I wrote almost all of this in mid-March before the FLI Open Letter and Eliezer's TIME piece. Weirdly, after just six weeks I'd likely write something different. This isn't as finished/polished as I'd like, but better to ship it as is than languish incomplete forever.
Not quite two years ago, Daniel Kokotaljo wrote a highly acclaimed post about What 2026 looks like that aimed to tell a single detail future history ("trajectory") about how world events play out in coming years.
As I'm trying to orient myself to what is about to happen, I figured it'd be useful to make my own attempt at this kind of thing. Daniel was bolder than me and tried to imagine 2026 from 2021; I simply don't think I can imagine anything five years out and writing out the rest of 2023, 2024, and 2025 has given me plenty to think about further.
Daniel's vignette places a lot of attention on the size (parameters, compute) and capabilities of models. Daniel and others when imagining the future also want to describe changes in world economy (of which GDP may or may not be a good measure). Those elements feel less interesting to me to think about directly than other effects.
Major Variables
Over the years, it feels like the following are key to track.
Object-level capabilities of the models. Elaboration unnecessary
Adoption and application. It's become salient to me recently that not only is the raw "inherent" power level of models relevant to the world, but also how much they're being harnessed. Widespread use and application of AI will determine things like attention, hype, societal effects, competition, government involvement, etc.
Hype and attention. Importance, neglectedness, tractability. Many of us were used to thinking about how to achieve AI alignment in a world where not that many people were focused on Alignment or even AGI at all. As we gradually (or not that gradually) get into a world where everyone is thinking about AI, it's a pretty different gameboard.
For example, I joined the LessWrong dev team in 2018/2019 and in those days we were still trying to revive LessWrong and restore it's activity levels. Now we're preparing to handle the droves of new users who've found their way to the site due to newfound interest in AI. It significantly alters the strategy and projects we're working on, and I expect similar effects for most people in the Alignment ecosystem.
Economic effects. How much is AI actually creating value? Is it making people more productive at their jobs? Is it replacing jobs? Etc.
Social Effects. There's already a question of how much did Russian chatbots influence the last election. With LLMs capable of producing human-quality text, I do think we should worry about how the online discourse goes from this point on.
Politicization. AI hasn't been deeply politicized yet. I would be surprised if it stays that way, and tribal affiliation affecting people's views and actions will be notable.
Government attention and action. Governments already are paying attention to AI, and I think that will only increase over time, and eventually they'll take actions in response.
Effects on the Alignment and EA community. The increased attention on AI (and making AI good) means that many more people will find their way to our communities, and recruiting will be much easier (it already is compared to a few years ago, as far as I can tell). The Great Influx as I've been calling it, is going to change things and strain things.
Alignment progress. As other events unfold and milestones are reached, I think it's worth thinking about how much progress has realistically been made on various technical Alignment questions.
This is not an exhaustive list on things worth predicting or tracking, but it's some of the major ones according to me.
La Vignette
My goal is to not write my all things considered "most likely story" but instead a story that feels quite plausible.
2023
We're part ways through this year but there's still plenty more time for things to happen. In the timeline of this vignette, no major model is released that outperforms GPT-4 significantly. Any more powerful models trained behind closed servers don't escape or do anything funny to get noticed. Standalone image models make some further progress, but they're not the main show these days.
What does happen in 2023 is the world begins to make real practical use out of GPT-4. GPT-4 is not a general replacement for a human, but it is good enough to start being useful for a lot of purposes. In particular, services built off of the APIs and plugins start to be pretty useful. Google launches AI integrated into products, as does Microsoft, and both integrate a ChatGPT-like interface into their search pages, causing tens of millions (maybe hundreds of millions) of people to regularly interact with language models for mundane search tasks, work doing, school tasks, or fun. Major companies don't want to be left behind and many are hunting for ways to use this new tech, e.g. just integrating ChatGPT the way Snap did, Notion has, Hex.tech too, and more I'm not aware of or are yet to come. Copilot X is a really big deal, helping programmers be way more productive and effective beyond sophisticated autocomplete. Another plausible transformative productive (and hint of what's to come) is Microsoft Security Copilot for GPT-4 powered cybersecurity. Then there's the long list of companies that have GPT-4 Plugs In not limited to Expedia, Instacart, KAYAK, OpenTable, Shopify, Slack, and Wolfram. Again, this is not even an exhaustive list of what's happened already, and we're only finishing Q1 now.
