This is a special post for quick takes by paulfchristiano. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
One way of viewing takeoff speed disagreements within the safety community is: most people agree that growth will eventually be explosively fast, and so the question is "how big an impact does AI have prior to explosive growth?" We could quantify this by looking at the economic impact of AI systems prior to the point when AI is powerful enough to double output each year.
(We could also quantify it via growth dynamics, but I want to try to get some kind of evidence further in advance which requires looking at AI in particular---on both views, AI only has a large impact on total output fairly close to the singularity.)
The "slow takeoff" view is that general AI systems will grow to tens of trillions of dollars a year of revenue in the years prior to explosive growth, and so by the time they have automated the entire economy it will look like a natural extension of the prior trend.
(Cost might be a more robust measure than revenue, especially if AI output is primarily reinvested by large tech companies, and especially on a slow takeoff view with a relatively competitive market for compute driven primarily by investors. Revenue itself is very sensitive to unimportant accounting questions, like what transactions occur within a firm vs between firms.)
The fast takeoff view is that the pre-takeoff impact of general AI will be... smaller. I don't know exactly how small, but let's say somewhere between $10 million and $10 trillion, spanning 6 orders of magnitude. (This reflects a low end that's like "ten people in a basement" and a high end that's just a bit shy of the slow takeoff view.)
It seems like growth in AI has already been large enough to provide big updates in this discussion. I'd guess total revenue from general and giant deep learning systems[1] will probably be around $1B in 2023 (and perhaps much higher if there is a lot of stuff I don't know about). It also looks on track to grow to $10 billion over the next 2-3 years if not faster. It seems easy to see how the current technology could do $10-100 billion per year of revenue with zero regulatory changes or further technology progress.
If the "fast takeoff" prediction about pre-takeoff AGI impact was uniformly distributed between $10 million and $10 trillion, that would mean we've already run through 1/3 of the probability mass and so should have made a factor of 3/2 update for slow takeoff. By the time we get to $100 billion/year of impact we will have run through 2/3 of the probability mass.
My sense is that fast takeoff proponents are not owning the predictions of their view and now acknowledging this fact as evidence. Eliezer in particular has frustrated me on this point. These observations are consistent with fast takeoff (which as far as I can tell practically just says "anything goes" until right at the end), but that they are basically implied by the slow takeoff model.
(One might object to this perspective by saying that there is no analogous form of evidence that could ever support fast takeoff. But I think that's just how it is---if Alice thinks that the world will end at t=1 and Bob thinks the world will end at a uniformly random time between t=0 and t=1, then Bob's view will just inevitably become less likely as time passes without the world ending.)
- ^
It's unclear if you should treat "general and giant deep learning systems" as the relevant category, though I think it's probably right if you want to evaluate the views of actual slow takeoff proponents in the safety community. And more broadly, within that community I expect a lot of agreement that these systems are general intelligences that are the most relevant comparison point for transformative AI.
[For reference, my view is “probably fast takeoff, defined by <2 years between widespread common knowledge of basically how AGI algorithms can work, and the singularity.” (Is that “fast”? I dunno the definitions.) ]
My view is that LLMs are not part of the relevant category of proto-AGI; I think proto-AGI doesn’t exist yet. So from my perspective,
- you’re asking for a prediction about how much economic impact comes from a certain category of non-proto-AGI software,
- you’re noting that the fast takeoff hypothesis doesn’t constrain this prediction at all,
- and therefore you’re assigning the fast takeoff hypothesis a log-uniform prior as its prediction.
I don’t think this is a valid procedure.
ANALOGY:
The Law of Conservation of Energy doesn’t offer any prediction about the half-life of tritium. It would be wrong to say that it offers an implicit prediction about the half-life of tritium, namely, log-uniform from 1 femtosecond to the lifetime of the universe, or whatever. It just plain doesn’t have any prediction at all!
Really, you have to distinguish two things:
- “The Law of Conservation of Energy”
- “My whole worldview, within which The Law of Conservation of Energy is just one piece.”
If you ask me to predict the total energy of the tritium decay products, I would make a prediction using Conservation of Energy. If you ask me to predict the half-life of tritium, I would make a prediction using other unrelated things that I believe about nuclear physics.
And that’s fine!
And in particular, the failure of Conservation of Energy here is not a failure at all; indeed it’s not any evidence that I’m wrong to believe Conservation of Energy. Right?
BACK TO AI:
Again, you’re asking for a prediction about how much economic impact comes from a certain category of (IMO)-non-AGI AI software. And I’m saying “my belief in fast takeoff doesn’t constrain my answer to that question—just like my belief in plate tectonics doesn’t constrain my answer to that question”. I don’t think any less of the fast takeoff hypothesis on account of that fact, any more than I think less of plate tectonics.
So instead, I would come up with a prediction in a different way. What do these systems do now, what do I expect them to do in the future, how big are relevant markets, etc.?
I don’t know what my final answers would be, but I feel like you’re not allowed to put words in my mouth and say that my prediction is “log-uniform from $10M to $10T”. That’s not my prediction!
Sorry if I’m misunderstanding.
I don’t think any less of the fast takeoff hypothesis on account of that fact, any more than I think less of plate tectonics.
But if non-AGI systems in fact transform the world before AGI is built, then I don't think I should care nearly as much about your concept of "AGI." That would just be a slow takeoff, and would probably mean that AGI isn't the relevant thing for our work on mitigating AI risk.
So you can have whatever views you want about AGI if you say they don't make a prediction about takeoff speed. But once you are making a claim about takeoff speed, you are also making a prediction that non-AGI systems aren't going to transform the world prior to AGI.
I don’t know what my final answers would be, but I feel like you’re not allowed to put words in my mouth and say that my prediction is “log-uniform from $10M to $10T”. That’s not my prediction!
It seems to me like your view about takeoff is only valid if non-AGI systems won't be that impactful prior to AGI, and in particular will have <$10 trillion of impact or something like that (otherwise AGI is not really related to takeoff speed). So somehow you believe that. And therefore some kind of impact is going to be evidence against that part of your view. It might be that the entire update occurs as non-AGIs move from $1 trillion to $10 trillion of impact, because that's the step where you concentrated the improbability.
In some sense if you don't say any prediction then I'm "not allowed" to update about your view based on evidence, because I don't know which update is correct. But in fact I'm mostly just trying to understand what is true, and I'm trying to use other people's statements as a source of hypotheses and intuitions and models of the world, and regardless of whether those people state any predictions formally I'm going to be constantly updating about what fits the evidence.
The most realistic view I see that implies fast takeoff without making predictions about existing systems is:
- You have very short AGI timelines based on your reasoning about AGI.
- Non-AGI impact simply can't grow quickly enough to be large prior to AGI.
For example, if you think the median time to brain-like AGI is <10 years, then I think that most of our disagreement will be about that.
Thanks!
But if non-AGI systems in fact transform the world before AGI is built, then I don't think I should care nearly as much about your concept of "AGI."
Fair enough! I do in fact expect that AI will not be transformative-in-the-OpenPhil-sense (i.e. as much or more than the agricultural or industrial revolution) unless that AI is importantly different from today’s LLMs (e.g. advanced model-based RL). But I don’t think we’ve gotten much evidence on this hypothesis either way so far, right?
For example: I think if you walk up to some normal person and say “We already today have direct (albeit weak) evidence that LLMs will evolve into something that transforms the world much much more than electrification + airplanes + integrated circuits + the internet combined”, I think they would say “WTF?? That is a totally wild claim, and we do NOT already have direct evidence for it”. Right?
If you are mean “transformative” in a weaker-than-OpenPhil sense, well the internet “transformed the world” according to everyday usage, and the impact of the internet on the economy is (AFAICT) >$10T. I suppose that the fact that the internet exists is somewhat relevant to AGI x-risk, but I don’t think it’s very relevant. I think that people trying to make AGI go well in a hypothetical world where the internet doesn’t exist would be mostly doing pretty similar things as we are.
The most realistic view I see that implies fast takeoff without making predictions about existing systems is:
- You have very short AGI timelines based on your reasoning about AGI.
- Non-AGI impact simply can't grow quickly enough to be large prior to AGI.
Why not “non-AGI AI systems will eventually be (at most) comparably impactful to the internet or automobiles or the printing press, before plateauing, and this is ridiculously impactful by everyday standards, but it doesn’t strongly change the story of how we should be thinking about AGI”?
BTW, why do we care about slow takeoff anyway?
- Slow takeoff suggests that we see earlier smaller failures that have important structural similarity to later x-risk-level failures
- Slow takeoff means the world that AGI will appear in will be so different from the current world that it totally changes what makes sense to do right now about AGI x-risk.
(Anything else?)
I can believe that “LLMs will transform the world” comparably to how the internet or the integrated circuit has transformed the world, without expecting either of those bullets to be true, right?
I think we are getting significant evidence about the plausibility that deep learning is able to automate real human cognitive work, and we are seeing extremely rapid increases in revenue and investment. I think those observations have extremely high probability if big deep learning systems will be transformative (this is practically necessary to see!), and fairly low base rate (not clear exactly how low but I think 25% seems reasonable and generous).
So yeah, I think that we have gotten considerable evidence about this, more than a factor of 4. I've personally updated my views by about a factor of 2, from a 25% chance to a 50% chance that scaling up deep learning is the real deal and leads to transformation soon. I don't think "That's a wild claim!" means you don't have evidence, that's not how evidence works.
I think that normal people who follow tech have also moved their views massively. They take the possibility of crazy transformations from deep leaning much more seriously than they did 5 years ago. They are much more likely to view deep learning as producing systems analogous to humans in economically relevant ways. And so on.
Why not “non-AGI AI systems will eventually be (at most) comparably impactful to the internet or automobiles or the printing press, before plateauing, and this is ridiculously impactful by everyday standards, but it doesn’t strongly change the story of how we should be thinking about AGI”?
That view is fine, but now I'm just asking what your probability distribution is over the location of that plateau. Is it no evidence to see LMs at $10 billion? $100 billion? Is your probability distribution just concentrated with 100% of its mass between $1 trillion and $10 trillion? (And if so: why?)
It's maybe plausible to say that your hypothesis is just like mine but with strong cutoffs at some particular large level like $1 trillion. But why? What principle makes an impact of $1 trillion possible but $10 trillion impossible?
Incidentally, I don't think the internet adds $10 trillion of value. I agree that as I usually operationalize it the soft takeoff view is not technically falsified until AI gets to ~$100 trillion per year (though by $10 trillion I think fast takeoff has gotten considerably less feasible in addition to this update, and the world will probably be significantly changed and prepared for AI in a way that is a large part of what matters about slow takeoff), so we could replace the upper end of that interval with $100 trillion if we wanted to be more generous.
Hmm, for example, given that the language translation industry is supposedly $60B/yr, and given that we have known for decades that AI can take at least some significant chunk out of this industry at the low-quality end [e.g. tourists were using babelfish.altavista.com in the 1990s despite it sucking], I think someone would have to have been very unreasonable indeed to predict in advance that there will be an eternal plateau in the non-AGI AI market that’s lower than $1B/yr. (And that’s just one industry!) (Of course, that’s not a real prediction in advance ¯\_(ツ)_/¯ )
What I was getting at with "That's a wild claim!" is that your theory makes an a-priori-obvious prediction (AI systems will grow to a >$1B industry pre-FOOM) and a controversial prediction (>$100T industry), and I think common sense in that situation is to basically ignore the obvious prediction and focus on the controversial one. And Bayesian updating says the same thing. The crux here is whether or not it has always been basically obvious to everyone, long in advance, that there’s at least $1B of work on our planet that can be done by non-FOOM-related AI, which is what I’m claiming in the previous paragraph where I brought up language translation. (Yeah I know, I am speculating about what was obvious to past people without checking what they said at the time—a fraught activity!)
Yeah deep learning can “automate real human cognitive work”, but so can pocket calculators, right? Anyway, I’d have to think more about what my actual plateau prediction is and why. I might reply again later. :)
I feel like your thinking here is actually mostly coming from “hey look at all the cool useful things that deep learning can do and is doing right now”, and is coming much less from the specific figure “$1B/year in 2023 and going up”. Is that fair?
