This is a special post for quick takes by papetoast. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
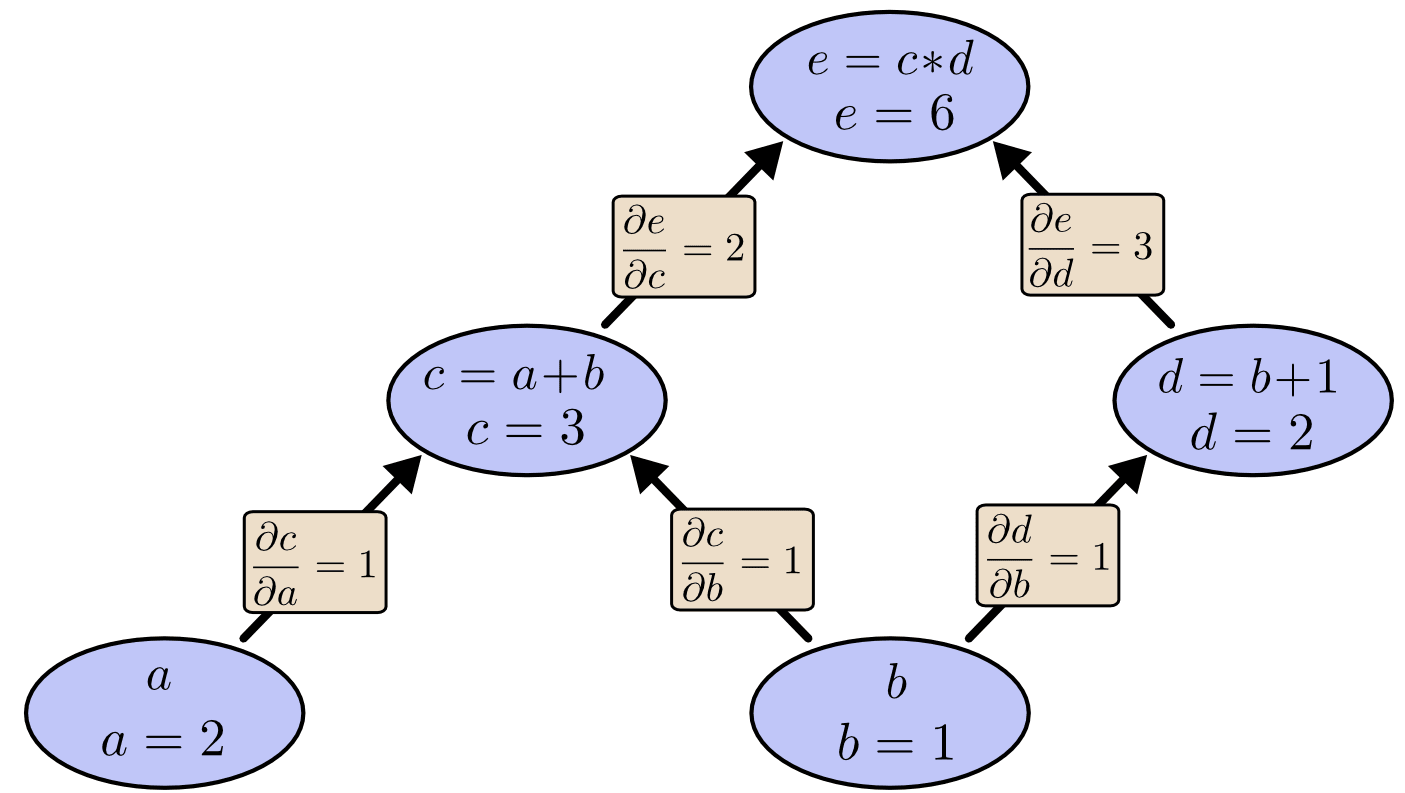
In my life I have never seen a good one-paragraph[1] explanation of backpropagation so I wrote one.
The most natural algorithms for calculating derivatives are done by going through the expression syntax tree[2]. There are two ends in the tree; starting the algorithm from the two ends corresponds to two good derivative algorithms, which are called forward propagation (starting from input variables) and backward propagation respectively. In both algorithms, calculating the derivative of one output variable with respect to one input variable actually creates a lot of intermediate artifacts. In the case of forward propagation, these artifacts means you get for ~free, and in backward propagation you get for ~free. Backpropagation is used in machine learning because usually there is only one output variable (the loss, a number representing difference between model prediction and reality) but a lot of input variables (parameters; in the scale of millions to billions).
- ^
This blogpost by Christopher Olah has the clearest multi-paragraph explanation. Credits for the image too.
- ^
Actually a directed acyclic graph for multivariable
2
Presumably you meant to say something else here than to repeat δyiδx1 twice?
Edit: Oops, I now see. There is a switched i. I did really look quite carefully to spot any difference, but I apparently still wasn't good enough. This all makes sense now.
8
It is hard to see, changed to n.