In terms of hype and attention, 2023 is a year that starts with perhaps 1% of people in the developed world having "really noticed" that AI is becoming a big deal to 20-50% have noticed the transformation. I would hazard that we are somewhere near the "takeoff point" in the graph, and things are only going to accelerate from here. I'm imagining it's a bit like Covid: exponential. Every n weeks, twice as many people are thinking and talking about AI until it's most of the world.
Another way to get at increasing interest in AI is Google Search trends. Unfortunately, these don't provide absolute numbers, however, I think it's still informative from both the shape of the curve and comparisons.
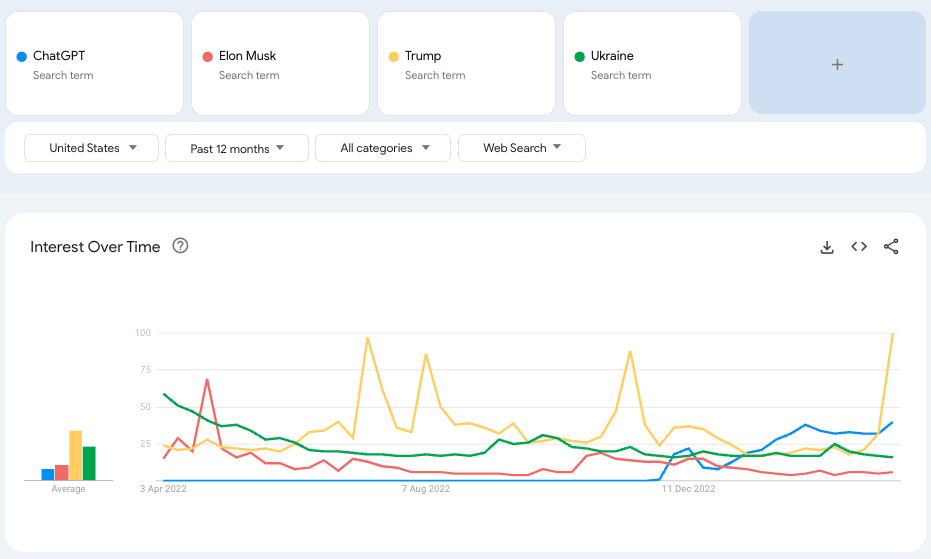
Until Trump became major news again due to potential indictment (edit: made this graph prior to the actual indictment), ChatGPT had trended up in searches higher than Trump, Ukraine [War], and Elon Musk. ChatGPT is still getting 40% of the searches that Trump is, even when he's in the spotlight[1]. This is at end of Q3 2023. By the end of the year, attention is at least 10-fold of this.
The attention and productization of AI, among other things, flows into increased investment in AI research and development. Microsoft might have invested 10 billion in OpenAI already, but Microsoft has a lot more to give. It's market cap is 2 trillion dollars and has 100 billion in cash on hand – definitely enough to train GPT-4 many times over. Google has similar market cap and cash on hand. Of course, the AI products themselves start to produce revenue that can be channeled back into development. By end of 2023, both Microsoft, Google, and others are funneling vastly more of their resources into the AI race.
Similarly in terms of talent, top-tier students begin targeting AI for their careers since it's obviously the biggest deal. Interest in enrolling in CS, AI, and ML degrees goes up 5-10x from start to end of 2023.
By the end of 2023 there have been multiple prominent incidents of AIs behaving badly in the way that Bing has and worse. Additionally a number of serious major security breaches occurred due to AIs having access to data, but they mostly make for a news story and become talking points for already concerned people. The incidents influence government thinking about regulation a bit. However overall, things do not slow down.
Some people attempt to coordinate mass slow downs but fail due to gaffes and slip ups, with the unfortunate result of discrediting further attempts. It's an unfortunate reality that taking major action unilaterally correlates with lack of caution and care in other ways, so this kind of thing happens a lot. (See more in the Mass Movement section below.)
Closer to home, of the masses that are paying attention to AI, there is a fraction that is thinking about whether AI will go well for humanity, and a fraction of that fraction finds its ways to the EA and Alignment communities. Plus, recruitment has gotten really really easy compared to a few years ago when AI concerns felt much more speculative and far off. Already LessWrong by end of Q1 2023 is seeing increased traffic, increased new accounts, and dramatically increased posting about AI.
