I have been posting a lot on instrumental geometric rationality, with Nash bargaining, Kelly betting, and Thompson sampling. I feel some duty to also post about epistemic geometric rationality, especially since information theory is filled with geometric maximization. The problem is that epistemic geometric rationality is kind of obvious.
A Silly Toy Model
Let's say you have some prior beliefs at time 0, and you have to choose some new beliefs for time 1. are both distributions over worlds. For now, let's say you don't make any observations. What should your new beliefs be?
The answer is obvious, you should set . However, if we want to phrase this as a geometric maximization, we can say
.
This is saying, imagine the true world is sampled according to , and geometrically maximize the probability you assign to the true world. I feel silly recommending this because it is much more complicated that . However, it gives us a new lens that we can use to generalize and consider alternatives.
For example, we can consider the corresponding arithmetic maximization,
.
What would happen if we were to do this? We would find the world with the highest probability, and put all our probability mass on that world. We would anticipate that world, and ignore all the others.
This is a stupid way to manage our anticipation. Nobody is going around saying we should arithmetically maximize the probability we assign to the true world. (However, people are going around saying we should arithmetically maximize average utility, or arithmetically maximize our wealth.)
Not only does arithmetic maximization put all our anticipatory eggs in one basket, it also opens us up to all sorts of internal politics. If we take a world and add some extra features to it to split it up into multiple different worlds, this changes the evaluation of which world is most efficient to believe in. This is illustrating two of the biggest virtues of geometric rationality: proportional representation, and gerrymander resistance.
A Slightly Less Silly Toy Model
Now, lets assume we make some observation , so we know that the real world is in . We will restrict our attention to probability distributions that assign probability 1 to . However, if we try to set
,
we run into a problem. We are geometrically maximizing the same quantity as before, subject to the constraint that , but the problem is that the geometric expectation is 0 no matter what we do, because for any .
However, this is easy to fix. Instead of requiring that , we can require that , and take a limit as approaches 1 from below. Thus, we get
.
Turns out this limit exists, and corresponds exactly to Bayesian updating on the event . Again, this is more complicated that just defining Bayesian updating like a normal person, so I am being a little obnoxious by treating this as an application of geometric rationality.
However, I think you can see the connection to geometric rationality in Bayesian updating directly. When I assign probability 1 to an event that I used to assign probability , I have all this extra probability mass in worlds. How should I distribute this probability mass across the worlds? Bayesian updating recommends that I geometrically scale all the probabilities up by the same amount. Why are we scaling probabilities up rather than e.g. arithmetically increasing all the probabilities by the same amount?
Because we actually care about our probabilities in a geometric (multiplicative) way!
It is much worse to decrease your probability of the true world from .11 to .01 than it is to decrease your probability of the true world from .9 to .8. This is because the former is geometrically a much larger decrease.
Generalized Updates
This model stops being silly when we start using it for something new, where the geometric maximization actually helps. For that, we can consider updating on some more strange stuff. Imagine you want to update on the fact that X and Y are independent. How do you observe this? Well maybe you looked into the mechanism of how the world is generated, and see that there is no communication between the thing that generates X and the thing that generates Y. Or maybe you don't actually observe the fact, but you want to make your probability distribution simpler and easier to compress by separating out the X and Y parts. Or maybe represents your choice, and represents your parents, and you want to implement a causal counterfactual via conditioning. Anyway, we have a proposal for updating on this.
.
In general, we can enforce any restrictions we want on our new probability distribution, and geometric maximization gives us a sane way to update.
Aggregating Beliefs
Now let's say I have a bunch of hypotheses about the world. is my set of hypotheses, and each hypothesis is a distribution on worlds, . I also have a distribution , representing my credence on each of these hypotheses. How should interpret myself as having beliefs about the world, rather than just beliefs about hypotheses?
Well, my beliefs about the world are just . Again, I could have done this in a simpler way, not phrased as geometric maximization. However, I would not be able to do the next step.
Now, let's consider the following modification: Each hypothesis is no longer a distribution on , but instead a distribution on some coarser partition of . Now is still well defined, and other simpler methods of defining aggregation are not. (The argmax might not be a single distribution, but it will be a linear space of distributions, and it will give a unique probability to every event in any of the sigma algebras of the hypotheses.)
I have a lot to say about this method of aggregating beliefs. I have spent a lot of time thinking about it over the last year, and think it is quite good. It can be used to track the difference between credence (probability) and confidence (the strength of your belief), and thinking a lot about it has also caused some minor shifts in the way I think about agency. I hope to write about it a bunch soon, but that will be in a different post/sequence.
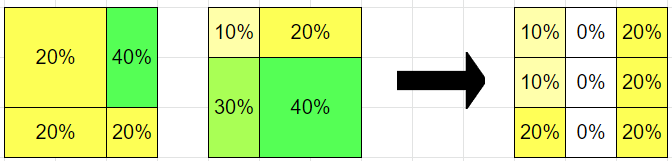
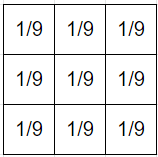
You draw a part, which is a subset of W, and thus has a probability according to Q.