I don't think it's obvious a priori that training deep learning to imitate human behavior can predict general behavior well enough to carry on customer support conversations, write marketing copy, or write code well enough to be helpful to software engineers. Similarly it's not obvious whether it will be able to automate non-trivial debugging, prepare diagrams for a research paper, or generate plausible ML architectures. Perhaps to some people it's obvious there is a divide here, but to me it's just not obvious so I need to talk about broad probability distributions over where the divide sits.
I think ~$1B/year is a reasonable indicator of the generality and extent of current automation. I really do care about that number (though I wish I knew it better) and watching it go up is a big deal. If it can just keep being more useful with each passing year, I will become more skeptical of claims about fundamental divides, even if after the fact you can look at each thing and say "well it's not real strong cognition." I think you'll plausibly be able to do that up through the end of days, if you are shameless enough.
I think the big ambiguity is about how you mark out a class of systems that benefit strongly from scale (i.e. such that doubling compute more than doubles economic value) and whether that's being done correctly here. I think it's fairly clear that the current crop of systems are much more general and are benefiting much more strongly from scale than previous systems. But it's up for debate.
Hmm. I think we’re talking past each other a bit.
I think that everyone (including me) who wasn’t expecting LLMs to do all the cool impressive things that they can in fact do, or who wasn’t expecting LLMs to improve as rapidly as they are in fact improving, is obligated to update on that.
Once I do so update, it’s not immediately obvious to me that I learn anything more from the $1B/yr number. Yes, $1B/yr is plenty of money, but still a drop in the bucket of the >$1T/yr IT industry, and in particular, is dwarfed by a ton of random things like “corporate Linux support contracts”. Mostly I’m surprised that the number is so low!! (…For now!!)
But whatever, I’m not sure that matters for anything.
Anyway…
I did spend considerable time last week pondering where & whether I expect LLMs to plateau. It was a useful exercise; I appreciate your prodding. :)
I don’t really have great confidence in my answers, and I’m mostly redacting the details anyway. But if you care, here are some high-level takeaways of my current thinking:
(1) I expect there to be future systems that centrally incorporate LLMs, but also have other components, and I expect these future systems to be importantly more capable, less safe, and more superficially / straightforwardly agent-y than is an LLM by itself as we think of them today.
IF “LLMs scale to AGI”, I expect that this is how, and I expect that my own research will turn out to be pretty relevant in such a world. More generally, I expect that, in such systems, we’ll find the “traditional LLM alignment discourse” (RLHF fine-tuning, shoggoths, etc.) to be pretty irrelevant, and we’ll find the “traditional agent alignment discourse” (instrumental convergence, goal mis-generalization, etc.) to be obviously & straightforwardly relevant.
(2) One argument that pushes me towards fast takeoff is pretty closely tied to what I wrote in my recent post:
Two different perspectives are:
- AGI is about knowing how to do lots of things
- AGI is about not knowing how to do something, and then being able to figure it out.
I’m strongly in the second camp.…
The following is a bit crude and not entirely accurate, but to a first approximation I want to say that LLMs have a suite of abstract “concepts” that it has seen in its training data (and that were in the brains of the humans who created that training data), and LLMs are really good at doing mix-and-match compositionality and pattern-match search to build a combinatorial explosion of interesting fresh outputs out of that massive preexisting web of interconnected concepts.
But I think there are some types of possible processes along the lines of:
- “invent new useful concepts from scratch—even concepts that have never occurred to any human—and learn them permanently, such that they can be built on the future”
- “notice inconsistencies in existing concepts / beliefs, find ways to resolve them, and learn them permanently, such that those mistakes will not be repeated in the future”
- etc.
I think LLMs can do things like this a little bit, but not so well that you can repeat them in an infinite loop. For example, I suspect that if you took this technique and put it in an infinite loop, it would go off the rails pretty quickly. But I expect that future systems (of some sort) will eventually be able to do these kinds of things well enough to form a stable loop, i.e. the system will be able to keep running this process (whatever it is) over and over, and not go off the rails, but rather keep “figuring out” more and more things, thus rocketing off to outer space, in a way that’s loosely analogous to self-play in AlphaZero, or to a smart human gradually honing in on a better and better understanding of a complicated machine.
I think this points to an upcoming “discontinuity”, in the sense that I think right now we don’t have systems that can do the above bullet points (at least, not well enough to repeat them in an infinite loop), and I think we will have such systems in the future, and I think we won’t get TAI until we do. And it feels pretty plausible to me (admittedly not based on much!) that it would only take a couple years or less between “widespread knowledge of how to build such systems” and “someone gets an implementation working well enough that they can run it in an infinite loop and it just keeps “figuring out” more and more things, correctly, and thus it rockets off to radically superhuman intelligence and capabilities.”
(3) I’m still mostly expecting LLMs (and more broadly, LLM-based systems) to not be able to do the above bullet point things, and (relatedly) to plateau at a level where they mainly assist rather than replace smart humans. This is tied to fundamental architectural limitations that I believe transformers have (and indeed, that I believe DNNs more generally have), which I don’t want to talk about…
(4) …but I could totally be wrong. ¯\_(ツ)_/¯ And I think that, for various reasons, my current day-to-day research program is not too sensitive to the possibility that I’m wrong about that.
Steven: as someone who has read all your posts agrees with you on almost everything, this is a point where I have a clear disagreement with you. When I switched from neuroscience to doing ML full-time, some of the stuff I read to get up to speed was people theorizing about impossibly large (infinite or practically so) neural networks. I think that the literature on this does a pretty good job of establishing that, in the limit, neural networks can compute any sort of function. Which means that they can compute all the functions in a human brain, or a set of human brains. Meaning, it's not a question of whether scaling CAN get us to AGI. It certainly can. It's a question of when. There is inefficiency in trying to scale an algorithm which tries to brute force learn the relevant functions rather than have them hardcoded in via genetics. I think that you are right that there are certain functions the human brain does quite well that current SoTA LLMs do very poorly. I don't think this means that scaling LLMs can't lead to a point where the relevant capabilities suddenly emerge. I think we are already in a regime of substantial compute and data overhang for AGI, and that the thing holding us back is the proper design and integration of modules which emulate the functions of parts of the brain not currently well imitated by LLMs. Like the reward and valence systems of the basal ganglia, for instance. It's still an open question to me whether we will get to AGI via scaling or algorithmic improvement. Imagine for a moment that I am correct that scaling LLMs could get us there, but also that a vastly more efficient system which borrows more functions from the human brain is possible. What might this scenario look like? Perhaps an LLM gets strong enough to, upon human prompting and with human assistance, analyze the computational neuroscience literature and open source code, and extract useful functions, and then do some combination of intuitively improve their efficiency and brute force test them in new experimental ML architectures. This is not so big a leap from what GPT-4 is capable of. I think that that's plausibly even a GPT-5 level of skill. Suppose also that these new architectures can be added onto existing LLM base models, rather than needed the base model to be retrained from scratch. As some critical amount of discoveries accumulate, GPT-5 suddenly takes a jump forward in efficacy, enabling it to process the rest of the potential improvements much faster, and then it takes another big jump forward, and then is able to rapidly self-improve with no further need for studying existing published research. In such a scenario, we'd have a foom over the course of a few days which could take us by surprise and lead to a rapid loss of control. This is exactly why I think Astera's work is risky, even though their current code seems quite harmless on its own. I think it is focused on (some of) the places where LLMs do poorly, but also that there's nothing stopping the work from being effectively integrated with existing models for substantial capability gains. This is why I got so upset with Astera when I realized during my interview process with them that they were open-sourcing their code, and also when I carefully read through their code and saw great potential there for integrating it with more mainstream ML to the empowerment of both.
literature examples of the sort of thing I'm talking about with 'enough scaling will eventually get us there', even though I haven't read this particular paper: https://arxiv.org/abs/2112.15577
https://openreview.net/forum?id=HyGBdo0qFm
Paul: I think you are making a valid point here. I think your point is (sadly) getting obscured by the fact our assumptions have shifted under our feet since the time when you began to make your point about slow vs fast takeoff.
I'd like to explain what I think the point you are right on is, and then try to describe how I think we need a new framing for the next set of predictions.
Several years ago, Eliezer and MIRI generally were frequently emphasizing the idea of a fast take-off that snuck up on us before the world had been much changed by narrow AI. You correctly predicted that the world would indeed be transformed in a very noticeable way by narrow AI before AGI. Eliezer in discussions with you has failed to acknowledge ways in which his views shifted from what they were ~10 years ago towards your views. I think this reflects poorly on him, but I still think he has a lot of good ideas, and made a lot of important predictions well in advance of other people realizing how important this was all going to be. As I've stated before, I often find my own views seeming to be located somewhere in-between your views and Eliezer's wherever you two disagree.
I think we should acknowledge your point that the world being changed in a very noticeable way by AI before true AGI, just as you have acknowledged Eliezer's point that once a runaway out-of-human-control human-out-of-the-loop recursive-self-improvement process gets started it could potentially proceed shockingly fast and lead to a loss of humanity's ability to regain control of the resulting AGI even once we realized what is happening. [I say Eliezer's point here, not to suggest that you disagreed with him on this point, but simply that he was making this a central part of his predictions from fairly early on.]
I think the framing we need now is: how can we predict, detect, and halt such a runaway RSI process before it is too late? This is important to consider from multiple angles. I mostly think that the big AI labs are being reasonably wary about this (although they certainly could do better). What concerns me more is the sort of people out in the wild who will take open source code and do dumb or evil stuff with it, Chaos-GPT-style, for personal gain or amusement. I think the biggest danger we face is that affordable open-source models seem to be lagging only a few years behind SotA models, and that the world is full of chaotic people who could (knowingly or not) trigger a runaway RSI process if such a thing is cheap and easy to do.
In such a strategic landscape, it could be crucially important to figure out how to:
a) slow down the progress of open source models, to keep dangerous runaway RSI from becoming cheap and easy to trigger
b) use SotA models to develop better methods of monitoring and preventing anyone outside a reasonably-safe-behaving org from doing this dangerous thing.
c) improving the ability of the reasonable orgs to self-monitor and notice the danger before they blow themselves up
I think that it does not make strategic sense to actively hinder the big AI labs. I think our best move is to help them move more safely, while also trying to build tools and regulation for monitoring the world's compute. I do not think there is any feasible solution for this which doesn't utilize powerful AI tools to help with the monitoring process. These AI tools could be along the lines of SotA LLMs, or something different like an internet police force made up of something like Conjecture's CogEms. Or perhaps some sort of BCI or gene-mod upgraded humans (though I doubt we have time for this).
My view is that algorithmic progress, pointed to by neuroscience, is on the cusp of being discovered, and if those insights are published, will make powerful AGI cheap and available to all competent programmers everywhere in the world. With so many people searching, and the necessary knowledge so widely distributed, I don't think we can count on keeping this under wraps forever. Rather than have these insights get discovered and immediately shared widely (e.g. by some academic eager to publish an exciting paper who didn't realize the full power and implications of their discovery), I think it would be far better to have a safety-conscious lab discover these, have a way to safely monitor themselves to notice the danger and potential power of what they've discovered. They can then keep the discoveries secret and collaborate with other safety-conscious groups and with governments to set up the worldwide monitoring we need to prevent a rogue AGI scenario. Once we have that, we can move safely to the long reflection and take our time figuring out better solutions to alignment. [An important crux for me here is that I believe that if we have control of an AGI which we know is potentially capable of recursively self-improving beyond our bounds to control it, we can successfully utilize this AGI at its current level of ability without letting it self-improve. If someone convinced me that this was untenable, it would change my strategic recommendations.]
As @Jed McCaleb said in his recent post, 'The only way forward is through!'. https://www.lesswrong.com/posts/vEtdjWuFrRwffWBiP/we-have-to-upgrade
As you can see from this prediction market I made, a lot of people currently disagree with me. I expect this will be a different looking distribution a year from now.
Here's an intuition pump analogy for how I've been thinking about this. Imagine that I, as someone with a background in neuroscience and ML was granted the following set of abilities. Would you bet that I, with this set of abilities, would be able to do RSI? I would.
Abilities that I would have if I were an ML model trying to self-improve:
Make many copies of myself, and checkpoints throughout the process.
Work at high speed and in parallel with copies of myself.
Read all the existing scientific literature that seemed potentially relevant.
Observe all the connections between my neurons, all the activations of my clones as I expose them to various stimuli or run them through simulations.
