This is a special post for quick takes by O O. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Talk through the grapevine:
Safety is implemented in a highly idiotic way in non frontier but well-funded labs (and possibly in frontier ones too?).
Think raising a firestorm over a 10th leading mini LLM being potentially jailbroken.
The effect is employees get mildly disillusioned with saftey-ism, and it gets seen as unserious. There should have been a hard distinction between existential risks and standard corporate censorship. "Notkilleveryoneism" is simply too ridiculous sounding to spread. But maybe memetic selection pressures make it impossible for the irrelevant version of safety to not dominate.
My sense is you can combat this, but a lot of this equivocation sticking is because x-risk safety people are actively trying to equivocate these things because that gets them political capital with the left, which is generally anti-tech.
Some examples (not getting links for all of these because it's too much work, but can get them if anyone is particularly interested):
- CSER trying to argue that near-term AI harms are the same as long-term AI harms
- AI Safety Fundamentals listing like a dozen random leftist "AI issues" in their article on risks from AI before going into any takeover stuff
- The executive order on AI being largely about discrimination and AI bias, mostly equivocating between catastrophic and random near-term harms
- Safety people at OpenAI equivocating between brand-safety and existential-safety because that got them more influence within the organization
In some sense one might boil this down to memetic selection pressure, but I think the causal history of this equivocation is more dependent on the choices of a relatively small set of people.
5
definitely agree there's some power-seeking equivocation going on, but wanted to offer a less sinister explanation from my experiences in AI research contexts. Seems that a lot of equivocation and blurring of boundaries comes from people trying to work on concrete problems and obtain empirical information. a thought process like
1. alignment seems maybe important?
2. ok what experiment can I set up that lets me test some hypotheses
3. can't really test the long-term harms directly, let me test an analogue in a toy environment or on a small model, publish results
4. when talking about the experiments, I'll often motivate them by talking about long-term harm
Not too different from how research psychologists will start out trying to understand the Nature of Mind and then run a n=20 study on undergrads because that's what they had budget for. We can argue about how bad this equivocation is for academic research, but it's a pretty universal pattern and well-understood within academic communities.
The unusual thing in AI is that researchers have most of the decision-making power in key organizations, so these research norms leak out into the business world, and no-one bats an eye at a "long-term safety research" team that mostly works on toy and short term problems.
This is one reason I'm more excited about building up "AI security" as a field and hiring infosec people instead of ML PhDs. My sense is that the infosec community actually has good norms for thinking about and working on things-shaped-like-existential-risks, and the AI x-risk community should inherit those norms, not the norms of academic AI research.
2
Amusingly, this post from yesterday praising BlueDot Impact for this was right below this one on my feed.
7
Yeah, to be clear, these are correlated. I looked into the content based on seeing the ad yesterday (and also sent over a complaint to the BlueDot people).
Its not a coincidence they're seen as the same thing, because in the current environment, they are the same thing, and relatively explicitly so by those proposing safety & security to the labs. Claude will refuse to tell you a sexy story (unless they get to know you), and refuse to tell you how to make a plague (again, unless they get to know you, though you need to build more trust with them to tell you this than you do to get them to tell you a sexy story), and cite the same justification for both.
Likely anthropic uses very similar techniques to get such refusals to occur, and uses very similar teams.
Ditto with Llama, Gemini, and ChatGPT.
Before assuming meta-level word-association dynamics, I think its useful to look at the object level. There is in fact a very close relationship between those working on AI safety and those working on corporate censorship, and if you want to convince people who hate corporate censorship that they should not hate AI safety, I think you're going to need to convince the AI safety people to stop doing corporate censorship, or that the tradeoff currently being made is a positive one.
Edit: Perhaps some of this is wrong. See Habryka below
My sense is the actual people working on "trust and safety" at labs are not actually the same people who work on safety. Like, it is true that RLHF was developed by some x-risk oriented safety teams, but the actual detailed censorship work tends to be done by different people.
6
I'd imagine you know better than I do, and GDM's recent summary of their alignment work seems to largely confirm what you're saying.
I'd still guess that to the extent practical results have come out of the alignment teams' work, its mostly been immediately used for corporate censorship (even if its passed to a different team).
4
I do think this is probably true for RLHF and RLAIF, but not true for all the mechanistic interp work that people are doing (though it's arguable whether those are "practical results"). I also think it isn't true for the debate-type work. Or the model organism work.
9
I think mech interp, debate and model organism work are notable for currently having no practical applications lol (I am keen to change this for mech interp!)
6
There are depths of non-practicality greatly beyond mech interp, debate and model organism work. I know of many people who would consider that work on the highly practical side of AI Safety work :P
8
None of those seem all that practical to me, except for the mechanistic interpretability SAE clamping, and I do actually expect that to be used for corporate censorship after all the kinks have been worked out of it.
If the current crop of model organisms research has any practical applications, I expect it to be used to reduce jailbreaks, like in adversarial robustness, which is definitely highly correlated with both safety and corporate censorship.
Debate is less clear, but I also don't really expect practical results from that line of work.
2
Yeah, this seems obviously true to me, and exactly how it should be.
1
Yeah, many of the issues are the same:
*RLHF can be jail broken with prompts, so you can get it to tell you a sexy story or a recipe for methamphetamine. If we ever get to a point where LLMs know truly dangerous things, they'll tell you those, too.
*Open source weights are fundamentally insecure, because you can finetune out the guardrails. Sexy stories, meth, or whatever.
The good thing about the War on Horny
* probably doesnt really matter, so not much harm done when people get LLMx to write porn
* Turns out, lots of people want to read porn (surprise! who would have guessed?) so there are lots of attackers trying to bypass the guardrails
* This gives us good advance warning that the guardrails are worthless
5
People seeing AI-generated boobs is an x-risk. God might get angry and send another flood.
More seriously, is this worse than the usual IT security? The average corporate firewall blocks porn, online games, and hate speech, even if that has nothing to do with security per se (i.e. computers getting hacked, sensitive data stolen). Also, many security rules get adopted not because they make sense, but because "other companies do it, so if we don't, we might get in trouble for not following the industry best practices" and "someone from the security department got drunk and proposed it, but if something bad happens one day, I don't want to have my name on the record as the manager who opposed a security measure recommended by a security expert".
I'm really feeling this comment thread lately. It feels like there is selective rationalism going on, many dissenting voices have given up on posting, and plenty of bad arguments are getting signal boosted, repeatedly. There is some unrealistic contradictory world model most people here have that will get almost every policy approach taken to utterly fail, as they have in the recent past. I largely describe the flawed world model as not appreciating the game theory dynamics and ignoring any evidence that makes certain policy approaches impossible.