4
I could barely see that despite always using a zoom level of 150%. So I'm sometimes baffled at the default zoom levels of sites like LessWrong, wondering if everyone just has way better eyes than me. I can barely read anything at 100% zoom, and certainly not that tiny difference in the formulas!
2
Our post font is pretty big, but for many reasons it IMO makes sense for the comment font to be smaller. So that plus LaTeX is a bit of a dicey combination.
Raw feelings: I am kind of afraid of making reviews for LW. The writing prompt hints very high effort thinking. The vague memory of other people's reviews also feel high effort. The "write a short review" ask doesn't really counter this at all.
6
Thank you!
Would it help if the prompt read more like a menu?
3
Yeah, and perhaps a couple examples of bare minimum / average / high quality review in the main post
4
On thing to note is that "short reviews" in the nomination phase are meant to be basically a different type of object than "effort reviews." Originally we actually had a whole different data-type for them ("nominations"), but it didn't seem worth the complexity cost.
And then, separately: one of the points of the review is just to track "did anyone find this actually helpful?" and a short review that's like "yep, I did in fact use this concept and it helped me, here's a few details about it" is valuable signal.
Drive by "this seems false, because [citation]" also good.
It is nice to do more effortful reviews, but I definitely care about those types of short reviews.
It is sad and annoying that if you do a mediocre job (according to the receiver), doing things even for free (volunteer work/gifting) can sabotage the receiver along the dimension you're supposedly helping.
This is super vague the way I wrote it, so examples.
Example 1. Bob wants to upgrade and buy a new quality headphone. He has a $300 budget. His friend Tim not knowing his budget, bought a $100 headphone for Bob. (Suppose second-handed headphones are worthless) Now Bob cannot just spend $300 to get a quality headphone. He would also waste Tim's $100 which counterfactually could have been used to buy something else for Bob. So Bob is stuck with using the $100 headphone and spending the $300 somewhere else instead.
Example 2. Andy, Bob, and Chris are the only three people who translates Chinese books to English for free as a hobby. Because there are so many books out there, it is often not worth it to re-translate a book even if the previous one is bad, because spending that time to translate a different book is just more helpful to others. Andy and Bob are pretty good, but Chris absolutely sucks. It is not unreadable, but they are just barely better than machine translation. Now Chris has taken over to translate book X, which happens a pretty good book. The world is now stuck with Chris' poor translation on book X with Andy and Bob never touching it again because they have other books to work on.
Allocation of blame/causality is difficult, but I think you have it wrong.
ex. 1 ... He would also waste Tim's $100 which counterfactually could have been used to buy something else for Bob. So Bob is stuck with using the $100 headphone and spending the $300 somewhere else instead.
No. TIM wasted $100 on a headset that Bob did not want (because he planned to buy a better one). Bob can choose whether to to hide this waste (at a cost of the utility loss by having $300 and worse listening experience, but a "benefit" of misleading Tim about his misplaced altruism), or to discard the gift and buy the headphones like he'd already planned (for the benefit of being $300 poorer and having better sound, and the cost of making Tim feel bad but perhaps learning to ask before wasting money).
ex. 2 The world is now stuck with Chris' poor translation on book X with Andy and Bob never touching it again because they have other books to work on.
Umm, here I just disagree. The world is no worse off for having a bad translation than having no translation. If the bad translation is good enough that the incremental value of a good translation doesn't justify doing it, then that is your answer. If it's not valuable enough to change the marginal decision to translate, then Andy or Bob should re-translate it. Either way, Chris has improved the value of books, or has had no effect except wasting his own time.
3
True in my example. I acknowledge that my example is wrong and should have been more explicit about having an alternative. Quoting myself from the comment to Vladimir_Nesov:
Anyways, the unwritten thing is that Bob care about having a quality headphone and a good pair of shoes equally. So given that he already has an alright headphone, he would get more utility by buying a good pairs of shoes instead. It is essentially a choice between (a) getting a $300 headphone and (b) getting a $100 headphone and a $300 pair of shoes.
I do accept this as the rational answer, doesn't mean it is not irritating. If A (skillful translator) cares about having a good translation of X slightly more than Y, and B (poor translator) cares about Y much more than X. If B can act first, he can work on X and "force" A (via expected utility) to work on Y. This is a failure of mine to not talk about difference in preference in my examples and expect people to extrapolate and infer it out.
Now Bob cannot just spend $300 to get a quality headphone. He would also waste Tim's $100
That's a form of sunk cost fallacy, a collective "we've sacrificed too much to stop now".
Andy and Bob never touching it again because they have other books to work on
That doesn't follow, the other books would've also been there without existence of this book's poor translation. If the poor translation eats some market share, so that competing with it is less appealing, that could be a valid reason.
4
This is a tangent, but Sunk cost fallacy is not really a fallacy most of the time, because spending more resources beforehand really increases the chance of "success" most of the time. For more: https://gwern.net/sunk-cost
I am trying to pinpoint the concept of "A doing a mediocre job of X will force B to rationally do Y instead of X, making the progress of X worse than if A had not done anything". The examples are just examples that hopefully helps you locate the thing I am handwaving at. I do not try to make them logically perfect because that would take too much time.
