Scaling inference
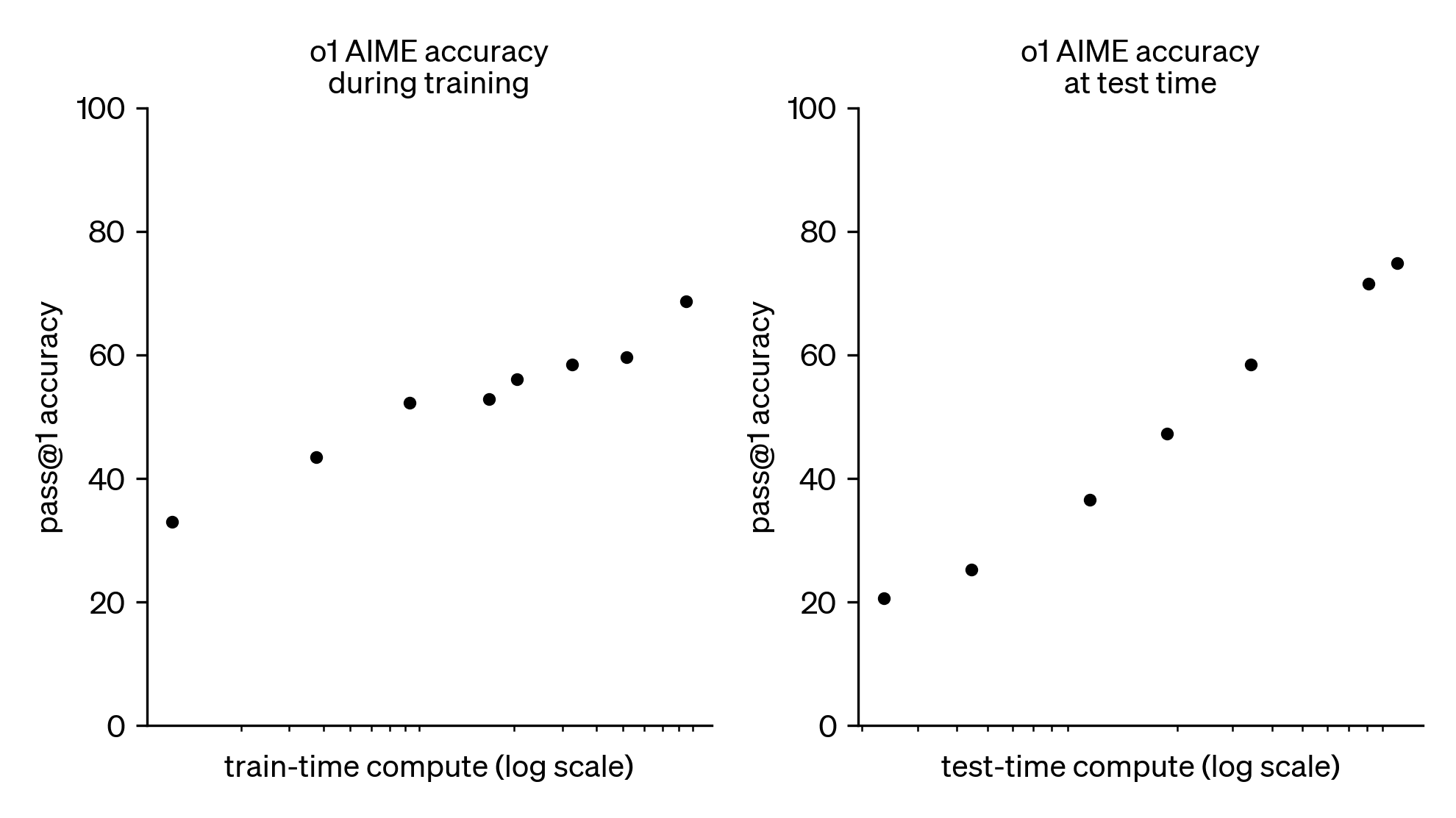
With the release of OpenAI's o1 and o3 models, it seems likely that we are now contending with a new scaling paradigm: spending more compute on model inference at run-time reliably improves model performance. As shown below, o1's AIME accuracy increases at a constant rate with the logarithm of test-time compute (OpenAI, 2024).