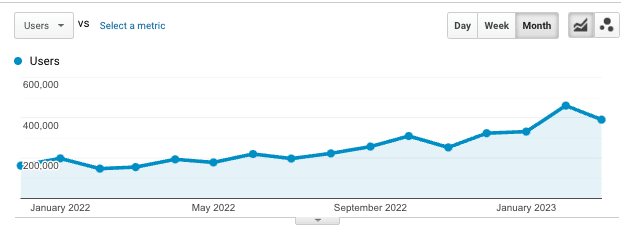
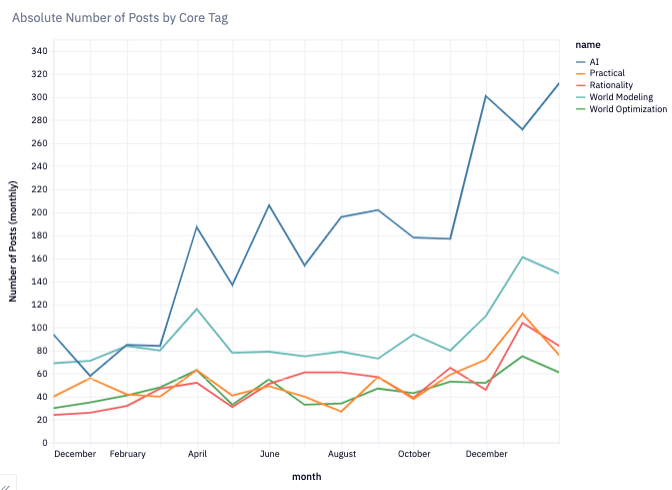
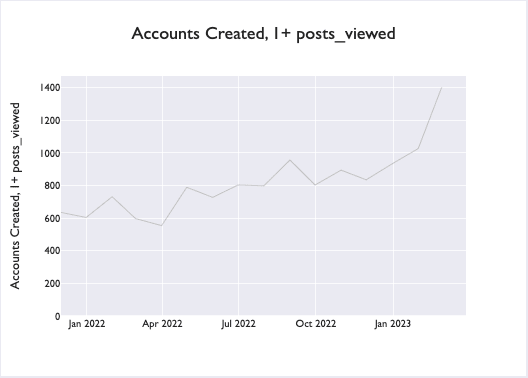
By the end of 2023, these metrics on LessWrong approximately increase 5x (or would have absent changes made by the LessWrong dev team).
By end of 2023 is only in the beginning stages of politicization[2] since most people are still catching up with the magnitude of its implications. Governments have noticed and are investigating and discussing[3], but aren't yet sure what to do. Probably some kind of increased regulation, but pretty unclear what. Some kind of mandatory "evals" seems likely because a pretty competent coalition has been pushing for that.
Alignment research progress has continued. Perhaps "30%" more got done in 2023 than in 2022. While there are many new people showing up eager to help, the process from taking them from eager new-person to making progress at the frontier is weak. If anything, the deluge of new researchers is overwhelming and distracting. Established researchers now spend more time fending off attention and requests they can't meet, and often feel anxious about it. They retreat leaving new eager people without guidance. Many of the new people keep gravitating towards the same few ideas, often skinned slightly differently. Social competition (for career opportunities, which of course are mixed with the social life) is fierce and unhealthy for many new people trying to get a foothold to help on the world's most important problems.
Interpretability is the area which has seen the most visible progress, though there have also been multiple public examples (and presumably more private ones) where interpretability seems to have just accelerated capabilities in the way they are credited in this post.
Various groups, including from the AI Alignment/EA cluster, start working on mass outreach projects to variously convince people about AI x-risk so that (1) they vote for good regulation, (2) they donate, (3) they change careers, (4) they...know about the problem therefore good stuff will come of it...These are executed with varying degrees of skill and success; there's no one with the ability to block not great projects that maybe do harm, so this too is subject to the unilaterist's curse.
2024
AI tools are now in widespread use. There are multiple online courses on using GPT-4 for tasks and services. University courses have been slow to catch up, but people learning to code now (and many other tasks) do so in an LLM-centric way. Many, many apps and services have ChatGPT (or similar) integrated into their products. It's still a bit early-adopter, but many people have integrated GPT-4 with their note-taking, to-do lists, Zapier, other plugin to deliver a super Alexa/Siri. Top software engineers use language models for a 20-50% productivity boost.
In many domains that can be text-based, AIs are substituting for humans: AI friends and romantic/sexual[4] companions are booming, AI therapy is becoming widespread, millions of Americans use GPT-derived services to help them do their taxes, millions more go to GPT-4 with medical questions if not just Bing search. Even if they're not using them to plagiarize outright, language models are functioning as tutors and teachers who frankly are more knowledgeable (despite some hallucinations), have better pedagogy, and way more available than human teachers. There's a market of fine-tuned LLMs for particular purposes e.g. med school, SAT, GRE, etc. Education as a sector had kind of a major crisis due to AI starting in 2023 and full blown in 2024, but actually most people never cared that much about learning things rather than babysitting and credentialism, so the world at large doesn't really care.