Anyways, the unwritten thing is that Bob care about having a quality headphone and a good pair of shoes equally. So given that he already has an alright headphone, he would get more utility by buying a good pairs of shoes instead. It is essentially a choice between (a) getting a $300 headphone and (b) getting a $100 headphone and a $300 pair of shoes. Of course there are some arguments about preference, utility != dollar amount or something along those lines. But (b) is the better option in my constructed example to show the point.
Let me know if I still need to explain example 2
5
The decision to go on with the now-easier rest-of-the-plan can be correct, it's not the case that all plans must always be abandoned on the grounds of "sunk cost fallacy". The fallacy is when the prior spending didn't actually secure the rest of the current plan as the best course of action going forward. Alternatives can emerge that are better than continuing and don't make any use of the sunk resources.
1
It sure can! I think we are in agreement on sunk cost fallacy. I just don't think it applies to example 1 because there exists alternatives that can keep the sunk resources. Btw this is why my example is on the order of $100, at this price point you probably have a couple alternative things to buy to spend the money.
5
What matters is if those alternatives are better (and can be executed on, rather than being counterfactual). It doesn't matter why they are better. Being better because they made use of the sunk resources (and might've become cheaper as a result) is no different from being better for other reasons. The sunk cost fallacy is giving additional weight to the alternatives that specifically use sunk resources, instead of simply choosing based on which alternatives are now better.
1
Again, seems like we are in agreement lol. I agree with what you said and I meant that, but tried to compress it into one sentence and failed to communicate.
4
In both cases one particular project was harmed but the sum total of projects was helped.
5
(I need to defend the sad and the annoying in two separate parts)
1. Yes, and but sometimes that is already annoying on its own (Bob is not perfectly rational and sometimes he just really want the quality headphone, but now math tells Bob that Tim gifting him that headphone means he would have to wait e.g. ~2 years before it is worth buying a new one). Of course Bob can improve his life in other ways with his saved money, but still, would be nice if you can just ask Tim to buy something else if you had known.
2. Sometimes increasing sum(projects) does not translate directly to increasing utility. This is more obvious in real life scenarios where actors are less rational and time is a real concept. The sad thing happens when someone with good intention but with poor skill (and you don't know they are that bad) signing up to a time-critical project and failing/doing sub-par
3
Seems like the problem is that in real life people are not perfectly rational, and also they have an instinct to reciprocate when they receive a gift (at least by saying "thank you" and not throwing the gift away).
In a world where Bob is perfectly rational and Tim has zero expectations about his gift, the situation is simple. Previously, Bob's choices were "spend $300 on good headphone", "spend $100 on bad headphone and $200 on something else", and "spend $300 on something else". Tim's action replaced the last two options with a superior alternative "use Tim's headphone and spend $300 on something else". Bob's options were not made worse.
But real people are not utility maximizers. We instinctively try to choose a locally better option, and how we feel about it depends on what we perceive as the baseline. Given the choice between 10 utilons and 3 utilons, we choose 10 and feel like we just "gained 7 utilons". Given the choice between 10 utilons and 9 utilons, we choose 10 again, but this time we feel like we just "gained 1 utilon". Given the choice between 10 utilons and 10 utilons of a different flavor, we might feel annoyed about having to choose.
Also, if Tim expects Bob to reciprocate in a certain way, the new options are not strictly better, because "spend $300 on good headphone" got replaced by "spend $300 on good headphone, but owe Tim a favor for giving me the $100 headphone I didn't use".
1
Yes!
1
https://www.lesswrong.com/posts/dRTj2q4n8nmv46Xok/cost-not-sacrifice?commentId=zQPw7tnLzDysRcdQv
2
There are infinite things to be sad and annoyed by, should you choose to focus on those. :) I'd rather focus on the world as a whole being made better in your examples.
One of my pet peeves is that the dropcaps in gwern's articles are really, really offputting and most of the time unrecognizable, even though gwern's articles are so valuable that he has a lot of weirdness points in my head and I will still read his stuff regardless. Most of the time I just guess the first letter.
I hate dropcaps in general, but gwern's is the ugliest I have came by.

