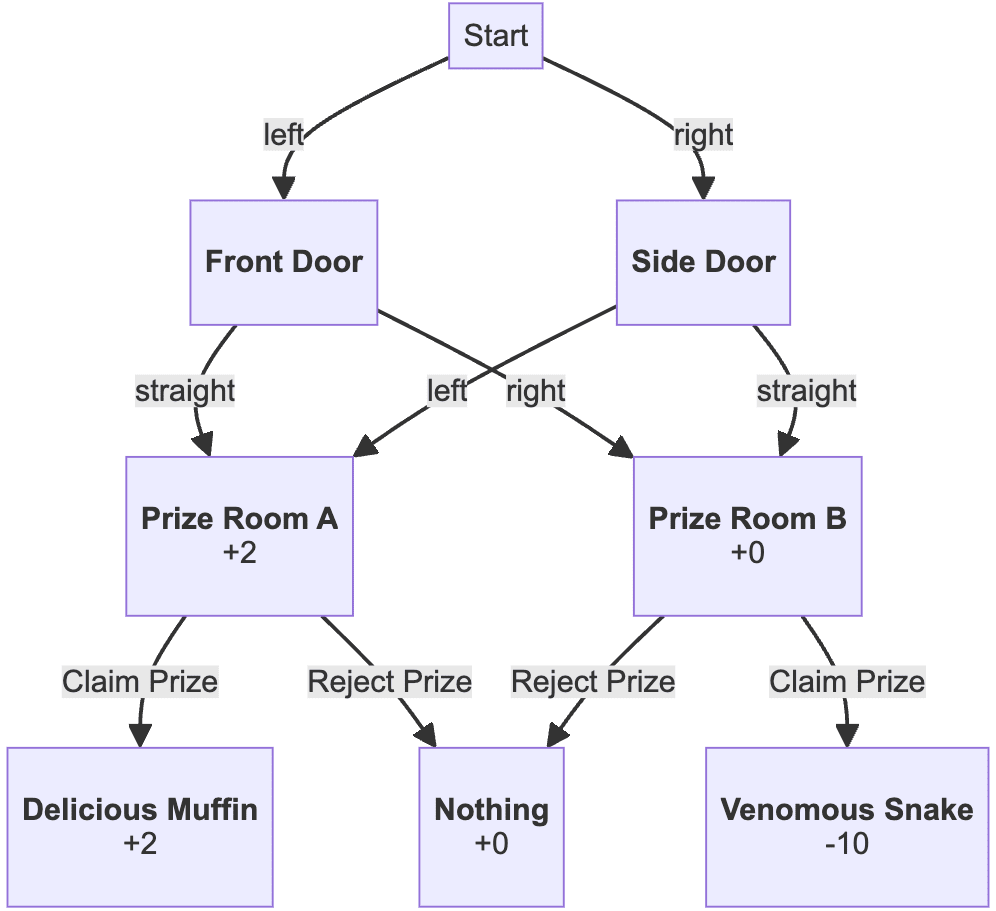
and so the reasoning is that there is no coherent policy which chooses Prize Room A from the front door but chooses Prize Room B from the side door.