For the most part, tools are still augmenting humans and making them more productive rather than entirely displacing them. As above, therapy and education are exceptions. Unsurprisingly, phone customer support for many products has been replaced, likewise debt collection. While GPT-4 is cognitively capable of many tasks, e.g. being waiters and flight attendants, robotics hasn't caught up and this keeps many humans in jobs for now. (However, investment in robotics has gone up at least 3x as many people can tell that if you stick powerful language models in robots can manipulate objects in the real world similar to humans, it'll be darn profitable.)
There hasn't been quite enough job replacement yet for a full-blown crisis, but concern is brewing and many people are uneasy. Fewer people buy the "they're just machines that don't think/humans are special" arguments as before, and many realize they're only going to get more capable (rumors of GPT-5 launch circulate all the time). This isn't helped by the fact that self-driving cars start to roll-out for real, and a replacement of truckers seems actually on the horizon.
GPT-4's multimodal capabilities have been rolled-out/augmented so that images can be used as prompts and produced as outputs.
Heads of major AI companies have been called before Congress. They get asked confused questions. Calls for regulation are frequent but inconsistent. More than half the dialog is about privacy, security, fairness, and bias; but much more than zero is greater concern, even existential. Evaluation and auditing is mandated but the legislation is ambiguous and unclear how to apply it. ARC Evals is one authorized 3rd party evaluator, but not the only one. When testifying before Congress, Sam Altman cites evaluation of models by ARC as trustworthy evidence that OpenAI is being responsible and safe. This, together with not really knowing what's up, means Congress doesn't immediately take notable action on anything.
Some believed that China would be slow on large language model development out of fear that if they developed models that said things the CCP wouldn't like, they'd get in trouble. The CCP has begun to appreciate the stakes of the AI race and is throwing everything it's got at keeping up or winning. This looks like providing enormous funding and reassurance that nothing too bad will happen to you if your model doesn't always tow the party line. People in Washington (including the EAs there) are very spooked by this and commit extra firmly to their side of the race.
2024 is a US election year and the rise of AI is a talking point of equivalent salience as the upcoming election; people are just as likely to talk about it with friends and families. Common viewpoints are "yep, it's a big deal and we'll figure it out", "we're all going to die (but in a detached or joking way)", "this is just the same as internet/electricity", "it's not actually intelligent", and "I don't want to think about it".
Due to it being an election year, politicization comes early. The Left is concerned about loss of jobs, unfairness (the proceeds of AI should go to everyone equally, not just the greedy wealthy capitalists), and to a lesser degree language models not saying anything they're not supposed to (but in comparison with the changing economic landscape, it's less important than it used to be). The Right is concerned about jobs and not losing the AI race with China/Russia/rest of the world, and to a lesser degree about language models having freedom of speech. AI is part of the presidential debate (more than 20% of the total speaking time), though the focus in short-term immediate stuff, not the everyone-dies part.
Online discourse is a shitshow. It doesn't take that much programming skill to hook a language model up to Twitter or Discord (GPT-4 will basically tell you how!) and even if OpenAI RLHF's its models into not being online propaganda/interference bots, you can get pretty good alternatives elsewhere, e.g. fine-tuned versions of LLaMA. So most people have given up on participating in any kind of discussion, many people have given up on trusting what they read – too likely that a model wrote it[5]. Instead what prevails is believing what you want to believe via massive confirmation bias. What spreads is what goes viral. This makes for an election cycle where things were more polarized than ever, but not by much since actually things were pretty polarized already. Things shift a bit offline/off of text as people think they can trust podcast and TV appearances more to be real and show what politicians said, etc., but this too can't be trusted due to ML emulation of voices and video creation that's also know to be very good.
At some point in the year, OpenAI releases GPT-5. It had been trained in 2023 but there wasn't strong incentive to release it fast since the world needed to adapt anyway, and GPT-4 was good enough for that anyway. A number of things needed to be accomplished before release time:
- Sufficient post-training to make it behave well. Granted that they can get away with a lot, it's still better for severe bad behavior to rare. This is also good for revenue since the companies using their APIs/integrations will pay a premium for the OpenAI safety/alignment brand. It also helps keeping government attention off their backs.