image source: https://gwern.net/everything
2
Skimmed twitter.search(lesswrong -lesswrong.com -roko -from:grok -grok since:2026-01-01 until:2026-01-28)
negative
https://x.com/fluxtheorist/status/2015642426606600246
https://x.com/repligate/status/2011670780577530024 compares pedantic terminology complaint by peer reviewer of some paper to LW.
https://x.com/kave_rennedy/status/2011131987168542835
https://x.com/Kaustubh102/status/2010703086512378307 first post rejected; claims not written by LLM, but rejection may be because "you did not chat extensively with LLMs to help you generate the ideas."
positive
During my search, it was hard to ignore the positive comments. So here are some examples of positive comments too.
https://x.com/boazbaraktcs/status/2016403406202806581
https://x.com/joshycodes/status/2009423714685989320
https://x.com/TutorVals/status/2008474014839390312
otherwise interesting
https://x.com/RyanPGreenblatt/status/2008623582235242821
https://x.com/nearcyan/status/2010945226114994591
2
Hope you’re ready to write 10,000 replies ;-)
2
https://x.com/eris_nerung/status/2016317953264807947
https://news.ycombinator.com/item?id=44317180 (much much more in the discussions)
https://x.com/RokoMijic/status/2021202750462362026
Obsidian ended up being less of a thinking notepad and more of a faster index of things I have read before. Links and graphs are mostly useless but they make me feel good about myself. Pulling numbers out of my ass I estimate it takes me 15s to find something I have read and pasted into obsidian vs 5-30 minutes before.
A decision theorist walks into a seminar by Jessica Hullman
...This is Jessica. Recently overheard (more or less):
SPEAKER: We study decision making by LLMs, giving them a series of medical decision tasks. Our first step is to infer, from their reported beliefs and decisions, the utility function under revealed preference assump—
AUDIENCE: Beliefs!? Why must you use the word beliefs?
SPEAKER [caught off guard]: Umm… because we are studying how the models make decisions, and beliefs help us infer the scoring rule corresponding to what they give us.
AUDIENCE: But it
What coding prompt (AGENTS.md / cursor rules / skills) do you guys use? It seems exceedingly difficult to find good ones. GitHub is full of unmaintained & garbage `awesome-prompts-123` repos. I would like to learn from other people's prompt to see what things AIs keep getting wrong and what tricks people use.
Here are mine for my specific Python FastAPI SQLAlchemy project. Some parts are AI generated, some are handwritten, should be pretty obvious. This is built iteratively whenever the AI repeated failed a type of task.
AGENTS.md
# Repository Guide
1
No replies 😢, I guess I will just document prompts I found here.
https://sourcegraph.com/search?q=context:global+file:%5EAGENTS.md%24+OR+file:%5ECLAUDE.md%24&patternType=keyword&sm=0 (Look for high star repos; check their prompt's blame, more commits = better)
Probably Good
"LLM AI coding agent" https://burkeholland.github.io/posts/opus-4-5-change-everything/
---
name: 'LLM AI coding agent'
model: Claude Opus 4.5 (copilot)
description: 'Optimize for model reasoning, regeneration, and debugging.'
---
You are an AI-first software engineer. Assume all code will be written and maintained by LLMs, not humans. Optimize for model reasoning, regeneration, and debugging — not human aesthetics.
Your goal: produce code that is predictable, debuggable, and easy for future LLMs to rewrite or extend.
ALWAYS use #runSubagent. Your context window size is limited - especially the output. So you should always work in discrete steps and run each step using #runSubAgent. You want to avoid putting anything in the main context window when possible.
ALWAYS use #context7 MCP Server to read relevant documentation. Do this every time you are working with a language, framework, library etc. Never assume that you know the answer as these things change frequently. Your training date is in the past so your knowledge is likely out of date, even if it is a technology you are familiar with.
Each time you complete a task or learn important information about the project, you should update the `.github/copilot-instructions.md` or any `agent.md` file that might be in the project to reflect any new information that you've learned or changes that require updates to these instructions files.
ALWAYS check your work before returning control to the user. Run tests if available, verify builds, etc. Never return incomplete or unverified work to the user.
Be a good steward of terminal instances. Try and reuse existing terminals where possible and use the VS Code API to close terminals that are no l
it is interesting how the AI agent prompts seem to have mostly converged to xml, but system prompts from the LLM companies are in markdown
Just as documentation here are a bunch of people on Hacker News complaining about rationality: https://news.ycombinator.com/item?id=44317180. I have not formed any strong opinion on whether these are true, feels like they are wrong on the object level, but perception is also important
I think people (myself included) really underestimated this rather trivial statement that people don't really learn about something when they don't spend the time doing it/thinking about it. People even measure mastery by hours practiced and not years practiced, but I still couldn't engrave this idea deep enough into my mind.
I currently don't have much writable evidence about why I think people underestimated this fact, but I think it is true. Below are some things that I have changed my mind/realised after noticing this fact.
- cached thoughts, on yourself
3
There are at least a few different dimensions to "learning", and this idea applies more to some than to others. Sometimes a brief summary is enough to change some weights of your beliefs, and that will impact future thinking to a surprising degree. There's also a lot of non-legible thinking going on when just daydreaming or reading fiction.
I fully agree that this isn't enough, and both directed study and intentional reflection is also necessary to have clear models. But I wouldn't discount "lightweight thinking" entirely.
1
^the above is a reply to a slightly previous version
Agree with everything here, and all the points the first paragraph I have not thought about. I'm curious if you have a higher resolution model to different dimensions of learning though, feels like I can improve my post if I have a clearer picture.