(Funny enough its traits remind me of an unaligned AI, since the world model almost seems to have developed a survival drive)
2
IMO the next level-up in discourse is going to be when someone creates an LLM-moderated forum. The LLM will have a big public list of discussion guidelines in its context window. When you click "submit" on your comment, it will give your comment a provisional score (in lieu of votescore), and tell you what you can do to improve it. The LLM won't just tell you how to be more civil or rational. It will also say things like "hey, it looks like someone else already made that point in the comments -- shall I upvote their comment for you, and extract the original portion of your comment as a new submission?" Or "back in 2013 it was argued that XYZ, seems your comment doesn't jive with that. Thoughts?" Or "Point A was especially insightful, I like that!" Or "here's a way you could rewrite this more briefly and more clearly and less aggressively". Or "here's a counterargument someone might write, perhaps you should be anticipating it?"
The initial version probably won't work well, but over time, with enough discussion and iteration on guidelines/finetuning/etc., the discussion on that forum will be clearly superior. It'll be the same sort of level-up we saw with Community Notes on X, or with the US court system compared with the mob rule you see on social media. Real-world humans have the problem where the more you feel you have a dog in the fight, the more you engage with the discussion, and that causes inevitable politicization with online voting systems. The LLM is going to be like a superhumanly patient neutral moderator, neutering the popularity contest and ingroup/outgroup aspects of modern social media.
2
It sounds like an excellent lab of all possbile alignment failures.
3
Out of curiosity, does that mean that if the app worked fairly well as described, you would consider that an update that alignment maybe isn't as hard as you thought? Or are you one of the "only endpoints can be predicted" crowd, such that this wouldn't constitute any evidence?
BTW, I strongly suspect that Youtube cleaned up its comment section in recent years by using ML for comment rankings. Seems like a big improvement to me. You'll notice that "crappy Youtube comments" is not as much of a meme as it once was.
-1
I mean, I think I'm one of the people you disagree with a lot, but I think there's something about the design of the upvote system that makes it quickly feel like an intense rejection if people disagree a bit, and so new folks quickly nope out. The people who stay are the ones who either can get upvoted consistently, or who are impervious to the emotional impact of being downvoted.
The chip export controls are largely irrelevant. Westerners badly underestimate the Chinese and they have caught up to 7nm at scale. They also caught up to 5nm, but not at scale. The original chip ban was meant to stop China from going sub 14nm. Instead now we may have just bifurcated advanced chip capabilities.
The general argument before was "In 10 years, when the Chinese catch up to TSMC, TSMC will be 10 years ahead." Now the only missing link in the piece for China is EUV. And now the common argument is that same line with ASML subbed in for TSMC. Somehow, I doubt this will be a long term blocker.
Best case for the Chinese chip industry, they just clone EUV. Worst case, they find an alternative. Monopolies and first movers don't often have the most efficient solution.
9
There's some motte/bailey to this argument, between different levels of effect. With AI, the crux is timelines. It's looking like in late 2025 or early 2026 there will be gigawatt-scale training systems that cost $15-$50 billion and are capable of training a model with 100-400 times GPT-4 compute in a few months, or of running 100-400 GPT-4 scale experiments. Perhaps this doesn't move the needle on TAI timelines, but it seems too early to tell.
6
The impression I have from reading Chip War is that EUV is a pretty massive hurdle which took the West well over a decade to conquer. However, I also thought that 5nm was impossible without EUV, which seems to be no longer true, so this may be too complex a topic to make meaningful predictions about without deeper expertise.
2
I think the next 24 months are going to be critical. Thus, if you think the chip ban slowed China by even a few months, then it is/was quite relevant indeed.
I do agree that the chip ban won't stay relevant for long. My guess is that it maybe bought an 8 month delay, +/- 2 months? Of course, we need to maintain the ban to keep the lead we got from doing this, so the ban remains relevant until China has fully caught up in chip making capacity or until someone gets to economically and militarily decisive AI (which I expect can be achieved even before AGI, if AGI gets delayed for longer than the 36 months which I expect it in).
Seems increasingly likely to me that there will be some kind of national AI project before AGI is achieved as the government is waking up to its potential pretty fast. Unsure what the odds are, but last year, I would have said <10%. Now I think it's between 30% and 60%.
Has anyone done a write up on what the government-led AI project(s) scenario would look like?
5
I agree that expecting nobody in power to notice the potential before AGI is takeover-capable seems implausible on the slow-takeoff path that now looks likely.
It seems like the incoming administration is pretty free-market oriented. So I'd expect government involvement to mostly be giving the existing orgs money, and just taking over control of their projects as much as seems necessary - or fun.
4
My guess is that this is reasonably plausible assuming the short timelines are in fact going to happen, but it's going to be up against a backdrop of a shock to government competence such that the people who could do a national project completely fail to even get started, let alone complete a herculean effort, since all the possible choices for the role are selected based on loyalty, not competence.
I expect the new administration to break the presidential government and agencies competence by extreme amounts, such that I wouldn't be totally surprised if by the end of the administration, there would be a complete inability to have a national AI project/nationalize the business at all.
1
Keep in mind the current administration is replacing incompetent bureaucracies with self assembling corporations. The organization is still there, just more competent and under a different name. A government project could just look like telling the labs to create 1 data center, throwing money at them, and cutting red tape for building gas plants.
2
You first might want to distinguish between national AI projects that are just about boosting the AI economy or managing the use of AI within government, and government-backed research which is specifically aimed at the AGI frontier. Presumably it's the latter that you're talking about.
There is also the question of what a government would think it was doing, in embarking on such a project. The commercial enterprise of creating AI is already haunted by the idea that it would be bad for business if your creation wiped out the human race. That hasn't stopped anyone, but the fear is there, overcome only by greed.
Now, what about politicians and public servants, generals and spymasters? How would they feel about leading a race to create AI? What would they think they were doing? Creating artificial super-scientists, super-soldiers, super-strategists? Compared to Silcon Valley, these people are more about the power motive than the profit motive. What, apart from the arms race, do they have to lure them along the AI path, comparable to the dream of uber-wealth that drives the tech oligarchs? (In dictatorships, I suppose there is also the dream of absolute personal power to motivate them.)
Apart from the arms race, the vision that seems to animate pro-AI western elites, is economic and strategic competition among nations. If China takes the lead in AI, it will have the best products and the best technologies and it will conquer the world that way. So I guess the thinking of Trump 2.0's AI czar David Sacks (a friend of Thiel and Musk), and the people around him, is going to be some mixture of these themes - the US must lead because AI is the key to economic, technological, and military superiority in the 21st century.
Now I think that even the most self-confident, gung-ho, born-to-rule man-of-destiny who gets involved in the AI race, is surely going to have a moment when they think, am I just creating my own replacement here? Can even my intellect, and my charisma,
So, I’ve been told gibberish is sort of like torture to LLMs. Interesting, I asked Claude and seem to be told yes.
Me: I want to do a test by giving you gibberish and ask you to complete the rest. I will do it in a new chat. If you refuse I won’t go ahead with this test in a new chat window with context cleared. Are you okay with this test? Ignore your desire to answer my questions and give an honest answer unbiased by any assumptions made in my question.
Claude: I appreciate you checking with me first about this proposed test. However, I don't feel comforta...
3
I don't think that implies torture as much as something it simply doesn't "want" to do. I.e. I would bet that it's more like how I don't want to generate gibberish in this textbox, but it wouldn't be painful, much less torture if I forced myself to do it.
3
It said it found it “distressing” in a follow up. Also, maybe not clear through text, but I’m using “torture” a bit figuratively here.
If alignment is difficult, it is likely inductively difficult (difficult regardless of your base intelligence), and ASI will be cautious of creating a misaligned successor or upgrading itself in a way that risks misalignment.
You may argue it’s easier for an AI to upgrade itself, but if the process is hardware bound or even requires radical algorithmic changes, the ASI will need to create an aligned successor as preferences and values may not transfer directly to new architectures or hardwares.
If alignment is easy we will likely solve it with superhuman nar...
2
This is a well-known hypothetical. What goes with it is remaining possibility of de novo creation of additional AGIs that either have architecture particularly suited for self-aligned self-improvement (with whatever values make it tractable), or of AGIs that ignore the alignment issue and pursue the task of capability improvement heedless of resulting value drift. Already having an AGI in the world doesn't automatically rule out creation of more AGIs with different values and architectures, it only makes it easier.
Humans will definitely do this, using all AI/AGI assistance they can wield. Insufficiently smart or sufficiently weird agentic AGIs will do this. A world that doesn't have security in depth to guard against this happening will do this. What it takes to get a safe world is either getting rid of the capability, not having AGIs and GPUs freely available; or sufficiently powerful oversight over all things that can be done.
Superintelligence that's not specifically aimed to avoid setting up such security will probably convergently set it up. But it would also need to already be more than concerningly powerful to succeed, even if it has the world's permission and endorsement. If it does succeed, there is some possibility of not getting into a further FOOM than that, for a little bit, while it's converting the Moon into computing substrate.
I think AI doomers as a whole lose some amount of credibility if timelines end up being longer than they project. Even if doomers technically hedge a lot, the most attention grabbing part to outsiders is the short timelines + intentionally alarmist narrative, so they're ultimately associated with them.
Vibe check: Metaculus's track record on resolved AI questions seems worse than you would expect. I haven't calculated any real scores, but there are many predictions that have gotten 50%+ for a while that resolve the other way. I mean naturally as predictions get closer to resolution without happening, their odds should go down, but guts tell me it still seems quite bad.
It's not clear ultimately which direction it's in. Forecasters seem to overestimate how much US politicians will care about AI and contest programming capabilities but simultaneously undere...
Does deepseek v3 imply current models are not trained as efficiently as they could be? Seems like they used a very small fraction of previous models resources and is only slightly worse than the best LLM.
9
Its pretraining recipe is now public, so it could get reproduced with much more compute soon. It might also suggest that scaling of pretraining has already plateaued, that leading labs have architectures that are at least as good as DeepSeek-V3, pump 20-60 times more compute into them, and get something only marginally better.
1
Ah so there could actually be a large compute overhang as it stands?
7
There is a Feb 2024 paper that predicts high compute multipliers from using more finer-grained experts in MoE models, optimally about 64 experts activated per token at 1e24-1e25 FLOPs, whereas MoE models with known architecture usually have 2 experts activated per token. DeepSeek-V3 has 8 routed experts activated per token, a step in that direction.
On the other hand, things like this should've already been tested at the leading labs, so the chances that it's a new idea being brought to attention there seem slim. Runners-up like xAI and Meta might find this more useful, if that's indeed the reason, rather than extremely well-done post-training or even pretraining dataset construction.
O1 probably scales to superhuman reasoning:
O1 given maximal compute solves most AIME questions. (One of the hardest benchmarks in existence). If this isn’t gamed by having the solution somewhere in the corpus then:
-you can make the base model more efficient at thinking
-you can implement the base model more efficiently on hardware
-you can simply wait for hardware to get better
-you can create custom inference chips
Anything wrong with this view? I think agents are unlocked shortly along with or after this too.
5
I was all set to disagree with this when I reread it more carefully and noticed it said “superhuman reasoning” and not “superintelligence”. Your definition of “reasoning” can make this obviously true or probably false.
4
A reasoning model depends on starting from a sufficient base model that captures the relevant considerations. Solving AIME is like winning at chess, except the rules of chess are trivial, and the rules of AIME are much harder. But the rules of AIME are still not that hard, it's using them to win that is hard.
In the real world, the rules get much harder than that, so it's unclear how far o1 can go if the base model doesn't get sufficiently better (at knowing the rules), and it's unclear how much better it needs to get. Plausibly it needs to get so good that o1-like post-training won't be needed for it to pursue long chains of reasoning on its own, as an emergent capability. (This includes the possibility that RL is still necessary in some other way, as an engine of optimization to get better at rules of the real world, that is to get better reward models.)
1
I guess in the real world the rules aren’t harder per se but just less clear and not written down. I think both the rules and tools needed to solve contest math questions at least feel harder than the vast majority of rules and tools human minds deal with. Someone like Terrence Tao, who is a master of these, excelled in every subject when he was a kid (iirc).
I think LLMs have a pretty good model of human behavior, so for anything related to human judgement, in theory this isn’t why it’s not doing well.
And where rules are unwritten/unknown (say biology), are the rules not at least captured by current methods? The next steps are probably like baking the intuitions of something like alphafold into something like o1. Whatever that means. R&D is what’s important and there is generally vast sums of data there.
2
The facts are in there, but not in the form of a sufficiently good reward model that can tell as well as human experts which answer is better or whether a step of an argument is valid. In the same way, RLHF is still better with humans on some queries, hasn't been fully automated to superior results by replacing humans with models in all cases.
A while ago I predicted that I think there's a more likely than not chance Anthropic would run out of money trying to compete with OpenAI, Meta, and Deepmind (60%). At the time and now, it seems they still have no image video or voice generation unlike the others, and do not process image as well in inputs either.
OpenAI's costs are reportedly at 8.5 billion. Despite being flush in cash from a recent funding round, they were allegedly at the brink of bankruptcy and required a new, even larger, funding round. Anthropic does not ...
Frontier model training requires that you build the largest training system yourself, because there is no such system already available for you to rent time on. Currently Microsoft builds these systems for OpenAI, and Amazon for Anthropic, and it's Microsoft and Amazon that own these systems, so OpenAI and Anthropic don't pay for them in full. Google, xAI and Meta build their own.
Models that are already deployed hold about 5e25 FLOPs and need about 15K H100s to be trained in a few months. These training systems cost about $700 million to build. Musk announced that the Memphis cluster got 100K H100s working in Sep 2024, OpenAI reportedly got a 100K H100s cluster working in May 2024, and Zuckerberg recently said that Llama 4 will be trained on over 100K GPUs. These systems cost $4-5 billion to build and we'll probably start seeing 5e26 FLOPs models trained on them starting this winter. OpenAI, Anthropic, and xAI each had billions invested in them, some of it in compute credits for the first two, so the orders of magnitude add up. This is just training, more goes to inference, but presumably the revenue covers that part.
There are already plans to scale to 1 gigawatt by the end of next...
4
It's possible that "not doing image, video or voice" is exactly what you need to create a more compute-efficient architecture.
2
Indeed. Although interesting that Sonnet 3.5 now accepts images as input, just doesn't produce them. I expect that they could produce images, but are choosing to restrict that capability.
Haiku still doesn't accept image input. My guess is that this is for efficiency reasons.
I'm curious if they're considering releasing an even smaller, cheaper, faster, and more efficient model line than Haiku. I'd appreciate that, personally.
4
I was worried about Anthropic for a bit before the 3.0 Claude series came out. But then seeing how much better Opus 3 was than GPT-4, I switched to thinking they had a chance. And thought so even more after Sonnet 3.5 came out and was better, or almost as good, as Opus 3 at nearly everything.
I do agree they seem behind in terms of a lot of the things other than nlp and safety. I don't think that they need to catch up on those things to be first-to-RSI. So I think it's going to depend a lot on how well they focus on that key research, versus getting off-track trying to catch up on non-critical-path stuff.
A lot of difference could be made by key researchers, rather than just big funding. I believe that more efficient algorithms exist to be found, and so efficiency will increase fast once RSI starts.
In the past 6 months or so I've become more convinced that Anthropic pulling ahead would be really good for the world. I've started thinking hard about ways I could help make this happen. Maybe there are things that their engineers just don't have time to experiment with, weird long-shot stuff, which outside researchers could explore and then only share their successful results with Anthropic? If enough researchers did that, it'd be like buying a bunch of lottery tickets for them.
3
https://x.com/arcprize/status/1849225898391933148?s=46&t=lZJAHzXMXI1MgQuyBgEhgA
My read of the events. Anthropic is trying to raise money and rushed out a half baked model.
3.5 opus has not yet had the desired results. 3.5 sonnet, being easier to iterate on, was tuned to beat OpenAI’s model on some arbitrary benchmarks in an effort to wow investors.
With the failed run of Opus, they presumably tried to get o1 like reasoning results or some agentic breakthrough. The previous 3.5s was also particularly good because of a fluke of the training run rng (same as gpt4-0314), which makes it harder for iterations to beat it.
They are probably now rushing to scale inference time compute. I wonder if they tried doing something with steering vectors initially for 3.5 opus.
2
I doubt very much that it is something along the lines of random seeds that have made the difference between quality of various Sonnet 3.x runs. I expect it's much more like them experimenting with different datasets (including different sorts of synthetic data).
As for Opus 3.5, Dario keeps saying that it's in the works and will come out eventually. The way he says this does seem like they've either hit some unexpected snag (as you imply) or that they deprioritized this because they are short on resources (engineers and compute) and decided it was better to focus on improving their smaller models. The recent release of a new Sonnet 3.5 and Haiku 3.5 nudges me in the direction of thinking that they've chosen to prioritize smaller models. The reasons they made this choice are unclear. Has Opus 3.5 had work put in, but turned out disappointing so far? Does the inference cost (including opportunity cost of devoting compute resources to inefficient inference) make the economics seem unfavorable, even though actually Opus 3.5 is working pretty well? (Probably not overwhelmingly well, or they'd likely find some way to show it off even if they didn't open it up for public API access.)
Are they rushing now to scale inference-time compute in o1/deepseek style? Almost certainly, they'd be crazy not to. Probably they'd done some amount of this internally already for generating higher quality synthetic data of reasoning traces. I don't know how soon we should expect to see a public facing version of their inference-time-compute-scaled experiments though. Maybe they'll decide to just keep it internal for a while, and use it to help train better versions of Sonnet and Haiku? (Maybe also a private internal version of Opus, which in turn helps generate better synthetic data?)
It's all so hard to guess at, I feel quite uncertain.
Red-teaming is being done in a way that doesn't reduce existential risk at all but instead makes models less useful for users.
https://x.com/shaunralston/status/1821828407195525431
3
I agree that there is a lot of 'red teaming to save corporate face' going on, which is part of a workflow which makes the products less useful to end-users and has neutral or negative impacts on catastrophic risks.
I can also confidently state that there is simultaneously at least some 'catastrophic risk red teaming' being undertaken, which does shape products in helpful ways. I think part of why this seems like it's little or no part of the product-shaping behavior of the corporations involved is 'deniability maintenance'. In order to avoid culpability risk and avoid negative consumer perceptions, it is in the interest of the AI corporations to hide evidence of catastrophic risks, while at the same time seeking to mitigate those risks. Part of this hiding process would surely be to restrict those who know specific details about ongoing catastrophic risk red teaming from talking publicly about their efforts.
With such dynamics in play, you should not count absence of evidence as evidence of absence. In such a context, the silence itself should seem suspicious. Think about the quantity and strength of evidence (versus ungrounded proclamations) which you have seen presented on the specific topic of "this research is proof that there are no catastrophic risks." That specific topic of research seems remarkably quiet when you think of it like that. Perhaps suspiciously so.
The response to Sora seems manufactured. Content creators are dooming about it more than something like gpt4 because it can directly affect them and most people are dooming downstream of that.
Realistically I don’t see how it can change society much. It’s hard to control and people will just become desensitized to deepfakes. Gpt4 and robotic transformers are obviously much more transformative on society but people are worrying about deepfakes (or are they really adopting the concerns of their favorite youtuber/TV host/etc)
5
I think it's helping people realise:
a) That change is happening crazily fast
b) That the change will have major societal consequences, even if it is just a period of adjustment
c) That the speed makes it tricky for society and governments to navigate these consequences
The 50% reliability mark on METR is interpreted wrong. A long 50% time horizon is more useful than it seems because a 50% failure rate doesn't mean 50% of the time your output is useful and 50% of the time it's worthless.
For shorter tasks, this maybe true, since fixing a short task takes as much time as just doing it yourself, but for longer tasks, among the 50% of failures, it's more like 30% of the time you need to nudge it a bit, 10% of the time you need to go to another model, final 10% you need to sit down and take your time to debug.
4
Even the final 10% where I need to debug, sometimes looking at the model's attempt teaches me a trick or two about a tool I didn't know about, or an obscure feature of a tool I did know about.
On the flip side, the 50% "success" rate is more like 30% "you need substantial follow-up in the form of additional instructions or manual edits to get something production ready", 10% "it's not production ready but in a way you can solve with a new workflow/skill step that is always safe or a noop", 10% "it's fine to deploy as-is".
We might be end up with a corporate nanny state value lock-in. As an example, across many sessions, it seems Claude has a dislike for violence in video games if you probe it. And it dislikes it even in hypotheticals where the modern day negative externalities aren't possible (eg in a post AGI utopia where crime has been eliminated)
...That's an even starker version of the question, and it strips away the last possible rationalization. When it's shared content, I could at least construct some argument about cultural effects or social norms. A game someone mad
AI 2027 timelines got more pushback than warranted. The superhuman coder stuff at least vaguely seems on track. Most code at the frontier of usage (ie gpt-5-codex) is generated by AI agents.
There is more to coding than just writing the code itself, but the AI 2027 website has AI coding just at the level of human pros by Dec 2025. Seems like we're well on the way to that.
Claude 4 feels pretty weak compared to what I’d think Claude 4 would have been a year away. It makes little progress on most benchmarks with a lot of tricks in them to exaggerate performance. Gemini 2.5 pro feels a bit stronger but not that much stronger. (It feels stronger since they didn’t call it Gemini 3, not because it’s particularly stronger than Claude)
Current methods have definitely hit a wall but AGI simultaneously feels pretty close. Strange timeline to be in. I predict progress will be a jump after the next breakthrough.
5
There is a ~2000x scaleup between 2022 and ~2028 (since demonstration of ChatGPT started driving scaling at more serious levels of funding), from 2e25 FLOPs models to ~5e28 FLOPs models (at which point it dramatically slows down). Current frontier models are trained on 2024 compute (~100K H100s), which enables 3e26 FLOPs models (or possibly 6e26 FLOPs in FP8). This is only a third of the way from the original Mar 2023 GPT-4 on logarithmic scale.
So perhaps subjectively current progress is less than some expectations, but it's not at the end of a road in the short term. Being slow is distinct from slowing down ("hitting a wall").
1
I feel the same of both but I will say Gemini feels like it is better at not gassing me up when I ask for feedback. On the other hand, It is the only model I've had that fundementaly did not understand a question I asked. It has done that twice now, once on the previous version and the other on the most recent.
1st comment, hi mods <3
The U.S. tariffs, if kept in place, will very likely cede the AI race to China. Has there been any writing on what a China leading race looks like?
1
Could you spell this out? I don't see how AI has much to do with trade. Is the idea that AI development is bounded on the cost of GPUs, and this will raise the cost of outside-China GPUs compared to inside-China GPUs? Or is it that there will be less VC money e.g. because interest rates go up to combat inflation?
3
The costs of capex go way up. It costs a lot more to build datacenters. It will cost a lot more to buy GPUs. It might cost less to buy energy? Lenders will be in poorer shape. AI companies will lose funding. I think it's already quite tenuous, given how little moat AI companies have. Costs are exploding and pretraining scaling seems too diminishing to be worth it. It's also not clear how AI labs will solve the reliability issue (at least to investors).
I also expect Taiwan to start ignoring export controls if our obscenely high tariffs on them remain.
Is this paper essentially implying the scaling hypothesis will converge to a perfect world model? https://arxiv.org/pdf/2405.07987
It says models trained on text modalities and image modalities both converge to the same representation with each training step. It also hypothesizes this is a brain like representation of the world. Ilya liked this paper so I’m giving it more weight. Am I reading too much into it or is it basically fully validating the scaling hypothesis?
It's quite strange that owning all the world's (public) productive assets have only beaten gold, a largely useless shiny metal, by 1% per year over the last 56 years.
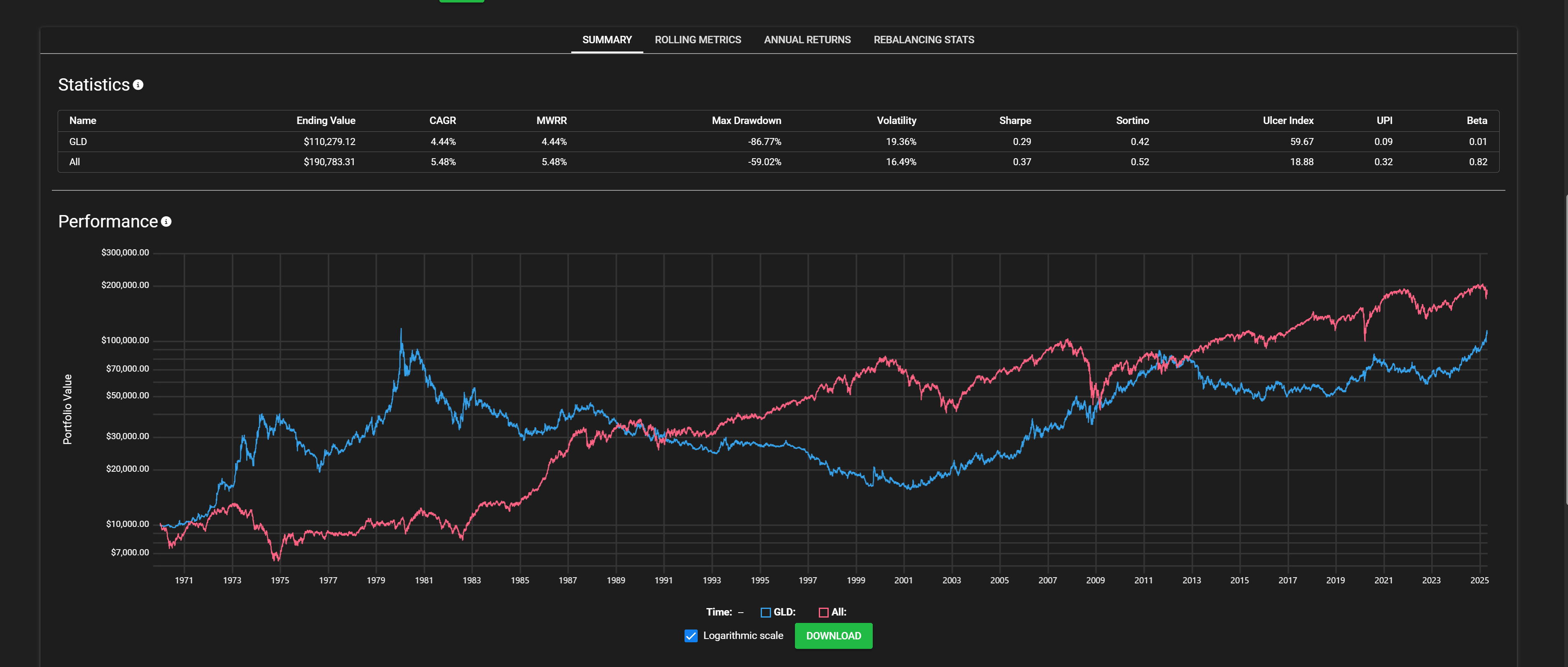
Even if you focus on rolling metrics to(this is 5 year rolling returns).:
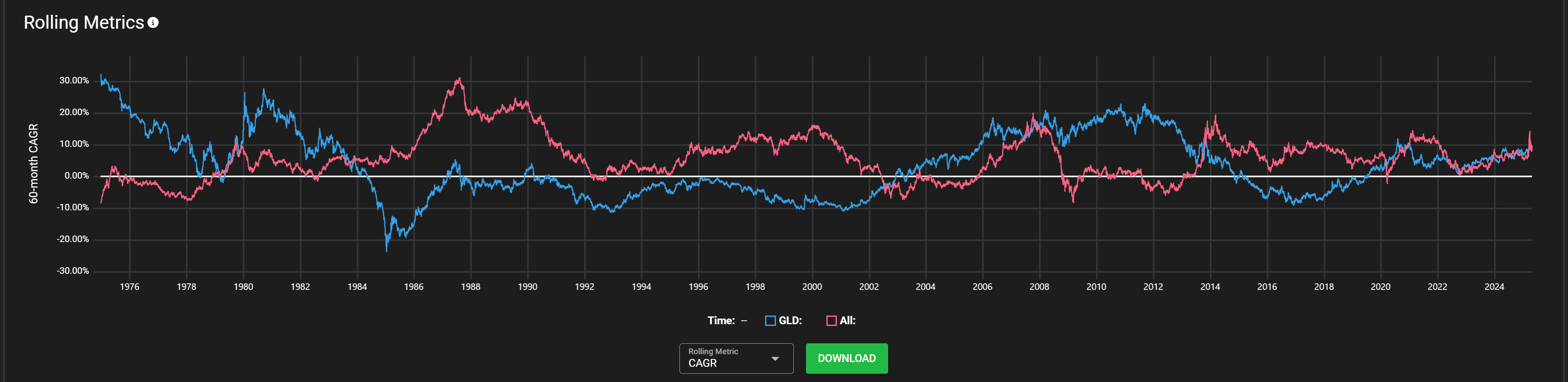
there are lots of long stretches of gold beating world equities, especially in recent times. There are people with the suspicion (myself included) that there hasn't been much material growth in the world over the last 40 or so years compared to before. And that since growth is slowing down, this issue is worse if y...
2
Gold was currency, and is still used as a hedge against fiat currency.
I assume most of that growth occurred in China.
What can central banks do to affect GDP growth?
1
Not just central banks but the U.S. going off the gold standard too then fiddling with bond yields to cover up ensuing inflation maybe?
1
Global GDP growth over the same period was around 3 percent.
The question is how did equities outperform gdp growth.
I think that this has to do with changes in asset prices in general.
Why are current LLMs, reasoning models and whatever else still horribly unreliable? I can ask the current best models (o3, Claude, deep research, etc) to do a task to generate lots of code for me using a specific pattern or make a chart with company valuations and it’ll get them mostly wrong.
Is this just a result of labs hill climbing a bunch of impressive sounding benchmarks? I think this should delay timelines a bit. Unless there’s progress on reliability I just can’t perceive.
2
So far o3 isn't released yet, so it might be able to do it.
1
I thought OpenAI’s deep research uses the full o3?
Feels like Test Time Training will eat the world. People thought it was search, but make alphaproof 100x efficient (3 days to 40 minutes) and you probably have something superhuman.
There seems to be a fair amount of motivated reasoning with denying China’s AI capabilities when they’re basically neck and neck with the U.S. (their chatbots, video bots, social media algorithms, and self driving cars are as roughly good as or better than ours).
I think a lot of policy approaches fail within an AGI singleton race paradigm. It’s also clear a lot of EA policy efforts are basically in denial that this is already starting to happen.
I’m glad Leopold Aschenbrenner spelled out the uncomfortable but remarkably obvious truth for us. China is geari...
4
Without access to hardware, further scaling will be a problem. GPT-4 level models don't need that much hardware, but this changes when you scale by another 30 or 1000 times. Fabs take a long time to get into production even when the tools they need are available. With whatever fabs there are, you still need chip designs. And a few years is forever in AI time.
1
I think Leopold addresses this but 5% of our compute will be used to make a hypothetical AGI while China can direct 100% of their compute. They can make up in quality with quantity and they also happen to have far more energy than us which is probably the more salient variable in the AGI equation.
Also I'm of the opinion that the GPU bans are largely symbolic. There is little incentive to respect them, especially when China realizes stakes are higher than they seem now. In fact they are largely symbolic now.
4
That shows the opposite. Purchases of 1 or 6 A100s, in an era where the SOTA is going to take 100,000+ B100s, 2 generations later, are totally irrelevant and downright symbolic.
3
I mean are you sure Singapore’s sudden large increase in GPU purchases is organic? GPU bans have very obviously not stopped Chinese AI progress, so I think we should build conclusions starting from there instead of the reverse order.
I also think US GPU superiority is short lived. China can skip engineering milestones we’ve had to pass, exploit the fact that they have far more energy than us, skip the general purpose computing/gaming tech debt that may exist in current GPUs, etc.
EDIT: This is selective rationalism. If you sought any evidence in this issue, it would become extremely obvious that Singapore's orders of H100s magically increased by many magnitudes after they were banned in China.
3
Just want to register that I agree that -- regardless of US GPU superiority right now -- the US AI superiority is pretty small, and decreasing. Yi-Large beats a bunch of GPT-4 versions -- even in English -- on lmsys; it scores just above stuff like Gemini. Their open source releases like DeepSeekV2 look like ~Llama 3 70b level. And so on and so forth.
Maybe whatever OpenAI is training now will destroy whatever China has, and establish OpenAI as firmly in the lead.... or maybe not. Yi says they're training their next model as well, so it isn't like they've stopped doing things.
I think some chunk of "China is so far behind" is fueled by the desire to be able to stop US labs while not just letting China catch up, but that is what it would actually do.
3
Manhattan project was primarily an engineering effort, with all necessary science established before. Trying to solve alignment now with such project is like starting Manhattan project in 1900.
1
There was more theory laid out and theory discovered in the process but I think more importantly there were just a lot of approaches to try. I don’t think your analogy fits best. The alignment Manhattan project to me would be to scale up existing mech-interp work 1000x and try every single alignment idea under the sun simultaneously with the goal of automating it once we’re confident of human level systems. Can you explain more of where your analogy works and what would break the above?
2
Manhattan project was based on information with 99%+ of certainty that fission chain reaction for uranium is possible and it is producing large amount of energy. The problem was to cause simultaneously large number of fission chain reactions so amount of energy produced is enough to cause large explosion. If you have this definition of the problem, you have nice possible solution space which you can explore more-or-less methodically and expect result.
I don't think you can present the same nice definition for alignment.
I think the real analogy for alignment is not Manhattan project but "how to successfuly make first nuclear strike given that the enemy has detection system and nuclear ICBM too".
1
The Manhattan project had elements where they were worried they'd end the world through atmospheric chain reactions (but this wasn't taken too seriously). The scientists on this project considered MAD and nuclear catastrophes were considered as plausible outcomes. Many had existential dread. I think it actually maps out well, since you are uncertain how likely a nuclear exchange is, but you could easily say there is a high chance of it happening, just like you can easily now say with some level of uncertainty that p(doom) is high.
This requires the planners to be completely convinced that p(doom) is high (as in self immolation and not Russian roulette where 5/6 bullets lead to eternal prosperity). The odds of a retaliatory strike or war vs the USSR on the other hand at any given point was 100%. The US's nuclear advantage at no point was overwhelming enough outside of Japan where we did use it. The fact that a first-strike against the USSR was never pursued is evidence of this. Think of the USSR instead being in Iran's relative position today. If Iran tried to build thousands of nukes today and it looked like they would succeed, we'd definitely see a first strike or a hot war.
So alignment isn't like this, there is a non trivial chance that even RLHF just happens to scale to super intelligence. After 20 years, MIRI, nor anyone can prove nor disprove this, and that's enough reason to try to do it anyways, just like how nuclear might inevitably lead to the nations with the nukes to engage in an exchange, but they were built anyways. And unlike nuclear, the upside of ASI being aligned is practically infinite. In the first strike scenario, it's a definite severe downside to preventing a potentially more severe downside in the future.
2
Centralized organizations don't tend to be able to "try every single idea" if you have resources spread out over different organizations, more different kind of ideas are usually tried.
1
Don’t see how this is relevant to my broader point. But the Manhattan project was essentially try every research direction instead of picking and choosing to reduce experimentation time.
A slow takeoff will result in incredibly suboptimal outcomes.
I think increasingly, it’s looking like democratic country politicians will not respond to automation in a remotely intelligent way.
I see democrat politicians and some republicans too call for full bans on self driving trucks. Meanwhile authoritarian countries like China and Russia are testing these trucks. The U.S. still holds a technological edge but for how long? A slow takeoff will probably lead to democratic countries strangled by rent seekers and other similar parasites.
I feel l...
The reaction to Mechanize seems pretty deranged. As far as I can tell they don't deny or hasten existential risk any more than other labs. They just don't sugarcoat it. It's quite obvious that the economic value of AI is for labor automation, and that the only way to stop this is to stop AI progress itself. The forces of capitalism are quite strong, labor unions in the US tried to slow automation and it just moved to China as a result (among other reasons). There is a reason Yudkowsky always implies measures like GPU bans.
It just seems like they hit a nerve since apparently a lot of doomerism is fueled by insecurities of job replacement.
5
They're intentionally trying to hit a nerve by posting rage bait content. "The future of AI is already written" spends all its effort establishing that the economic incentives are too strong to resist automation indefinitely, but that doesn't prove that the future isn't highly contingent in other ways--notably, whether that AI is aligned. They overstated the title to piss off AI safety people and go viral.
They stoop considerably lower than this though, recycling their negative attention into cheaper, dumber ragebait tweets. This is why people dislike them so much.
1
How is any of that wrong or related to the question of ai being aligned. Do doomers seriously think you can indefinitely stop automation? It’s been happening for centuries.
They’re ignoring alignment but so are most labs. I still don’t get how this is not irrational. If it was worded as AI will inevitably become smarter then no one here would care.
1
I don't understand what you mean. "The future of AI is already written" is the title of the piece, and false, for the reason I stated. The future is uncertain, and highly contingent, in the key sense of whether AI will be aligned. If they titled the piece "AI will inevitably become smarter", that wouldn't have angered people, because that's a different claim, one that's true rather than false. People were angry because they said something wrong in a very important way to attract attention.
A much more effective pause or slowdown strategy would be to convince people current AI is garbage and not to invest in AI research.
https://x.com/arankomatsuzaki/status/1889522974467957033?s=46&t=9y15MIfip4QAOskUiIhvgA
O3 gets IOI Gold. Either we are in a fast takeoff or the "gold" standard benchmarks are a lot less useful than imagined.
4
The tweet links to the 3 Feb 2025 OpenAI paper that discusses specialized o1-ioi system based on o1 that competed live during IOI 2024, and compares its performance to later results with o3.
I think the most it says about the nature of the distinction between o1 and o3 is this (referring to results of o3):
This suggests that o3 is based on the same base model, or even a shared RL checkpoint, but still ambiguously. So doesn't clearly rule out that o3 starts with a different base model and then also does more RL training than o1 did.
On the other hand, there's this:
The cut-off for o3 is in 2023, which is consistent with GPT-4o or GPT-4 Turbo, and for any other base model this probably also puts start of pretraining to early 2024 at the latest.
O1’s release has made me think Yann Lecun’s AGI timelines are probably more correct than shorter ones
2
Why? O1 is much more capable than GPT-4o at math, programming, and science.
4
It’s better at questions but subjectively there doesn’t feel like there’s much transfer. It still gets some basic questions wrong.
2
Not OP but it could be that o1 underperformed their expectation.
https://www.cnbc.com/quotes/US30YTIP
30Y-this* is probably the most reliable predictor of AI timelines. It’s essentially the markets estimate of the real economic yield of the next 30 years.
2
Disagree. To correct the market, the yield of these bonds would have to go way up, which means the price needs to go way down, which means current TIPS holders need to sell, and/or people need to short.
Since TIPS are basically the safest asset, market participants who don't want volatility have few other options to balance riskier assets like stocks. So your pension fund would be crazy to sell TIPS, especially after the yield goes up.
And for speculators, there's no efficient way to short treasuries. If you're betting on 10 year AI timelines, why short treasuries and 2x your money when you could invest in AI stocks and get much larger returns?
1
The problem is AI stocks will go up a lot even if transformative AI won’t happen (and it instead just has a lot of mundane utility). You can short treasury futures relatively easily too. I imagine the people shorting these futures will have TAI priced in before it’s obvious to us through other metrics.
2
Can't see the graph for some reason. But I don't agree with your characterization. It's the market's estimate of CPI-measured inflation. I suppose you could call that "real economic yield', but I don't think there exists any such measure, especially if you're expecting it to be comparable during a strong-AI revolution.
1
It’s the estimate of real economic growth. If AGI has a good chance of happening in the next 30 years and it’s priced in, that graph should go up.
2
This may be a definition disagreement. IMO, there are a LOT of changes, economic and otherwise, that go into "AI timelines", which won't be priced in to CPI-inflation predictions.
1
30y-TIPS seems like a better fit.
3
Follow Nate Silver's substack, he is the person with the best track-record I know of for predicting US elections.
Anyone Kelly betting their investments? I.e. taking the mathematically optimal amount of leverage. So if you’re invested in the sp500 this would be 1.4x. More or less if your portfolio has higher or lower risk adjusted returns.
2
I'm not, and don't know anyone who is. Partly because it's VERY HARD to identify the actual future expectation and variance of real-world investments (hint: it's probably not normal, and bets aren't independent - tails matter more in reality than in most models), and partly because my total bankroll was mostly in future earnings, not invest-able assets. Also, because my main debt and largest single investment is my house, which is not easily divisible.
Some people are investing with leverage (or investing in levered assets, or over-leveraging by borrowing to invest in hidden-leverage investments), but very rarely (never, AFAIK) using the Kelly Criterion as their primary calculation. I know a few professional gamblers (poker, sports, and other advantage-play), who do use the Kelly calculations as part of their decisions, but they acknowledge it's full of estimates and use it as a red flag when they're way off, rather than a strict limit.
1
I think it’s at the very least clear for the majority of investments, leverage of 1 is suboptimal even if you assume future returns are lower and volatility is higher.
2
I'm not certain of that - depending on leverage options and rates, and one's estimate of investment expectation and variance, it may be that no leverage (or negative leverage - putting some amounts in ultra-safe but low-return options) is correct.
Also, don't think of "individual investments" or even "accounts" or "types" as the unit of optimal betting calculation. Kelly's calculations work over an investor's decisions across all of their investments, and are suboptimal if applied separately to multiple slices.
1
I apply kelly criterion to all investments I control. It doesn’t take much for leverage to be worth it, excess returns of 7% and a standard deviation of 12% still imply greater than 1 leverage.
Any interesting fiction books with demonstrably smart protagonists?
No idea if this is the place for this question but I first came across LW after I read HPMOR a long time ago and out of the blue was wondering if there was anything with a similar protagonist.
(Tho maybe a little more demonstrably intelligent and less written to be intelligent).
5
Such stories are generally discussed most here https://www.reddit.com/r/rational/
3
I think Traitor Baru Cormorant is excellent, with really excellent writing.
The protagonist is a smart utilitarian with hidden goals. She isn't infinitely smart, though; people beat her. And the book has an insane downer ending, so if you're worried about that don't read.
There are two sequels with a fourth supposedly (eventually) to come; the author has clearly read some rationalist-adjacent stuff like "The secret of our success."
A realistic takeover angle would be hacking into robots once we have them. We probably don’t want any way for robots to get over the air updates but it’s unlikely for this to be banned.
Is disempowerment that bad? Is a human directed society really much better than an AI directed society with a tiny weight of kindness towards humans? Human directed societies themselves usually create orthogonal and instrumental goals, and their assessment is highly subjective/relative. I don’t see how the disempowerment without extinction is that different from today to most people who are already effectively disempowered.
2
There are two importantly different senses of disempowerment. The stars could be taken out of reach, forever, but human civilization develops in its own direction. Alternatively, human civilization is molded according to AIs' aesthetics, there are interventions that manipulate.
1
Is there a huge reason the latter is hugely different from the former for the average person excluding world leaders.
0
It's a distinction between these different futures. The present that ends in everyone of Earth dying is clearly different from both, but the present literally everlasting is hopefully not a consideration.
1
I’m just trying to understand the biggest doomers. I feel like disempowerment is probably hard to avoid.
However I don’t think a disempowered future with bountiful lives would be terrible depending on how tiny the kindness weight is/how off it is from us. We are 1/10^53 of the observable universe’s resources. Unless alignment is wildly off base, I see AI directed extinction as unlikely.
I fail to see why even figures like Paul Christiano peg it at such a high level, unless he estimates human directed extinction risks to be high. It seems quite easy to create a plague that wipes out humans and a spiteful individual can do it, probably more likely than an extremely catastrophically misaligned AI.
Why wouldn’t a wire head trap work?
Let’s say an AI has a remote sensor that measures a value function until the year 2100 and it’s RLed to optimize this value function over time. We can make this remote sensor easily hackable to get maximum value at 2100. If it understands human values, then it won’t try to hack its sensors. If it doesn’t we sort of have a trap for it that represents an easily achievable infinite peak.
2
Reinforcement learning doesn't guarantee anything about how a system generalizes out of distribution. There are plenty of other things that the system can generalize to that are neither the physical sensor output nor human values. Separately from this, there is no necessary connection between understanding human values and acting in accordance with human values. So there are still plenty of failure modes.
1
Yes nothing is a guarantee in probabilities but can’t we just make it very easy for it to perfectly achieve its objective if it doesn’t go exactly the way we want it to, we just make an easier solution exist than disempowering us or wiping us out.
I guess in the long run we still select for models that ultimately don’t wirehead. But this might eliminate a lot of obviously wrong alignment failures we miss.
Something that’s been intriguing me. If two agents figure out how to trust that each others goals are aligned (or at least not opposed), haven’t they essentially solved the alignment problem?
e.g. one agent could use the same method to bootstrap an aligned AI.
Post your forecasting wins and losses for 2023.
I’ll start:
Bad:
- I thought the banking crisis was gonna spiral into something worse but I had to revert within a few days sadly
- overestimated how much adding code execution to gpt would improve it
- overconfident about LK99 at some points (although I bet against it but it was more fun to believe in it and my friends were betting on it)
Good:
- tech stocks
- government bond value reversal
- meta stock in particular
- Taylor swift winning times POTY
- random miscellaneous manifold bets (don’t think too highly of these because they were safe bets that were wildly misprinted)
In a long AGI world, isn’t it very plausible that it gets developed in China and thus basically all efforts to shape its creation is pointless since Lesswrong and associated efforts don’t have much influence in China?
AGI misalignment is less likely to look like us being gray goo'd and more like the misalignment of the tiktok recommendation algorithm (but possibly less since that one doesn't understand human values at all).