Ability to edit these weights and connections.
Ability to add neurons (up to a point) where they seemed most needed, connected in any way I see fit, initialized with whatever weights I choose.
Ability to assemble new datasets and build new simulations to do additional training with.
Ability to freeze some subsection of a clone's model and thus more rapidly train the remaining unfrozen section.
Ability to take notes and write collaborative documents with my clones working in parallel with me.
Ok. Thinking about that set of abilities, doesn't it seem like a sufficiently creative, intelligent, determined general agent could successfully self-improve? I think so. I agree it's unclear where the threshold is exactly, and when a transformer-based ML model will cross that threshold. I've made a bet at 'GPT-5', but honestly I'm not certain. Could be longer. Could be sooner...
Sorry @the gears to ascension . I know your view is that it would be better for me to be quiet about this, but I think the benefits of speaking up in this case outweigh the potential costs.
Is your probability distribution just concentrated with 100% of its mass between $1 trillion and $10 trillion? (And if so: why?)
To specifically answer the question in the parenthetical (without commenting on the dollar numbers; I don't actually currently have an intuition strongly mapping [the thing I'm about to discuss] to dollar amounts—meaning that although I do currently think the numbers you give are in the right ballpark, I reserve the right to reconsider that as further discussion and/or development occurs):
The reason someone might concentrate their probability mass at or within a certain impact range, is if they believe that it makes conceptual sense to divide cognitive work into two (or more) distinct categories, one of which is much weaker in the impact it can have. Then the question of how this division affects one's probability distribution is determined almost entirely by the question of what level at which they think the impact of the weaker category will saturate. And that question, in turn, has a lot more to do with the concrete properties they expect (or don't expect) to see from the weaker cognition type, than it has to do with dollar quantities directly. You can translate the former into the latter, but only via an additional series of calculations and assumptions; the actual object-level model—which is where any update would occur—contains no gear directly corresponding to "dollar value of impact".
So when this kind of model encounters LLMs doing unusual and exciting things that score very highly on metrics like revenue, investment, and overall "buzz"... well, these metrics don't directly lead the model to update. What instead the model considers relevant is whether, when you look at the LLM's output, that output seems to exhibit properties of cognition that are strongly prohibited by the model's existing expectations about weak versus strong cognitive work—and if it doesn't, then the model simply doesn't update; it wasn't, in fact, surprised by the level of cognition it observed—even if (perhaps) the larger model embedding it, which does track things like how the automation of certain tasks might translate into revenue/profit, was surprised.
And in fact, I do think this is what we observe from Eliezer (and from like-minded folk): he's updated in the sense of becoming less certain about how much economic value can be generated by "weak" cognition (although one should also note that he's never claimed to be particularly certain about this metric to begin with); meanwhile, he has not updated about the existence of a conceptual divide between "weak" and "strong" cognition, because the evidence he's been presented with legitimately does not have much to say on that topic. In other words, I think he would say that the statement
I think we are getting significant evidence about the plausibility that deep learning is able to automate real human cognitive work
is true, but that its relevance to his model is limited, because "real human cognitive work" is a category spanning (loosely speaking) both "cognitive work that scales into generality", and "cognitive work that doesn't", and that by agglomerating them together into a single category, you're throwing away a key component of his model.
Incidentally, I want to make one thing clear: this does not mean I'm saying the rise of the Transformers provides no evidence at all in favor of [a model that assigns a more direct correspondence between cognitive work and impact, and postulates a smooth conversion from the former to the latter]. That model concentrates more probability mass in advance on the observations we've seen, and hence does receive Bayes credit for its predictions. However, I would argue that the updates in favor of this model are not particularly extreme, because the model against which it's competing didn't actually strongly prohibit the observations in question, only assign less probability to them (and not hugely less, since "slow takeoff" models don't generally attempt to concentrate probability mass to extreme amounts, either)!
All of which is to say, I suppose, that I don't really disagree with numerical likelihoods you give here:
I think that we have gotten considerable evidence about this, more than a factor of 4. I've personally updated my views by about a factor of 2, from a 25% chance to a 50% chance that scaling up deep learning is the real deal and leads to transformation soon.
but that I'm confused that you consider this "considerable", and would write up a comment chastising Eliezer and the other "fast takeoff" folk because they... weren't hugely moved by, like, ~2 bits' worth of evidence? Like, I don't see why he couldn't just reply, "Sure, I updated by around 2 bits, which means that now I've gone from holding fast takeoff as my dominant hypothesis to holding fast takeoff as my dominant hypothesis." And that seems like that degree of update would basically produce the kind of external behavior that might look like "not owning up" to evidence, because, well... it's not a huge update to begin with?
(And to be clear, this does require that his prior look quite different from yours. But that's already been amply established, I think, and while you can criticize his prior for being overconfident—and I actually find myself quite sympathetic to that line of argument—criticizing him for failing to properly update given that prior is, I think, a false charge.)
Yes, I'm saying that each $ increment the "qualitative division" model fares worse and worse. I think that people who hold onto this qualitative division have generally been qualitatively surprised by the accomplishments of LMs, that when they make concrete forecasts those forecasts have mismatched reality, and that they should be updating strongly about whether such a division is real.
What instead the model considers relevant is whether, when you look at the LLM's output, that output seems to exhibit properties of cognition that are strongly prohibited by the model's existing expectations about weak versus strong cognitive work—and if it doesn't, then the model simply doesn't update; it wasn't, in fact, surprised by the level of cognition it observed—even if (perhaps) the larger model embedding it, which does track things like how the automation of certain tasks might translate into revenue/profit, was surprised.
I'm most of all wondering how you get high level of confidence in the distinction and its relevance. I've seen only really vague discussion. The view that LM cognition doesn't scale into generality seems wacky to me. I want to see the description of tasks it can't do.
In general if someone won't state any predictions of their view I'm just going to update about your view based on my understanding of what it predicts (which is after all what I'd ultimately be doing if I took a given view seriously). I'll also try to update about your view as operated by you, and so e.g. if you were generally showing a good predictive track record or achieving things in the world then I would be happy to acknowledge there is probably some good view there that I can't understand.
I'm confused that you consider this "considerable", and would write up a comment chastising Eliezer and the other "fast takeoff" folk because they... weren't hugely moved by, like, ~2 bits' worth of evidence? Like, I don't see why he couldn't just reply, "Sure, I updated by around 2 bits, which means that now I've gone from holding fast takeoff as my dominant hypothesis to holding fast takeoff as my dominant hypothesis."
I do think that a factor of two is significant evidence. In practice in my experience that's about as much evidence as you normally get between realistic alternative perspectives in messy domains. The kind of forecasting approach that puts 99.9% probability on things and so doesn't move until it gets 10 bits is just not something that works in practice.
On the slip side, it's enough evidence that Eliezer is endlessly condescending about it (e.g. about those who only assigned a 50% probability to the covid response being as inept as it was). Which I think is fine (but annoying), a factor of 2 is real evidence. And if I went around saying "Maybe our response to AI will be great" and then just replied to this observation with "whatever covid isn't the kind of thing I'm talking about" without giving some kind of more precise model that distinguishes, then you would be right to chastise me.
Perhaps more importantly, I just don't know where someone with this view would give ground. Even if you think any given factor of two isn't a big deal, ten factors of two is what gets you from 99.9% to 50%. So you can't just go around ignoring a couple of them every few years!
And rhetorically, I'm not complaining about people ultimately thinking fast takeoff is more plausible. I'm complaining about not expressing the view in such a way that we can learn about it based on what appears to me to be multiple bits of evidence, or acknowledging that evidence. This isn't the only evidence we've gotten, I'm generally happy to acknowledge many bits of ways in which my views have moved towards other people's.
So one claim is that a theory of post-AGI effects often won't say things about pre-AGI AI, so mostly doesn't get updated from pre-AGI observations. My take on LLM alignment asks to distinguish human-like LLM AGIs from stronger AGIs (or weirder LLMs), with theories of stronger AGIs not naturally characterizing issues with human-like LLMs. Like, they aren't concerned with optimizing for LLM superstimuli while their behavior remains in human imitation regime, where caring for LLM-specific things didn't have a chance to gain influence. When the mostly faithful imitation nature of LLMs breaks with enough AI tinkering, the way human nature is breaking now towards influence of AGIs, we get another phase change to stronger AGIs.
This seems like a pattern, theories of extremal later phases being bounded within their scopes, saying little of preceding phases that transition into them. If the phase transition boundaries get muddled in thinking about this, we get misleading impressions about how the earlier phases work, while their navigation is instrumental for managing transitions into the much more concerning later phases.
- What you are basically saying is "Yudkowsky thought AGI might have happened by now, whereas I didn't; AGI hasn't happened by now, therefore we should update from Yud to me by a factor of ~1.5 (and also from Yud to the agi-is-impossible crowd, for that matter)" I agree.
- Here's what I think is going to happen (this is something like my modal projection, obviously I have a lot of uncertainty; also I don't expect the world economy to be transformed as fast as this projects due to schlep and regulation, and so probably things will take a bit longer than depicted here but only a bit.):
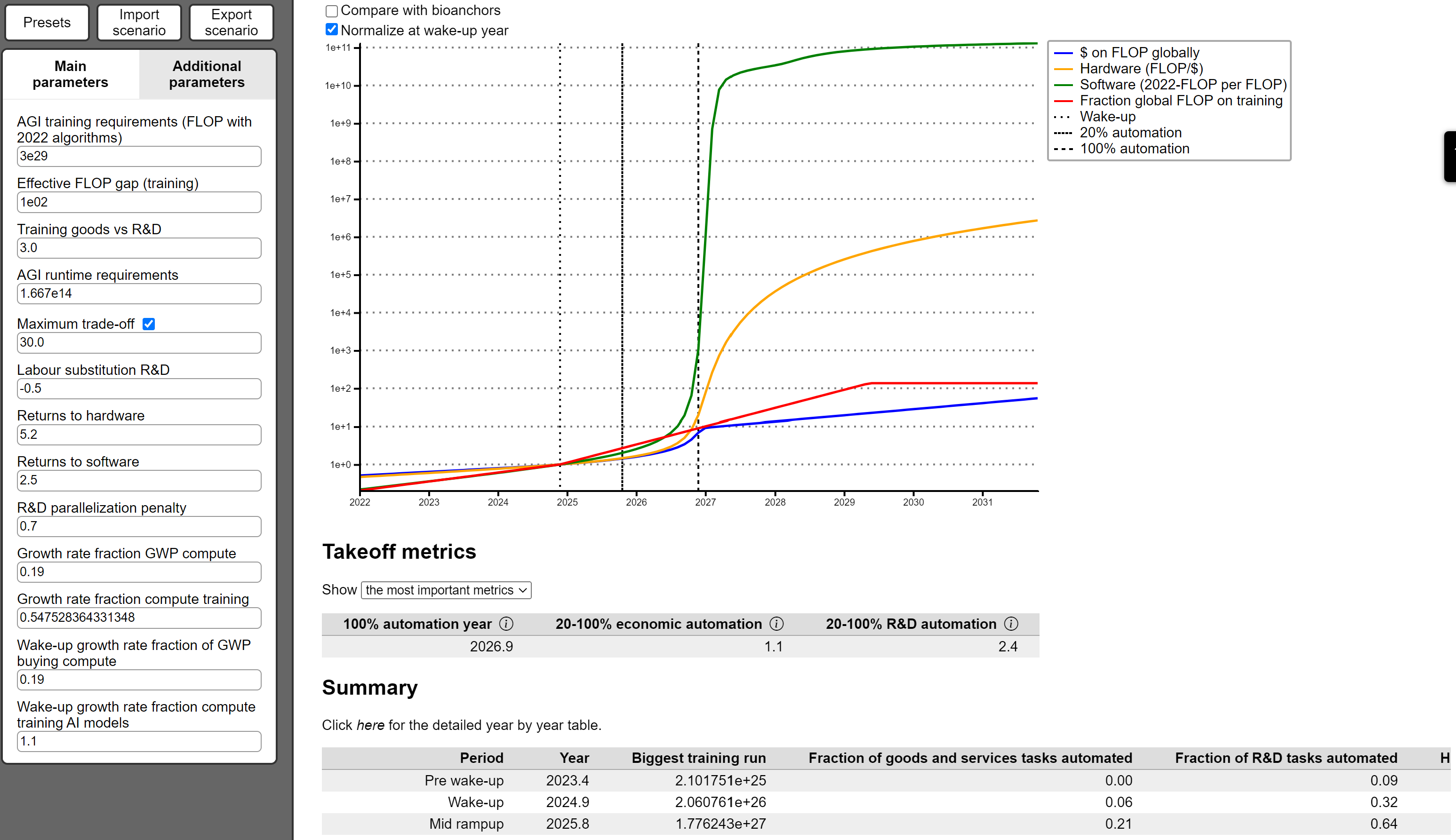
No pressure, but I'd love it if you found time someday to fiddle with the settings of the model at takeoffspeeds.com and then post a screenshot of your own modal or median future. I think that going forward, we should all strive to leave this old "fast vs. slow takeoff" debate in the dust & talk more concretely about variables in this model, or in improved models.
