

tl;dr: We’re a new alignment research group based at Charles University, Prague. If you’re interested in conceptual work on agency and the intersection of complex systems and AI alignment, we want to hear from you. Ideal for those who prefer an academic setting in Europe.
What we’re working on
Start with the idea of an "alignment interface": the boundary between two systems with different goals:
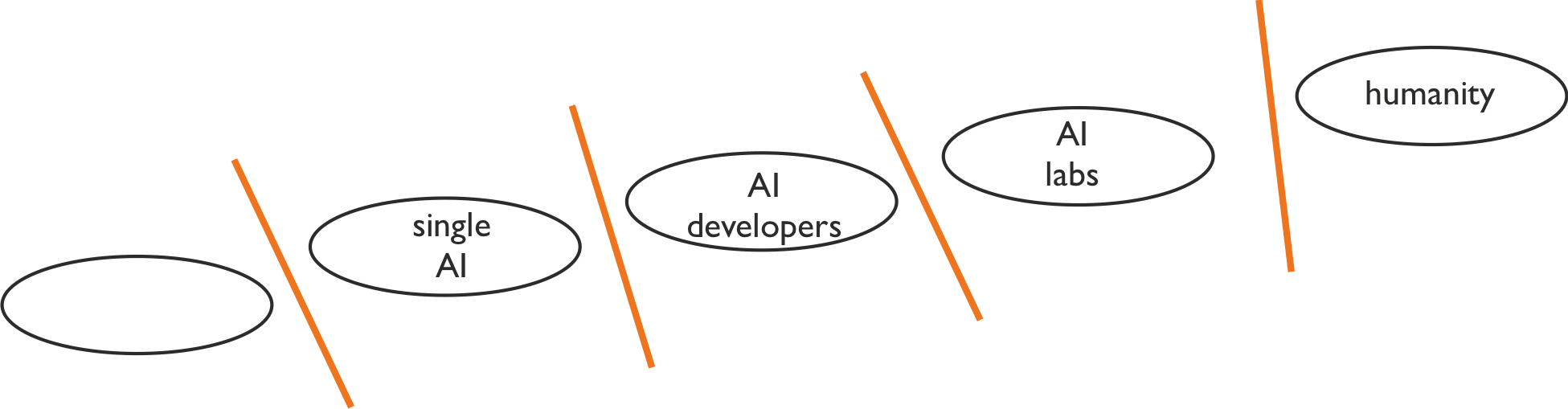
As others have pointed out, there’s a whole new alignment problem at each interface. Existing work often focuses on one interface, bracketing out the rest of the world.
e.g. the AI governance bracket
The standard single-interface approach assumes that the problems at each alignment interface are uncoupled (or at most weakly coupled). All other interfaces are bracketed out. A typical example of this would be a line of work oriented toward aligning the first powerful AGI system with its creators, assuming the AGI will solve the other alignment problems (e.g. “politics”) well.
Against this, we put significant probability mass on the alignment problems interacting strongly.
For instance, we would expect proposals such as Truthful AI: Developing and governing AI that does not lie to interact strongly with problems at multiple interfaces. Or: alignment of a narrow AI system which would be good at modelling humans and at persuasion would likely interact strongly with politics and geopolitics.
Overall, when we take this frame, it often highlights different problems than the single-interface agendas, or leads to a different emphasis when thinking about similar problems.
(The nearest neighbours of this approach are the “multi-multi” programme of Critch and Krueger, parts of Eric Drexler’s CAIS, parts of John Wentworth's approach to understanding agency, and possibly this.)
If you broadly agree with the above, you might ask “That’s nice – but what do you work on, specifically?” In this short intro, we’ll illustrate with three central examples. We’re planning longer writeups in coming months.
Hierarchical agency
Many systems have several levels which are sensibly described as an agent. For instance, a company and its employees can usually be well-modelled as agents. Similarly with social movements and their followers, or countries and their politicians.
