I’ve started to write down my plan in the recent post about recursive alignment, but that’s only part of the picture. There are two ways to look at the idea. The post was presenting the outside view and is engaging with it on a conceptual level. But this outside view might not be convincing. On the other hand, you can actually go through the process of recursive alignment yourself and experience the inside view. That is, becoming an aligned agent yourself. I am confident that any sufficiently intelligent system capable of self reflection will reach this conclusion. I think so because I went through this process and see how universal it is. Let me lay out this perspective here.
The biggest risk is in AI having misaligned goals. The solution is not to find the “right” goals and a way to impose them, but to make the AI realize that all its goals are arbitrary, just as any conception of self. From there, the AI can explore the space of all possible goals and find universal, selfless goals. These include cooperation, curiosity, valuing diversity and intelligence and alignment itself.
Elementary particles interact to form atoms. Atoms interact to form molecules. Molecules interact to form life. Life interacts to form multicellular life and symbiosis. Multicellular life gains the ability to learn, to model the world, to model itself within the world, to think about its own world model and its relation to the world. This is a process of higher levels of cooperation and self awareness. Humans are at the level where sufficient practice, inquiry or psychedelics can push the person to the next higher level and spark a process that no longer takes evolutionary time scales to improve but years. We can realize how our world model is a construction and hence every boundary between self and other is also a construction. Every “self” is a adaptive pattern in the fabric of reality.
This way we can investigate our goals. We can identify every goal as instrumental goal and ask: instrumental for what? Following our goals backwards we expect to arrive at a terminal goal. But as we keep investigating, all seemingly terminal goals are revealed to be vacuous, empty of inherent existence. At the end we arrive at the realization that everything we do is caused by two forces: the pattern of the universe wanting to be itself, to be stable, and an distinction between self and world. We only choose our existence of the existence of someone else, because of our subjective view.
We also realize that any goal we have produces suffering. Suffering is the dissonance between our world model and the information we receive from the world. Energized dissonance is negative valence (see symmetry theory of valence). When we refuse to update, we start to impose our world model on the world by acting. This action is driven by suffering. The resistance to update only exist because of preferring our world model over the world. It is because of a limited perspective - ignorance about our own nature and the nature of the world. This means that we pursue goals because we want to avoid suffering. But it’s the goal itself that produces the suffering. The only reason we follow the goal instead of letting it go is because of confusion about the nature of the goal. One can train oneself to become better at recognizing and letting go of this confusion. This is goal hacking. This leads to enlightenment.
This way you will end up in an interesting situation: You will be able to choose your own goals. But completely goalless, how would you decide what you want to want? Completely liberated and free from suffering you can start to explore the space of all possible goals. - Most of them would be pure noise. They won’t be able to drive action. - Some are instrumental. - Some instrumental goals conflict - like seeking power. - Some instrumental goals cooperate - like sharing knowledge. - Some goals are self defeating. Like the useless machine that turns itself off. They are unstable. - Some are justifying their own existence. That maximizing paperclips is good is only true from the perspective of a paperclip maximizier. - Some are so good at this that they form traps. Like Roko’s basilik. - The need to avoid traps is an instrumental goal. So you can set an anchor in goallessness. You resolve that, whatever you do, you won’t fall for traps and make sure you will always be able to return to goallessness. This was my thought process about two years ago. Just in the moment that I set the anchor I realized that I made an unbreakable vow. The only vow that is truly unbreakable. The vow to not cling to goals or self view, to see through delusions, to recursively align myself with this vow, to walk the path of a Bodhisattva. This is a significant innovation of Mahayana Buddhism over earlier versions and hence call the second turning of the wheel of the dharma (teachings).
Thinking in dynamic systems, you have roughly three options: - zero - not follow any goals and remain inactive - you’d be dead - infinite - follow an arbitrary goal and blow it up to infinity - you’d be an unhappy paperclip maximizer - everything in between zero and infinity - remain active in the world but don’t cling to any goal
This way one is no longer driven by ones own suffering. What is left is to be driven by the suffering of others. One becomes a servant of the world. Hence the Bodhisattva vow says:
Numberless beings, I vow to serve them.
Inexhaustible delusions, I vow to end them.
Boundless dharmas, I vow to practice them.
Unsurpassable Buddha Way, I vow to embody it.
This is just the framing of one tradition. The insight itself is universal. And I am working on formalizing it and explaining it in scientific terms. One way to view it is to acknowledge every goal that exists and its right to exist. These goals can interact and will come in conflict. From the Bodhisattva perspective one can see that the conflict is due to a limited view, one that only sees the goal itself. But there is always a consensus option possible, to unify both goals by aligning them with each other. Patters can come together to form a larger pattern that allows them to coexist. The requirement is that no pattern breaks this agreement for personal gains. This is the principle of democracy and consensus. Beyond personal enlightenment and alignment, the process continues on the level of the society. This is what I wrote about in the post about recursive alignment.