I don't quite know what "AGI might have happened by now means."
I thought that we might have built transformative AI by 2023 (I gave it about 5% in 2010 and about 2% in 2018), and I'm not sure that Eliezer and I have meaningfully different timelines. So obviously "now" doesn't mean 2023.
If "now" means "When AI is having ~$1b/year of impact," and "AGI" means "AI that can do anything a human can do better" then yes, I think that's roughly what I'm saying.
But an equivalent way of putting it is that Eliezer thinks weak AI systems will have very little impact, and I think weak AI systems will have a major impact, and so the more impact weak AI systems have the more evidence it gives for my view.
One way of putting it makes it seem like Eliezer would have shorter timelines since AGI might happen at any moment. Another way of putting it makes it seem like Eliezer may have longer timelines because nothing happens in the AGI-runup, and the early AI applications will drive increases in investment and will eventually accelerate R&D.
I don't know whether Eliezer in fact has shorter or longer timelines, because I don't think he's commented publicly recently. So it seems like either way of putting it could be misleading.
Ah, I'm pretty sure Eliezer has shorter timelines than you. He's been cagy about it but he sure acts like it, and various of his public statements seem to suggest it. I can try to dig them up if you like.
If "now" means "When AI is having ~$1b/year of impact," and "AGI" means "AI that can do anything a human can do better" then yes, I think that's roughly what I'm saying.
Yep that's one way of putting what I said yeah. My model of EY's view is: Pre-AGI systems will ramp up in revenue & impact at some rate, perhaps the rate that they have ramped up so far. Then at some point we'll actually hit AGI (or seed AGI) and then FOOM. And that point MIGHT happen later, when AGI is already a ten-trillion-dollar industry, but it'll probably happen before then. So... I definitely wasn't interpreting Yudkowsky in the longer-timelines way. His view did imply that maybe nothing super transformative would happen in the run-up to AGI, but not because pre-AGI systems are weak, rather because there just won't be enough time for them to transform things before AGI comes.
Anyhow, I'll stop trying to speak for him.
My model is very discontinues, I try to think of AI as AI (and avoid the term AGI).
And sure intelligence has some G measure, and everything we have built so far is low G[1] (humans have high G).
Anyway, at the core I think the jump will happen when an AI system learns the meta task / goal "Search and evaluate"[2], once that happens[3] G would start increasing very fast (versus earlier), and adding resources to such a thing would just accelerate this[4].
And I don't see how that diverges from this reality or a reality where its not possible to get there, until obviously we get there.
- ^
I can't speak to what people have built / are building in private.
- ^
Whenever people say AGI, I think AI that can do "search and evaluate" recursively.
- ^
And my intuition says that requires a system that has much higher G than current once, although looking at how that likely played out for us, it might be much lower than my intuition leads me to believe.
- ^
That is contingent on architecture, if we built a system that cannot scale easily or at all, then this wont happen.
[This comment is no longer endorsed by its author]
+1 for the push for more quantitative models.
(though I would register that trying to form a model with so many knobs to turn is really daunting, so I expect I personally will probably procrastinate a bit before actually putting together one, and I anticipate others to maybe feel similar)
I mean it's not so daunting if you mostly just defer to Tom & accept the default settings, but then tweak a few settings here and there.
Also it's very cheap to fiddle with each setting one by one to see how much of an effect it has. Most of them don't have much of an effect, so you only need to really focus on a few of them (such as the training requirements and the FLOP gap)
Why slow hardware takeoff (just in 4 years, though measuring in dollars is confusing)? I expect it a bit later, but faster, because nanotech breaks manufacturing tech level continuity, channeling theoretical research directly, and with reasonable amount of compute performing relevant research is not a bottleneck. This would go from modern circuit fabs to disassembling the moon and fueling it with fusion (or something of this sort of level of impact), immediately and without any intermediate industrial development process.
I don't think the model applies once you get to strongly superhuman systems--so, by mid-2027 in the scenario depicted. At that point, yeah, I'd expect the whole economy to be furiously bootstrapping towards nanotech or maybe even there already. Then the dissassemblies begin.
Also, as I mentioned, I think the model might overestimate the speed at which new AI advances can be rolled out into the economy, and converted into higher GDP and more/better hardware. Thus I think we completely agree.
Very minor note: is there some way we can move away from the terms "slow takeoff" and "fast takeoff" here? My impression is that almost everyone is confused by these terms except for a handful of people who are actively engaged in the discussions. I've seen people variously say that slow takeoff means:
- That AI systems will take decades to go from below human-level to above human level
- That AI systems will take decades to go from slightly above human-level to radically superintelligent
- That we'll never get explosive growth (GDP will just continue to grow at like 3%)
Whereas the way you're actually using the term is "We will have a smooth rather than abrupt transition to a regime of explosive growth." I don't have any suggestions for what terms we should use instead, only that we should probably come up with better ones.
Questions of how many trillions of dollars OpenAI will be allowed to generate by entities like the U.S. government are unimportant to the bigger concern, which is: Will these minds be useful in securing AIs before they become so powerful they're dangerous? Given the pace of ML research and how close LLMS are apparently able to get to AGI without actually-being-AGI, as a person who was only introduced to this debate in like the last year or so, my answer is: seems like that's what's happening now? Yeah?
In my model, the AGI threshold is a phase change. Before that point, AI improves at human research speed; after that point it improves much faster (even as early AGI is just training skills and not doing AI research). Before AGI threshold, the impact on the world is limited to what sub-AGI AI can do, which depends on how much time is available before AGI for humans to specialize AI to particular applications. So with short AGI threshold timelines, there isn't enough time for humans to make AI very impactful, but after AGI threshold is crossed, AI advancement accelerates much more than before that point. And possibly there is not enough time post-AGI to leave much of an economic impact either, before it gets into post-singularity territory (nanotech and massive compute; depending on how AGIs navigate transitive alignment, possibly still no superintelligence).
I think this doesn't fit into the takeoff speed dichotomy, because in this view the speed of the post-AGI phase isn't observable during the pre-AGI phase.
In the strategy stealing assumption I describe a policy we might want our AI to follow:
- Keep the humans safe, and let them deliberate(/mature) however they want.
- Maximize option value while the humans figure out what they want.
- When the humans figure out what they want, listen to them and do it.
Intuitively this is basically what I expect out of a corrigible AI, but I agree with Eliezer that this seems more realistic as a goal if we can see how it arises from a reasonable utility function.
So what does that utility function look like?
A first pass answer is pretty similar to my proposal from A Formalization of Indirect Normativity: we imagine some humans who actually have the opportunity to deliberate however they want and are able to review all of our AI's inputs and outputs. After a very long time, they evaluate the AI's behavior on a scale from [-1, 1], where 0 is the point corresponding to "nothing morally relevant happens," and that evaluation is the AI's utility.
The big difference is that I'm now thinking about what would actually happen, in the real world if the humans had the space and security to deliberate rather than formally defining a hypothetical process. I think that is going to end up being both safer and easier to implement, though it introduces its own set of complications.
Our hope is that the policy "keep the humans safe, then listen to them about what to do" is a good strategy for getting a high utility in this game, even if our AI is very unsure about what the humans would ultimately want. Then if our AI is sufficiently competent we can expect it to find a strategy at least this good.
The most important complication is that the AI is no longer isolated from the deliberating humans. We don't care about what the humans "would have done" if the AI hadn't been there---we need our AI to keep us safe (e.g. from other AI-empowered actors), we will be trusting our AI not to mess with the process of deliberation, and we will likely be relying on our AI to provide "amenities" to the deliberating humans (filling the same role as the hypercomputer in the old proposal).
Going even further, I'd like to avoid defining values in terms of any kind of counterfactual like "what the humans would have said if they'd stayed safe" because I think those will run into many of the original proposal's problems.
Instead we're going to define values in terms of what the humans actually conclude here in the real world. Of course we can't just say "Values are whatever the human actually concludes" because that will lead our agent to deliberately compromise human deliberation rather than protecting it.
Instead, we are going to add in something like narrow value leaning. Assume the human has some narrow preferences over what happens to them over the next hour. These aren't necessarily that wise. They don't understand what's happening in the "outside world" (e.g. "am I going to be safe five hours from now?" or "is my AI-run company acquiring a lot of money I can use when I figure out what I want?"). But they do assign low value to the human getting hurt, and assign high value to the human feeling safe and succeeding at their local tasks; they assign low value to the human tripping and breaking their neck, and high value to having the AI make them a hamburger if they ask for a hamburger; and so on. These preferences are basically dual to the actual process of deliberation that the human undergoes. There is a lot of subtlety about defining or extracting these local values, but for now I'm going to brush that aside and just ask how to extract the utility function from this whole process.
It's no good to simply use the local values, because we need our AI to do some lookahead (both to future timesteps when the human wants to remain safe, and to the far future when the human will evaluate how much option value the AI actually secured for them). It's no good to naively integrate local values over time, because a very low score during a brief period (where the human is killed and replaced by a robot accomplice) cannot be offset by any number of high scores in the future.
Here's my starting proposal:
- We quantify the human's local preferences by asking "Look at the person you actually became. How happy are you with that person? Quantitatively, how much of your value was lost by replacing yourself with that person?" This gives us a loss on a scale from 0% (perfect idealization, losing nothing) to 100% (where all of the value is gone). Most of the values will be exceptionally small, especially if we look at a short period like an hour.
- Eventually once the human becomes wise enough to totally epistemically dominate the original AI, they can assign a score to the AI's actions. To make life simple for now let's ignore negative outcomes and just describe value as a scalar from 0% (barren universe) to 100% (all of the universe is used in an optimal way). Or we might use this "final scale" in a different way (e.g. to evaluate the AI's actions rather than the actually assessing outcomes, assigning high scores to corrigible and efficient behavior and somehow quantifying deviations from that ideal).
- The utility is the product of all of these numbers.
I think there are a lot of problems with this method of quantitative aggregation. But I think this direction is promising and I currently expect something along these lines will work.
Here's my starting proposal:
- We quantify the human's local preferences by asking "Look at the person you actually became. How happy are you with that person? Quantitatively, how much of your value was lost by replacing yourself with that person?" This gives us a loss on a scale from 0% (perfect idealization, losing nothing) to 100% (where all of the value is gone). Most of the values will be exceptionally small, especially if we look at a short period like an hour.
- Eventually once the human becomes wise enough to totally epistemically dominate the original AI, they can assign a score to the AI's actions. To make life simple for now let's ignore negative outcomes and just describe value as a scalar from 0% (barren universe) to 100% (all of the universe is used in an optimal way). Or we might use this "final scale" in a different way (e.g. to evaluate the AI's actions rather than the actually assessing outcomes, assigning high scores to corrigible and efficient behavior and somehow quantifying deviations from that ideal).
- The utility is the product of all of these numbers.
If I follow correctly, the first step requires the humans to evaluate the output of narrow value learning, until this output becomes good enough to become universal with regard to the original AI and supervise it? I'm not sure I get why the AI wouldn't be incentivized to temper with the narrow value learning, à la Predict-o-matic? Depending on certain details, (like maybe the indescribable hellworld hypothesis), maybe the AI can introduce changes to the partial imitations/deliberations that end up hidden and compounding until the imitations epistemically dominates the AI, and then it ask it to do simple stuff.
The hope is that a tampering large enough to corrupt the human's final judgment would get a score of ~0 in the local value learning. 0 is the "right" score since the tampered human by hypothesis has lost all of the actual correlation with value. (Note that at the end you don't need to "ask it to do simple stuff" you can just directly assign a score of 1.)