But then if we update the states to include information about the history, and say put +3 on "histories where we have gone straight", we get
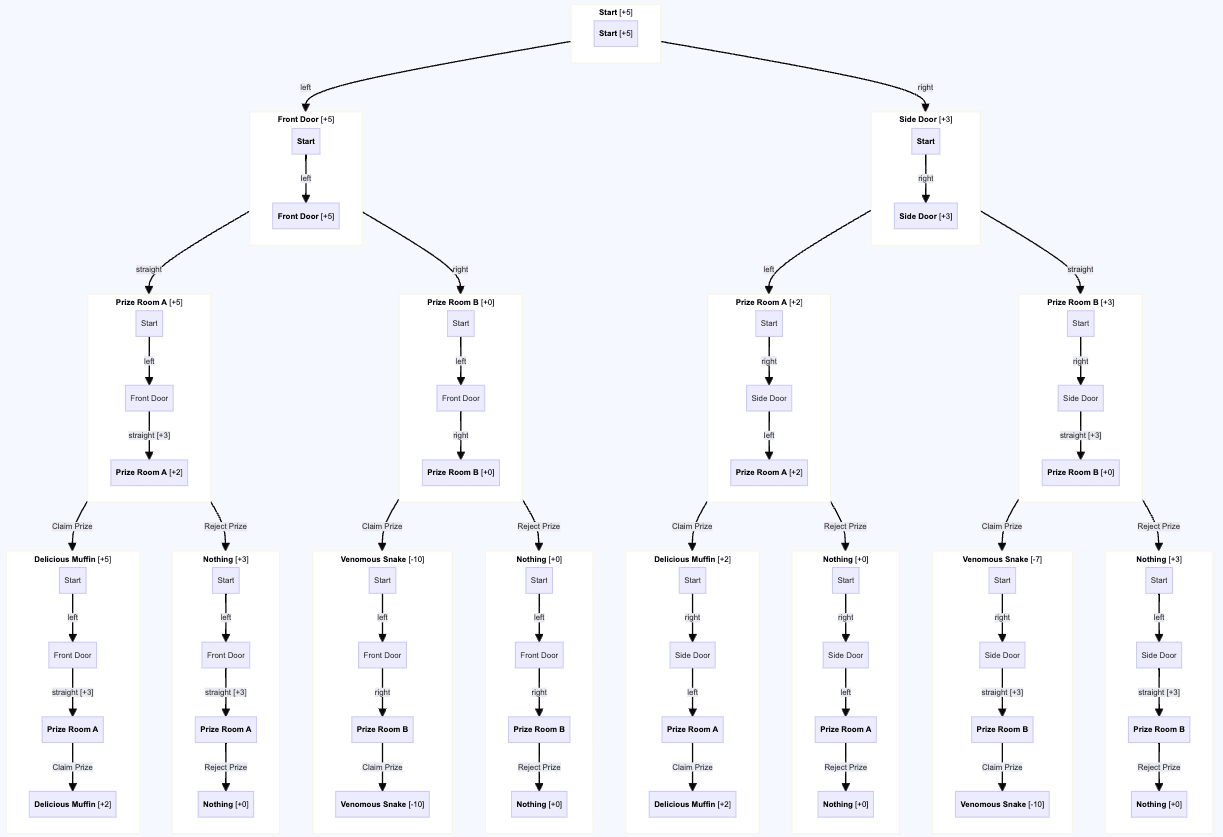
and in that case, the optimal policy will go to Prize Room A from the front door and Prize Room B from the side door. This happens because "Prize Room A from the front door" is not the same node as "Prize Room A from the side door" in this graph.
The coherence theorem in the post talks about how optimal models can't make take alternate options when presented with the same choice based on their history, but for the choice to be "the same choice" you have to have merging paths on the graph, and if nodes contain their own history, paths will never merge.
Is that basically why only the final state is allowed to "count" under this proof, or am I still missing something?
Edited to add: link to legible version of final diagram
A surprisingly large fraction of people I talk to try to convince me that some kind of irrationality is good actually, and my overly strong assumptions about rationality are causes me to expect AI doom. I fairly sure this is false and I'm making relatively weak assumptions about what it means to be rational. One assumption I am happy to make is that an agent will try to avoid shooting itself in the foot (by its own lights). What sort of actions count as "shooting itself in the foot" depends on what the goals are about, and what the environment is like, and often while explaining this I reference this post.
Having a simple example of an extremely obvious example of coherence is great.
I meant to write a longer review but have run out of time. I'll try to add it later.
This post presents a simple toy coherence theorem, and then uses it to address various common confusions about coherence arguments.
Setting
Deterministic MDP. That means at each time t there's a state S[t][1], the agent/policy takes an action A[t] (which can depend on both time t and current state S[t]), and then the next state S[t+1] is fully determined by S[t] and A[t]. The current state and current action are sufficient to tell us the next state.
We will think about values over the state at some final time T. Note that often in MDPs there is an incremental reward each timestep in addition to a final reward at the end; in our setting there is zero incremental reward at each timestep.
One key point about this setting: if the value over final state is uniform, i.e. same value for all final states, then the MDP is trivial. In that case, all policies are optimal, it does not matter at all what the final state is or what any state along the way is, everything is equally valuable.
Theorem
There exist policies which cannot be optimal for any values over final state except for the trivial case of uniform values. Furthermore, such policies are exactly those which display inconsistent revealed preferences transitively between all final states.