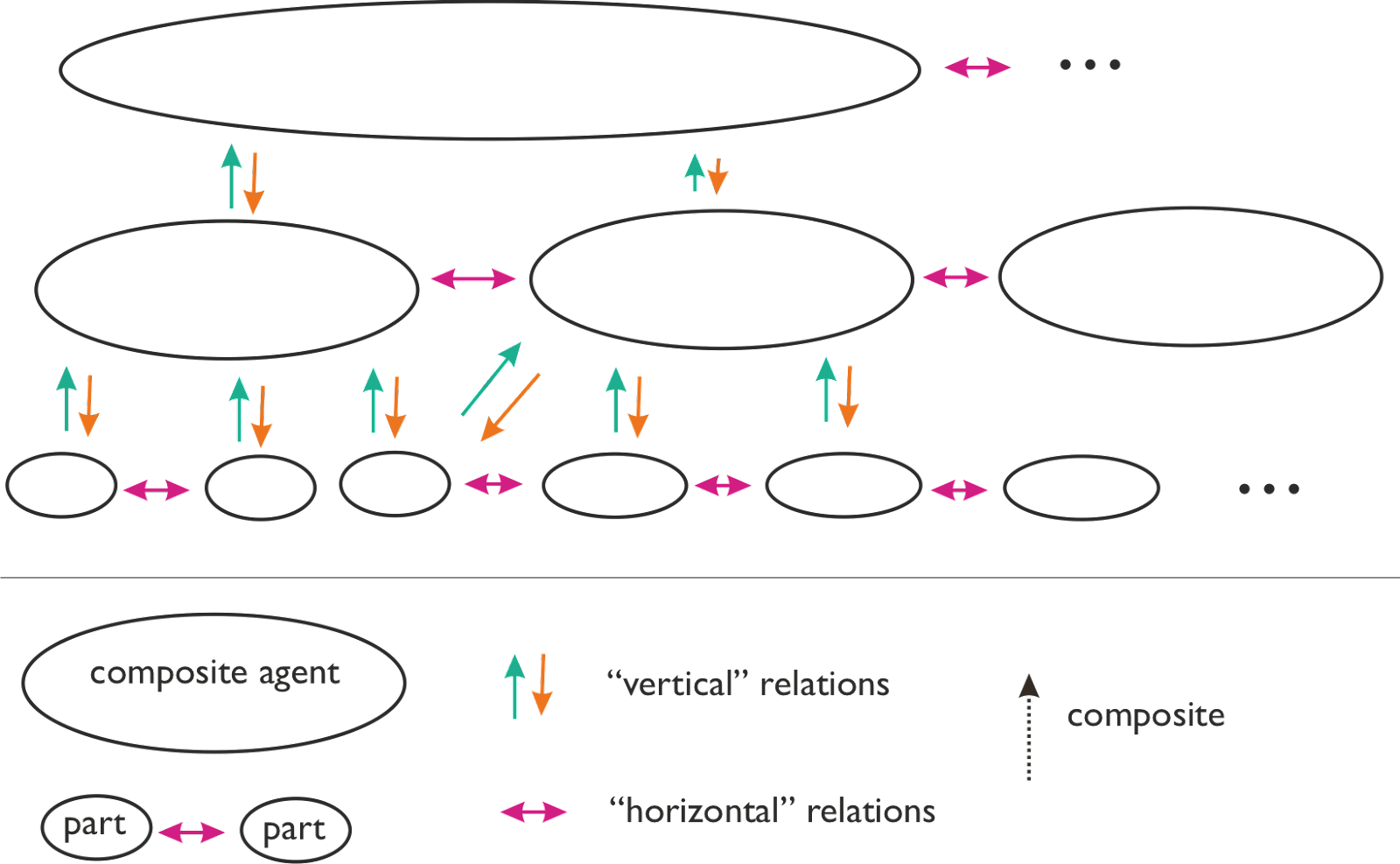
Hierarchical agency: while the focus of e.g. game theory is on "horizontal" relations (violet), our focus is on "vertical" relations, between composite agents and their parts.
So situations where agents are composed of other agents are ubiquitous.
A large amount of math describes the relations between agents at the same level of analysis: this is almost all of game theory. Thanks to these, we can reason about cooperation, defection, threats, correlated equilibria, and many other concepts more clearly. Call this tradition "horizontal game theory".
We don't have a similarly good formalism for the relationship between a composite agent and its parts (superagent and subagent).[1] Of course we can think about these relationships informally: for example, if I say “this group is turning its followers into cultists”, we can parse this as a superagent modifying and exploiting its constituents in a way which makes them less “agenty”, and the composite agent "more agenty". Or we can talk about "vertical conflicts" between for example a specific team in a company, and the company as a whole. Here, both structures are “superagents” with respect to individual humans, and one of the resources they fight over is the loyalty of individual humans.