OpenAI's o3 model continues this trend with record-breaking performance, scoring:
- 2727 on Codeforces, which makes it the 175th best competitive programmer on Earth;
- 25% on FrontierMath, where "each problem demands hours of work from expert mathematicians";
- 88% on GPQA, where 70% represents PhD-level science knowledge;
- 88% on ARC-AGI, where the average Mechanical Turk human worker scores 75% on hard visual reasoning problems.
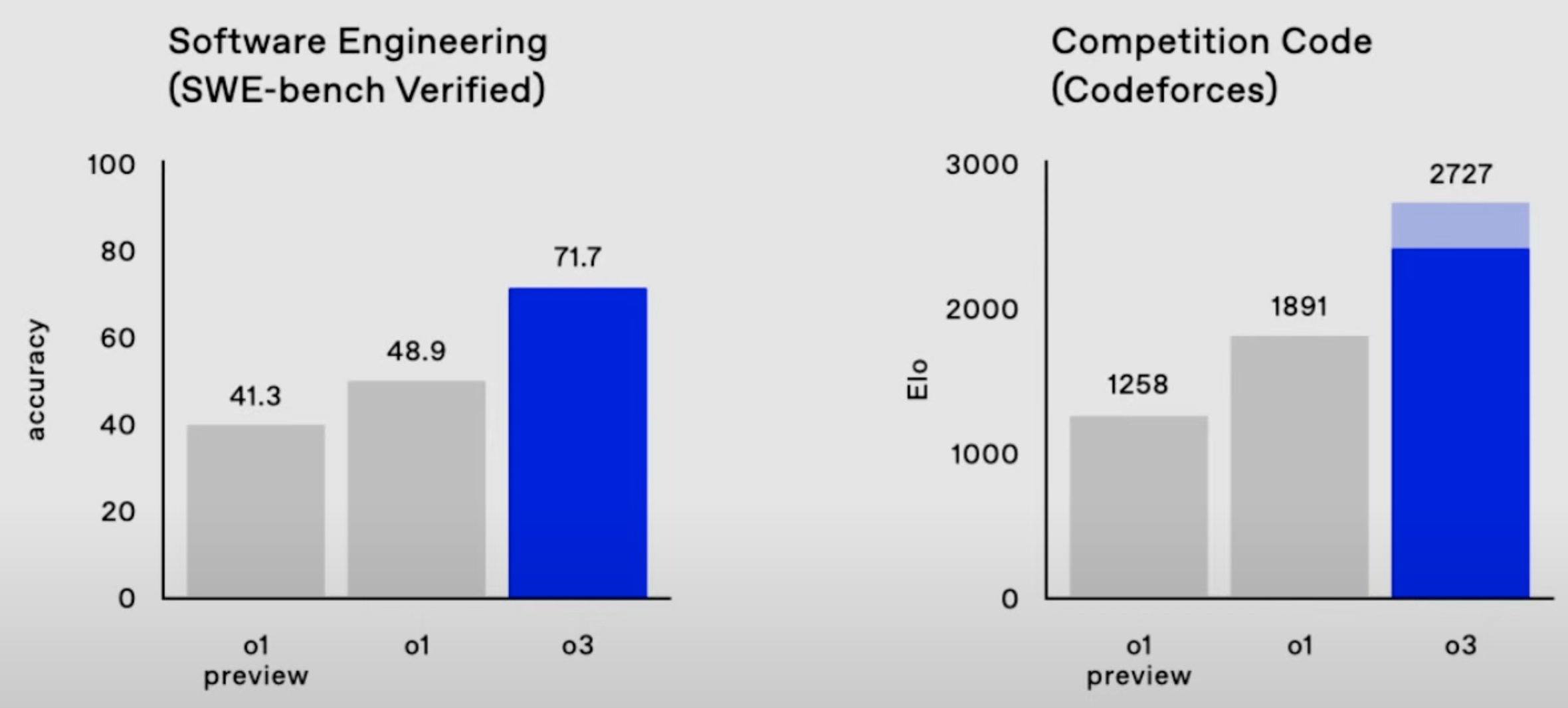
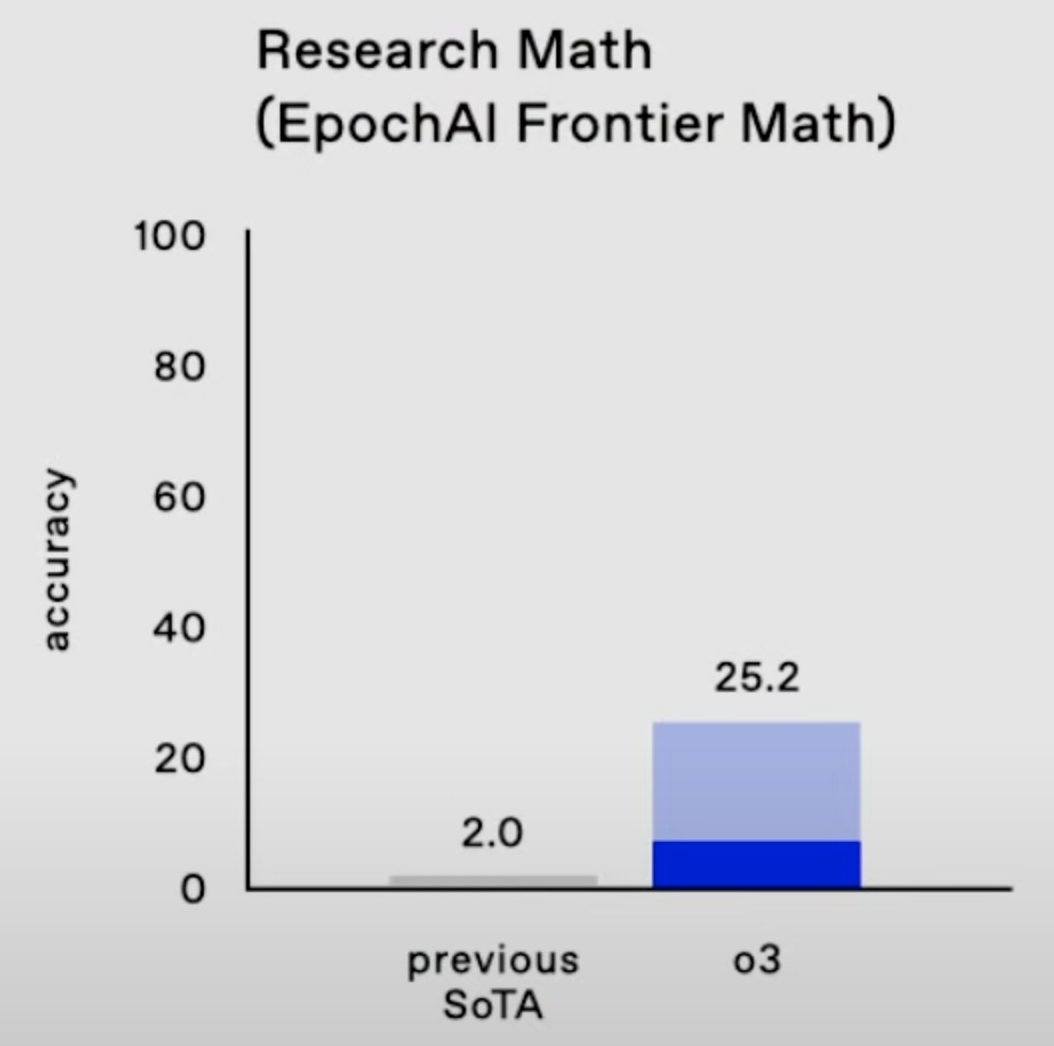
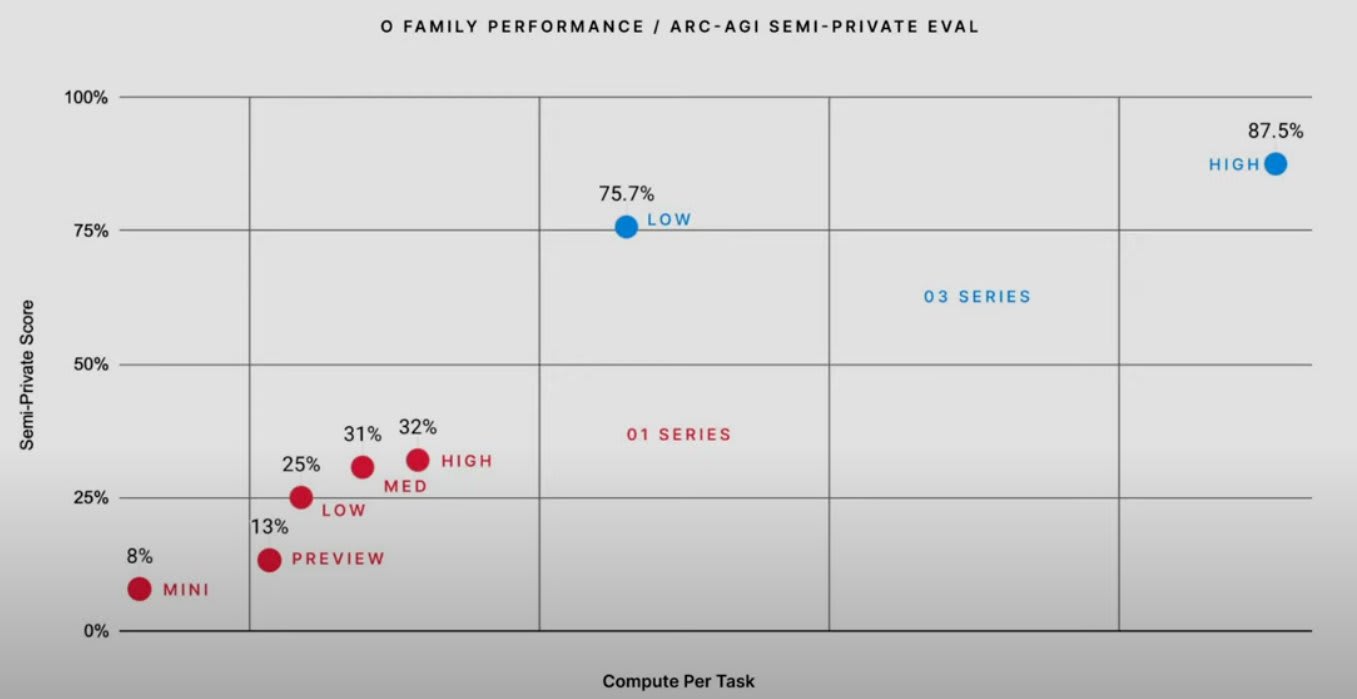
According to OpenAI, the bulk of model performance improvement in the o-series of models comes from increasing the length of chain-of-thought (and possibly further techniques like "tree-of-thought") and improving the chain-of-thought (CoT) process with