- Time to build and improve infrastructure to inference/serving the APIs. GPT-family are becoming the most widely used API is all history, and that takes some engineering. No point launching GPT-5 before they've got the infrastructure to serve the demand.
- ARC evals (and others) to play around with the models and certify that they're safe.
In addition to that, release timing of GPT-5 was timed to avoid impacting bad outcomes in political discussions and regulation that's getting passed. OpenAI judges it better to wait until Congress/politicians/public feel safer with GPT-4, etc before making things even more intense.
GPT-5 in fact was let-down compared to the hopes and fears of people. On text-based tasks, it was perceived as 15-30% better than GPT-4, with the real difference being that the multi-modal (image, etc) was significantly improved. GPT-5's text comprehension with image generation causes it to replace most usages of other image generators, because it is vastly easier to get what you want, especially with iterative prompting of the kind ChatGPT got people used to.
Traffic to LessWrong and broader AI Alignment community can be described as a tsunami by end of 2024. The community has become severely onion like with inner layers ever more difficult to enter. The innermost layers are the community that existed in 2023 and prior where familiarity and trust remains and people continue trying to get research done. Some (including the LessWrong team) work to manage and utilize the hordes of Alignment-interested people at the outer layers. The focus of efforts is scalable web infrastructure like LessWrong and Stampy.ai and other online very automated courses (but hey, they have GPT-4/5 as tutor). Heavy filters and testing are used to extract people from the outermost layers and recruit them into on-the-ground orgs. Concretely, LessWrong has placed very strong barriers to active participation on the site. Anyone can read, but being allowed to comment is uncommon privilege – a restriction necessary to to maintain any quality of discourse.
In terms of Alignment research, it was a pretty exciting year. Yet more interpretability progress (we now a bit of an idea of how to interpret MLPs even), Elicit and its new siblings have helped build AI-assisted researchers, Heuristics Arguments is developing into something that is maybe practical, John Wentworth has developed Natural Abstractions into something that even Nate Soares thinks is ok. A few more interesting agendas have arisen that people still think is pretty promising. Overall, things have accelerated a lot and 130% more got done in 2024 than in 2023 (which was 30% more than 2022, so 2024 was 2.3x of 2022).
2025
GPT-6, released in early 2025 and much sooner than people expected, was trained with a lot more data and a lot more compute. It was trained on text, images, audio recordings, and videos. Thousands (millions?) of years of content: every book, every public document, every textbook, every TV show and movie, millions of YouTube videos (especially those on technical topics and how-to's).
It's a hot take to say that GPT-6 is not a general intelligence. It lacks physical embodiment, but it's multimodal and cognitively it can do many many many varied tasks. Architecture tweaks mean that somehow the limitation of context windows is overcome and your personal "instance" of GPT-6 can recall your previous interactions if you want (this makes it very useful as an assistant/exobrain). Arguments rage about whether or not it's truly an agent but empirically humans have GPT-6 perform many many tasks on their behalf. Security concerns be damned, GPT-6 has access to most people's emails and will write and respond for them, schedule medical appointments, research and buy products via Amazon, and heaps of other plug-in/Zapier enabled tasks. Yes, GPT-6 helps you do your taxes, plan your vacation, fill out paperwork, negotiate a raise, get legal advice, research medical advice, navigate conflict with your spouse, do your Christmas shopping for you, train your employees, decorate your house, write your emails, write your novel, fix your broken door lock, maintain your to-do list, be your friend and confident, and countless other tasks.
What's really striking is the level of inference that GPT-6 is capable of. Ask it the answer to contrived and bizarre physics problems that definitely did not appear directly in the training data, and it answers convincingly and correctly, as far as can generally be said. Randall Munroe says he won't bother writing another What If? because you can just ask GPT-6. Relatedly, the academic community is torn over whether it's good that GPT-6 is now being used to write more than half of papers (Yay productivity!) or terribly (people are usings AIs to do the work of humans! Cheating!)
GPT-6 is zealous in responding to many prompts that it is only an AI language model created by OpenAI and couldn't possibly have opinions about how to accomplish Task X, where X is anything that might offend or harm anyone even slightly. Few people believe that it couldn't, they just differ in how much they trust that it won't. Jailbreaking is possible but more difficult, in large part because the API/model is aggressive at detecting attempts to jailbreak and disabling your access.
GPT-6's freedom to act on people's behalf has caused them harm, and that makes headlines, but GPT-6 is far too useful for people to give it up despite a few financially ruinous purchases, lethal medical advice, bad relationship advice, and misuse as babysitter.