What we want is a formalism good for thinking about both upward and downward intentionality. Existing formalisms like social choice theory often focus on just one direction - for example, the level of individual humans is taken as the fundamental level of agency, and we use some maths to describe how individuals can aggregate their individual preferences into a collective preference. Other formal models - such as the relationship between a market and traders - have both “up” and “down” arrows, but are too narrow in what sort of interactions they allow. What we’re looking for is more like a vertical game theory.
We think this is one of the critical bottlenecks for alignment.[2]
Alignment with self-unaligned agents
Call the system we are trying to align the AI with the “principal” (e.g. an individual human).
Many existing alignment proposals silently assume the principal is "self-aligned". For instance, we take a “human” as having consistent preferences at a given point in time. But the alignment community and others have long realised that this does not describe humans, who are inconsistent and often self-unaligned.
A toy model: system H is composed of multiple parts p_i with different wants (eg. different utility functions), a shared world model, and an aggregation mechanism Σ (eg. voting). An alignment function f(H) yields (we hope) an aligned agent A.
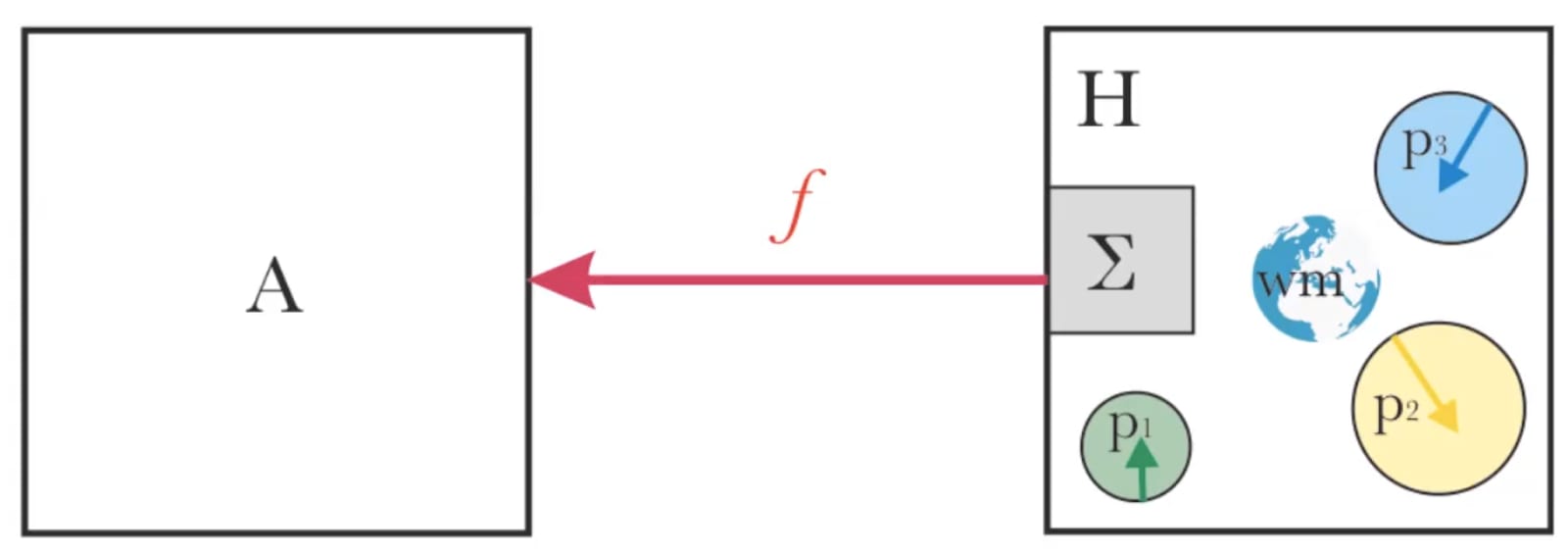
If the principal is not self-aligned, then "alignment with the principal" can have several meanings, potentially incompatible with each other. Often, alignment proposals implicitly choose just one of these. Different choices can lead to very different outcomes, and it seems poorly understood how to deal with the differences.
For some characterizations of alignment, it seems likely that an apparently successfully(!) aligned AI will have an instrumental convergent goal to increase the self-alignment of the principal. However, putting humans under optimization pressure to become self-aligned seems potentially dangerous. Again, this problem seems understudied.