reinforcement learning. Running o3 at maximum performance is currently very expensive, with single ARC-AGI tasks costing ~$3k, but inference costs are falling by ~10x/year!
A recent analysis by Epoch AI indicated that frontier labs will probably spend similar resources on model training and inference.[1] Therefore, unless we are approaching hard limits on inference scaling, I would bet that frontier labs will continue to pour resources into optimizing model inference and costs will continue to fall. In general, I expect that the inference scaling paradigm is probably here to stay and will be a crucial consideration for AGI safety.
AI safety implications
So what are the implications of an inference scaling paradigm for AI safety? In brief I think:
- AGI timelines are largely unchanged, but might be a year closer.
- There will probably be less of a deployment overhang for frontier models, as they will cost ~1000x more to deploy than expected, which reduces near-term risks from speed or collective superintelligence.
- Chain-of-thought oversight is probably more useful, conditional on banning non-language CoT, and this is great for AI safety.
- Smaller models that are more expensive to run are easier to steal, but harder to do anything with unless you are very wealthy, reducing the unilateralist's curse.
- Scaling interpretability might be easier or harder; I'm not sure.
- Models might be subject to more RL, but this will be largely "process-based" and thus probably safer, conditional on banning non-language CoT.
- Export controls will probably have to adapt to handle specialized inference hardware.