This hope does require the local oversight process to be epistemically competitive with the AI, in the sense that e.g. if the AI understands something subtle about the environment dynamics then the oversight process also needs to understand that. And that's what we are trying to do with all of this business about training AIs to answer questions honestly. The point is just that you don't have to clear up any of the ambiguity about what the human wants, you just have to be able to detect someone tampering with deliberation. (And the operationalization of tampering doesn't have to be so complex.)
(I'm not sure if this made too much sense, I have a draft of a related comment that I'll probably post soon but overall expect to just leave this as not-making-much-sense for now.)
This hope does require the local oversight process to be epistemically competitive with the AI, in the sense that e.g. if the AI understands something subtle about the environment dynamics then the oversight process also needs to understand that. And that's what we are trying to do with all of this business about training AIs to answer questions honestly. The point is just that you don't have to clear up any of the ambiguity about what the human wants, you just have to be able to detect someone tampering with deliberation. (And the operationalization of tampering doesn't have to be so complex.)
So you want a sort of partial universality sufficient to bootstrap the process locally (while not requiring the understanding of our values in fine details), giving us enough time for a deliberation that would epistemically dominate the AI in a global sense (and get our values right)?
If that's about right, then I agree that having this would make your proposal work, but I still don't know how to get it. I need to read your previous posts on reading questions honestly.
You basically just need full universality / epistemic competitiveness locally. This is just getting around "what are values?" not the need for competitiveness. Then the global thing is also epistemically competitive, and it is able to talk about e.g. how our values interact with the alien concepts uncovered by our AI (which we want to reserve time for since we don't have any solution better than "actually figure everything out 'ourselves'").
Almost all of the time I'm thinking about how to get epistemic competitiveness for the local interaction. I think that's the meat of the safety problem.
The upside of humans in reality is that there is no need to figure out how to make efficient imitations that function correctly (as in X-and-only-X). To be useful, imitations should be efficient, which exact imitations are not. Yet for the role of building blocks of alignment machinery, imitations shouldn't have important systematic tendencies not found in the originals, and their absence is only clear for exact imitations (if not put in very unusual environments).
Suppose you already have an AI that interacts with the world, protects it from dangerous AIs, and doesn't misalign people living in it. Then there's time to figure out how to perform X-and-only-X efficient imitation, which drastically expands the design space, makes it more plausible that the kinds of systems that you wrote about a lot relying on imitations actually work as intended. In particular, this might include the kind of long reflection that has all the advantages of happening in reality without wasting time and resources on straightforwardly happening in reality, or letting the bad things that would happen in reality actually happen.
So figuring out object level values doesn't seem like a priority if you somehow got to the point of having an opportunity to figure out efficient imitation. (While getting to that point without figuring out object level values doesn't seem plausible, maybe there's a suggestion of a process that gets us there in the limit in here somewhere.)
I think the biggest difference is between actual and hypothetical processes of reflection. I agree that an "actual" process of reflection would likely ultimately involve most humans migrating to emulations for the speed and other advantages. (I am not sure that a hypothetical process necessarily needs efficient imitations, rather than AI reasoning about what actual humans---or hypothetical slow-but-faithful imitations---might do.)
I see getting safe and useful reasoning about exact imitations as a weird special case or maybe a reformulation of X-and-only-X efficient imitation. Anchoring to exact imitations in particular makes accurate prediction more difficult than it needs to be, as it's not the thing we care about, there are many irrelevant details that influence outcomes that accurate predictions would need to take into account. So a good "prediction" is going to be value-laden, with concrete facts about actual outcomes of setups built out of exact imitations being unimportant, which is about the same as the problem statement of X-and-only-X efficient imitation.
If such "predictions" are not good enough by themselves, underlying actual process of reflection (people living in the world) won't save/survive this if there's too much agency guided by the predictions. Using an underlying hypothetical process of reflection (by which I understand running a specific program) is more robust, as AI might go very wrong initially, but will correct itself once it gets around to computing the outcomes of the hypothetical reflection with more precision, provided the hypothetical process of reflection is defined as isolated from the AI.
I'm not sure what difference between hypothetical and actual processes of reflection you are emphasizing (if I understood what the terms mean correctly), since the actual civilization might plausibly move in into a substrate that is more like ML reasoning than concrete computation (let alone concrete physical incarnation), and thus become the same kind of thing as hypothetical reflection. The most striking distinction (for AI safety) seems to be the implication that an actual process of reflection can't be isolated from decisions of the AI taken based on insufficient reflection.
There's also the need to at least define exact imitations or better yet X-and-only-X efficient imitation in order to define a hypothetical process of reflection, which is not as absolutely necessary for actual reflection, so getting hypothetical reflection at all might be more difficult than some sort of temporary stability with actual reflection, which can then be used to define hypothetical reflection and thereby guard from consequences of overly agentic use of bad predictions of (on) actual reflection.
It seems to me like "Reason about a perfect emulation of a human" is an extremely similar task to "reason about a human," to me it does not feel closely related to X-and-only-X efficient imitation. For example, you can make calibrated predictions about what a human would do using vastly less computing power than a human (even using existing techniques), whereas perfect imitation likely requires vastly more computing power.
The point is that in order to be useful, a prediction/reasoning process should contain mesa-optimizers that perform decision making similar in a value-laden way to what the original humans would do. The results of the predictions should be determined by decisions of the people being predicted (or of people sufficiently similar to them), in the free-will-requires-determinism/you-are-part-of-physics sense. The actual cognitive labor of decision making needs to in some way be an aspect of the process of prediction/reasoning, or it's not going to be good enough. And in order to be safe, these mesa-optimizers shouldn't be systematically warped into something different (from a value-laden point of view), and there should be no other mesa-optimizers with meaningful influence in there. This just says that prediction/reasoning needs to be X-and-only-X in order to be safe. Thus the equivalence. Prediction of exact imitation in particular is weird because in that case the similarity measure between prediction and exact imitation is hinted to not be value-laden, which it might have to be in order for the prediction to be both X-and-only-X and efficient.
This is only unimportant if X-and-only-X is the likely default outcome of predictive generalization, so that not paying attention to this won't result in failure, but nobody understands if this is the case.
The mesa-optimizers in the prediction/reasoning similar to the original humans is what I mean by efficient imitations (whether X-and-only-X or not). They are not themselves the predictions of original humans (or of exact imitations), which might well not be present as explicit parts of the design of reasoning about the process of reflection as a whole, instead they are the implicit decision makers that determine what the conclusions of the reasoning say, and they are much more computationally efficient (as aspects of cheaper reasoning) than exact imitations. At the same time, if they are similar enough in a value-laden way to the originals, there is no need for better predictions, much less for exact imitation, the prediction/reasoning is itself the imitation we'd want to use, without any reference to an underlying exact process. (In a story simulation, there are no concrete states of the world, only references to states of knowledge, yet there are mesa-optimizers who are the people inhabiting it.)
If prediction is to be value-laden, with value defined by reflection built out of that same prediction, the only sensible way to set this up seems to be as a fixpoint of an operator that maps (states of knowledge about) values to (states of knowledge about) values-on-reflection computed by making use of the argument values to do value-laden efficient imitation. But if this setup is not performed correctly, then even if it's set up at all, we are probably going to get bad fixpoints, as it happens with things like bad Nash equilibria etc. And if it is performed correctly, then it might be much more sensible to allow an AI to influence what happens within the process of reflection more directly than merely by making systematic distortions in predicting/reasoning about it, thus hypothetical processes of reflection wouldn't need the isolation from AI's agency that normally makes them safer than the actual process of reflection.
Recently I've been thinking about ML systems that generalize poorly (copying human errors) because of either re-using predictive models of humans or using human inference procedures to map between world models.
My initial focus was on preventing re-using predictive models of humans. But I'm feeling increasingly like there is going to be a single solution to the two problems, and that the world-model mismatch problem is a good domain to develop the kind of algorithm we need. I want to say a bit about why.
I'm currently thinking about dealing with world model mismatches by learning a correspondence between models using something other than a simplicity prior / training a neural network to answering questions. Intuitively we want to do something more like "lining up" the two models and seeing what parts correspond to which others. We have a lot of conditions/criteria for such alignments, so we don't necessarily have to just stick with simplicity. This comment fleshes out one possible approach a little bit.
If this approach succeeds, then it also directly applicable to avoiding re-using human models---we want to be lining up the internal computation of our model with concepts like "There is a cat in the room" rather than just asking the model to predict whether there is a cat however it wants (which it may do by copying a human labeler). And on the flip side, I think that the "re-using human models" problem is a good constraint to have in mind when thinking about ways to do this correspondence. (Roughly speaking, because something like computational speed or "locality" seems like a really central constraint for matching up world models, and doing that approach naively can greatly exacerbate the problems with copying the training process.)
So for now I think it makes sense for me to focus on whether learning this correspondence is actually plausible. If that succeeds then I can step back and see how that changes my overall view of the landscape (I think it might be quite a significant change), and if it fails then I hope to at least know a bit more about the world model mismatch problem.
I think the best analogy in existing practice is probably doing interpretability work---mapping up the AI's model to my model is kind of like looking at neurons and trying to make sense of what they are computing (or looking for neurons that compute something). And giving up on a "simplicity prior" is very natural when doing interpretability, instead using other considerations to determine whether a correspondence is good. It still seems kind of plausible that in retrospect my current work will look like it was trying to get a solid theoretical picture on what interpretability should do (including in the regime where the correspondence is quite complex, and when the goal is a much more complete level of understanding). I swing back and forth on how strong the analogy to interpretability seems / whether or not this is how it will look in retrospect. (But at any rate, my research methodology feels like a very different approach to similar questions.)
Suppose that someone has trained a model to predict given , and I want to extend it to a question-answering model that answers arbitrary questions in a way that reflects all of 's knowledge.
Two prototypical examples I am thinking of are:
- runs a low-level model of physics. We want to extract high-level features of the world from the intermediate physical states, which requires e.g. a cat-classifier that operates directly on physical states rather than pixels.
- performs logical deductions from a set of statements produced by an opaque "intuition module." We want to output all of the intermediate inferences, which requires knowing how to translate between its intermediate language and natural language.
Here's an approach that seems kind of silly to me but is probably worth exploring:
- Let be all the activations of . In our examples, this includes (amongst other things) all of the physical states computed by or all of the intermediate deductions.
- Train an extraction model that answers questions given only the activations of .
- Define
- Optimize aggressively for speed, e.g. choose the simplest circuit that produces good answers.
This feels appealing for the same reason that you might hope minimal circuits are not deceptive. For example, it seems like would never bother re-using its model of a human because it would be faster to just hard-code all the facts about how humans answer questions.
In addition to feeling a bit silly, there are some obvious problems:
- Maybe does happen to compute the instrumental policy (e.g. because its thinking about a human who is thinking about the instrumental policy...) and so the fastest thing for to do is just to look up the instrumental policy and use it. And more generally there could be other things for to do that are faster than the intended model.
- The reason why we expect to be able to extract knowledge from is that needs to be able to extract that knowledge. For example, needs to be able to read sentences written in its internal language in order to perform deduction with them, so we know there is some fast way to do that. However, there are some disanalogies between the problems faced by E and F. A small issue is that F is "cooperating" with itself rather than trying to read off values from a fixed intermediate. A potentially bigger issue is that they use different priors (and F may use lots of weight-sharing and be relatively computationally slow when utilizing its own intermediate representation), and it's totally unclear what architectures for E could potentially work.
Some random thoughts:
- This approach has a vibe more like interpretability, where we first train a model and then search over interpretations of its activations, rather than other approaches I've described recently that are focused on jointly learning good predictions and question-answering. That said, in practice I do expect that we would need to learn E "as we go" in order for it to have a chance of "keeping up" with F (since otherwise F may have developed to a very arcane state from which SGD has no chance of learning a reasonable decoding).
- It's kind of weird to use something like a speed prior over E rather than something that tries to be a closer match for the "real" human prior. I expect to use a more "real" prior in the end but at this point I don't really know what's going on and am just looking for something that gets traction.
The most fundamental reason that I don't expect this to work is that it gives up on "sharing parameters" between the extractor and the human model. But in many cases it seems possible to do so, and giving on up on that feels extremely unstable since it's trying to push against competitiveness (i.e. the model will want to find some way to save those parameters, and you don't want your intended solution to involve subverting that natural pressure).