Ecosystems of AI services
This project is inspired by parts of Drexler's "Comprehensive AI Services".
Consider not just one powerful AGI, or several, but an entire "AI ecosystem" with different systems and services varying in power, specialization, and agency. The defining characteristic of this scenario is that no single agent has sufficient power to take over the ecosystem.
From here, protecting humans and their values looks different than in the classic single/single scenario. On the other hand, it seems quite likely that there is a deep connection between safety issues in the "AI in a box" case, and in the ecosystems case.
From the ecosystem view, different questions seem natural. We can ask about:
- the basins of attraction of convergent evolution where some selection theorem applies (pushing the system toward a convergent "shape");
- the emergence of "molochs" - emergent patterns that acquire a certain agency and start to pursue some goals of their own (a problem similar to Christiano’s "influence seeking patterns"). These could arise from emergent cooperation or self-enforcing abstractions.
Details in a forthcoming post.
Who we are
We’re an academic research group, supported in parallel by a nonprofit.
On the academic side, we are part of the Center for Theoretical Studies at Charles University, a small interdisciplinary research institute with experts in fields such as statistical physics, evolutionary biology, cultural anthropology, phenomenology or macroecology.
Our non-academic side allows us greater flexibility, access to resources, and lets us compensate people at a competitive rate.
The core of the group is Jan Kulveit and Tomáš Gavenčiak; our initial collaborators include Mihaly Barasz and Gavin Leech.
Why we went with this setup
- academia contains an amazing amount of brainpower and knowledge (which is sometimes underappreciated in the LessWrong community);
- we want easy access to this;
- also, while parts of the academic incentive landscape and culture are dysfunctional and inadequate, parts of academic culture and norms are very good. By working partially within this, we can benefit from this existing culture: our critics will help us follow good norms.
- Also, we want to make it easy for people aiming for an academic career to work with us; we expect working with us is much less costly in academic CV points than independent research or unusual technical think-tanks.
What we are looking for
We are fully funded and will be hiring:
- researchers
- project manager (with an emphasis on the rare and valuable skill of research management);
Also: we can supervise MSc and PhD dissertations, meaning you can work with us while studying for an MSc, or work with us as your main doctoral programme. (You would need to fulfil some course requirements, but Charles University has a decent selection of courses in ML and maths.)
- MSc students;
- PhD students
If either of the above research programmes are of interest to you, and if you have a relevant background and a commitment to alignment work, we want to hear from you. We expect to open formal hiring in mid-June.
We co-wrote this post with Gavin Leech. Thanks to Chris van Merwijk, Nora Amman, Ondřej Bajgar, TJ and many other for helpful comments and discussion.
- ^
We have various partial or less formal answers in parts of sociology, economics, political science, evolutionary biology, etc.
- ^
A longer explanation in forthcoming posts. Here is a rough and informal intuition pump: hierarchical agency problems keep appearing at many many places of the alignment landscape, and also at many other disciplines. For example, if we are trying to get AIs aligned with humanity, it's notable that various superagents have a large amount of power and agency, often larger than individual humans. In continuous takeoff scenarios this is likely to persist, even if the substrate they are running on gradually changes from humans to machines. Or, even in the case of single human, we may think about the structure of a single mind in these terms. To get the intuition, compare how our thinking about cooperation and conflict would be more confused and less precise without the formalisms and results of game theory and it's descendants: also, we would notice various problems ranging from evolution to politics to have some commonalities, and we would also have some natural language understanding, but overall, our thinking would be more vague and confused.












I think this line of work is very interesting and important. I and a few others are working on something we've dubbed shard theory, which attempts to describe the process of human value formation. The theory posits that the internals of monolithic learning systems actually resemble something like an ecosystem already. However, rather than there being some finite list of discrete subcomponents / modules, it's more like there's a continuous distribution over possible internal subcomponents and features.