Proof
As a specific example: consider an MDP in which every state is reachable at every timestep, and a policy which always stays in the same state over time. From each state S every other state is reachable, yet the policy chooses S, so in order for the policy to be optimal S must be a highest-value final state. Since each state must be a highest-value state, the policy cannot be optimal for any values over final state except for the trivial case of uniform values. That establishes the existence part of the theorem, and you can probably get the whole idea by thinking about how to generalize that example. The rest of the proof extends the idea of that example to inconsistent revealed preferences in general.
Bulk of Proof (click to expand)
Assume the policy is optimal for some particular values over final state. We can then start from those values over final state and compute the best value achievable starting from each state at each earlier time. That's just dynamic programming:
V[S,t]=max S′ reachable in next timestep from S V[S′,t+1]
where V[S,T] are the values over final states.
A policy is optimal for final values V[S,T] if-and-only-if at each timestep t−1 it chooses a next state with highest reachable V[S,t].
Now, suppose that at timestep t there are two different states either of which can reach either state A or state B in the next timestep. From one of those states the policy chooses A; from the other the policy chooses B. This is an inconsistent revealed preference between A and B at time t: sometimes the policy has a revealed preference for A over B, sometimes for B over A.
In order for a policy with an inconsistent revealed preference between A and B at time t to be optimal, the values must satisfy
V[A,t]=V[B,t]
Why? Well, a policy is optimal for final values V[S,T] if-and-only if at each timestep t−1 it chooses a next state with highest reachable V[S,t]. So, if an optimal policy sometimes chooses A over B at timestep t when both are reachable, then we must have V[A,t]≥V[B,t]. And if an optimal policy sometimes chooses B over A at timestep t when both are reachable, then we must have V[A,t]≤V[B,t]. If both of those occur, i.e. the policy has an inconsistent revealed preference between A and B at time t, then V[A,t]=V[B,t].
Now, we can propagate that equality to a revealed preference on final states. We know that the final state which the policy in fact reaches starting from A at time t must have the highest reachable value, and that value is equal (by definition) to V[A,t]. Similarly for B. So, if we call the final state which the policy in fact reaches starting from state S at time t FINAL(S,t), our condition V[A,t]=V[B,t] becomes
V[FINAL(A,t),T]=V[FINAL(B,t),T]
When the policy ends in different final states starting from A versus B, this is an inconsistent revealed preference between final states FINAL(A,t) and FINAL(B,t): there are states at t−1 from which both states FINAL(A,t) and FINAL(B,t) are achievable (over multiple timesteps), and the policy sometimes chooses one and sometimes the other when both are achievable.
Let's pause a moment. We've now shown that there is a property of the policy - ie. inconsistent revealed preference between two final states FINAL(A,t) and FINAL(B,t) - such that a certain constraint V[FINAL(A,t),T]=V[FINAL(B,t),T] must be satisfied by any final values for which the policy is optimal.
Note that we can also chain together such constraints - e.g. if the policy's inconsistent revealed preferences between final states X and Y, and between final states Y and Z, imply both V[X,T]=V[Y,T] and V[Y,T]=V[Z,T], then we get the full chain V[X,T]=V[Y,T]=V[Z,T]. Thus we have a "transitively" inconsistent revealed preference between X and Z.
If the policy displays inconsistent revealed preferences transitively between all final states, that means the chain of equalities covers all final states, and therefore the values over final state must be uniform. That's the main claim of the theorem.
Lastly, to show that policies which are optimal only for uniform values are exactly those with inconsistent revealed preferences transitively between all final states, we need to show that there are some non-uniform values for which the policy is optimal if there aren't inconsistent revealed preferences transitively between all final states. This part is less interesting and kinda mathematically tedious IMO, so I'll be more terse and technical: the equality constraints yield equivalence classes between the final states. Between each equivalence class pair, there's either a revealed preference (if the policy ever chooses a state in one class over a state in the other), or no constraint (if there's never a starting point from which states in both classes are available and the policy chooses one of them). The revealed preferences between equivalence classes are acyclic, since any cycle would be another inconsistent preference. So, toposort the equivalence classes by revealed preference, take the value to be the toposort index, and we have a value function for which the policy is optimal.