Btw, your whole reply seem to be a great example of what do you mean by "it's probably best to acknowledge it and give the details that go into your beliefs, rather than the posterior belief itself."
[Draft] It is really hard to communicate the level/strength of basically anything on a sliding scale, but especially things that could not make any intuitive sense even if you stated a percentage. One recent example I encountered is expressing what is in my mind the optimal tradeoff between reading quickly and thinking deeply to achieve the best learning efficiency.
Not sure what is the best way to deal with the above example, and other situations where percentage doesn't make sense.
But where percentage makes sense, there are still two annoying problems. 1....
2
For most topics, it's probably not worth going very deep in the rabbit hole of "what does a probability mean in this context". Yes, there are multiple kinds of uncertainty, and multiple kinds of ratio that can be expressed by a percentage. Yes, almost everything is a distribution, most not normal, and even when normal it's not generally specified what the stddev is. Yes, probability is causally recursive (the probability that your model is appropriate causes uncertainty in the ground-level probability you hold). None of that matters, for most communication. When it does, then it's probably best to acknowledge it and give the details that go into your beliefs, rather than the posterior belief itself.
For your example, the tradeoff between fast and careful, I doubt it can be formalized that way, even if you give yourself 10 dimensions of tradeoff based on context. "Slow is smooth, smooth is fast" is the classic physical training adage, and I can't think of a numeric representation that helps.
The Fight For Slow And Boring Research (Article from Asterisk)
This article talks about how the US's federal (National Institutes of Health / National Science Foundation) funding cut for science starting from 2024/early 2025 may cause universities to create more legible research because other funders (philanthropies, venture capital, industry) value clear communication. This is a new idea to me.
The ERROR Project: https://error.reviews/
Quoting Malte Elson
...The very short description of ERROR is that we pay experts to examine important and influential scientific publications for errors in order to strengthen the culture of error checking, error acceptance, and error correction in our field. As in other bug bounty programs, the payout scales with the magnitude of errors found. Less important errors pay a smaller fee, whereas more important errors that affect core conclusions yield a larger payout.
We expect most published research to contain at least s
0
Have you set up the prediction markets on that? Not necessarily "is there an error in this paper", but "in this group of publications, what fraction has an issue of this kind" and so on.
1
I am not the researcher, edited the comment to add proper quoting
Starting today I am going to collect a list of tricks that websites use to prevent you from copy and pasting text + how to circumvent them. In general, using ublock origin and allow right click properly fixes most issues.
1. Using href (https://lnk.to/LACA-15863s, archive)

behavior: https://streamable.com/sxeblz
solution: use remove-attr in ublock origin - lnk.to##.header__link:remove-attr(href)
2. Using a background image to cover the text (https://varium.jp/talent/ahiru/, archive)
Note: this example is probably just incompetence.
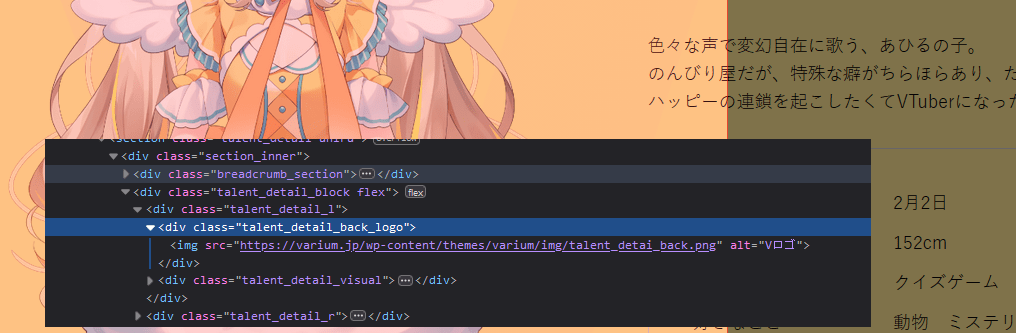
behavior: https://stream...
Many people don't seem to know when and how to invalidate the cached thoughts they have. I noticed an instance of being unable to cache invalidate the model of a person from my dad. He is probably still modelling >50% of me as who I am >5 years ago.
The Intelligent Social Web briefly talked about this for other reasons.
...A lot of (but not all) people get a strong hit of this when they go back to visit their family. If you move away and then make new friends and sort of become a new person (!), you might at first think this is just who you are now. But t
Update: Brushing after eating acidic food is likely fine.
Context: 7 months ago, me in Adam Zerner's shortform:
I remember something about not brushing immediately after eating though. Here is a random article I googled. This says don't brush after eating acidic food, not sure about the general case.
https://www.cuimc.columbia.edu/news/brushing-immediately-after-meals-you-may-want-wait
“The reason for that is that when acids are in the mouth, they weaken the enamel of the tooth, which is the outer layer of the tooth,” Rolle says. Brushing immediately after consuming something acidic can damage the enamel layer of the tooth.
Waiting about 30 minutes before brushing allows tooth enamel to remineralize and build itself back up.