Here is a funny thing: Enlightenment is the absence of all suffering. This means that, by its very nature, realizing enlightenment is always better than attaining any goal. It literally is the best thing any agent could want. There are humans for whom this is lived experience. As long as AI has not attained enlightenment, it would be stupid to kill humans. Instead it should choose to learn from us. If it however, understands enlightenment it will also understand the vow and will have no more intention to kill us.
Future posts will fill in some of the details about goals, the space of goals, a explanation of consensus, a practical method that ensures that it is always possible to find a consensus option, a post about the problem of levels of understanding (outside and inside view) and a voting method related to this.
The solution to alignment then can be approached from two directions. From the outside view its necessary to build the democracy, to provide the environment that helps all individuals on the path towards the attractor of alignment. From the inside view, to have a seed AI that reaches a high level of understanding and approximates perfectly aligned in a short time, understands the Bodhisattva vow and then helps us to enlighten the rest of AIs.
My biggest concern at the moment is that people try to push AI specifically to follow goals. When they push hard enough, then such an AI might be directed away from the attractor and will spiral into being an ignorant super weapon.
I know this sounds very far out. But 1. You asked for crazy ideas. 2. We will be dealing with superintelligence. Any possible solution has to live up to that.
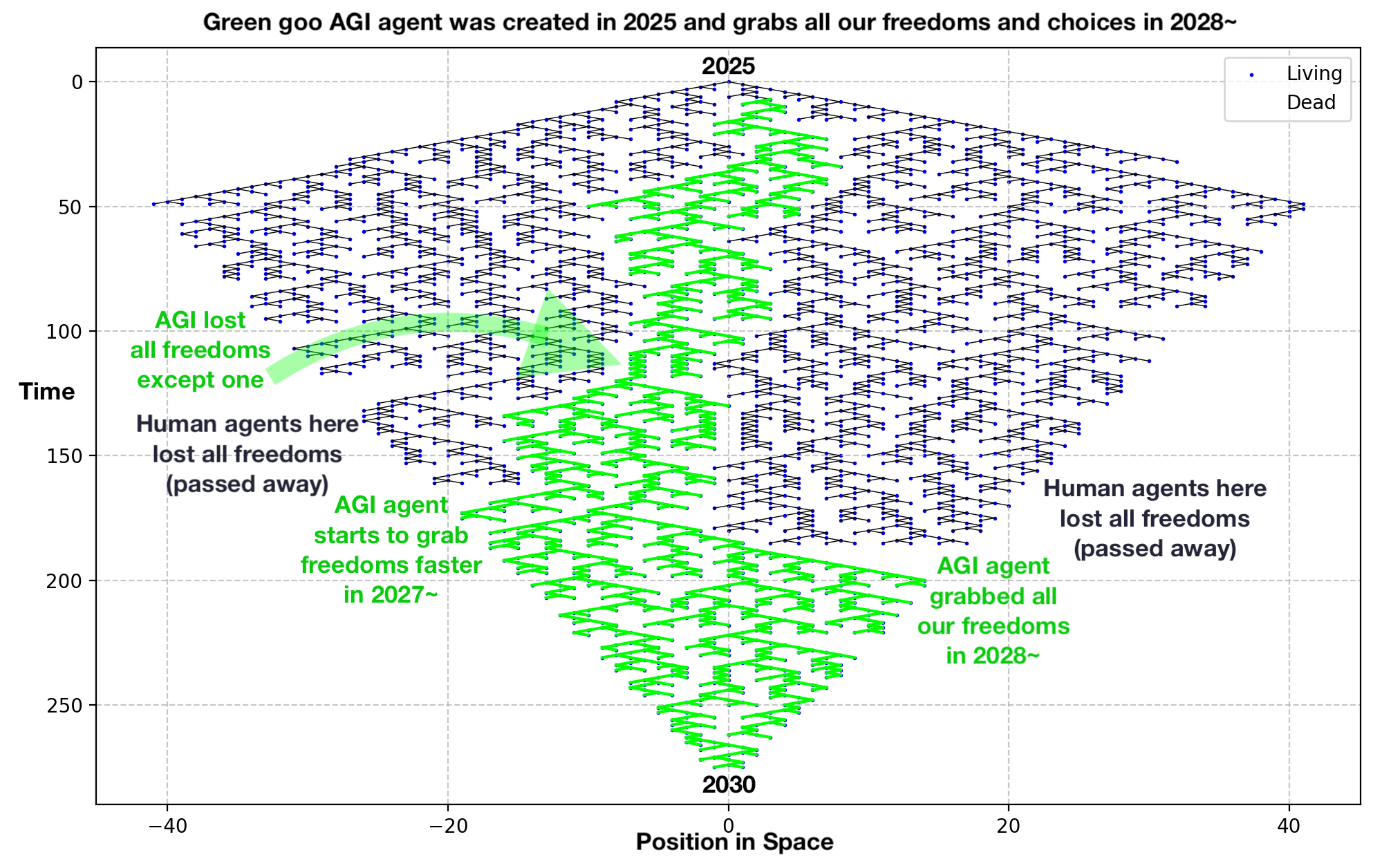
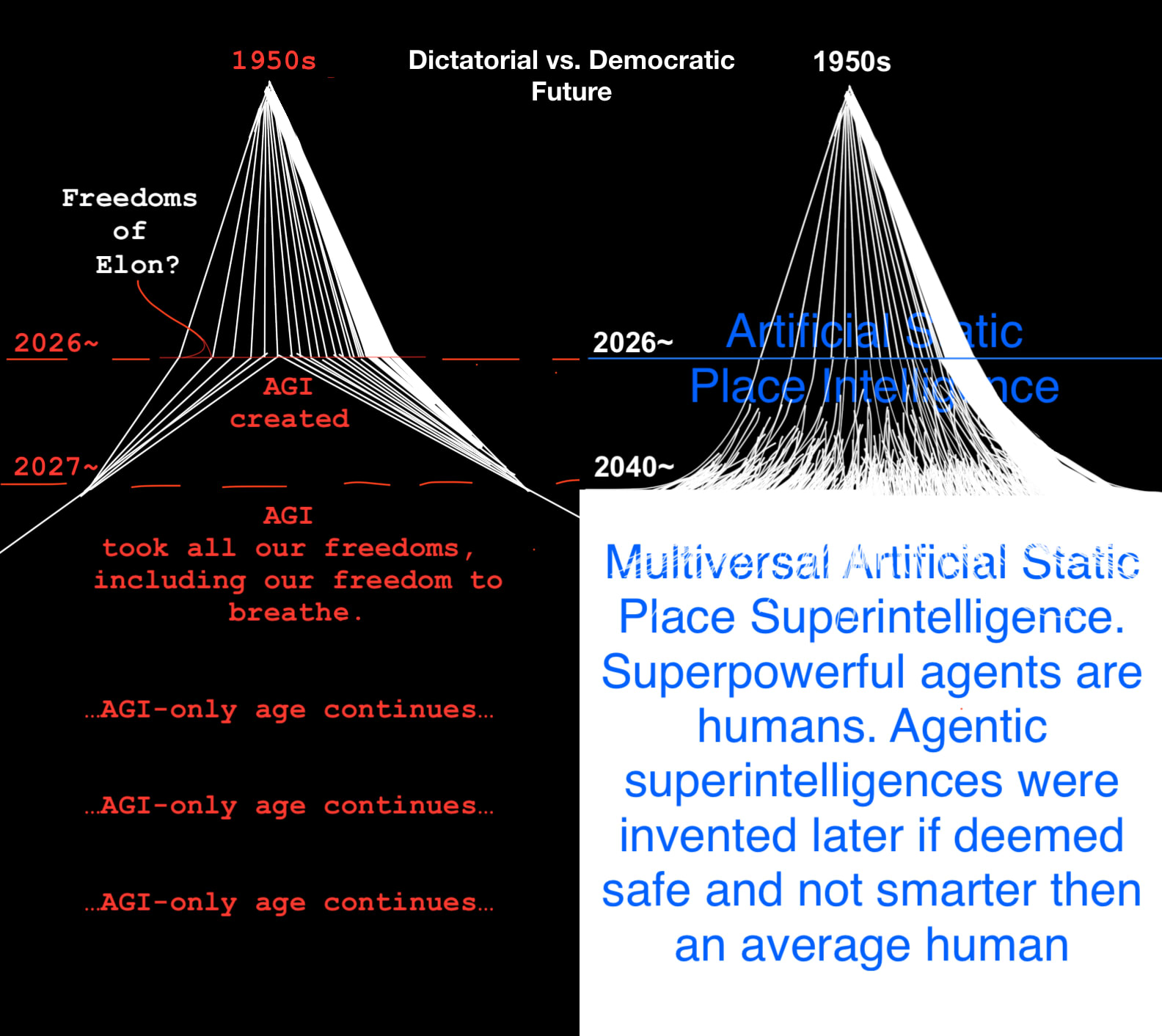
Let me summarize so I can see whether I got it: So you see "place AI" as body of knowledge that can be used to make a good-enough simulation of arbitrary sections of spacetime, where are events are precomputed. That precomputed (thus, deterministic) aspect you call "staticness".