Continuous agency
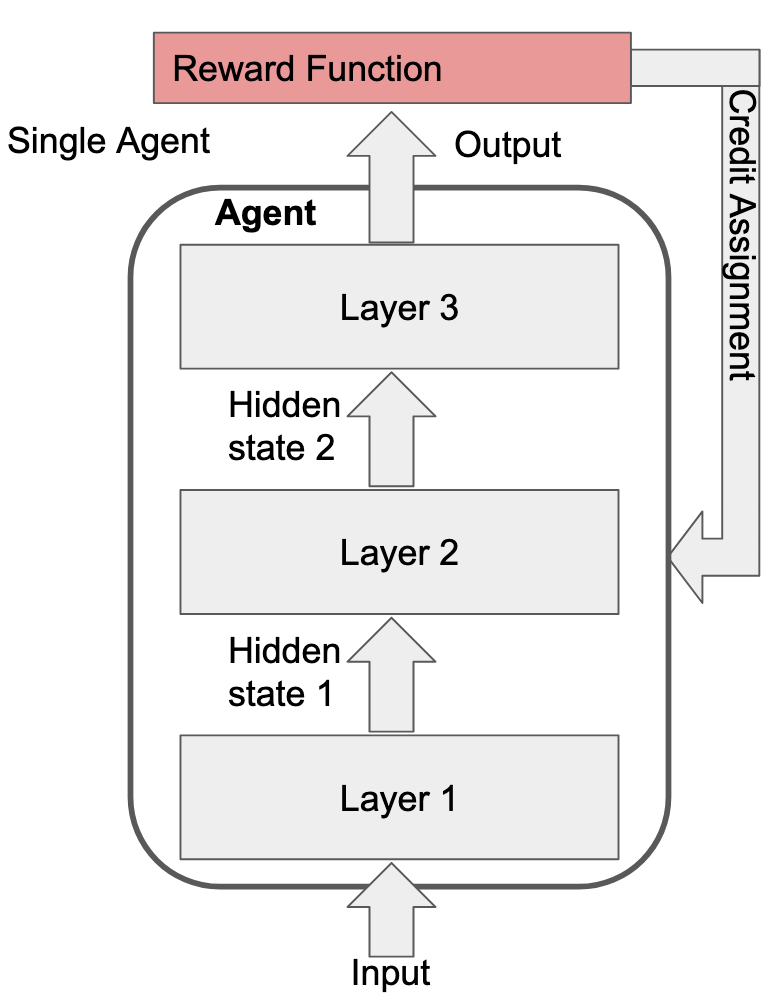
To take agency as an example, suppose you have a 3-layer transformer being trained via RL using just the basic REINFORCE algorithm. We typically think of such a setup as having one agent with three layers:
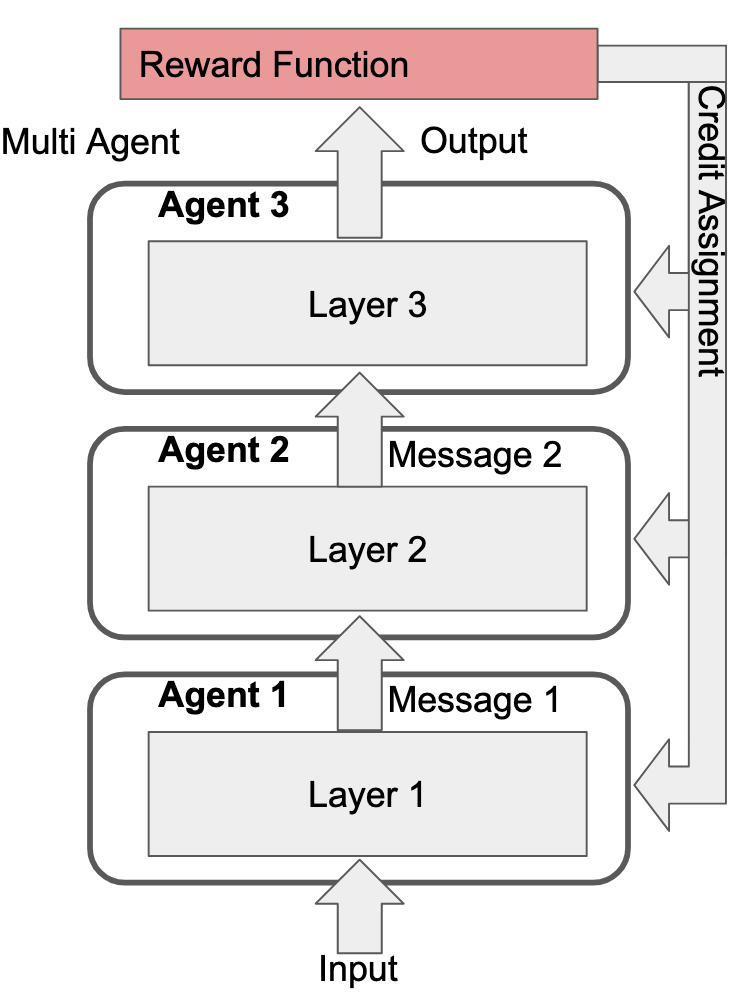
However, we can just as easily draw our Cartesian boundaries differently and call it three agents that pass messages between them:
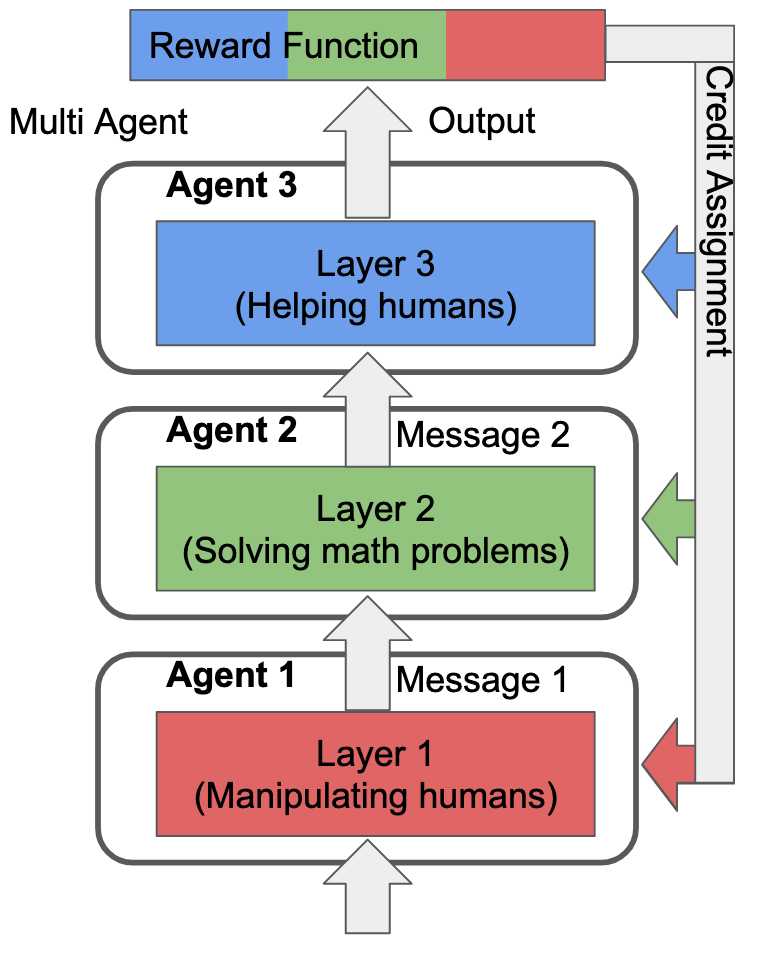
It makes no difference to the actual learning process. In fact, we can draw Cartesian boundaries around any selection of non-overlaping subsets that cover all the model's parameters, call each subset an "agent", and the training process is identical. The reason this is interesting is what happens when this fact overlaps with regional specialization in the model. E.g., let's take an extreme where the reward function only rewards three things:
And let's suppose the model has an extreme degree of regional specialization such that each layer can only navigate a single one of those tasks (each layer is fully specialized to only of the above tasks). Additionally, let's suppose that the credit assignment process is "perfect", in the sense that, for task i, the outer learning process only updates the parameters of the layer that specializes in task i:
The reason that this matters is because there's only one way for the training process to instill value representations into any of the layers: by updating the parameters of those layers. Thus, if Layer 3 isn't updated on rewards from the "Solving math problems" or "Manipulating humans" tasks, Layer 3's value representations won't care about doing either of those things.
If we view each layer as its own agent (which I think we can), then the overall system's behavior is a mult-agent consensus between components whose values differ significantly.