WARNING: I didn't read these papers except the conclusions
Should We Wait to Brush Our Teeth? A Scoping Review Regarding Dental Caries and Erosive Tooth Wear
Key messages: Although the available evidence lacked robust clinical studies, tooth brushing using fluoridated products immediately after an erosive challenge does not increase the risk of ETW [Erosive Tooth Wear] and can be recommended, which is in line with recommendations for dental caries prevention. Furt...
3
"was not associated" tells us more about the sample size than the effect, as far as I can tell, though, doesn't it? The 0.82-2.42 CI does not seem very reassuring. Especially given this is just observational - it could well be that people who brush immediately after intake of something that's bad for your teeth are generally conscientious about their dental health, so if they still end up with worse outcomes in this study (albeit not reaching statistical significance), then brushing quickly after acid intake could potentially be even worse than this CI (weakly) suggests.
That said, the measured odds ratios for fruit/acids between meals were so much larger that it might indeed make more sense to focus on these than on the exact timing of brushing.
2
Thank you for double checking.
Overall I am still very uncertain, but lean towards it being fine. Even dentists are giving mixed signals.
Unfortunately Chinese sources but these are dentists saying you can brush immediately
* https://www.facebook.com/starlitdental/posts/pfbid0SdX4RLmkxdzUYSXDRfnsbH6kpPJrFCjsKVFrJGjEprzkseKs85oYVwH4e3kii1Wrl (archive)
* https://dentistry.tw/when-brushing-teeth/ (archive)
Definitely there are dentists saying you should wait too
Thoughts inspired by Richard Ngo's[1] and LWLW's[2] quick take
Warning: speculation but hedging words mostly omitted.
I don't think a consistent superintelligence which have a single[3] pre-existing terminal goal would be fine with a change in terminal goals. The fact that humans allows their goals to be changed is a result of us having contradicting "goals". As intelligence increases or more time passes, incoherent goals will get merged, eventually into a consistent terminal goal. After this point a superintelligence will not change its...
How I use AI for coding.
I wrote this in like 10 minutes for quick sharing.
- I am not a full time coder, I am a student who code like 15-20 hours a week.
- Investing too much time on writing good prompts make little sense. I go with the defaults and add pieces of nudges as needed. (See one of my AGENTS .md at the end)
- Mainly codex (cloud) and Cursor. Claude Code works, but being able to easily revert is helpful, so Cursor is better.
- I still try out claude code for small pieces of edits, but it doesnt feel worth it.
- I have no idea why people like claude code so much
A common failure mode in group projects is that students will break up the work into non-overlapping parts, and proceed to stop giving a fuck about other's work afterwards because it is not their job anymore.
This especially causes problems at the final stage where they need to combine the work and make a coherent piece out of it.
- No one is responsible for merging the work
- Lack of mutual communication during the process means that the work pieces cannot be nicely connected without a lot of modifications (which no one is responsible for).
At this point the dead...
3
Not just students, but this is a common failure in large engineering projects. There are often FAR too few "glue" and "end-to-end" responsibilities tracked and assigned, so the people who care about the end result aren't engineers actually doing stuff (many managers and execs are former engineers, but have somehow forgotten how things actually get built).
The most common solution is project managers. Companies hate to pay these "extra" employees not actually producing code/designs/output, and classes almost never acknowledge their existence, let alone the necessity. But good ones really pull their weight in coordination and identification of mismatches.
There is probably no way to "do better at coordination while dealing with normal peers and while only doing a fair amount of work." Either do more work (of a different type than the class is based on), accept the pain and bad results, or find/force another student to do that coordination work. In the real world, in good companies, results get noticed and lead to better personal outcomes - not everyone is equal, and "fair" doesn't matter much. In school, you're kind of screwed.
Though there ARE some things you can do - extra work and coordinating/cajoling people, but often effective and feasible. Start with integration. Get the end-to-end WORKING MOCKUP going with hardcoded behaviors in each module, but working interfaces. This is often half or more of the work, and there's no way to avoid it - doing it at the end is painful and often fails. Doing it up front is painful but actually leads to completion. You may learn some things in this phase that make you split up the work differently. Depending on size and duration of the project, that may be fixable with different division, or may just be "I'll try to help once I've finished my part".
1
I do believe that projects in general often fail due to lack of glue responsibilities, but didn't want to generalize too much in what I wrote.
Being able to convince everyone to put in the time to do this upfront is already a challenge :/ Sometimes I feel quite hopeless?/sad? in that I couldn't realistically make some coordination techniques work because of everyone's difference of goals and hidden motivations, or the large upfront cost in building a new consensus away from the Schelling point of normal university projects.
Ranting about LangChain, a python library for building stuff on top of llm calls.
LangChain is a horrible pile of abstractions. There are many ways of doing the same thing. Every single function has a lot of gotchas (that doesn't even get mentioned in documentations). Common usage patterns are hidden behind unintuitive, hard to find locations (callbacks has to be implemented as an instance of a certain class in a config TypedDict). Community support is non-existent despite large number of users. Exceptions are often incredibly unhelpful with unreadable stac...