Everyone knows about GPT-6 at this point, and it's a question of just how extensively a person has integrated it into their lives (or mind). At the extreme end, many people have GPT-6 as a live, ever-present assistant to answer, advise, remind, coach, etc. An ever present friend, collaborator, and personal expert on basically any topic. Some people have it only speak when spoken to, but increasingly many have it passively listening and configured to chime in whenever it might have something helpful to say. Parents will say "no GPT at the dinner table" and young folk advertise in their Tinder bios "looking for GPT-6-free dates".
Beneath the general public usage is the burgeoning industry use. Fine-tuned models assist humans in construction, design, accounting, medicine, logistics, etc., etc. The bottleneck is mostly educating people in using the new tools, but heck, the tools teach themselves.
The economic effects are mixed and confusing and don't lend themselves easily to a single narrative. It is true that many humans have been augmented and made more vastly productive, thereby creating a lot more economic value. It's also the case that many other people weren't hired because of GPT-6, even though it wasn't a simple case of "driverless cars have replaced truckers and rideshare drivers". Doctors aren't wholesale obsolete, but the nurses who staff phone lines for medical advice are in vastly less demand. Generally, you still need a lawyer to represent you in court or a doctor to perform procedures, but first round consultations are getting automated. Similarly, teachers aren't yet replaced wholesale, but between a GPT-assisted teacher and each kid having an AI, class sizes are larger and fewer teachers are needed.
In aggregate, unemployment is up to somewhere between 10-20% and there is a large class of disgruntled people. In quieter times, they'd be at the forefront of public attention but there's so much going on so it only gets a slice of the news cycle. The White House is rolling out improved and indefinite unemployment benefits (it's kind of a universal basic income, but they don't want to call it that) plus "retraining programs" to help people "master new AI tools and reenter the workforce". Many people mock these programs saying obviously AI is going to automate more and more, so let's just actually have UBI.
"Anti-capitalist Marxists", i.e. the people who are generally concerned about who owns the "capital", are very onboard with AI concerns. It's clear that AI is the ultimate capital and it's the tech companies like OpenAI, Microsoft, and Google who are going to own the future by default. OpenAI is happy to pay taxes and do other showy acts of wealth redistribution if it deflects public concern.
The governments of nation states have heaved their massive inertia and are in the swing of Doing Things. The US Department of Defense has its own program going and is paying extremely well to attract top talent, but they're not completely fools and know that the commercial labs are where things are at and might remain. The US government covertly demands that OpenAI cooperate with it in exchange for being allowed to continue to operate in the consumer domain. This means early access to models and support in tailoring their models for US strategic defense needs. Custom-tailored models are being put in use by DoD, DoJ, NSA, FBI, CIA, and whoever can get security clearance to be given models that are immensely capable at surveillance/espionage. Those who claimed that GPT models evened out things between attackers and defenders in cybersecurity advertised falsely. It is still easier for a model to locate unpatched weaknesses in overall human designed tech infrastructure than to detect and defend against all those weaknesses. This means that GPT models are both excellent at obtaining data – and perhaps more importantly, sifting through it to find the interesting stuff. Major government action is basically about to become downstream of intelligence data sources and interpreted by AI models.
<ideally more stuff>
- ^
However those searches aren't coming from the same place, e.g. searches for ChatGPT come heavily from California. The future is here, it's just not evenly distributed.
- ^
I'm not sure what to make of a Fox News reporter citing Eliezer on AI Doom to the White House press secretary. Matching article on Fox News itself. One can only hope that the two parties compete for greater caution.
Note again that I wrote most of this post before the recent publicity. This might already be a positive update from my actual fear that the Right would be calling for more powerful so we beat China, etc. Nonetheless, I'll leave the post as I was first writing it.
- ^
Granted, the Biden administration had already put out this Blueprint for an AI Bill of Rights and the EU discussed its approach already in April 2021.
- ^
Major labs might refuse to do it, but others are willing to have their models produce graphic content.
- ^
In fact GPT-3 was adequate for a convincing Twitter bot, the difference is that now far more people are aware of this thereby eroding trust.
Haha no way, the educational system does not adapt so quickly. The main concern of teachers in 2025 will probably be inventing various annoying ways how to prevent their students from using GPT to do their homework (and most students will probably figure out how to circumvent that, most likely by asking the GPT).
Tend to agree that this will be the median experience. It's important to realize that the future is not evenly distributed - there will be some areas and schools that embrace GPT and other modern tooling.