AGI timelines
Interestingly, AGI timeline forecasts have not changed much with the advent of o1 and o3. Metaculus' "Strong AGI" forecast seems to have dropped by 1 year to mid-2031 with the launch of o3; however, this forecast has fluctuated around 2031-2033 since March 2023. Manifold Market's "AGI When?" market also dropped by 1 year, from 2030 to 2029, but this has been fluctuating lately too. It's possible that these forecasting platforms were already somewhat pricing in the impacts of scaling inference compute, as chain-of-thought, even with RL augmentation, is not a new technology. Overall, I don't have any better take than the forecasting platforms' current predictions.
Deployment overhang
In Holden Karnofsky's "AI Could Defeat All Of Us Combined" a plausible existential risk threat model is described, in which a swarm of human-level AIs outmanoeuvre humans due to AI's faster cognitive speeds and improved coordination, rather than qualitative superintelligence capabilities. This scenario is predicated on the belief that "once the first human-level AI system is created, whoever created it could use the same computing power it took to create it in order to run several hundred million copies for about a year each." If the first AGIs are as expensive to run as o3-high (costing ~$3k/task), this threat model seems much less plausible. I am consequently less concerned about a "deployment overhang," where near-term models can be cheaply deployed to huge impact once expensively trained. This somewhat reduces my concern regarding "collective" or "speed" superintelligence, while slightly elevating my concern regarding "qualitative" superintelligence (see Superintelligence, Bostrom), at least for first-generation AGI systems.
Chain-of-thought oversight
If more of a model's cognition is embedded in human-interpretable chain-of-thought compared to internal activations, this seems like a boon for AI safety via human supervision and scalable oversight! While CoT is not always a faithful or accurate description of a model's reasoning, this can likely be improved. I'm also optimistic that LLM-assisted red-teamers will be able to prevent steganographic scheming or at least bound the complexity of plans that can be secretly implemented, given strong AI control measures.[2] From this perspective, the inference compute scaling paradigm seems great for AI safety, conditional on adequate CoT supervison.
Unfortunately, techniques like Meta's Coconut ("chain of continuous thought") might soon be applied to frontier models, enabling continuous reasoning without using language as an intermediary state. While these techniques might offer a performance advantage, I think they might amount to a tremendous mistake for AI safety. As Marius Hobbhahn says, "we'd be shooting ourselves in the foot" if we sacrifice legible CoT for marginal performance benefits. However, given that o1's CoT is not visible to the user, it seems uncertain whether we will know if or when non-language CoT is deployed, unless this can be uncovered with adversarial attacks.
AI security
A proposed defence against nation state actors stealing frontier lab model weights is enforcing "upload limits" on datacenters where those weights are stored. If the first AGIs (e.g., o5) built in the inference scaling paradigm have smaller parameter count compared to the counterfactual equivalently performing model (e.g., GPT-6), then upload limits will be smaller and thus harder to enforce. In general, I expect smaller models to be easier to exfiltrate.
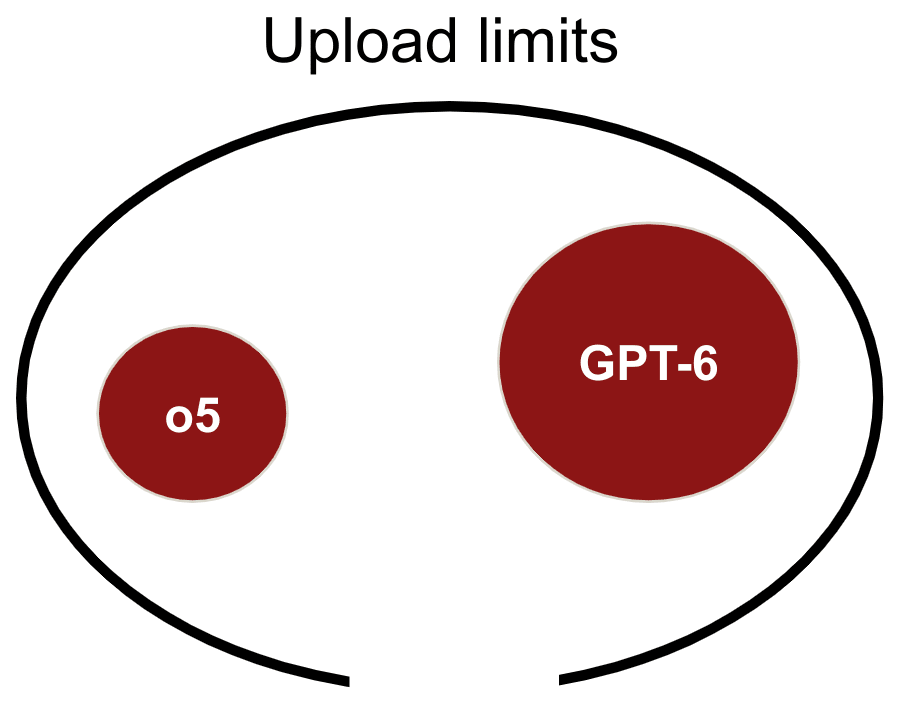