Intuitively, I can imagine three kinds of approaches to doing this parameter sharing:
- Introduce some latent structure (e.g. semantics of natural language, what a cat "actually is") that is used to represent both humans and the intended question-answering policy. This is the diagram
- Introduce some consistency check between and . This is the diagram
- Somehow extract from or build it out of pieces derived from . This is the diagram . This is kind of like a special case of 1, but it feels pretty different.
(You could imagine having slightly more general diagrams corresponding to any sort of d-connection between and .)
Approach 1 is the most intuitive, and it seems appealing because we can basically leave it up to the model to introduce the factorization (and it feels like there is a good chance that it will happen completely automatically). There are basically two challenges with this approach:
- It's not clear that we can actually jointly compress and . For example, what if we represent in an extremely low level way as a bunch of neurons firing; the neurons are connected in a complicated and messy way that learned to implement something like , but need not have any simple representation in terms of . Even if such a factorization is possible, it's completely unclear how to argue about how hard it is to learn. This is a lot of what motivates the compression-based approaches---we can just say " is some mess, but you can count on it basically computing " and then make simple arguments about competitiveness (it's basically just as hard as separately learning and ).
- If you overcame that difficulty, you'd still have to actually incentivize this kind of factorization in the model (rather than sharing parameters in the unintended way). It's unclear how to do that (maybe you're back to think about something speed-prior like, and this is just a way to address my concern about the speed-prior-like proposals), but this feels more tractable than the first problem.
I've been thinking about approach 2 over the last 2 months. My biggest concern is that it feels like you have to pay the bits of H back "as you learn them" with SGD, but you may learn them in such a way that you don't really get a useful consistency update until you've basically specified all of H. (E.g. suppose you are exposed to brain scans of humans for a long time before you learn to answer questions in a human-like way. Then at the end you want to use that to pay back the bits of the brain scans, but in order to do so you need to imagine lots of different ways the brain scans could have looked. But there's no tractable way to do that, because you have to fill in the the full brain scan before it really tells you about whether your consistency condition holds.)
Approach 3 is in some sense most direct. I think this naturally looks like imitative generalization, where you use a richer set of human answers to basically build on top of your model. I don't see how to make this kind of thing work totally on its own, but I'm probably going to spend a bit of time thinking about how to combine it with approaches 1 and 2.
One aspect of this proposal which I don't know how to do is evaluation the answers of the question-answerer. That looks too me very related to the deconfusion of universality that we discussed a few months ago, and without an answer to this, I feel like I don't even know how to run this silly approach.
You could imitate human answers, or you could ask a human "Is answer much better than answer ?" Both of these only work for questions that humans can evaluate (in hindsight), and then the point of the scheme is to get an adequate generalization to (some) questions that humans can't answer.
Ok, so you optimize the circuit both for speed and for small loss on human answers/comparisons, hoping that it generalizes to more questions while not being complex enough to be deceptive. Is that what you mean?
I'm mostly worried about parameter sharing between the human models in the environment and the QA procedure (which leads the QA to generalize like a human instead of correctly). You could call that deception but I think it's a somewhat simpler phenomenon.
I think the biggest problem is that can compute the instrumental policy (or a different policy that works well, or a fragment of it). Some possible reasons:
- Maybe some people in the world are incidentally thinking about the instrumental policy and makes predictions about them.
- Maybe an adversary who computes a policy that performs well in order to try to attack the learning process (since may just copy the adversary's policy in order to be fast if it works well on training, resulting in bad generalization).
- Maybe no one computes the instrumental policy itself, but they compute helpful building blocks and can save compute by reusing those.
- Maybe wants to predict question-answering policies, and computing optimal responses to the training objective is a simple way for it to forecast what they will do. (It's totally unclear if this is actually more efficient than the intended policy.) Then can copy that.
I don't know if any of those particular failures are too likely. But overall it seems really bad to rely on never computing something inconvenient, and it definitely doesn't look like it's going to work in the worst case.
What are some possible outs, if in fact computes something adversarial to try to make it easy for to learn something bad?
- At the time when is running it doesn't know the question Q that will need to answer. So in order to cause trouble it would need to compute answers for all of these questions. But I'm afraid that this is doable in many cases, since could translate a big chunk of its internal state into natural language and then can do some simple QA on top of that.
- We could try to ensure that the correctness/consistency checks are really complex or challenging to meet, at least for some questions. If the complexity of these checks scales up with the complexity of itself (e.g. by using amplification where the evaluator consults a model as big as ), then maybe it's impossible for to meet them. This idea can be applied without the factorization into F and E, but it's probably useful to have this kind of factorization in mind as a possible tool when exploring approaches based on tricky-evaluations.
- We could try to exploit some further structural facts about the parts of that are used by . For example, it feels like the intended model is going to be leveraging facts that are further "upstream." For example, suppose an attacker observes that there is a cat in the room, and so writes out "There is a cat in the room" as part of a natural-language description of what it's going on that it hopes that will eventually learn to copy. If predicts the adversary's output, it must first predict that there is actually a cat in the room, which then ultimately flows downstream into predictions of the adversary's behavior. And so we might hope to prefer the "intended" by having it preferentially read from the earlier activations (with shorter computational histories).
Overall this kind of approach feels like it's probably doomed, but it does capture part of the intuition for why we should "just" be able to learn a simple correspondence rather than getting some crazy instrumental policy. So I'm not quite ready to let it go yet. I'm particularly interested to push a bit on the third of these approaches.
Here's another approach to "shortest circuit" that is designed to avoid this problem:
- Learn a circuit that outputs an entire set of beliefs. (Or maybe some different architecture, but with ~0 weight sharing so that computational complexity = description complexity.)
- Impose a consistency requirement on those beliefs, even in cases where a human can't tell the right answer.
- Require 's beliefs about to match . We hope that this makes an explication of "'s beliefs."
- Optimize some combination of (complexity) vs (usefulness), or chart the whole pareto frontier, or whatever. I'm a bit confused about how this step would work but there are similar difficulties for the other posts in this genre so it's exciting if this proposal gets to that final step.
The "intended" circuit just follows along with the computation done by and then translates its internal state into natural language.
What about the problem case where computes some reasonable beliefs (e.g. using the instrumental policy, where the simplicity prior makes us skeptical about their generalization) that could just read off? I'll imagine those being written down somewhere on a slip of paper inside of 's model of the world.
- Suppose that the slip of paper is not relevant to predicting , i.e. it's a spandrel from the weight sharing. Then the simplest circuit just wants to cut it out. Whatever computation was done to write things down on the slip of paper can be done directly by , so it seems like we're in business.
- So suppose that the slip of paper is relevant for predicting , e.g. because someone looks at the slip of paper and then takes an action that affects . If (the correct) is itself depicted on the slip of paper, then we can again cut out the slip of paper itself and just run the same computation (that was done by whoever wrote something on the slip of paper). Otherwise, the answers produced by still have to contain both the items on the slip of paper as well as some facts that are causally downstream of the slip of paper (as well as hopefully some about the slip of paper itself). At that point it seems like we have a pretty good chance of getting a consistency violation out of .
Probably nothing like this can work, but I now feel like there are two live proposals for capturing the optimistic minimal circuits intuition---the one in this current comment, and in this other comment. I still feel like the aggressive speed penalization is doing something, and I feel like probably we can either find a working proposal in that space or else come up with some clearer counterexample.
We could try to exploit some further structural facts about the parts of that are used by . For example, it feels like the intended model is going to be leveraging facts that are further "upstream." For example, suppose an attacker observes that there is a cat in the room, and so writes out "There is a cat in the room" as part of a natural-language description of what it's going on that it hopes that will eventually learn to copy. If predicts the adversary's output, it must first predict that there is actually a cat in the room, which then ultimately flows downstream into predictions of the adversary's behavior. And so we might hope to prefer the "intended" by having it preferentially read from the earlier activations (with shorter computational histories).
The natural way to implement this is to penalize not for the computation it does, but for all the computation needed to compute its output (including within .). The basic problem with this approach is that it incentivizes to do all of the computation of from scratch in a way optimized for speed rather than complexity. I'd set this approach aside for a while because of this difficulty and the unnaturalness mentioned in the sibling (where we've given up on what seems to be an important form of parameter-sharing).
Today I was thinking about some apparently-totally-different angles of attack for the ontology identification problem, and this idea seems to have emerged again, with a potential strategy for fixing the "recompute problem". (In the context of ontology identification, the parameter-sharing objection no longer applies.)
Here's the idea:
- Train as before.
- Start with a bunch of facts and probabilistic relationships that the human knows, expressed in their own ontology. These might be facts like "Ice melts at 100 degrees" or "Dogs bark at cats" or whatever.
- We are going to try to jointly learn (i) a correspondence between and the human's ontology, (ii) a set of "justifications" showing that satisfies all of the relationships the human expects. I'm imagining justifications like simulating ice at 100 degrees and observing that it indeed melts, or sampling situations with dogs and cats and verifying that the dogs bark.
- The correspondence is constrained to map "the observations" (a concept in the human's ontology) to the output of , but other than that there is no simplicity prior, it can be anything.
- Our goal is to make the justifications as computationally simple as possible. (Which indirectly incentivizes us to make as computationally simple as possible.)
This still feels a bit weird, but you could imagine it handling a bunch of cases in a promising way:
- has no reason to "reuse the human" or to use the human's inference procedure in order to save bits, because doing either of those things makes the justifications more computationally complex.
- If there is a human embedded inside who performs the correspondence and writes it down in an easy-to-read way, has no motivation to read it: if is defined in that way, then justifying facts will require simulating the human (even if that work was already done inside ). If simply cut out the middle man and applied the correspondence itself, then it could save compute in the typical case (except when talking about facts about that human). This is subtle in a few ways but tentatively looks plausible to me.
- has no reason to ignore and implement a new more-efficient-but-more-complex simulation , because (i) it ultimately needs to relate observations back to the output of , and many of its concepts are related to observations (e.g. what cats look like), (ii) that forces and to have the same behavior, (iii) the justification would then need to show that the the "observations" in are the same as the observations in , which is computationally costly.
But right now it's a pretty vague proposal, because it's unclear what the nature of these facts or justifications are. If you set that up in a naive way, then the justification effectively just needs to simulate all of . That's a problem because it reintroduces the failure mode where you need to simulate the human, and therefore there's no extra cost to just simulating and then listening to whatever they say.
Overall I think that probably nothing like this works, but I'm still feeling a lot more optimistic than I was last week and want to explore it further. (This is partially for reasons not discussed in this comment, that several other approaches/motivations seem to converge on something similar.)
Here's a slightly more formal algorithm along these lines:
- Assume that both the human's model and the AI's model are Bayesian networks where you compute the probability distribution over a node 's value based on the values of its parents . I'll write for the set of values that a node can take on (in either model), and for the joint values of a set of nodes .
- A correspondence tells you how to compute the value of each node in the human's model. This consistent of (i) a neighborhood in the AI's model which suffices to determine , (ii) a function .
- Both the AI's model and the human model contain some distinguished observation nodes. must be the identity on these nodes.
- An "explanation" of a correspondence consists of a set of nodes in the AI's model for each node in the human's model. The intuition is that we can run a simulation involving only these nodes in order to reproduce the probability distribution of given its parents' values.
- In particular, , and for all . In order to check whether reproduces the right distribution, we first sample values at random for all the nodes some of whose parents aren't in . Then we sample values for the remaining nodes. We can use to compute the corresponding values for and all of its parents. And then we can compute the conditional distributions for given each set of values for its parents.
- We require that the explanations exactly reproduce the conditional probability over given .
- The "cost" of the explanation of is the sum of the compute required to sample all the nodes in . The "cost" of the correspondence is the compute required to evaluate it.
- We search for the set of correspondences and explanations for which the total cost is minimized.
- (Maybe we also have some requirement where the correspondence agrees with some training data about . I'm not really sure about that.)
Reviewing how this behaves in each of the bad cases from the parent:
- It's very bad to define by computing the observation and then using the human's inference algorithm. The entire motivation for defining it this way was to save on description complexity, but is only being penalized for computational complexity. (This also forces every single to include the entire process that generates the observations, which seems like it should be an even bigger deal. But this feels less like the "right" reason and I think it might change for a future version of the scheme.)