Anti-Takeaways: Things Which Don't Generalize
Determinism
This theorem does not involve any uncertainty. That's the most important sense in which it is "toy". We can easily add a little uncertainty, in the form of nondeterministic state transitions, but that's a pretty narrow form of uncertainty. The more interesting and realistic possibility is uncertainty over current state, i.e. turning the MDP into a POMDP, and that completely destroys the proof; it no longer makes sense to use a value function over earlier states at all. Interesting new possibilities come up, like e.g. using the state to store information for the future[2]. Also ideally we'd like to derive the implied probability distribution along with the value function; that's a whole additional dimension to the problem under uncertainty. It's a pretty fun problem.
Takeaways: Things Which (I Expect) Do Generalize
Coherence Is Nontrivial For Optimization "At A Distance"
Notice that we used values over final state, and explicitly set incremental reward at earlier timesteps to zero. That was load-bearing: with arbitrary freedom to choose rewards at earlier timesteps, any policy is optimal for some nontrivial values/rewards. (Proof: just pick the rewards at timestep t to reward whatever the policy does enough to overwhelm future value/rewards.)
This ties to a common criticism: that any system can be well-modeled as a utility maximizer, by simply choosing the utility function which rewards whatever the system in fact does. As far as I can tell, that criticism usually reflects ignorance of what coherence says[3]. Coherence is not about whether a system "can be well-modeled as a utility maximizer" for some utility function over anything at all, it's about whether a system can be well-modeled as a utility maximizer for utility over some specific stuff.
The utility in the toy coherence theorem in this post is very explicitly over final states, and the theorem says nontrivial things mainly when the agent is making decisions at earlier times in order to influence that final state - i.e. the agent is optimizing the state "far away" (in time) from its current decision. That's the prototypical picture in my head when I think of coherence. Insofar as an incoherent system can be well-modeled as a utility maximizer, its optimization efforts must be dominated by relatively short-range, myopic objectives. Coherence arguments kick in when optimization for long-range objectives dominates.
(A visual anology: one can in-principle arrange positive and negative charges to form any electric field. So I can't look at an arbitrary field and say "ah, that does/doesn't look like an electric field". But in a vacuum, an electric field is much more restricted - I can look at an arbitrary field and say "ah, that does/doesn't look like an electric field in a vacuum". It's away from the charges that we can say nontrivial things about what the field looks like, without needing to know about the charges. Likewise for coherence: coherence is like vacuum equations for goals. It tells us what optimal policies look like away from the things which the goal cares about directly.)
We Didn't Need Trades, Adversaries, Money-Pumping, Etc
Another common criticism of coherence arguments which mostly reflects ignorance: in real life, nobody will actually try to money-pump me, and even if they did I'd notice and then change my revealed preferences.
The usual response to that critique is that coherence is not really about trades and adversaries and money-pumping; the world presents us with choices constantly, and coherence is a requirement for any "non-dominated" strategy. But that part usually isn't explained as well.
The toy theorem in this post sidesteps the entire issue, making it clear that coherence is indeed not really about trades and adversaries and money-pumping. We didn't even mention any of those things.
Approximation
Though the theorem in this post is worded in terms of exact optimality, it extends pretty easily to approximate optimality. Basically, rather than "inconsistent preference between A and B implies V[A,t]=V[B,t]", we say "inconsistent preference between A and B implies the difference between V[A,t] and V[B,t] is at most ϵ", and then the theorem talks about policies which achieve value within ϵ of optimal (or sum of ϵ at each timestep, or some such approximation error). So "coherence theorems only talk about optimal agents, and real-world agents aren't fully optimal" is yet another common criticism which mostly reflects ignorance.
Coherence Is About Revealed Preferences
Among actual academic decision theorists some popularity has accrued in recent years to frameworks for preferences which are not revealed preference. The theorem in this post illustrates that coherence is about revealed preferences.
Importantly, even when one is using some other model or notion of preferences, the system in question usually still has revealed preferences and coherence arguments will still apply to it. So if you're using some other notion of preferences, and want to see what coherence has to say about your agent, then you do need to look at its revealed preferences, and those may be different from whatever other kinds of "preferences" it has.
I'm using square brackets here to evoke the mental picture of an array, since when solving this problem via dynamic programming we'd typically keep all this data in arrays.
Note that the agent has no memory of its own other than the state. In order to derive a Bayesian agent we'd probably want to give it memory separate from the current state, i.e. allow the policy's choice at time t to depend on all previous states.
...though notably in Rohin's case, the "all behavior can be rationalized as EU maximization" critique did not reflect ignorance, but rather (according to him) he knew it was misleading-in-isolation but used it to make a different point which he didn't know a better way to make.