Conversely, if frontier models are very expensive to run, then this decreases the risk of threat actors stealing frontier model weights and cheaply deploying them. Terrorist groups who might steal a frontier model to execute an attack will find it hard to spend enough money or physical infrastructure to elicit much model output. Even if a frontier model is stolen by a nation state, the inference scaling paradigm might mean that the nation with the most chips and power to spend on model inference can outcompete the other. Overall, I think that the inference scaling paradigm decreases my concern regarding "unilateralist's curse" scenarios, as I expect fewer actors to be capable of deploying o5 at maximum output relative to GPT-6.
Interpretability
The frontier models in an inference scaling paradigm (e.g., o5) are likely significantly smaller in parameter count than the counterfactual equivalently performing models (e.g., GPT-6), as the performance benefits of model scale can be substituted by increasing inference compute. Smaller models might allow for easier scaling of interpretability techniques such as "neuron labelling". However, given that the hypothetical o5 and GPT-6 might contain a similar number of features, it's possible that these would be more densely embedded in a smaller o5 and thus harder to extract. Smaller models trained to equivalent performance on the same dataset might exhibit more superposition, which might be more of a bottleneck to scaling interpretability than parameter count. At this point, I think the implications of inference scaling for AI interpretability are unclear and merit investigation.
More RL?
OpenAI has been open about using reinforcement learning (RL) on CoT to improve o-series model output. It is unclear to me whether o5 would be subject to more RL fine-tuning than GPT-6, but possible reasons to expect this include:
- Optimizing CoT via RL might provide cheaper performance improvements than optimizing base models via RL;
- RL feedback on long-chain CoT might allow for higher-quality signal than RL on shorter model outputs;
- OpenAI might be using some sort of "meta-level controller" to steer between different "tree-of-thought" branches in the o-series models, which would be cheaper to update with RL than an entire base model.
If the inference scaling paradigm incentivizes more RL fine-tuning this is somewhat concerning. Excessive optimization of AI systems via RL is the origin of many AI safety threat models, including "incentivizing power-seeking." However, I expect RL on CoT to amount to "process-based supervision," which seems inherently safer than "outcome-based supervision." Overall, I think that this is weakly good news for AI safety, as I expect that AI labs would have used significant amounts of RL to enhance GPT-6 in the counterfactual world and process-based supervision is safer (conditional on the process being human-legible).
Edit: I no longer believe that RL on CoT straightforwardly amounts to process-based supervision (see Daniel Kokotajlo's comment) and I think increased RL on CoT would be a negative update for AI safety.
Export controls
Different types of AI chips might be better at model inference than training, which might have implications for US semiconductor export controls. I expect AI labs to generally use specialized chips for training and inference to eke out more performance at lower cost. Any compute monitoring or on-chip security initiatives should consider how increased chip specialization impacts their efforts.
Conclusion
Overall, conditional on negligible effects on AGI timelines, I think that the advent of the inference compute scaling paradigm is weakly positive for AI safety. I welcome substantial feedback, as I am far from an expert on any of the topics I've covered and I wrote this fast to cover a gap in MATS' curriculum.
- ^
I see this trade-off as analogous to the base-optimizer/mesa-optimizer trade-off discussed in "Risks from Learned Optimization".
- ^
I think studying the performance bounds on steganography-assisted model scheming with unrestricted red-team access deserves much more attention.
Ah, that's a mistake. Our bad.