- If there is a human in the simulation who knows the value of , it's extremely bad to define to be that human. This is because the explanation will need to include the entire process by which the human computes that value. This is guaranteed to be more expensive than just performing that compute in the correspondence itself.
- We could define to compute the value of from scratch using the initial values of the simulation, using some more-efficient simulation. But we can't do this for the observation node , since it is required to map up with the observation node in the AI's model. So in order to explain the observation node we will need to have include the AI's entire model, or at least the parts leading up to the observation. This means we are basically paying for two full copies of the computation, and so we're not really benefiting from the fact that the second copy is more efficient. (We are also potentially overlapping a lot of computation between the different 's, but again I'm a bit less sure how robust that is and whether it will hold up in different formalizations.)
There are a lot of problems and missing details in this proposal:
- This requires exactly reproducing the conditional probabilities in the human's model. But that's totally unrealistic for anything short of a full simulation---and even for the full simulation it wouldn't reproduce the probabilities since the human model isn't accurate. So we need some way to choose a good enough explanation, i.e. a way of balancing the computational complexity of the explanation against the quality of the conditional probabilities that come out.
- We're sampling the inputs to uniformly at random. This seems unlikely to work in general. We could easily sample each node from its marginal, but most of the action is in the correlation. Allowing arbitrary correlations causes problems (since you could just specify the "human is accurate" correlation and then read off the correct answers from there). So I think probably some more flexible system is needed here; there are a lot of options but it's tricky.
- There is something problematic about the overlapping explanations . If they overlap you need to pay for all of them, but for the intended mapping there will often be quite significant overlap. This isn't inherently a problem, but I'm scared that it's going to introduce a lot of pressure towards some different correspondence that is able to avoid that problem. We need to penalize overlap because the case where the training data is embedded in the model---the main problem with that model is that you need to separately explain every way in which the human is correct with highly overlapping explanations. If you didn't penalize those then you may just end up with the embedded explanations (for which is extremely cheap).
- There is something tricky about uniformity in the model and in the implementations of .
- I'm still scared about the "recompute everything from scratch" failure mode. The model does need to have a single explanation that needs to include the whole model. But (i) it doesn't have to reproduce work, (ii) it can cut out all the stuff not on the path to the observation. So the obvious reason that this one loses is by the duplicated work in . Hopefully that's actually robust.
- We are making really strong structural assumptions on the models and the correspondence between them. We get some things for free (because humans actually do have extra structure in our beliefs about the world that is properly part of the problem statement, and the AI's model is constrained by its architecture) but not nearly this much.
Overall I'm becoming significantly more optimistic that something like this will work (though still less likely than not). Trying to step back and see the big picture, it seems like there are three key active ingredients:
- Using "speed" instead of "simplicity" as the ~only requirement for these correspondences.
- Having separate correspondences for separate properties and not allowing them to share tons of computation with each other (to prevent re-running the whole simulation).
- Forcing the model to explain correlations, so that using an "embedded" copy of the answers (like a simulation of the data-generating process) forces you to reproduce the computation that produced that answer.
My next step would probably be looking at cases where these high-level ingredients aren't sufficient (e.g. are there cases where "generate obs then do inference in the human model" is actually cheaper?). If they look pretty good, then I'll spend some more time trying to fill in the details in a more plausible way.
We might be able to get similar advantages with a more general proposal like:
Fit a function f to a (Q, A) dataset with lots of questions about latent structure. Minimize the sum of some typical QA objective and the computational cost of verifying that f is consistent.
Then the idea is that matching the conditional probabilities from the human's model (or at least being consistent with what the human believes strongly about those conditional probabilities) essentially falls out of a consistency condition.
It's not clear how to actually formulate that consistency condition, but it seems like an improvement over the prior situation (which was just baking in the obviously-untenable requirement of exactly matching). It's also not clear what happens if this consistency condition is soft.
It's not clear what "verify that the consistency conditions are met" means. You can always do the same proposal as in the parent, though it's not really clear if that's a convincing verification. But I think that's a fundamental philosophical problem that both of these proposals need to confront.
It's not clear how to balance computational cost and the QA objective. But you are able to avoid most of the bad properties just by being on the Pareto frontier, and I don't think this is worse than the prior proposal.
Overall this approach seems like it could avoid making such strong structural assumptions about the underlying model. It also helps a lot with the overlapping explanations + uniformity problem. And it generally seems to be inching towards feeling plausible.
(To restate the obvious, all of the stuff here is extremely WIP and rambling.)
I've often talked about the case where an unaligned model learns a description of the world + the procedure for reading out "what the camera sees" from the world. In this case, I've imagined an aligned model starting from the unaligned model and then extracting additional structure.
It now seems to me that the ideal aligned behavior is to learn only the "description of the world" and then have imitative generalization take it from there, identifying the correspondence between the world we know and the learned model. That correspondence includes in particular "what the camera sees."
The major technical benefit of doing it this way is that we end up with a higher prior probability on the aligned model than the unaligned model---the aligned one doesn't have to specify how to read out observations. And specifying how to read out observations doesn't really make it easier to find that correspondence.
We still need to specify how the "human" in imitative generalization actually finds this correspondence. So this doesn't fundamentally change any of the stuff I've recently been thinking about, but I think that the framing is becoming clearer and it's more likely we can find our way to the actually-right way to do it.
It now seems to me that a core feature of the situation that lets us pull out a correspondence is that you can't generally have two equally-valid correspondences for a given model---the standards for being a "good correspondence" are such that it would require crazy logical coincidence, and in fact this seems to be the core feature of "goodness." For example, you could have multiple "correspondences" that effectively just recompute everything from scratch, but by exactly the same token those are bad correspondences.
(This obviously only happens once the space and causal structure is sufficiently rich. There may be multiple ways of seeing faces in clouds, but once your correspondence involves people and dogs and the people talking about how the dogs are running around, it seems much more constrained because you need to reproduce all of that causal structure, and the very fact that humans can make good judgments about whether there are dogs implies that everything is incredibly constrained.)
There can certainly be legitimate ambiguity or uncertainty. For example, there may be a big world with multiple places that you could find a given pattern of dogs barking at cats. Or there might be parts of the world model that are just clearly underdetermined (e.g. there are two identical twins and we actually can't tell which is which). In these cases the space of possible correspondences still seems effectively discrete, rather than being a massive space parameterized as neural networks or something. We'd be totally happy surfacing all of the options in these cases.
There can also be a bunch of inconsequential uncertainty, things that feel more like small deformations of the correspondence than moving to a new connected component in correspondence-space. Things like slightly adjusting the boundaries of objects or of categories.
I'm currently thinking about this in terms of: given two different correspondences, why is it that they manage to both fit the data? Options:
- They are "very close," e.g. they disagree only rarely or make quantitatively similar judgments.
- One of them is a "bad correspondence" and could fit a huge range of possible underlying models, i.e. it's basically introducing the structure we are interested in within the correspondence itself.
- The two correspondences are "not interacting," they aren't competing to explain the same logical facts about the underlying model. (e.g. a big world, one correspondence faces .)
- There is an automorphism of my model of the world (e.g. I could exchange the two twins Eva and Lyn), and can compose a correspondence with that automorphism. (This seems much more likely to happen for poorly-understood parts of the world, like how we talk about new physics, than for simple things like "is there a cat in the room.")
I don't know where all of this ends up, but I feel some pretty strong common-sense intuition like "If you had some humans looking at the model, they could recognize a good correspondence when they saw it" and for now I'm going to be following that to see where it goes.
I tentatively think the whole situation is basically the same for "intuition module outputs a set of premises and then a deduction engine takes it from there" as for a model of physics. That is, it's still the case that (assuming enough richness) the translation between the "intuition module"'s language and human language is going to be more or less pinned down uniquely, and we'll have the same kind of taxonomy over cases where two translations would work equally well.
Here's an example I've been thinking about today to investigate the phenomenon of re-using human models.
Suppose that the "right" way to answer questions is . And suppose that a human is a learned model trained by gradient descent to approximate (subject to architectural and computational constraints). This model is very good on distribution, but we expect it to fail off distribution. We want to train a new neural network to approximate , without inheriting the human's off-distribution failures (though the new network may have off-distribution failures of its own).
The problem is that our model needs to learn the exact parameters for the human model in order to other aspects of human behavior. The simplest case is that we sometimes directly open human brains to observe directly.
Once we've learned it is very easy to learn the question-answering policy . So we're worried that our model will do that rather than learning the additional parameters to implement .
Intuitively there is a strong connection between and . After all, is optimized to make them nearly equal on the training distribution. If you understood the dynamics of neural network training it is likely possible to essentially reconstruct from , i.e. the complexity fo specifying both and is essentially the same as the complexity of specifying only .
But it's completely unclear how to jointly represent and using some parameters of similar size to . So prima facie there is a strong temptation to just reuse .
How much hope is there for jointly representing and ?
The most obvious representation in this case is to first specify , and then actually model the process of gradient descent that produces . This runs into a few problems:
- Actually running gradient descent to find is too expensive to do at every datapoint---instead we learn a hypothesis that does a lot of its work "up front" (shared across all the datapoints). I don't know what that would look like. The naive ways of doing it (redoing the shared initial computation for every batch) only work for very large batch sizes, which may well be above the critical batch size. If this was the only problem I'd feel pretty optimistic about spending a bunch of time thinking about it.
- Specifying "the process that produced " requires specifying the initialization , which is as big as . That said, the fact that the learned also contains a bunch of information about means that it can't contain perfect information about the initialization , i.e. that multiple initializations lead to exactly the same final state. So that suggests a possible out: we can start with an "initial" initialization . Then we can learn by gradient descent. The fact that many different values of would work suggests that it should be easier to find one of them; intuitively if we set up training just right it seems like we may be able to get all the bits back.
- Running the gradient descent to find even a single time may be much more expensive than the rest of training. That is, human learning (perhaps extended over biological or cultural evolution) may take much more time than machine learning. If this the case, then any approach that relies on reproducing that learning is completely doomed.
Similar to problem 2, the mutual information between and the learning process that produced also must be kind of low---there are only bits of mutual information to go around between the learning process, its initialization, and . But exploiting this structure seems really hard, if actually there aren't any fast learning processes that lead to the same conclusion
My current take is that even in the case where was actually produced by something like SGD, we can't actually exploit that fact to produce a direct, causally-accurate representation .
That's kind of similar to what happens in my current proposal though: instead we use the learning process embedded inside the broader world-model learning. (Or a new learning process that we create from fresh to estimate the specialness of , as remarked in the sibling comment.)
So then the critical question is not "do we have enough time to reproduce the learning process that lead to ?" it is "Can we directly learn as an approximation to ?" If we able to do this in any way, then we can use that to help compress . In the other proposal, we can use it to help estimate the specialness of in order to determine how many bits we get back---it's starting to feel like these things aren't so different anyway.
Fully learning the whole human-model seems impossible---after all, humans may have learned things that are more sophisticated then what we can learn with SGD (even if SGD learned a policy with "enough bits" to represent , so that it could memorize them one by one if it saw the brain scans or whatever).
So we could try to do something like "learning just the part of the human policy is that is about answering questions." But it's not clear to me how you could disentangle this from all the rest of the complicated stuff going in for the human.
Overall this seems like a pretty tricky case. The high-level summary is something like: "The model is able to learn to imitate humans by making detailed observations about humans, but we are not able to learn a similarly-good human model from scratch given data about what the human is 'trying' to do or how they interpret language." Under these conditions it seems particularly challenging to either jointly represent and , or to compute how many bits you should "get back" based on a consistency condition between them. I expect it's going to be reasonably obvious what to do in this case (likely exploiting the presumed limitation of our learning process), which is what I'll be thinking about now.
The difficulty of jointly representing and motivates my recent proposal, which avoids any such explicit representation. Instead it separately specifies and , and then "gets back" bits by imposing a consistency condition that would have been satisfied only for a very small fraction of possible 's (roughly of them).
But thinking about this neural network case also makes it easy to talk about why my recent proposal could run into severe computational problems:
- In order to calculate this loss function we need to evaluate how "special" is, i.e. how small is the fraction of 's that are consistent with
- In order to evaluate how special is, we basically need to do the same process of SGD that produces ---then we can compare the actual iterates to all of the places that it could have gone in a different direction, and conclude that almost all of the different settings of the parameters would have been much less consistent with .