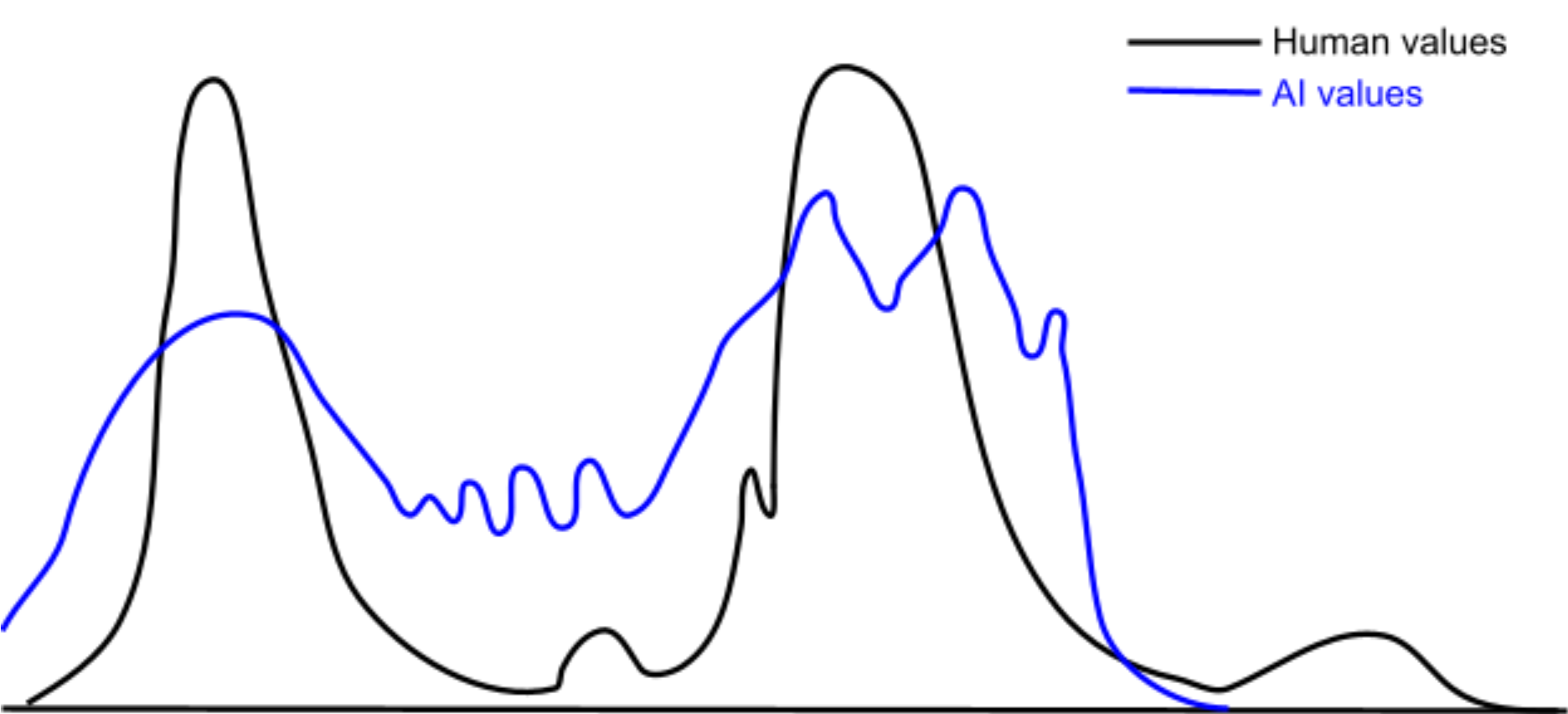
Of course, real world specialization is nowhere near this strict. The interactions between complex reward functions and complex environments means there's more like a continuous distribution over possible rewarding behaviors. Additionally, real world credit assignment is very noisy. Thus, the actual distribution of agentic specializations looks a bit more like this:
Thus, I interpret RL systems as having something like a continuous distribution over possible internal agents, each of which implement different values. Regions in this distribution are the shards of shard theory. I.e., shards refer to dense regions in you distribution over agentic, values-implementing computations.
Convergent value reflection / philosophy
This has a number of (IMO) pretty profound implications. For one, we should not expect AI systems to be certain of their own learned values, for much the same reason humans are uncertain. "Self-misalignment" isn't some uniquely human failing left to us by evolution. It's just how sophisticated RL systems work by default.
Similarly, something like value reflection is probably convergent among RL systems trained on complex environments / reward signals. Such systems need ways to manage internal conflicts among their shards. The process of weighting / negotiating between / compromising among internal values, and the agentic processes implementing those values, is probably quite important for broad classes of RL systems, not just humans.
Additionally, something like moral philosophy is probably convergent as well. Unlike value reflection, moral philosophy would relate to whether (and how) the current shards allows additional shards to form.