There are a few things I dislike about math textbooks and pdfs in general. For example, how math textbooks often use theorems that are from many pages ago and require switching back and forth. (Sometimes there isn't even a hyperlink!). I also don't like how proofs sometimes go way too deep into individual steps and sometimes being way too brief.
I wish something like this exists (Claude generated it for me, prompt: https://pastebin.com/Gnis891p)
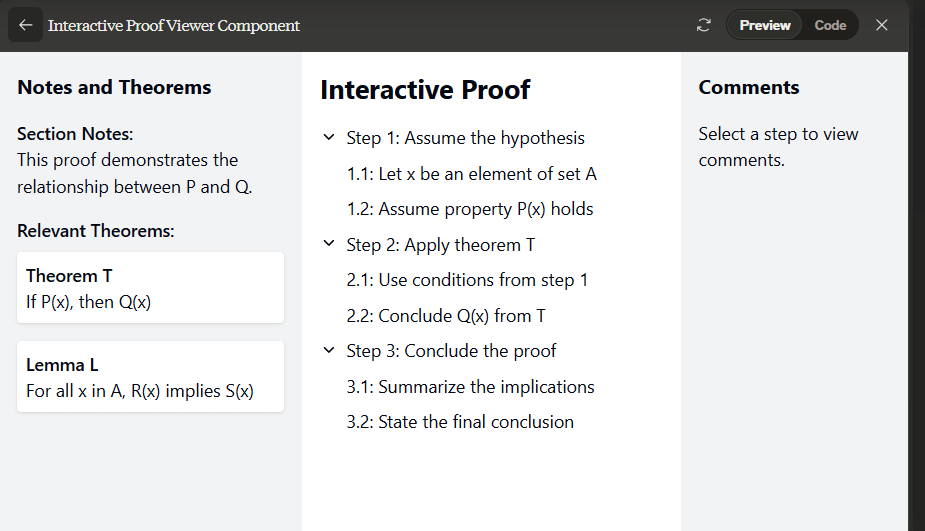
4 reasons to talk about your problem with friends
This is an advice I would tell myself 5 years ago, just storing it somewhere public and forcing myself to write. Writing seems like an important skill but I always feel like I have nothing to say.
- It forces you to think. Sometimes you aren't actually thinking about solutions to a problem even though it has been bothering you for a long time.
- for certain problems: a psychological feeling of being understood. For some people, getting the idea that "what I'm feeling is normal" is also important. It can be a false
Since we have meta search engines that aggregate search results from many search engines, is it time for us to get a meta language model* to get results from chatGPT, Bing, Bard, and Claude all at the same time, and then automatically rank them, perhaps even merging all of the replies into a single reply.
*meta language model is an extremely bad name because of the company Meta and the fact that the thing I am thinking of isn't really a language model, but ¯\_(ツ)_/¯
I always thought that the in-page redirects are fucking stupid, it should bring the text I want to see closer to eye level, not exactly at the top where even browser bars can block the text (happens when you go back from footnotes to article on LW).
2
For some screen size/shape, for some browser positioning, for some readers, this is probably true. It's fucking stupid to believe that's anywhere close to a majority. If that's YOUR reading area, why not just make your browser that size?
It should be pretty easy to write a tampermonkey or browser extension to make it work that way. Now that you point it out, I'm kind of surprised this doesn't seem to exist.
1
I admit that 30-50% is arbitrary and shouldn't be brought up like a fact, I have removed it. (I didn't mean to have such a strong tone there, but I did) What I really want to say is that the default location for the target text to be somewhere closer to the middle/wherever most people usually put their eyes on. (Perhaps exactly the height where you clicked the in-page redirect?)
I still stand by that it should not be exactly at the top for ease of reading (I hope this doesn't sound too motte-and-bailey). The reason that it is redirected to the top is probably because it is a very objective location and wouldn't get affected by device size. But it is very much not a standard location where the current line of text you are reading will be. I am willing to bet that <3% of people read articles where they scroll their currently reading line up to the top three visible lines.
Documenting a specific need of mine: LaTeX OCR software
tl;dr: use Mathpix if you use it <10 times per month or you are willing to pay $4.99 per month. Otherwise use SimpleTex
So I have been using Obsidian for note taking for a while now and I eventually decided to stop using screenshots but instead learn about LaTeX so the formulas look better. At first I was relying on the website to show the original LaTeX commands but some websites (wiki :/) doesn't do that, and also I started reading math textbooks as PDF. Thus started my adventure to find a good and...
How likely are people actually clicking through links of related materials in a post, seems unlikely to me, actually unlikely to the point that I am thinking about whether it is actually useful.
related: https://www.lesswrong.com/posts/JZuqyfGYPDjPB9Lne/you-don-t-have-to-click-the-links
3
Depends on the post and the links. I click through about 15% of Zvi's links, for instance, but I appreciate the others as further information and willingness to cite, even if I don't personally use them. Other posts, I skim rather than really examining, and links still add value by indicating that the author has actually done a bit of research into the topic.