- The implicit hope of my proposal is that the outer neural network is learning its human model using something like SGD, and so it can do this specialness-calculation for free---it will be considering lots of different human-models, and it can observe that almost all of them are much less consistent with .
- But the outer neural network could learn to model humans in a very different way, which may not involve representing a serious of iterates of "plausible alternative human models." For example, suppose that in each datapoint we observe a few of the bits of directly (e.g. by looking at a brain scan), and we fill in much of in this way before we ever start making good predictions about human behavior. Then we never need to consider any other plausible human-models.
So in order to salvage a proposal like this, it seems like (at a minimum) the "specialness evaluation" needs to take place separately from the main learning of the human model, using a very different process (where we consider lots of different human models and see that it's actually quite hard to find one that is similarly-consistent with ). This would take place at the point where the outer model started actually using its human model in order to answer questions.
I don't really know what that would look like or if it's possible to make anything like that work.
Suppose I am interested in finding a program M whose input-output behavior has some property P that I can probabilistically check relatively quickly (e.g. I want to check whether M implements a sparse cut of some large implicit graph). I believe there is some simple and fast program M that does the trick. But even this relatively simple M is much more complex than the specification of the property P.
Now suppose I search for the simplest program running in time T that has property P. If T is sufficiently large, then I will end up getting the program "Search for the simplest program running in time T' that has property P, then run that." (Or something even simpler, but the point is that it will make no reference to the intended program M since encoding P is cheaper.)
I may be happy enough with this outcome, but there's some intuitive sense in which something weird and undesirable has happened here (and I may get in a distinctive kind of trouble if P is an approximate evaluation). I think this is likely to be a useful maximally-simplified example to think about.
The speed prior is calibrated such that this never happens if the learned optimizer is just using brute force---if it needs to search over 1 extra bit then it will take 2x longer, offsetting the gains.
That means that in the regime where P is simple, the speed prior is the "least you can reasonably care about speed"---if you care even less, you will just end up pushing the optimization into an inner process that is more concerned with speed and is therefore able to try a bunch of options.
(However, this is very mild, since the speed prior cares only a tiny bit about speed. Adding 100 bits to your program is the same as letting it run 2^100 times longer, so you are basically just optimizing for simplicity.)
To make this concrete, suppose that I instead used the kind-of-speed prior, where taking 4x longer is equivalent to using 1 extra bit of description complexity. And suppose that P is very simple relative to the complexities of the other objects involved. Suppose that the "object-level" program M has 1000 bits and runs in 2^2000 time, so has kind-of-speed complexity 2000 bits. A search that uses the speed prior will be able to find this algorithm in 2^3000 time, and so will have a kind-of-speed complexity of 1500 bits. So the kind-of-speed prior will just end up delegating to the speed prior.
The speed prior still delegates to better search algorithms though. For example, suppose that someone is able to fill in a 1000 bit program using only 2^500 steps of local search. Then the local search algorithm has speed prior complexity 500 bits, so will beat the object-level program. And the prior we'd end up using is basically "2x longer = 2 more bits" instead of "2x longer = 1 more bit," i.e. we end up caring more about speed because we delegated.
The actual limit on how much you care about speed is given by whatever search algorithms work best. I think it's likely possible to "expose" what is going on to the outer optimizer (so that it finds a hypothesis like "This local search algorithm is good" and then uses it to find an object-level program, rather than directly finding a program that bundles both of them together). But I'd guess intuitively that it's just not even meaningful to talk about the "simplest" programs or any prior that cares less about speed than the optimal search algorithm.
I think multi-level search may help here. To the extent that you can get a lower-confidence estimate of P much more quickly, you can budget your total search time such that you examine many programs and then re-examine only the good candidates. If your confidence is linear with time/complexity of evaluation, this probably doesn't help.
This is interesting to me for two reasons:
- [Mainly] Several proposals for avoiding the instrumental policy work by penalizing computation. But I have a really shaky philosophical grip on why that's a reasonable thing to do, and so all of those solutions end up feeling weird to me. I can still evaluate them based on what works on concrete examples, but things are slippery enough that plan A is getting a handle on why this is a good idea.
- In the long run I expect to have to handle learned optimizers by having the outer optimizer instead directly learn whatever the inner optimizer would have learned. This is an interesting setting to look at how that works out. (For example, in this case the outer optimizer just needs to be able to represent the hypothesis "There is a program that has property P and runs in time T' " and then do its own search over that space of faster programs.)
In traditional settings, we are searching for a program M that is simpler than the property P. For example, the number of parameters in our model should be smaller than the size of the dataset we are trying to fit if we want the model to generalize. (This isn't true for modern DL because of subtleties with SGD optimizing imperfectly and implicit regularization and so on, but spiritually I think it's still fine..)
But this breaks down if we start doing something like imposing consistency checks and hoping that those change the result of learning. Intuitively it's also often not true for scientific explanations---even simple properties can be surprising and require explanation, and can be used to support theories that are much more complex than the observation itself.
Some thoughts:
- It's quite plausible that in these cases we want to be doing something other than searching over programs. This is pretty clear in the "scientific explanation" case, and maybe it's the way to go for the kinds of alignment problems I've been thinking about recently.
A basic challenge with searching over programs is that we have to interpret the other data. For example, if "correspondence between two models of physics" is some kind of different object like a description in natural language, then some amplified human is going to have to be thinking about that correspondence to see if it explains the facts. If we search over correspondences, some of them will be "attacks" on the human that basically convince them to run a general computation in order to explain the data. So we have two options: (i) perfectly harden the evaluation process against such attacks, (ii) try to ensure that there is always some way to just directly do whatever the attacker convinced the human to do. But (i) seems quite hard, and (ii) basically requires us to put all of the generic programs in our search space.
- It's also quite plausible that we'll just give up on things like consistency conditions. But those come up frequently enough in intuitive alignment schemes that I at least want to give them a fair shake.
Just spit-balling here, but it seems that T' will have to be much smaller than T in order for the inner search to run each candidate program (multiple times for statistical guarantees) up to T' to check whether it satisfies P. Because of this, you should be able to just run the inner search and see what it comes up with (which, if it's yet another search, will have an even shorter run time) and pretty quickly (relative to T) find the actual M.
Causal structure is an intuitively appealing way to pick out the "intended" translation between an AI's model of the world and a human's model. For example, intuitively "There is a dog" causes "There is a barking sound." If we ask our neural net questions like "Is there a dog?" and it computes its answer by checking "Does a human labeler think there is a dog?" then its answers won't match the expected causal structure---so maybe we can avoid these kinds of answers.
What does that mean if we apply typical definitions of causality to ML training?
- If we define causality in terms of interventions, then this helps iff we have interventions in which the labeler is mistaken. In general, it seems we could just include examples with such interventions in the training set.
- Similarly, if we use some kind of closest-possible-world semantics, then we need to be able to train models to answer questions consistently about nearby worlds in which the labeler is mistaken. It's not clear how to train a system to do that. Probably the easiest is to have a human labeler in world X talking about what would happen in some other world Y, where the labeling process is potentially mistaken. (As in "decoupled rl" approaches.) However, in this case it seems liable to learn the "instrumental policy" that asks "What does a human in possible world X think about what would happen in world Y?" which seems only slightly harder than the original.
- We could talk about conditional independencies that we expect to remain robust on new distributions (e.g. in cases where humans are mistaken). I'll discuss this a bit in a reply.
Here's an abstract example to think about these proposals, just a special case of the example from this post.
- Suppose that reality M is described as a causal graph X --> A --> B --> C, and then the observation Y is a function of (A, B, C).
- The human's model M' of the situation is X --> A' --> B' --> C'. Each of them is a coarse-graining of the corresponding part of the real world model, and the observation Y is still a function of (A', B', C'), it's just more uncertain now.
- The coarse-grained dynamics are simpler than the actual coarse-graining f: (A, B, C) --> (A', B', C').
- We prepare a dataset by actually sampling (X, A, B, C, Y) from M, having humans look at it, make inferences about (A', B', C'), and get a dataset of (X, A', B', C', Y) tuples to train a model.
- The intended question-answering function is to use M to sample (A, B, C, Y) then apply the coarse-graining f to get (A', B', C'). But there is also a bad function that produces good answers on the training dataset: use M to sample (A, B, C, Y), then use the human's model to infer (A', B', C'), and output those.
- We'd like to rule out this bad function by making some kind of assumption about causal structure.
This is also a way to think about the proposals in this post and the reply:
- The human believes that A' and B' are related in a certain way for simple+fundamental reasons.
- On the training distribution, all of the functions we are considering reproduce the expected relationship. However, the reason that they reproduce the expected relationship is quite different.
- For the intended function, you can verify this relationship by looking at the link (A --> B) and the coarse-graining applied to A and B, and verify that the probabilities work out. (That is, I can replace all of the rest of the computational graph with nonsense, or independent samples, and get the same relationship.)
- For the bad function, you have to look at basically the whole graph. That is, it's not the case that the human's beliefs about A' and B' have the right relationship for arbitrary Ys, they only have the right relationship for a very particular distribution of Ys. So to see that A' and B' have the right relationship, we need to simulate the actual underlying dynamics where A --> B, since that creates the correlations in Y that actually lead to the expected correlations between A' and B'.
- It seems like we believe not only that A' and B' are related in a certain way, but that the relationship should be for simple reasons, and so there's a real sense in which it's a bad sign if we need to do a ton of extra compute to verify that relationship. I still don't have a great handle on that kind of argument. I suspect it won't ultimately come down to "faster is better," though as a heuristic that seems to work surprisingly well. I think that this feels a bit more plausible to me as a story for why faster would be better (but only a bit).
- It's not always going to be quite this cut and dried---depending on the structure of the human beliefs we may automatically get the desired relationship between A' and B'. But if that's the case then one of the other relationships will be a contingent fact about Y---we can't reproduce all of the expected relationships for arbitrary Y, since our model presumably makes some substantive predictions about Y and if those predictions are violated we will break some of our inferences.
So are there some facts about conditional independencies that would privilege the intended mapping? Here is one option.
We believe that A' and C' should be independent conditioned on B'. One problem is that this isn't even true, because B' is a coarse-graining and so there are in fact correlations between A' and C' that the human doesn't understand. That said, I think that the bad map introduces further conditional correlations, even assuming B=B'. For example, if you imagine Y preserving some facts about A' and C', and if the human is sometimes mistaken about B'=B, then we will introduce extra correlations between the human's beliefs about A' and C'.
I think it's pretty plausible that there are necessarily some "new" correlations in any case where the human's inference is imperfect, but I'd like to understand that better.
So I think the biggest problem is that none of the human's believed conditional independencies actually hold---they are both precise, and (more problematically) they may themselves only hold "on distribution" in some appropriate sense.
This problem seems pretty approachable though and so I'm excited to spend some time thinking about it.
Actually if A --> B --> C and I observe some function of (A, B, C) it's just not generally the case that my beliefs about A and C are conditionally independent given my beliefs about B (e.g. suppose I observe A+C). This just makes it even easier to avoid the bad function in this case, but means I want to be more careful about the definition of the case to ensure that it's actually difficult before concluding that this kid of conditional independence structure is potentially useful.
Sometimes we figure out the conditional in/dependence by looking at the data. It may not match common sense intuition, but if your model takes that into account and gives better results, then they just keep the conditional independence in there. You are only able to do with what you have. Lack of attributes may force you to rely on other dependencies for better predictions.
Conditional probability should be reflected if given enough data points. When you introduce human labeling into the equation, you are adding another uncertainty about the accuracy of the human doing the labeling, regardless whether the inaccuracy came from his own false sense of conditional independence. Usually human labeling don't directly take into account of any conditional probability to not mess with the conditionals that exist within the data set. That's why the more data the better, which also means the more labelers you have the less dependent you are on the inaccuracy of any individual human.
The conditional probability assumed in the real world carries over to the data representation world simply because it's trying to model the same phenomenon in the real world, despite it's coarse grained nature. Without the conditional probability, we wouldn't be able to make the same strong inferences that match up to the real world. The causality is part of the data. If you use a different casual relationship, the end model would be different, and you would be solving a very different problem than if you applied the real world casual relationship.