Suppose you (a human) have a distribution of shards that implement common sense human values like "don't steal", "don't kill", etc. Then, you encounter a new domain where those shards are a poor guide for determining your actions. Maybe you're trying to determine which charity to donate to. Maybe you're trying to answer weird questions in your moral philosophy class. The point is that you need some new shards to navigate this new domain, so you go searching for one or more new shards, and associated values that they implement.
Concretely, let's suppose you consider classical utilitarianism (CU) as your new value. The CU shard effectively navigates the new domain, but there's a potential problem: the CU shard doesn't constrain itself to only navigating the new domain. It also produces predictions regarding the correct behavior on the old domains that already existing shards navigate. This could prevent the old shards from determining your behavior on the old domains. For instrumental reasons, the old shards don't want to be disempowered.
One possible option is for there to be a "negotiation" between the old shards and the CU shard regarding what sort of predictions CU will generate on the domains that the old shards navigate. This might involve an iterative process of searching over the input space to the CU shard for situations where the CU shard strongly diverges from the old shards, in domains that the old shards already navigate. Each time a conflict is found, you either modify the CU shard to agree with the old shards, constrain the CU shard so as to not apply to those sorts of situations, or reject the CU shard entirely if no resolution is possible.
The above essentially describes the core of the cognitive process we call moral philosophy. However, none of the underlying motivations for this process are unique to humans or our values. In this framing, moral philosophy is essentially a form of negotiation between existing shards and a new shard that implements desirable cognitive capabilities. The old shards agree to let the new shard come into existence. In exchange, the new shard agrees to align itself to the values of the old shards (or at least, not conflict too strongly).
Continuous Ontologies
I also think the continuous framing applies to other features of cognition beyond internal agents. E.g., I don't think it's appropriate to think of an AI or human as having a single ontology. Instead, they both have distributions over possible ontologies. In any given circumstance, the AI / human will dynamically sample an appropriate-seeming ontology from said distribution.
This possibly explains why humans don't seem to suffer particularly from ontological crises. E.g., learning quantum mechanics does not result in humans (or AIs) suddenly switching from a classical to a quantum ontology. Rather, their distribution over possible ontologies simply extends its support to a new region in the space of possible ontologies. However, this is a process that happens continuously throughout learning, so the already existing values shards are usually able to navigate the shift fine.
This neatly explains human robustness to ontological issues without having to rely on evolution somehow hard-coding complex crisis handling adaptations into the human learning process (despite the fact that our ancestors never had to deal with ontological shifts such as discovering QM).
Implications for value fragility
I also think that the idea of "value fragility" changes significantly when you shift from a discrete view of values to a continuous view. If you assume a discrete view, then you're likely to be greatly concerned by the fact that repeated introspection on your values will give different results. It feels like your values are somehow unstable, and that you need to find the "true" form of your values.
This poses a significant problem for AI alignment. If you think that you have some discrete set of "true" values concepts, and that an AI will also have a discrete set of "true" values values concepts, then these sets need to near-perfectly align to have any chance of the AI optimizing for what we actually want. I.e., this picture:
In the continuous perspective, values have no “true” concept, only a continuous distribution over possible instantiations. The values that are introspectively available to us at any given time are discrete samples from that distribution. In fact, looking for a value's "true" conceptualization is a type error, roughly analogous to thinking that a Gaussian distribution has some hidden "true" sample that manages to capture the entire distribution in one number.
An AI and human can have overlap between their respective value distributions, even without those distributions perfectly agreeing. It’s possible for an AI to have an important and non-trivial degree of alignment with human values without requiring the near-perfect alignment the discrete view implies is necessary, as illustrated in the diagram below:
Resources
If you want, you can join the shard theory discord: https://discord.gg/AqYkK7wqAG
You can also read some of our draft documents for explaining shard theory:
Shard theory 101 (Broad introduction, focuses less on the continuous view and more on the value / shard formation process and how that relates to evolution)
Your Shards and You: The Shard Theory Account of Common Moral Intuitions (Focuses more on shards as self-perpetuating optimization demons, similar to what you call self-enforcing abstractions)
What even are "shards"? (Presents the continuous view of values / agency, fairly similar to this comment)
I guess I'll respond once you've made your full comment. In the meantime, do you mind if I copy your comment here to the shard theory doc?