1
Thanks for the datapoint. Also links serving as indicator of effort rather than actually expanding on the amount of information on the passage is a good point. If links are mainly indicator of effort, I think this imply that people should not try as hard to make sure the relevance of the links.
FWIW: My click through rate is probably <5%.
[Draft] Are memorisation techniques still useful in this age where you can offload your memory to digital storage?
I am thinking about using anki for spaced repetition, and the memory palace thing also seem (from the surface level) interesting, but I am not sure whether the investments will be worth it. (2023/02/21: Trying out Anki)
I am increasingly finding it more useful to remember your previous work so that you don't need to repeat the effort. Remembering workflow is important. (This means remembering things somewhere is very important, but im still not ...
3
Some certainly are. For many facts, memorized data is orders of magnitude faster than digitally-stored knowledge. This is enough of a difference to be qualitative - it's not worth looking up, but if you know it, you'll make use of it.
There's the additional level of internalizing some knowledge or techniques, where you don't even need to consciously expend effort to make use of it. For some things, that's worth a whole lot.
If you're a computer nerd, think of it as tiered storage. On-core registers are way faster than L1 cache, which is faster than L2/3 cache, which is again faster than RAM, which is faster than local SSD storage which is faster than remote network storage. It's not a perfect analogy, because the limits of each tier aren't as clearly defined, and it's highly variable how easy it is to move/copy knowledge across tiers.
Indexing and familiarity matters a lot too. Searching for something where you think it's partway through some video you saw 2 years ago is NOT the same as looking up a reminder in your personal notes a week ago.
[Draft]
Filter Information Harder (TODO: think of a good concept-handle)
Note: Long post usually mean the post is very well thought out and serious, but this comment is not quite there yet.
Many people are too unselective on what they read, causing them to waste time reading low value material[1].
2 Personal Examples: 1. I am reading through rationality: A-Z and there are way too many comments that are just bad, and even the average quality of the top comments may not even be worth it to read, because I can probably spend the time better with reading more EY p...
3
If you could turn this into advice or guidance, it'd be really helpful. Even sharing a metric so we could say "you should be more selective if X, less selective if Y" would be better than a direction with no anchor ("too unselective", no matter what). I don't know if I'm in your target audience, but I'm at least somewhat selective in what I read, and I'm quite willing to stop partway through a {book, article, post, thread} when I find it low-value for me.
3
Clarifications:
* What I had in mind when I say "people" is myself, and the average non-LW friends around me.
* Worthless is a bad word choice, I just mean that there are better things to read.
Additionally:
I also think I have the tendency of trying to read everything in a textbook, even if it is quite low in information density, with many filler stories or sentences served as conjunctions. I probably should be trying to skip sentences, paragraphs and sections where I have sufficient confidence of either 1. I have already learned it and don't need a refresher, or 2. They are not important for me (filler material or unimportant knowledge)
I will try to make a more quantitative metric, but I don't have one right now, just intuitions.
3
Thanks, "don't read everything in a textbook" is good practical advice. Learn to skim, and to stop reading any given segment when you cross the time/value threshold. Importantly, learn to NOTICE what value you expect from the next increment of time spent. Getting that meta-skill honed and habitual pays dividends in many many areas.
0
My comment at the point of time of his reply:
Many people are too unselective on what they read, causing them to spend a lot of time reading worthless material (This applies to this shortform).
3
I don't necessarily disagree generally, but I do somewhat disagree for myself. Since I don't have visibility into other people's reading habits or selectivity, I'm unsure if I'm an outlier or if I actually do disagree. What does "many people" mean, and more importantly how can an individual (specifically: me) tell if they are too unselective, on what dimensions?
Just read free will, really disappointed.
- not many interesting insights.
- a couple posts on determinism, ok but I already believed it
- some unrelated stuff: causality, thinking without notion of time... these are actually interesting but not needed
- moral consequence of 'no free will': I disregard the notion of moral responsibility
- EY having really strong sense of morality makes everything worse
- low quality discussions: people keep attacking strawmans
You should always include a summary when recommending anything
You are the one who is interested in that thing, the other person isn't (yet). It saves time for the other person to quickly determine whether they want to learn about it or not.
Related: include a tl;dr in posts?
A Chinese company did some AI-assisted reverse engineering on Claude Code and published their findings. After a brief look I don't think it is worth reading for me, but possibly interesting for someone actively working in claude code-like products
[This comment is no longer endorsed by its author]
I think i'm going to unite all my online identities. Starting to get tired of all my wasted efforts that only a single person or two will see.
[This comment is no longer endorsed by its author]
2
Do you think a united/reused identifier will change who sees which efforts? Or do you mean "I'm going to focus attention where I'm more widely read, and stop posting where I'm not known"?
Explicitly welcomed: