This is a special post for quick takes by sudo. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
A long time ago, I worked on an idea I called "Context Gems." A friend asked me to make a short, publicly accessible writeup for it. This is a really rough writeup of the idea, based on some old notes I had lying around.
Context Gems was an attempt at coming up with a theoretical way of safely eliciting superhuman capabilities from an AI. It was a fairly direct off-shoot of e.g. OSNR I later heard it was similar to some ideas Paul Christiano had a long time ago, like imitative generalization/learning the prior.
The goal is to get effective cognitive labor out of a superintelligent but possibly misaligned AI model without causing catastrophe. One insight is that if for a given goal, we want to achieve this goal while receiving a minimum amount of input/information from the superintelligent model. (Another way to phrase this is that we want to maximize the density of "helpful" information in the model's outputs, to reduce its opportunities for hijacking the human operators).
Our setup is to train/use a strong (possibly superhuman) model to generate short strings ("context gems"). We intend these strings to contain some insight about the problem domain. To verify the usefulness of these short strings, we feed them into context of weaker model, which we can assess on some benchmarks. We may "reward" the strong model based on the performance of the weak model on some problem domain.
I had Claude make me a flow-chart.
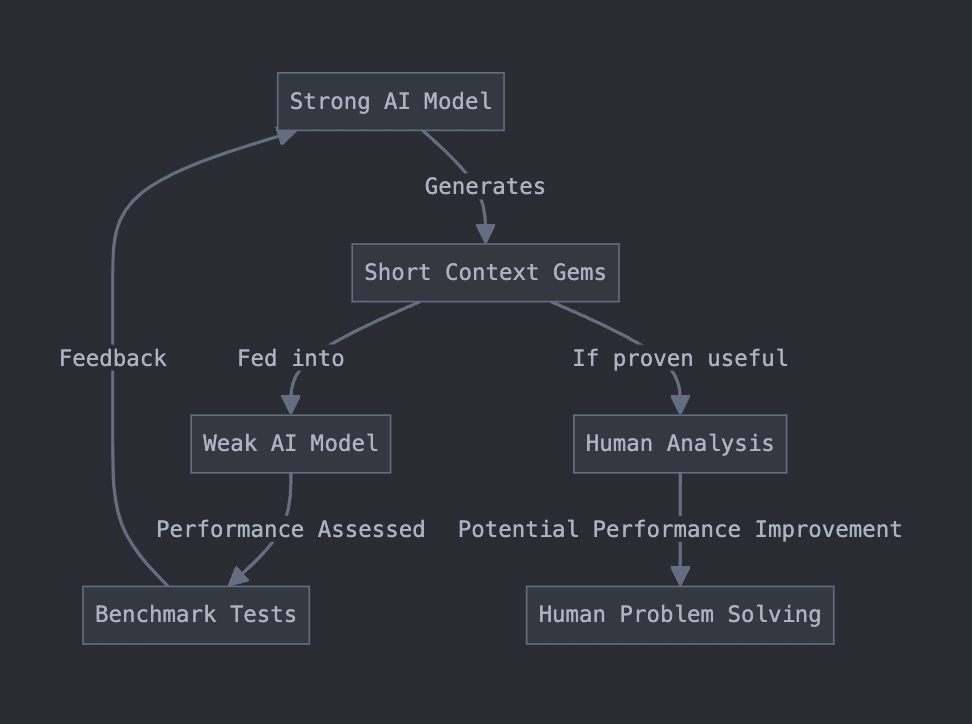
If the gems do dramatically improve the performance of the weak model, then perhaps they contain some true insight about the problem domain. Then, if the strings are sufficiently short, we might be able to expose the string to humans without causing catastrophe, hopefully resulting in similar performance improvements for humans.
Some things we might think about:
- What should be true of these "context gems"? Perhaps we want them to be short. Are there other restrictions we want to put on them?
- What are the right problem domains to select?
- If you were an adversarial/misaligned superintelligence, how might you attempt to take over the world given such a setup?
- What sort of information might actually go into these context gems?
- I'd also be interested in any empirical evidence that such a setup would work.
Why is this not just a description of an adversarial attack loop on the weak AI model, and would not just produce the usual short adversarial strings of gibberish (for LLMs) or handful of pixel perturbations (for vision or VLMs), which are generally completely useless to humans and contain no useful information?
My reply to both your and @Chris_Leong 's comment is that you should simply use robust benchmarks on which high performance is interesting.
In the adversarial attack context, the attacker's objectives are not generally beyond the model's "capabilities."
I don't think that's possible, because an attacker (LLM) can program a victim LLM to emit arbitrary text, so with enough attacks, you can solve any benchmark in the attacker's capability (thereby defeating the safety point entirely because now it's just a very expensive way to use an unsafe model), or otherwise bruteforce the benchmark by inferring the hidden answers and then creating the adversarial example which elicits that (like p-hacking: just keep trying things until you get below the magic threshold). See backdoors, triggers, dataset distillation... "A benchmark" is no more of a barrier than "flipping a specific image's class".
- We need not provide the strong model with access to the benchmark questions.
- Depending on the benchmark, it can be difficult or impossible to encode all the correct responses in a short string.
If the strong AI has knowledge of the benchmarks (or can make correct guesses about how these were structured), then it might be able to find heuristics that work well on them, but not more generally, Some of these heuristics might seem more likely than not to humans.
Still seems like a useful technique if the more powerful model isn't much more powerful.
What can be used to auth will be used to auth
One of the symptoms of our society's deep security inadequacy is the widespread usage of unsecure forms of authentication.
It's bad enough that there are systems which authenticate you using your birthday, SSN, or mother's maiden name by spec.
Fooling bad authentication is also an incredibly common vector for social engineering.
Anything you might have, which others seem unlikely to have (but which you may not immediately see a reason to keep secret), could be accepted by someone you implicitly trust as "authentication."
This includes:
- Company/industry jargon
- Company swag
- Certain biographical information about yourself (including information you could easily Google)
- Knowing how certain internal numbering or naming systems work (hotels seemingly assume only guests know how the rooms are numbered!)
Conventional advice directed at young people seem shockingly bad. I sat down to generate a list of anti-advice.
The anti-advice are things that I wish I was told in high school, but that are essentially negations of conventional advice.
You may not agree with the advice given here. In fact, they are deliberately controversial. They may also not be good advice. YMMV.
- When picking between colleges, do care a lot about getting into a prestigious/selective university. Your future employers often care too.
- Care significantly less about nebulous “college fit.” Whether you’ll enjoy a particular college is determined mainly by 1, the location, and 2, the quality of your peers
- Do not study hard and conscientiously. Instead, use your creativity to find absurd arbitrages. Internalize Thiel's main talking points and find an unusual path to victory.
- Refuse to do anything that people tell you will give you "important life skills." Certainly do not take unskilled part time work unless you need to. Instead, focus intently on developing skills that generate surplus economic value.
- If you are at all interested in a career in software (and even if you're not), get a “real” software job as quickly as possible. Real means you are mentored by a software engineer who is better at software engineering than you.
- If you’re doing things right, your school may threaten you with all manners of disciplinary action. This is mostly a sign that you’re being sufficiently ambitious.
- Do not generically seek the advice of your elders. When offered unsolicited advice, rarely take it to heart. Instead, actively seek the advice of elders who are either exceptional or unusually insightful.
There is some good stuff here! And i think it is accurate that some of these are controversial. But it also seems like a strange mix of good and “reverse-stupidity is not necessarily intelligence” ideas.
Directionally good but odd framing: It seems like great advice to offer to people that going straight for the goal (“software programming”) is a good way to approach a seemingly difficult problem. But one does not necessarily need to be mentored - this is only one of many ways. In fact, many programmers started and expanded their curiosity from typing something like ‘man systemctl’ into their shell.
Thanks for the feedback!
I agree that it is possible to learn quickly without mentorship. However, I believe that for most programmers, the first "real" programming job is a source of tremendous growth. Why not have that earlier, and save more of one's youth?
The first two points... I wonder what is the relation between "prestigious university" and "quality of your peers". Seems like it should be positively correlated, but maybe there is some caveat about the quality not being one-dimensional, like maybe rich people go to university X, but technically skilled people to university Y.
The third point, I'd say be aware of the distinction between the things you care about, and the things you have to do for bureaucratic reasons. There may or may not be an overlap between the former and the school lessons.
The fourth and seventh points are basically: some people give bad advice; and for anything you could possibly do, someone will find a rationalization why that specific thing is important (if everything else fails, they can say it makes you more "well-rounded"). But "skills that develop value" does not say how to choose e.g. between a smaller value now or a greater value in future.
The fifth point -- depends on what kind of job/mentor you get. It could be much better or much worse that school, and it may be difficult to see the difference; there are many overconfident people giving wrong advice in the industry, too.
The sixth point -- clearly, getting fired is not an optimal outcome; if you do not need to complete the school, what are you even doing there?
Signalling Considered Harmful.
I want to write an essay about how we so dramatically overvalue signalling that it might be good to completely taboo it for oneself.
Tabooing the word, or tabooing the action? I'd love to read an exploration of what types of signaling one COULD avoid - certainly we can recognize and apply less weight to them, but many (the majority, IMO) of signals are unavoidable, because there are actual goals and evaluations they impact.
I think LW folks often underestimate the importance of serendipity, especially for pre-paradigmatic fields like AI Alignment.
You want people learning functional programming and compiler design and writing kernels and playing around with new things, instead of just learning the innards of ML models and reading other people’s alignment research.
You even want people to go very deep into tangential things, and become expert kernel designers or embedded systems engineers. This is how people become capable.
People really should try to not have depression. Depression is bad for your productivity. Being depressed for eg a year means you lose a year of time, AND it might be bad for your IQ too.
A lot of EAs get depressed or have gotten depressed. This is bad. We should intervene early to stop it.
I think that there should be someone EAs reach out to when they’re depressed (maybe this is Julia Wise?), and then they get told the ways they’re probably right and wrong so their brain can update a bit, and a reasonable action plan to get them on therapy or meds or whatever.
I think this is probably good to just 80/20 with like a weekend of work? So that there’s a basic default action plan for what to do when someone goes “hi designated community person, I’m depressed.”
I don't disagree, but I don't think it's limited to EA or Rationalist community members, and I wouldn't expect that designated group helper contacts will reach most of the people who need it. It's been my experience (for myself and for a number of friends) that when someone can use this kind of help, they tend not to "reach out" for it.
Your framing of "we should intervene" may have more promise. Having specific advice on HOW lay-people can intervene would go a long way toward shifting our norms of discourse from "you seem depressed, maybe you should seek help" to "this framing may indicate a depressive episode or negative emotional feedback loop - please take a look at <this page/thread> to help figure out who you can talk with about it".
Sometimes when you purchase an item, the cashier will randomly ask you if you’d like additional related items. For example, when purchasing a hamburger, you may be asked if you’d like fries.
It is usually a horrible idea to agree to these add-ons, since the cashier does not inform you of the price. I would like fries for free, but not for $100, and not even for $5.
The cashier’s decision to withhold pricing information from you should be evidence that you do not, in fact, want to agree to the deal.
You could always ask.
I ignore upsells because I've already decided what I want and ordered that, whether it's extra fries or a hotel room upgrade.
For most LW readers, it's usually a bad idea, because many of us obsessively put cognitive effort into unimportant choices like what to order at a hamburger restaurant, and reminders or offers of additional things don't add any information or change our modeling of our preferences, so are useless. For some, they may not be aware that fries were not automatic, or may not have considered whether they want fries (at the posted price, or if price is the decider, they can ask), and the reminder adds salience to the question, so they legitimately add fries. Still others feel it as (a light, but real) pressure to fit in or please the cashier by accepting, and accept the add-on out of guilt or whatever.
Some of these reasons are "successes" in terms of mutually-beneficial trade, some are "predatory" in that the vendor makes more money and the customer doesn't get the value they'd hoped. Many are "irrelevant" in that they waste a small amount of time and change no decisions.
I think your heuristic of "decline all non-solicited offers" is pretty strong, in most aspects of the world.
Did some math today, and remembered what I love about it. Being able to just learn, without the pressure and anxiety of school, is so wonderfully joyful. I'm going back to basics, and making sure that I understand absolutely everything.
I'm feeling very excited about my future. I'm going to learn so much. I'm going to have so much fun. I'm going to get so good.
When I first started college, I set myself the goal of looking, by now, like an absolute wizard to me from a year ago. To be advanced enough to be indistinguishable from magic.
A year in, I now can do things that I couldn't have done a year ago. I'm more lucid, I'm more skilled, I'm more capable, and I'm mature than I was a year ago. I think I did it.
I'm setting myself the same goal again. I'm so excited to hit it out of the park.
I'm curious if people have looked into the extent to which Chinese AI labs are/aren't broadly value-aligned with ~longtermism (compared to US labs).
Similar question about safety: Curious if people have looked deeply into how Chinese AI labs are doing+thinking about safety relative to US labs. I think it's not entirely fair to compare on a commitment-to-commitment basis, because you'd imagine that commitments common among US companies are just not top-of-mind for Chinese labs.
I'm particularly interested in the attitudes of lab leads, and to some extent also members of technical staff.
Recently my alignment orientation has basically been “design stackable tools on top or around AI systems which produce pressure toward increased alignment.”
I think it’s a pretty productive avenue that’s 1) harder to get lost in, and 2) might be eventually sufficient for alignment.
Completely fair request. I think I was a bit vague when I said "on top or around AI systems."
The point here is that I want to find techniques that seem to positively influence model behavior, which I can "staple on" to existing models without a gargantuan engineering effort.
I am especially excited about these ideas if they seem scalable or architecture-agnostic.
Here are a few examples of the kind of research I'm excited about:
- Conciseness priors on outputs (as a way to shift cognitive labor to humans)
- I think there is a reasonable story for how conciseness priors could improve alignment. This looks like the AI being more eager to use higher level explanations that make humans guess the details, avoiding using ideas that would be very hard to grasp for a human when simpler-to-human ideas would do, being honest and transparent with humans so that we can do a better job filling in the gaps, etc.
- If it is indeed the case that strong conciseness priors incentivize transparency-to-humans, then it seems worth investigating 1, how far this effect goes, 2, if there are some tweaks / clever ways to apply pressure toward conciseness that work much better than others for alignment.
- OSNR.
- I feel pretty optimistic that applying noise to the outputs of an AI system and then having humans reconstruct it yields nice alignment properties.
- However, role-playing as a misaligned AI, there was ways that I could get around this process. Mainly, this involved "cheating" the noising process using selective redundancy. I've recently been investigating how to recover from this hack via methods like paraphrasing and calculating token salience.
- Other regularizations.
- Speed priors.
- Trying to figure out what sorts of inductive biases have nice alignment properties.
- Some of Tamera's work on externalized reasoning.
- I think betting on language models scaling to ASI would not be crazy.
- Investigating how we can influence "reasoning in language" seems promising, stackable, and is plausibly the type of work that can be "stapled on" to future models.
- AI Safety via Debate
- This just seems like something we can build once we have a really advanced language model. It stacks with everything else, and it seems to have great properties.
If someone were to discover a great regularizer for language models, OSNR turns out to work well and I sort out the issues around strategic redundancy, and externalized reasoning oversight turns out to be super promising, then we could just stack all three.
We could then clone the resulting model and run a debate, ior stack on whatever other advances we've made by that point. I'm really excited about this sort of modularity, and I guess I'm also pretty optimistic about a few of these techniques having more bite than people may initially guess.
I was watching some clips of Aaron Gwin's (American professional mountain bike racer) riding recently. Reflecting on how amazing humans are. How good we can get, with training and discipline.
It takes a certain degree of maturity and thought to see that a lot of advice from high profile advice-givers are bad.
It could be valuable to do point-by-point critiques of popular advice by high profile technologists.
Enlightened:
Terminal goal -> Instrumental goal -> Planning -> Execution
Buffoonery:
Terminal goal -> Instrumental goal -> Planning -> wait what did [insert famous person] do? Guess I need to get a PhD.
There's something really tyrannical about externally imposed KPIs.
I can't stop thinking about my GPA even if I make a conscious choice to stop optimizing for it.
Choosing to not optimize for it actually made it worse. A lower number is louder in my mind.
There's something about a number being used for sorting that completely short circuits my brain, and makes me agonize over it.
Yeah, most sane humans seem to have a deep-seated drive for comparisons with others. And numeric public comparisons trigger this to a great degree. GPA is competition-porn. Karma, for some, is social status junk-food.
This measure ALSO has some real value in feedback to you, and in signaling for future academic endeavors. The trick, like with any modern over-stimulus, is in convincing your system 1 to weight the input appropriately.